¡Bienvenido a Ruta de Programación — El Almacén Digital!
Fundamentos de Python para empezar con el pie correcto
¡Hola! Me da mucho gusto que hayas decidido comenzar tu aventura en el mundo de la programación con Python. Este libro está diseñado especialmente para personas que nunca han programado antes, así que no te preocupes si todo esto te parece completamente nuevo.
Imagínate que vas a aprender a gestionar tu propio almacén digital. Al principio puede parecer abrumador, pero con las herramientas correctas y una buena guía, pronto estarás organizando datos, automatizando tareas y creando soluciones increíbles.
¿Por qué este libro?
Durante mis años enseñando programación, me he dado cuenta de que muchos recursos asumen que ya sabes ciertas cosas o usan un lenguaje muy técnico desde el principio. Este libro es diferente. Aquí vamos a ir paso a paso, construyendo tu conocimiento como si estuvieras organizando un almacén desde cero.
Mi promesa: Al final de este libro, no solo sabrás programar en Python, sino que entenderás por qué funciona cada cosa y cómo aplicarlo en situaciones reales.
[!TIP] Consejo para principiantes No te preocupes si algunos conceptos no son claros al principio. La programación es como aprender un nuevo idioma: toma tiempo, pero cada pequeño paso te acerca más a la fluidez.
¿Qué vas a aprender?
Al terminar Ruta de Programación — El Almacén Digital, vas a poder:
- 🏗️ Construir tu propio almacén digital completo con Python
- Organizar datos usando diferentes tipos de “contenedores” (listas, diccionarios, conjuntos)
- Crear herramientas personalizadas (funciones) para automatizar tareas repetitivas
- 🤖 Programar robots digitales que trabajen por ti (bucles y condicionales)
- Generar reportes y análisis automáticos de tu inventario
- Desarrollar un sistema completo de gestión empresarial
¿Cómo está organizado este libro?
El libro sigue una progresión natural, como construir y equipar tu almacén paso a paso:
Parte I: Preparación (Capítulos 1-3)
Aquí preparamos tu “espacio de trabajo digital”. Aprenderás qué es Python, por qué es tan poderoso, y cómo configurar tu computadora para programar como un profesional.
🧠 Parte II: Conceptos Fundamentales (Capítulos 4-7)
Esta es donde aprendes a manejar tu almacén. Descubrirás cómo usar “cajas” (variables) para guardar información, “herramientas” (operadores) para procesarla, y “gerentes inteligentes” (condicionales) y “robots automatizadores” (bucles) para tomar decisiones y repetir tareas.
🏗️ Parte III: Estructuras de Datos y Organización (Capítulos 8-10)
Aquí las cosas se ponen más sofisticadas. Aprenderás diferentes sistemas de organización (listas, diccionarios, conjuntos), cómo crear herramientas especializadas (funciones), y cómo acceder al “almacén central” de herramientas de Python (módulos).
Parte IV: Proyecto Integrador (Capítulos 11-12)
¡La parte más emocionante! Construirás un sistema completo de gestión de inventario que integra todo lo aprendido, y descubrirás hacia dónde dirigir tu aprendizaje futuro.
Mi filosofía de enseñanza
Creo firmemente en aprender haciendo y entender el porqué. Por eso, cada concepto viene acompañado de:
- Analogías claras: Cada concepto de programación se explica usando la metáfora del almacén
- Ejemplos prácticos: Código que puedes probar inmediatamente y ver funcionando
- 🏋️ Ejercicios progresivos: Desde básicos hasta desafiantes, con soluciones incluidas
- Proyectos aplicados: Pequeños proyectos que muestran aplicaciones reales
- Consejos de experiencia: Tips basados en años de programación y enseñanza
¿Necesitas conocimientos previos?
¡Absolutamente ninguno! Este libro asume que nunca has programado antes. Lo único que necesitas es:
- Una computadora (Windows, Mac o Linux - te enseño a configurar cualquiera)
- 🧠 Curiosidad y ganas de aprender
- ⏰ Tiempo para practicar (recomiendo 30-60 minutos por sesión)
- Paciencia contigo mismo (todos cometemos errores al aprender)
¿Por qué Python?
Python es el lenguaje perfecto para principiantes porque:
- Es fácil de leer: Su sintaxis es casi como inglés
- Es poderoso: Usado por Google, Netflix, Instagram y miles de empresas
- Es versátil: Desde páginas web hasta inteligencia artificial
- Tiene una comunidad increíble: Millones de programadores dispuestos a ayudar
- Tiene demanda laboral: Una de las habilidades más buscadas en el mercado
Cómo usar este libro
Para el aprendizaje óptimo:
- Lee cada capítulo completamente antes de pasar al siguiente
- Prueba todos los ejemplos en tu computadora
- Haz los ejercicios - son fundamentales para el aprendizaje
- No te saltes capítulos - cada uno construye sobre el anterior
- Toma descansos cuando te sientas abrumado
Ritmo recomendado:
- Principiante total: 1-2 capítulos por semana
- Con algo de experiencia: 2-3 capítulos por semana
- Intensivo: 1 capítulo por día (con práctica)
Si te atascas:
- Vuelve a leer la sección anterior
- Prueba los ejemplos paso a paso
- Busca en la comunidad Python (te enseño cómo en el último capítulo)
- Recuerda: ¡todos los programadores se atascan a veces!
Tu viaje comienza ahora
Estás a punto de embarcarte en un viaje increíble. La programación no es solo sobre escribir código - es sobre resolver problemas, crear soluciones y hacer que las computadoras trabajen para ti.
Cada experto fue una vez principiante. Yo empecé exactamente donde estás tú ahora, y he visto a cientos de estudiantes hacer esta misma transición exitosamente.
He diseñado este libro basándome en mi experiencia enseñando Python a principiantes. He visto qué funciona, qué confunde, y qué realmente ayuda a las personas a “hacer clic” con la programación.
Mi objetivo no es solo enseñarte Python, sino convertirte en un programador que piensa como programador. Alguien que puede ver un problema y visualizar cómo resolverlo con código.
¡Empecemos!
Tu almacén digital te está esperando. Las herramientas están listas. Tu aventura en Ruta de Programación — El Almacén Digital comienza ahora.
¡Bienvenido al increíble mundo de la programación!
Consejo inicial: Mantén una actitud de curiosidad y experimentación. Los mejores programadores no son los que nunca cometen errores, sino los que aprenden de cada error y siguen intentando. ¡Tú puedes hacerlo!
Requisitos para este viaje:
- Paciencia contigo mismo (todos empezamos desde cero)
- Ganas de aprender y experimentar
- Una computadora con internet
[!WARNING] Importante Recuerda instalar Python en tu computadora antes de continuar con los ejercicios prácticos.
[consejo] Consejo adicional Si tienes experiencia previa con otros lenguajes de programación, Python te resultará sorprendentemente fácil de aprender.
Cómo usar este libro
Te recomiendo que:
- Leas cada capítulo en orden - cada uno se basa en el anterior
- Practiques todos los ejemplos - no solo los leas, ¡escríbelos!
- Hagas los ejercicios - son la clave para realmente aprender
- No te apures - es mejor entender bien cada concepto
Una nota personal
Cuando empecé a programar, me sentía completamente perdido. Todo parecía muy complicado y pensé muchas veces en rendirme. Pero la programación es como aprender un nuevo idioma: al principio cuesta trabajo, pero una vez que empiezas a “pensar” en ese idioma, todo se vuelve más natural.
Python es especialmente amigable para principiantes porque su sintaxis es muy parecida al inglés. Vas a ver que muchas cosas se leen casi como oraciones normales.
¿Listo para empezar?
¡Perfecto! En el siguiente capítulo vamos a hablar sobre qué es la programación y por qué Python es una excelente opción para empezar tu viaje como programador.
Recuerda: todos los programadores expertos fueron principiantes alguna vez. Lo importante es dar el primer paso.
¡Vamos a programar!
Capítulo 1: Introducción a la Programación y Python
¡Bienvenido a tu primer capítulo! Aquí vamos a responder las preguntas más importantes: ¿qué es la programación? y ¿por qué Python es perfecto para empezar?
¿Qué es la programación?
Imagínate que tienes un amigo muy obediente pero que necesita instrucciones súper específicas para hacer cualquier cosa. Si le dices “haz café”, no va a saber qué hacer. Pero si le dices:
- Ve a la cocina
- Llena la cafetera con agua
- Pon el filtro
- Agrega dos cucharadas de café
- Enciende la cafetera
- Espera 5 minutos
¡Ahí sí va a poder hacerte un café perfecto!
La programación es exactamente eso: darle instrucciones muy específicas a una computadora para que haga lo que queremos.
Un ejemplo cotidiano
Piensa en tu rutina matutina. Probablemente haces algo así:
# Pseudocódigo de rutina matutina
def rutina_matutina():
suena_alarma()
if dia in ["lunes", "martes", "miércoles", "jueves", "viernes"]:
levantarse_inmediatamente()
else: # fin de semana
dormir_30_minutos_mas()
ir_al_baño()
lavarse_dientes()
if hay_tiempo():
def preparar_para_trabajo():
if revisar_hora() < "8:00":
desayunar_en_casa()
else:
comprar_algo_en_camino()
¡Felicidades! Acabas de ver tu primer “algoritmo”. Un algoritmo es simplemente una serie de pasos para resolver un problema.
¿Por qué Python?
Existen muchos lenguajes de programación. Algunos son como hablar en código militar (muy precisos pero difíciles), otros son como hablar en jerga médica (muy específicos pero complicados).
Python es como hablar con un amigo inteligente: claro, directo y fácil de entender.
Mira esta comparación
En otros lenguajes podrías escribir algo así:
// Código en C++
#include <iostream>
using namespace std;
int main() {
cout << "¡Hola, mundo!" << endl;
return 0;
}
En Python escribes simplemente:
print("¡Hola, mundo!")
¿Ves la diferencia? Python es mucho más directo y fácil de leer.
¿Dónde se usa Python en el mundo real?
Python no es solo para principiantes. Se usa en lugares que probablemente conoces:
Entretenimiento
- Netflix usa Python para recomendarte películas
- Instagram procesa millones de fotos con Python
- Spotify analiza tu música favorita con Python
Empresas
- Google usa Python en muchos de sus servicios
- Dropbox está construido principalmente en Python
- Uber calcula rutas y precios con Python
Ciencia y Tecnología
- NASA usa Python para analizar datos espaciales
- Los científicos usan Python para descubrir nuevos medicamentos
- Los bancos usan Python para detectar fraudes
Las ventajas de Python
1. Fácil de leer
El código de Python se parece mucho al inglés normal. Si ves:
if edad >= 18:
print("Eres mayor de edad")
Probablemente puedes adivinar qué hace, ¡aunque nunca hayas programado!
2. Comunidad gigante
Python tiene millones de programadores en todo el mundo. Esto significa:
- Muchísimos tutoriales y recursos gratuitos
- Respuestas rápidas a tus preguntas
- Miles de herramientas ya hechas que puedes usar
3. Versatilidad increíble
Con Python puedes hacer:
- Páginas web
- Aplicaciones móviles
- Análisis de datos
- Inteligencia artificial
- Automatización de tareas
- Videojuegos
- ¡Y mucho más!
4. Oportunidades laborales
Python está entre los lenguajes más demandados. Las empresas buscan programadores de Python para:
- Desarrollo web
- Ciencia de datos
- Automatización
- Inteligencia artificial
- DevOps
La filosofía de Python
Python tiene una filosofía muy clara llamada “El Zen de Python”. Aquí tienes algunas de sus ideas principales:
- Hermoso es mejor que feo
- Explícito es mejor que implícito
- Simple es mejor que complejo
- La legibilidad cuenta
Esto significa que Python prefiere código que sea fácil de leer y entender, en lugar de código “inteligente” pero confuso.
Tu viaje de aprendizaje
Aprender a programar es como aprender a tocar un instrumento:
Al principio (donde estás ahora)
- Todo parece confuso
- Cada concepto nuevo es un reto
- Te sientes abrumado
Después de unas semanas
- Empiezas a reconocer patrones
- Los conceptos básicos se vuelven naturales
- Puedes escribir programas simples
Después de unos meses
- Puedes resolver problemas reales
- Entiendes cómo funcionan las cosas
- ¡Empiezas a disfrutar programar!
¿Qué vamos a construir juntos?
A lo largo de este libro, vamos a crear varios proyectos pequeños que te ayudarán a practicar:
- Una calculadora personal - para practicar operaciones básicas
- Un organizador de tareas - para manejar listas y datos
- Un juego de adivinanzas - para practicar lógica y decisiones
- Un analizador de texto - para trabajar con archivos
Al final del libro, vas a crear un proyecto integrador que combine todo lo que aprendiste.
Preparándote mentalmente
Antes de continuar, quiero que sepas algunas cosas importantes:
Es normal sentirse confundido
Todos los programadores se sienten así al principio. La confusión es parte del proceso de aprendizaje.
Los errores son tus amigos
En programación, los errores (llamados “bugs”) son completamente normales. De hecho, ¡vas a aprender más de tus errores que de tus éxitos!
La práctica es clave
Leer sobre programación está bien, pero programar de verdad es lo que te va a hacer mejorar.
Cada persona aprende diferente
Algunos entienden rápido los conceptos teóricos, otros prefieren ir directo a los ejemplos. Encuentra tu ritmo.
Ejercicio de reflexión
Antes de continuar al siguiente capítulo, piensa en estas preguntas:
- ¿Qué tareas repetitivas haces en tu computadora? (organizar archivos, enviar emails, etc.)
- ¿Qué te gustaría automatizar en tu vida diaria?
- ¿Qué tipo de programas te gustaría crear?
Escribe tus respuestas. Al final del libro, vas a ver que muchas de estas cosas las puedes hacer con Python.
Resumen del capítulo
En este capítulo aprendiste:
- Qué es la programación (dar instrucciones específicas a una computadora)
- Por qué Python es perfecto para principiantes (fácil de leer y muy poderoso)
- Dónde se usa Python en el mundo real (Netflix, Google, NASA, etc.)
- Las ventajas de Python (legible, versátil, gran comunidad)
- Qué esperar en tu viaje de aprendizaje
¿Qué sigue?
En el siguiente capítulo vamos a preparar tu computadora para programar. Vas a instalar Python y configurar tu entorno de desarrollo. ¡Es hora de ensuciarse las manos!
Consejo del capítulo: No trates de memorizar todo. En programación es más importante entender los conceptos que recordar sintaxis específica. ¡Para eso está Google y la documentación!
Capítulo 2: Configuración del Entorno de Python
¡Excelente! Ya sabes qué es la programación y por qué Python es genial. Ahora viene la parte práctica: vamos a preparar tu computadora para que puedas empezar a programar.
No te preocupes si esto te parece técnico al principio. Te voy a guiar paso a paso, y al final de este capítulo vas a tener todo listo para escribir tu primer programa.
¿Qué vamos a instalar?
Antes de empezar, déjame explicarte qué necesitamos:
1. Python (el lenguaje)
Es como instalar un nuevo idioma en tu computadora. Una vez instalado, tu computadora va a entender las instrucciones que escribas en Python.
2. Un editor de código (tu herramienta de trabajo)
Es como un procesador de texto, pero diseñado especialmente para escribir código. Te ayuda con colores, sugerencias y detecta errores.
3. La terminal/línea de comandos (ya viene con tu computadora)
Es una forma de darle instrucciones directas a tu computadora usando texto. No te asustes, ¡es más fácil de lo que parece!
Antes de empezar
¿Qué sistema operativo tienes?
Dependiendo de tu sistema operativo, los pasos son un poco diferentes:
- Windows - Si ves el logo de Windows al encender tu computadora
- macOS - Si tienes una Mac (computadora de Apple)
- Linux - Si usas Ubuntu, Fedora, o alguna distribución de Linux
¿Tienes derechos de administrador?
Para instalar Python necesitas permisos de administrador en tu computadora. Si es tu computadora personal, probablemente los tienes. Si es del trabajo o escuela, tal vez necesites pedirle ayuda al departamento de IT.
Guías de instalación por sistema operativo
Elige tu sistema operativo y sigue la guía correspondiente:
🪟 Instalación en Windows
- Descargar Python desde el sitio oficial
- Configurar las variables de entorno
- Verificar la instalación
Instalación en macOS
- Usar Homebrew (recomendado) o descarga directa
- Configurar el PATH
- Verificar la instalación
Instalación en Linux
- Usar el gestor de paquetes de tu distribución
- Compilar desde código fuente (si es necesario)
- Verificar la instalación
Después de instalar Python
Una vez que tengas Python instalado, vamos a verificar que todo funcione correctamente.
Verificar la instalación
Abre tu terminal o línea de comandos y escribe:
python --version
Deberías ver algo como:
Python 3.11.5
Si ves un número que empiece con 3 (como 3.8, 3.9, 3.10, 3.11, etc.), ¡perfecto! Tienes Python 3 instalado.
️ Nota importante: Si ves algo como “Python 2.7.x”, significa que tienes una versión muy antigua. En algunos sistemas, necesitas usar
python3en lugar depython.
Tu primer comando de Python
Ahora vamos a probar que Python funciona. En la terminal, escribe:
python
Deberías ver algo así:
# Ejemplo de salida:
Python 3.11.5 (main, Aug 24 2023, 15:18:16) [Clang 14.0.6 ] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
¡Felicidades! Estás dentro del intérprete interactivo de Python. Esos tres símbolos >>> significan que Python está esperando que le des una instrucción.
Prueba escribir:
print("¡Hola, mundo!")
Y presiona Enter. Deberías ver:
# Ejemplo de salida:
¡Hola, mundo!
¡Acabas de ejecutar tu primer programa en Python!
Para salir del intérprete, escribe:
exit()
Eligiendo un editor de código
Ahora que tienes Python funcionando, necesitas un buen editor para escribir tu código. Es como elegir un buen cuaderno para escribir: técnicamente puedes usar cualquier cosa, pero uno bueno hace la diferencia.
Editores e IDEs Recomendados
En la siguiente sección te explico las mejores opciones, desde las más simples hasta las más avanzadas.
Conceptos importantes
Python Shell vs. Archivos de Script
Hay dos formas principales de ejecutar código Python:
1. Python Shell (Intérprete Interactivo)
- Lo que acabas de probar
- Perfecto para probar cosas rápidas
- Escribes una línea, presionas Enter, ves el resultado
- Se pierde todo cuando sales
2. Archivos de Script (.py)
- Escribes todo tu código en un archivo
- Guardas el archivo con extensión
.py - Ejecutas todo el archivo de una vez
- Puedes guardar y reutilizar tu código
¿Cuándo usar cada uno?
Usa el Shell cuando:
- Quieras probar algo rápido
- Necesites hacer un cálculo simple
- Estés experimentando con una función nueva
Usa archivos .py cuando:
- Escribas un programa completo
- Quieras guardar tu trabajo
- Tengas más de unas pocas líneas de código
Organizando tu espacio de trabajo
Te recomiendo crear una carpeta especial para tus proyectos de Python:
En Windows:
C:\Users\TuNombre\Documentos\Python\
En macOS/Linux:
/Users/TuNombre/Documents/Python/
Dentro de esta carpeta, puedes crear subcarpetas para diferentes proyectos:
Python/
|-- ejercicios-libro/
|-- mi-primer-proyecto/
|-- experimentos/
Problemas comunes y soluciones
“python no se reconoce como comando”
Problema: Windows no encuentra Python Solución: Reinstala Python y asegúrate de marcar “Add Python to PATH”
“Permission denied”
Problema: No tienes permisos para instalar Solución: Ejecuta como administrador o pide ayuda a IT
“Python 2.7 en lugar de Python 3”
Problema: Tu sistema tiene Python 2 por defecto
Solución: Usa python3 en lugar de python
El editor no reconoce Python
Problema: Tu editor no sabe dónde está Python Solución: Configura la ruta de Python en las preferencias del editor
Ejercicio práctico
Antes de continuar al siguiente capítulo, vamos a hacer un ejercicio para asegurarnos de que todo funciona:
Paso 1: Crear tu primer archivo Python
- Abre tu editor de código
- Crea un nuevo archivo
- Escribe este código:
print("¡Mi primer programa en Python!")
print("Mi nombre es [tu nombre aquí]")
print("Estoy aprendiendo a programar")
- Guarda el archivo como
mi_primer_programa.pyen tu carpeta de Python
Paso 2: Ejecutar tu programa
- Abre la terminal
- Navega a tu carpeta de Python
- Ejecuta:
python mi_primer_programa.py
Si ves tus mensajes en la pantalla, ¡todo está funcionando perfectamente!
Resumen del capítulo
En este capítulo lograste:
- Entender qué necesitas para programar en Python
- Instalar Python en tu sistema operativo
- Verificar que la instalación funciona correctamente
- Conocer la diferencia entre el Shell y los archivos .py
- Elegir un editor de código apropiado
- Crear y ejecutar tu primer programa
¿Qué sigue?
En el siguiente capítulo vamos a profundizar en la sintaxis de Python. Aprenderás sobre:
- Las reglas básicas de escritura en Python
- Cómo Python entiende tu código
- La importancia de la indentación
- Cómo escribir comentarios útiles
¡Ya tienes las herramientas, ahora vamos a aprender el idioma!
Consejo del capítulo: No te preocupes si algo no funciona a la primera. La configuración del entorno es la parte más técnica de todo el proceso. Una vez que esté lista, ¡todo lo demás será mucho más divertido!
Instalación de Python en Windows
¡Perfecto! Tienes Windows. Esta es una de las instalaciones más sencillas. Te voy a guiar paso a paso.
Paso 1: Descargar Python
Ir al sitio oficial
- Abre tu navegador web
- Ve a python.org
- Haz clic en el botón amarillo grande que dice “Download Python 3.x.x”
💡 Tip: Siempre descarga desde python.org. Es el sitio oficial y más seguro.
¿Qué versión descargar?
- Python 3.11 o superior es perfecto para este libro
- Evita Python 2.x (ya está obsoleto)
- La página automáticamente te sugiere la mejor versión para Windows
Paso 2: Ejecutar el instalador
Abrir el archivo descargado
- Ve a tu carpeta de Descargas
- Busca un archivo que se llame algo como
python-3.11.5-amd64.exe - Haz doble clic para ejecutarlo
⚠️ IMPORTANTE: Configuración del instalador
Cuando se abra el instalador, vas a ver una ventana como esta:
+-----------------------------------+
| Install Python 3.11.5 |
| |
| [ ] Use admin privileges when... |
| [X] Add python.exe to PATH | <- ¡MUY IMPORTANTE!
| |
| [Install Now] [Customize...] |
+-----------------------------------+
¡ASEGÚRATE DE MARCAR LA CASILLA “Add python.exe to PATH”!
Esta casilla es súper importante. Si no la marcas, Windows no va a saber dónde está Python y tendrás problemas después.
Instalar
- Marca la casilla “Add python.exe to PATH”
- Haz clic en “Install Now”
- Si Windows te pide permisos de administrador, haz clic en “Sí”
- Espera a que termine la instalación (puede tomar unos minutos)
Paso 3: Verificar la instalación
Abrir la línea de comandos
- Presiona Windows + R
- Escribe
cmdy presiona Enter - Se abrirá una ventana negra (la línea de comandos)
Probar Python
En la ventana negra, escribe:
python --version
Deberías ver algo como:
Python 3.11.5
Si ves esto, ¡felicidades! Python está instalado correctamente.
Si no funciona…
Problema: “python no se reconoce como comando”
Esto significa que la casilla “Add to PATH” no se marcó correctamente.
Solución rápida:
- Desinstala Python desde “Configuración > Aplicaciones”
- Vuelve a descargar el instalador
- Esta vez SÍ marca la casilla “Add python.exe to PATH”
- Reinstala
Solución avanzada (si sabes lo que haces): Puedes agregar Python al PATH manualmente, pero es más fácil reinstalar.
Paso 4: Probar el intérprete interactivo
En la línea de comandos, escribe:
python
Deberías ver:
# Ejemplo de salida:
Python 3.11.5 (tags/v3.11.5:cce6ba9, Aug 24 2023, 14:38:34) [MSC v.1936 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
¡Perfecto! Ahora prueba tu primer comando:
print("¡Hola desde Windows!")
Para salir, escribe:
exit()
Paso 5: Instalar pip (gestor de paquetes)
La buena noticia es que pip viene incluido con Python 3.4+. Vamos a verificar que funciona:
pip --version
Deberías ver algo como:
# Ejemplo de salida:
pip 23.2.1 from C:/Users/TuNombre/AppData/Local/Programs/Python/Python311/Lib/site-packages/pip (python 3.11)
Configuración adicional para Windows
Windows Terminal (recomendado)
Si tienes Windows 10 o 11, te recomiendo instalar Windows Terminal desde la Microsoft Store. Es mucho mejor que el cmd tradicional:
- Abre Microsoft Store
- Busca “Windows Terminal”
- Instala la aplicación gratuita de Microsoft
PowerShell vs CMD
- CMD: La línea de comandos tradicional (funciona perfectamente)
- PowerShell: Más moderna y poderosa (también funciona bien)
- Windows Terminal: La más moderna y bonita
Cualquiera de las tres funciona para Python. Usa la que te sea más cómoda.
Problemas comunes en Windows
Error: “Microsoft Visual C++ 14.0 is required”
Cuándo aparece: Al instalar algunos paquetes de Python Solución: Instala “Microsoft C++ Build Tools” desde el sitio de Microsoft
Python se abre desde Microsoft Store
Problema: Windows 10/11 a veces redirige python a la Microsoft Store
Solución:
- Ve a Configuración > Aplicaciones > Alias de ejecución de aplicaciones
- Desactiva los alias de Python
Antivirus bloquea la instalación
Problema: Algunos antivirus son muy estrictos Solución: Temporalmente desactiva el antivirus durante la instalación
Verificación final
Para asegurarte de que todo está perfecto, crea un archivo de prueba:
Paso 1: Crear el archivo
- Abre el Bloc de notas
- Escribe:
print("¡Python funciona perfectamente en Windows!")
import sys
print(f"Versión de Python: {sys.version}")
print(f"Ubicación de Python: {sys.executable}")
- Guarda como
prueba.pyen tu escritorio
Paso 2: Ejecutar el archivo
- Abre la línea de comandos
- Navega al escritorio:
cd Desktop - Ejecuta:
python prueba.py
Si ves la información de tu instalación, ¡todo está listo!
Siguiente paso
Ahora que tienes Python funcionando en Windows, es hora de elegir un buen editor de código.
👉 Continúa con: Editores e IDEs Recomendados
🎯 Resumen para Windows: Descarga desde python.org, marca “Add to PATH”, verifica con
python --version. ¡Así de simple!
Instalación de Python en macOS
¡Excelente! Tienes una Mac. macOS ya viene con Python, pero probablemente es una versión antigua. Vamos a instalar la versión más reciente.
¿Ya tienes Python?
Primero, vamos a ver qué tienes instalado:
- Abre Terminal (Aplicaciones > Utilidades > Terminal)
- Escribe:
python3 --version
Probablemente veas algo como:
Python 3.9.6
Si ves Python 3.8 o superior, técnicamente puedes usar esa versión. Pero te recomiendo instalar la más reciente para tener todas las características nuevas.
Método 1: Homebrew (Recomendado) 🍺
Homebrew es el “gestor de paquetes” más popular para Mac. Es como una App Store para herramientas de desarrollo.
Paso 1: Instalar Homebrew
Si no tienes Homebrew, instálalo primero:
- Abre Terminal
- Copia y pega este comando:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
- Presiona Enter y sigue las instrucciones
- Te va a pedir tu contraseña (es normal)
Paso 2: Instalar Python con Homebrew
Una vez que tengas Homebrew:
brew install python
Esto instala la versión más reciente de Python 3.
Paso 3: Verificar la instalación
python3 --version
Deberías ver algo como:
Python 3.11.5
Método 2: Descarga directa desde python.org
Si prefieres no usar Homebrew:
Paso 1: Descargar
- Ve a python.org
- Haz clic en “Download Python 3.x.x”
- Descarga el archivo
.pkgpara macOS
Paso 2: Instalar
- Abre el archivo
.pkgdescargado - Sigue el asistente de instalación
- Usa todas las opciones por defecto
Paso 3: Verificar
python3 --version
Configurar el PATH (importante)
En Mac, es posible que necesites usar python3 en lugar de python. Para hacer tu vida más fácil, puedes crear un alias:
Opción 1: Alias temporal
alias python=python3
alias pip=pip3
Opción 2: Alias permanente
- Abre tu archivo de configuración:
nano ~/.zshrc
- Agrega estas líneas al final:
alias python=python3
alias pip=pip3
- Guarda (Ctrl+X, luego Y, luego Enter)
- Recarga la configuración:
source ~/.zshrc
Ahora puedes usar python en lugar de python3.
Verificar pip
Python viene con pip (el gestor de paquetes). Verifica que funciona:
pip3 --version
O si configuraste el alias:
pip --version
Probar el intérprete interactivo
python3
Deberías ver:
Python 3.11.5 (main, Aug 24 2023, 15:18:16) [Clang 14.0.6 ] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
Prueba:
print("¡Hola desde macOS!")
Para salir:
exit()
Configuración adicional para Mac
Xcode Command Line Tools
Algunos paquetes de Python necesitan herramientas de compilación. Instálalas con:
xcode-select --install
Esto abre una ventana donde puedes instalar las herramientas básicas de desarrollo.
iTerm2 (opcional pero recomendado)
iTerm2 es una terminal mucho mejor que la que viene por defecto:
- Ve a iterm2.com
- Descarga e instala iTerm2
- Úsala en lugar de Terminal
Problemas comunes en macOS
“python: command not found”
Problema: macOS no encuentra Python
Solución: Usa python3 o configura el alias como se explicó arriba
Problemas de permisos
Problema: “Permission denied” al instalar paquetes
Solución: Usa pip3 install --user nombre_paquete en lugar de sudo pip3 install
Conflicto entre versiones
Problema: Tienes múltiples versiones de Python
Solución: Usa python3.11 para ser específico sobre la versión
Homebrew no funciona
Problema: Homebrew no se instala correctamente Solución: Verifica que tienes Xcode Command Line Tools instalado
Gestión de versiones con pyenv (avanzado)
Si planeas trabajar con múltiples proyectos que requieren diferentes versiones de Python, considera usar pyenv:
# Instalar pyenv
brew install pyenv
# Instalar Python 3.11
pyenv install 3.11.5
# Usar Python 3.11 globalmente
pyenv global 3.11.5
Pero para empezar, esto no es necesario.
Verificación final
Crea un archivo de prueba para asegurarte de que todo funciona:
Paso 1: Crear el archivo
nano prueba.py
Paso 2: Escribir el código
print("¡Python funciona perfectamente en macOS!")
import sys
print(f"Versión de Python: {sys.version}")
print(f"Ubicación de Python: {sys.executable}")
Paso 3: Guardar y ejecutar
- Guarda (Ctrl+X, luego Y, luego Enter)
- Ejecuta:
python3 prueba.py
Si ves la información de tu instalación, ¡todo está listo!
Comandos útiles para recordar
# Verificar versión de Python
python3 --version
# Verificar versión de pip
pip3 --version
# Abrir intérprete interactivo
python3
# Ejecutar un archivo Python
python3 mi_archivo.py
# Instalar un paquete
pip3 install nombre_paquete
# Ver paquetes instalados
pip3 list
Siguiente paso
Ahora que tienes Python funcionando en macOS, es hora de elegir un buen editor de código.
👉 Continúa con: Editores e IDEs Recomendados
🍎 Resumen para macOS: Usa Homebrew (
brew install python) o descarga desde python.org. Recuerda usarpython3y considera crear aliases para mayor comodidad.
Instalación de Python en Linux
¡Genial! Usas Linux. Eres oficialmente un usuario avanzado 🐧. La buena noticia es que Linux y Python se llevan muy bien.
¿Ya tienes Python?
La mayoría de las distribuciones de Linux vienen con Python preinstalado. Vamos a verificar:
python3 --version
Probablemente veas algo como:
Python 3.9.2
Si tienes Python 3.8 o superior, técnicamente puedes usarlo. Pero te recomiendo instalar la versión más reciente.
Instalación por distribución
Ubuntu/Debian y derivados 📦
Actualizar el sistema
sudo apt update
sudo apt upgrade
Instalar Python 3.11 (o la más reciente)
# Agregar el repositorio deadsnakes (para versiones más nuevas)
sudo apt install software-properties-common
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt update
# Instalar Python 3.11
sudo apt install python3.11 python3.11-venv python3.11-pip
# Instalar herramientas de desarrollo
sudo apt install python3.11-dev build-essential
Verificar la instalación
python3.11 --version
Fedora/CentOS/RHEL 🎩
Fedora (DNF)
# Actualizar el sistema
sudo dnf update
# Instalar Python 3.11
sudo dnf install python3.11 python3.11-pip python3.11-devel
# Herramientas de desarrollo
sudo dnf groupinstall "Development Tools"
CentOS/RHEL (YUM)
# Habilitar EPEL
sudo yum install epel-release
# Instalar Python 3.11
sudo yum install python311 python311-pip python311-devel
# Herramientas de desarrollo
sudo yum groupinstall "Development Tools"
Arch Linux/Manjaro 🏹
# Actualizar el sistema
sudo pacman -Syu
# Instalar Python
sudo pacman -S python python-pip
# Herramientas de desarrollo
sudo pacman -S base-devel
openSUSE 🦎
# Actualizar el sistema
sudo zypper refresh
sudo zypper update
# Instalar Python
sudo zypper install python311 python311-pip python311-devel
# Herramientas de desarrollo
sudo zypper install -t pattern devel_basis
Compilar desde código fuente (método universal)
Si tu distribución no tiene Python 3.11+ en los repositorios:
Paso 1: Instalar dependencias
Ubuntu/Debian:
sudo apt install build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libreadline-dev libffi-dev libsqlite3-dev wget libbz2-dev
Fedora:
sudo dnf groupinstall "Development Tools"
sudo dnf install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel expat-devel
Paso 2: Descargar y compilar
# Descargar Python 3.11.5
cd /tmp
wget https://www.python.org/ftp/python/3.11.5/Python-3.11.5.tgz
tar -xf Python-3.11.5.tgz
cd Python-3.11.5
# Configurar la compilación
./configure --enable-optimizations --with-ensurepip=install
# Compilar (esto puede tomar un rato)
make -j 8
# Instalar
sudo make altinstall
Nota: Usamos
altinstallen lugar deinstallpara no sobrescribir el Python del sistema.
Paso 3: Verificar
python3.11 --version
Configurar aliases y PATH
Crear aliases útiles
Edita tu archivo de configuración de shell:
Para Bash:
nano ~/.bashrc
Para Zsh:
nano ~/.zshrc
Agrega estas líneas:
alias python=python3.11
alias pip=pip3.11
Recarga la configuración:
source ~/.bashrc # o ~/.zshrc
Verificar pip
python3.11 -m pip --version
Si pip no está instalado:
# Ubuntu/Debian
sudo apt install python3.11-pip
# Fedora
sudo dnf install python3.11-pip
# Método universal
python3.11 -m ensurepip --upgrade
Entornos virtuales
En Linux es especialmente importante usar entornos virtuales para no interferir con el Python del sistema:
Instalar venv
# Ubuntu/Debian
sudo apt install python3.11-venv
# Fedora
sudo dnf install python3.11-venv
Crear un entorno virtual
python3.11 -m venv mi_entorno
source mi_entorno/bin/activate
Para desactivar:
deactivate
Problemas comunes en Linux
“python3.11: command not found”
Problema: Python no está en el PATH
Solución: Usa la ruta completa /usr/local/bin/python3.11 o crea un symlink
Problemas de permisos con pip
Problema: “Permission denied” al instalar paquetes
Solución: Usa --user o entornos virtuales
pip3.11 install --user nombre_paquete
Falta librerías de desarrollo
Problema: Error al compilar paquetes Solución: Instala las herramientas de desarrollo mencionadas arriba
Conflicto con Python del sistema
Problema: Múltiples versiones de Python
Solución: Usa versiones específicas (python3.11) y entornos virtuales
Gestión avanzada con pyenv
Para manejar múltiples versiones de Python fácilmente:
Instalar pyenv
# Clonar pyenv
git clone https://github.com/pyenv/pyenv.git ~/.pyenv
# Configurar PATH
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc
echo 'command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(pyenv init -)"' >> ~/.bashrc
# Recargar
source ~/.bashrc
Usar pyenv
# Ver versiones disponibles
pyenv install --list
# Instalar Python 3.11.5
pyenv install 3.11.5
# Usar globalmente
pyenv global 3.11.5
# Verificar
python --version
Verificación final
Crea un archivo de prueba:
# Crear el archivo
cat > prueba.py << EOF
print("¡Python funciona perfectamente en Linux!")
import sys
print(f"Versión de Python: {sys.version}")
print(f"Ubicación de Python: {sys.executable}")
print(f"Distribución: {sys.platform}")
EOF
# Ejecutar
python3.11 prueba.py
Comandos útiles para Linux
# Verificar versión
python3.11 --version
# Verificar ubicación
which python3.11
# Ver información del sistema
python3.11 -c "import sys; print(sys.version_info)"
# Instalar paquete para el usuario
pip3.11 install --user paquete
# Crear entorno virtual
python3.11 -m venv nombre_entorno
# Activar entorno virtual
source nombre_entorno/bin/activate
# Ver paquetes instalados
pip3.11 list
Distribuciones específicas
WSL (Windows Subsystem for Linux)
Si usas WSL, sigue las instrucciones de Ubuntu/Debian. Todo funciona igual.
Raspberry Pi OS
sudo apt update
sudo apt install python3.11 python3.11-pip python3.11-venv
Alpine Linux
apk add python3 py3-pip
Siguiente paso
Ahora que tienes Python funcionando en Linux, es hora de elegir un buen editor de código.
👉 Continúa con: Editores e IDEs Recomendados
🐧 Resumen para Linux: Usa el gestor de paquetes de tu distribución, considera compilar desde fuente para versiones más nuevas, y siempre usa entornos virtuales para proyectos.
Editores e IDEs Recomendados
¡Perfecto! Ya tienes Python instalado. Ahora necesitas un buen editor para escribir tu código. Es como elegir un buen cuaderno para escribir: técnicamente puedes usar cualquier cosa, pero uno bueno hace toda la diferencia.
¿Editor o IDE? ¿Cuál es la diferencia?
Editor de código
- Más simple y ligero
- Se enfoca en escribir código
- Rápido de abrir y usar
- Perfecto para empezar
IDE (Entorno de Desarrollo Integrado)
- Más completo y robusto
- Incluye muchas herramientas integradas
- Puede ser abrumador para principiantes
- Perfecto cuando ya tienes experiencia
Recomendaciones por nivel
🌱 Para principiantes absolutos
1. Visual Studio Code (VS Code) ⭐ MÁS RECOMENDADO
¿Por qué es perfecto para empezar?
- Gratuito y de código abierto
- Muy fácil de usar
- Excelente soporte para Python
- Funciona en Windows, Mac y Linux
- Comunidad gigante
Instalación:
- Busca “Visual Studio Code” en tu navegador o ve directamente a Microsoft Store/App Store
- Descarga para tu sistema operativo (Windows, Mac, Linux)
- Instala normalmente siguiendo el asistente
Configuración para Python:
- Abre VS Code
- Ve a Extensions (Ctrl+Shift+X)
- Busca “Python”
- Instala la extensión oficial de Microsoft
- ¡Listo!
Características que te van a encantar:
- Resalta tu código con colores
- Te sugiere mientras escribes
- Detecta errores antes de ejecutar
- Terminal integrada
- Explorador de archivos
2. Thonny 🐍 PERFECTO PARA APRENDER
¿Por qué es genial para principiantes?
- Diseñado específicamente para aprender Python
- Interfaz súper simple
- Debugger visual (puedes ver cómo se ejecuta tu código paso a paso)
- Viene con Python incluido
Instalación:
- Ve a thonny.org
- Descarga para tu sistema
- Instala y ¡ya está listo para usar!
Perfecto si:
- Nunca has programado antes
- Quieres entender cómo funciona tu código
- Prefieres algo súper simple
🌿 Para usuarios con algo de experiencia
3. Sublime Text ⚡ SÚPER RÁPIDO
¿Por qué es genial?
- Extremadamente rápido
- Interfaz elegante y minimalista
- Muy personalizable
- Excelente para archivos grandes
Instalación:
- Ve a sublimetext.com
- Descarga la versión 4
- Instala normalmente
Nota: Es de pago, pero puedes usarlo gratis indefinidamente (solo aparece un recordatorio ocasional).
4. Atom (Descontinuado pero aún funcional)
GitHub descontinuó Atom, pero si ya lo tienes instalado, sigue funcionando bien.
🌳 Para usuarios avanzados
5. PyCharm 🚀 EL MÁS COMPLETO
¿Por qué es increíble?
- IDE profesional específico para Python
- Herramientas de debugging avanzadas
- Refactoring inteligente
- Integración con Git
- Soporte para frameworks web
Versiones:
- PyCharm Community (gratuito) - Perfecto para empezar
- PyCharm Professional (de pago) - Para desarrollo web y científico
Instalación:
- Ve a jetbrains.com/pycharm
- Descarga Community Edition
- Instala siguiendo el asistente
Advertencia: Puede ser abrumador para principiantes.
6. Vim/Neovim 🤓 PARA NINJAS
Si ya usas Vim, puedes configurarlo para Python. Pero si no sabes qué es Vim, ¡ignora esta opción por ahora!
Comparación rápida
| Editor | Dificultad | Velocidad | Características | Precio |
|---|---|---|---|---|
| VS Code | 🟢 Fácil | 🟡 Buena | 🟢 Muchas | Gratis |
| Thonny | 🟢 Muy fácil | 🟡 Buena | 🟡 Básicas | Gratis |
| Sublime | 🟡 Media | 🟢 Excelente | 🟡 Buenas | $99 |
| PyCharm | 🔴 Difícil | 🟡 Buena | 🟢 Excelentes | Gratis/Pago |
Mi recomendación personal
Si nunca has programado: Thonny
- Súper fácil de usar
- Te ayuda a entender cómo funciona Python
- No te abruma con opciones
Si tienes algo de experiencia con computadoras: VS Code
- Balance perfecto entre simplicidad y potencia
- Vas a poder usarlo para otros lenguajes también
- Comunidad enorme = muchos tutoriales
Si ya eres programador: PyCharm Community
- Herramientas profesionales
- Te hace más productivo
- Específico para Python
Configuración básica de VS Code para Python
Como VS Code es el más popular, aquí tienes una configuración básica:
Extensiones esenciales:
- Python (Microsoft) - Soporte básico para Python
- Pylance (Microsoft) - Análisis de código avanzado
- Python Docstring Generator - Para documentar tu código
- autoDocstring - Genera documentación automáticamente
Configuración recomendada:
- Abre VS Code
- Ve a File > Preferences > Settings (o Ctrl+,)
- Busca estas configuraciones:
{
"python.defaultInterpreterPath": "python3",
"python.linting.enabled": true,
"python.linting.pylintEnabled": true,
"python.formatting.provider": "black",
"editor.formatOnSave": true,
"editor.tabSize": 4,
"editor.insertSpaces": true
}
Características importantes que buscar
1. Resaltado de sintaxis
Tu código debe verse con colores diferentes para palabras clave, strings, comentarios, etc.
2. Autocompletado
El editor debe sugerirte mientras escribes.
3. Detección de errores
Debe subrayar errores antes de que ejecutes el código.
4. Terminal integrada
Para ejecutar tu código sin salir del editor.
5. Explorador de archivos
Para navegar entre tus archivos fácilmente.
Editores que NO recomiendo para empezar
❌ Notepad/Bloc de notas
- No tiene resaltado de sintaxis
- No detecta errores
- Muy básico
❌ Word/LibreOffice Writer
- Son procesadores de texto, no editores de código
- Agregan formato que rompe el código
❌ IDEs muy complejos
- Eclipse con PyDev
- NetBeans
- Son muy complicados para empezar
Configuración del primer proyecto
Una vez que elijas tu editor, vamos a configurar tu primer proyecto:
Paso 1: Crear una carpeta
Mi_Primer_Proyecto_Python/
|-- main.py
|-- ejercicios/
|-- notas.txt
Paso 2: Abrir en tu editor
- VS Code: File > Open Folder
- Thonny: File > Open
- PyCharm: File > Open
Paso 3: Crear tu primer archivo
- Crea un archivo llamado
hola.py - Escribe:
print("¡Hola, mundo!")
print("Mi primer programa en Python")
- Guarda el archivo
- Ejecuta desde la terminal:
python hola.py
Atajos de teclado útiles
VS Code:
Ctrl+Shift+P- Paleta de comandosCtrl+` - Abrir terminalF5- Ejecutar códigoCtrl+/- Comentar/descomentar línea
Thonny:
F5- Ejecutar códigoCtrl+D- Debugger paso a pasoCtrl+/- Comentar línea
Próximos pasos
Una vez que tengas tu editor configurado:
- Practica escribiendo código simple
- Aprende los atajos básicos
- Explora las características poco a poco
- No te abrumes con plugins al principio
Resumen de recomendaciones
🥇 Primera opción: VS Code
- Perfecto balance para principiantes
- Gratis y muy popular
- Crecerás con él
🥈 Segunda opción: Thonny
- Si quieres algo súper simple
- Perfecto para aprender conceptos
- Cambiarás después a algo más avanzado
🥉 Tercera opción: PyCharm Community
- Si ya tienes experiencia programando
- Muy completo pero puede abrumar
¿Qué sigue?
¡Perfecto! Ya tienes Python instalado y un editor configurado. En el siguiente capítulo vamos a aprender la sintaxis básica de Python y escribir nuestros primeros programas reales.
👉 Continúa con: Capítulo 3 - Sintaxis de Python y Tu Primer Programa
💡 Consejo final: No te obsesiones con elegir el editor “perfecto”. Cualquiera de los recomendados te servirá bien. Lo importante es empezar a programar. ¡Siempre puedes cambiar después!
Capítulo 3: Sintaxis de Python y Tu Primer Programa
¡Excelente! Ya tienes Python instalado y tu editor configurado. Ahora viene la parte emocionante: ¡vamos a escribir código Python de verdad!
En este capítulo vas a aprender las reglas básicas de Python y escribir varios programas. No te preocupes si al principio te parece extraño - es como aprender un nuevo idioma, y Python es uno de los más fáciles de aprender.
¿Qué hace especial a Python?
Antes de empezar, déjame mostrarte por qué Python es tan popular. Mira este ejemplo:
# En otros lenguajes podrías escribir algo así:
# if (edad >= 18) {
# printf("Eres mayor de edad\n");
# }
# En Python escribes simplemente:
if edad >= 18:
print("Eres mayor de edad")
¿Ves la diferencia? Python se lee casi como español normal. ¡Esa es su magia!
Tu primer programa (de verdad)
Vamos a empezar con algo simple pero significativo. Abre tu editor y crea un archivo llamado mi_primer_programa.py:
print("¡Hola, mundo!")
print("Mi nombre es [tu nombre aquí]")
print("Estoy aprendiendo Python")
print("¡Y me está gustando mucho!")
Guarda el archivo y ejecútalo desde la terminal:
python mi_primer_programa.py
¡Felicidades! Acabas de escribir y ejecutar tu primer programa en Python.
Las reglas básicas de Python
1. Python es sensible a mayúsculas y minúsculas
# Estas son variables DIFERENTES:
nombre = "Juan"
Nombre = "María"
NOMBRE = "Pedro"
print(nombre) # Imprime: Juan
print(Nombre) # Imprime: María
print(NOMBRE) # Imprime: Pedro
2. La indentación es SÚPER importante
En otros lenguajes usas llaves {} para agrupar código. En Python usas espacios o tabs:
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#77B255" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V4c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v28z"/><path fill="#FFF" d="M29.28 6.362c-1.156-.751-2.704-.422-3.458.736L14.936 23.877l-5.029-4.65c-1.014-.938-2.596-.875-3.533.138-.937 1.014-.875 2.596.139 3.533l7.209 6.666c.48.445 1.09.665 1.696.665.673 0 1.534-.282 2.099-1.139.332-.506 12.5-19.27 12.5-19.27.751-1.159.421-2.707-.737-3.458z"/></svg> CORRECTO
if edad >= 18:
print("Eres mayor de edad")
print("Puedes votar")
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> INCORRECTO
if edad >= 18:
print("Eres mayor de edad") # Error: falta indentación
Regla de oro: Usa siempre 4 espacios para indentar. La mayoría de los editores lo hacen automáticamente.
3. Una instrucción por línea
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#77B255" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V4c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v28z"/><path fill="#FFF" d="M29.28 6.362c-1.156-.751-2.704-.422-3.458.736L14.936 23.877l-5.029-4.65c-1.014-.938-2.596-.875-3.533.138-.937 1.014-.875 2.596.139 3.533l7.209 6.666c.48.445 1.09.665 1.696.665.673 0 1.534-.282 2.099-1.139.332-.506 12.5-19.27 12.5-19.27.751-1.159.421-2.707-.737-3.458z"/></svg> CORRECTO
print("Primera línea")
print("Segunda línea")
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> Evita esto (aunque funciona)
print("Primera línea"); print("Segunda línea")
4. Los comentarios empiezan con #
# Esto es un comentario - Python lo ignora
print("Hola") # También puedes comentar al final de una línea
# Los comentarios son para explicar tu código
# Son súper útiles para recordar qué hace cada parte
Probando la sintaxis básica
Vamos a crear un programa que demuestre las reglas básicas. Crea un archivo llamado sintaxis_basica.py:
# Mi segundo programa en Python
# Autor: [Tu nombre]
print("=== Programa de Sintaxis Básica ===")
# Variables (las veremos más a detalle en el siguiente capítulo)
mi_nombre = "Estudiante de Python"
mi_edad = 25
# Usando las variables
print("Hola, soy", mi_nombre)
print("Tengo", mi_edad, "años")
# Ejemplo de indentación con condicional
if mi_edad >= 18:
print("Soy mayor de edad")
print("Puedo programar sin supervisión <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#FFCC4D" d="M36 18c0 9.941-8.059 18-18 18-9.94 0-18-8.059-18-18C0 8.06 8.06 0 18 0c9.941 0 18 8.06 18 18"/><path fill="#664500" d="M28.457 17.797c-.06-.135-1.499-3.297-4.457-3.297-2.957 0-4.397 3.162-4.457 3.297-.092.207-.032.449.145.591.175.142.426.147.61.014.012-.009 1.262-.902 3.702-.902 2.426 0 3.674.881 3.702.901.088.066.194.099.298.099.11 0 .221-.037.312-.109.177-.142.238-.386.145-.594zm-12 0c-.06-.135-1.499-3.297-4.457-3.297-2.957 0-4.397 3.162-4.457 3.297-.092.207-.032.449.144.591.176.142.427.147.61.014.013-.009 1.262-.902 3.703-.902 2.426 0 3.674.881 3.702.901.088.066.194.099.298.099.11 0 .221-.037.312-.109.178-.142.237-.386.145-.594zM18 22c-3.623 0-6.027-.422-9-1-.679-.131-2 0-2 2 0 4 4.595 9 11 9 6.404 0 11-5 11-9 0-2-1.321-2.132-2-2-2.973.578-5.377 1-9 1z"/><path fill="#FFF" d="M9 23s3 1 9 1 9-1 9-1-2 4-9 4-9-4-9-4z"/></svg>")
print("¡Fin del programa!")
Ejecuta este programa y observa cómo funciona:
python sintaxis_basica.py
Entendiendo los errores de sintaxis
Los errores son normales y útiles. Python te dice exactamente qué está mal:
Error de indentación:
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> Código con error
if True:
print("Hola") # Falta indentación
Error que verás:
IndentationError: expected an indented block
Solución:
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#77B255" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V4c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v28z"/><path fill="#FFF" d="M29.28 6.362c-1.156-.751-2.704-.422-3.458.736L14.936 23.877l-5.029-4.65c-1.014-.938-2.596-.875-3.533.138-.937 1.014-.875 2.596.139 3.533l7.209 6.666c.48.445 1.09.665 1.696.665.673 0 1.534-.282 2.099-1.139.332-.506 12.5-19.27 12.5-19.27.751-1.159.421-2.707-.737-3.458z"/></svg> Código corregido
if True:
print("Hola") # Ahora sí está indentado
Error de sintaxis:
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> Código con error
print("Hola mundo" # Falta cerrar el paréntesis
Error que verás:
SyntaxError: unexpected EOF while parsing
Solución:
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#77B255" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V4c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v28z"/><path fill="#FFF" d="M29.28 6.362c-1.156-.751-2.704-.422-3.458.736L14.936 23.877l-5.029-4.65c-1.014-.938-2.596-.875-3.533.138-.937 1.014-.875 2.596.139 3.533l7.209 6.666c.48.445 1.09.665 1.696.665.673 0 1.534-.282 2.099-1.139.332-.506 12.5-19.27 12.5-19.27.751-1.159.421-2.707-.737-3.458z"/></svg> Código corregido
print("Hola mundo") # Paréntesis cerrado
Diferentes formas de ejecutar código Python
1. Archivos .py (lo que hemos estado haciendo)
python mi_programa.py
2. Intérprete interactivo
python
>>> print("Hola desde el intérprete")
Hola desde el intérprete
>>> exit()
3. Desde tu editor (si tiene esta función)
- En VS Code: presiona F5
- En Thonny: presiona F5
- En PyCharm: presiona Shift+F10
Ejercicio práctico: Tu tarjeta de presentación
Vamos a crear un programa más interesante. Crea un archivo llamado tarjeta_presentacion.py:
# Programa: Mi Tarjeta de Presentación Digital
# Descripción: Un programa que muestra información personal
print("=" * 40) # Imprime 40 signos de igual
print(" MI TARJETA DE PRESENTACIÓN")
print("=" * 40)
# Información personal (cambia estos datos por los tuyos)
nombre = "Tu Nombre Aquí"
edad = 25
ciudad = "Tu Ciudad"
hobby = "Tu Hobby Favorito"
# Mostrar la información
print() # Línea en blanco
print("Nombre:", nombre)
print("Edad:", edad, "años")
print("Ciudad:", ciudad)
print("Hobby favorito:", hobby)
print()
# Un mensaje personalizado
if edad >= 18:
print("¡Soy mayor de edad y estoy aprendiendo Python!")
else:
print("¡Soy joven y ya estoy aprendiendo Python!")
print()
print("¡Gracias por conocerme! <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M11.84 7.634c-.719 0-2.295 2.243-3.567 1.029-.44-.419 1.818-1.278 1.727-2.017-.075-.607-2.842-1.52-1.875-2.099.967-.578 2.418.841 3.513.866 2.382.055 4.212-.853 4.238-.866.541-.274 1.195-.052 1.464.496.27.547.051 1.213-.488 1.486-.131.066-2.225 1.105-5.012 1.105z"/><path fill="#77B255" d="M27.818 36c-3.967 0-8.182-2.912-8.182-8.308 0-1.374-.89-1.661-1.637-1.661-.746 0-1.636.287-1.636 1.661 0 5.396-4.216 8.308-8.182 8.308S0 33.23 0 27.692C0 14.4 14.182 12.565 14.182 14.4c0 1.835-7.636-1.107-7.636 12.185 0 2.215.89 2.769 1.636 2.769.747 0 1.637-.287 1.637-1.661 0-5.395 4.215-8.308 8.182-8.308 3.966 0 8.182 2.912 8.182 8.308 0 1.374.89 1.661 1.637 1.661s1.636-.287 1.636-1.661V11.077c0-3.855-3.417-4.431-5.454-4.431 0 0-3.272 1.108-6.545 1.108s-4.364-2.596-4.364-4.431C13.091 1.488 17.455 0 24 0c6.546 0 12 4.451 12 11.077v16.615C36 33.088 31.784 36 27.818 36z"/><circle fill="#292F33" cx="19" cy="3" r="1"/></svg>")
print("=" * 40)
Personaliza este programa:
- Cambia los valores de las variables por tu información real
- Agrega más información si quieres (país, comida favorita, etc.)
- Experimenta con diferentes mensajes
Buenas prácticas de escritura
1. Usa nombres descriptivos
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#77B255" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V4c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v28z"/><path fill="#FFF" d="M29.28 6.362c-1.156-.751-2.704-.422-3.458.736L14.936 23.877l-5.029-4.65c-1.014-.938-2.596-.875-3.533.138-.937 1.014-.875 2.596.139 3.533l7.209 6.666c.48.445 1.09.665 1.696.665.673 0 1.534-.282 2.099-1.139.332-.506 12.5-19.27 12.5-19.27.751-1.159.421-2.707-.737-3.458z"/></svg> BUENO
nombre_usuario = "Juan"
edad_en_años = 25
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> MALO
n = "Juan"
x = 25
2. Agrega comentarios útiles
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#77B255" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V4c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v28z"/><path fill="#FFF" d="M29.28 6.362c-1.156-.751-2.704-.422-3.458.736L14.936 23.877l-5.029-4.65c-1.014-.938-2.596-.875-3.533.138-.937 1.014-.875 2.596.139 3.533l7.209 6.666c.48.445 1.09.665 1.696.665.673 0 1.534-.282 2.099-1.139.332-.506 12.5-19.27 12.5-19.27.751-1.159.421-2.707-.737-3.458z"/></svg> BUENO
# Calcular el precio con descuento del 10%
precio_final = precio_original * 0.9
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> MALO
# Multiplicar por 0.9
precio_final = precio_original * 0.9
3. Usa espacios para mayor legibilidad
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#77B255" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V4c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v28z"/><path fill="#FFF" d="M29.28 6.362c-1.156-.751-2.704-.422-3.458.736L14.936 23.877l-5.029-4.65c-1.014-.938-2.596-.875-3.533.138-.937 1.014-.875 2.596.139 3.533l7.209 6.666c.48.445 1.09.665 1.696.665.673 0 1.534-.282 2.099-1.139.332-.506 12.5-19.27 12.5-19.27.751-1.159.421-2.707-.737-3.458z"/></svg> BUENO
resultado = (a + b) * c
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> MALO (funciona, pero es difícil de leer)
resultado=(a+b)*c
4. Organiza tu código con líneas en blanco
# Información del usuario
nombre = "Juan"
edad = 25
# Procesar información
if edad >= 18:
print("Mayor de edad")
# Mensaje final
print("¡Hasta luego!")
Herramientas útiles en tu editor
VS Code:
- Ctrl + / - Comentar/descomentar líneas
- Shift + Alt + F - Formatear código automáticamente
- F5 - Ejecutar programa
Thonny:
- Ctrl + / - Comentar líneas
- F5 - Ejecutar programa
- Ctrl + D - Debugger (muy útil para aprender)
Ejercicios para practicar
Ejercicio 1: Calculadora de presentación
Crea un programa que:
- Muestre un título bonito
- Defina dos números
- Muestre la suma, resta, multiplicación y división
- Use comentarios para explicar cada parte
Ejercicio 2: Historia personal
Crea un programa que cuente una historia corta usando:
- Al menos 5 líneas de print()
- Variables para nombres y lugares
- Comentarios explicando la historia
- Buena indentación y formato
Ejercicio 3: Detector de errores
Te doy este código con errores. Encuéntralos y corrígelos:
# Programa con errores - ¡encuéntralos!
print("Iniciando programa"
nombre = "Python"
if nombre == "Python":
print("¡Me gusta este lenguaje!")
# Falta algo aquí...
print("Fin del programa"
Resumen del capítulo
En este capítulo aprendiste:
- Las reglas básicas de sintaxis de Python
- La importancia de la indentación
- Cómo escribir y ejecutar programas .py
- Diferentes formas de ejecutar código Python
- Cómo leer y entender errores de sintaxis
- Buenas prácticas de escritura de código
- Herramientas útiles en tu editor
¿Qué sigue?
En el siguiente capítulo vamos a profundizar en variables y tipos de datos. Aprenderás:
- Qué son las variables y cómo usarlas
- Los diferentes tipos de datos en Python
- Cómo convertir entre tipos
- Reglas para nombrar variables
- ¡Y mucho más!
Ya tienes las bases de la sintaxis. Ahora vamos a aprender a manejar información de verdad.
Consejo del capítulo: No te preocupes por memorizar toda la sintaxis. Lo importante es entender los conceptos. Con la práctica, escribir código Python se volverá tan natural como escribir en español. ¡La clave está en practicar un poco cada día!
Reglas de Sintaxis de Python
La sintaxis son las “reglas de gramática” de Python. Así como el español tiene reglas sobre cómo formar oraciones, Python tiene reglas sobre cómo escribir código. ¡La buena noticia es que Python tiene menos reglas que el español!
La regla más importante: Indentación
¿Qué es la indentación?
La indentación son los espacios al inicio de una línea. En Python, estos espacios no son opcionales - son parte del código.
# Sin indentación (nivel 0)
print("Esta línea no tiene indentación")
# Con indentación (nivel 1)
if True:
print("Esta línea tiene 4 espacios de indentación")
# Con más indentación (nivel 2)
if True:
print("Esta línea tiene 8 espacios de indentación")
¿Por qué es importante?
Python usa la indentación para saber qué código va junto:
# Ejemplo: código que va junto
if edad >= 18:
print("Eres mayor de edad") # Estas dos líneas
print("Puedes obtener tu licencia") # van juntas
print("Este mensaje siempre se muestra") # Esta línea es independiente
Reglas de indentación:
- Usa siempre la misma cantidad de espacios
# ✅ CORRECTO - siempre 4 espacios
if True:
print("Línea 1")
print("Línea 2")
# ❌ INCORRECTO - mezcla 4 y 2 espacios
if True:
print("Línea 1") # 4 espacios
print("Línea 2") # 2 espacios - ¡Error!
- La recomendación oficial es 4 espacios
# ✅ Recomendado
if True:
print("Usando 4 espacios")
# ✅ Funciona, pero no es recomendado
if True:
print("Usando 2 espacios")
- No mezcles espacios y tabs
# ❌ NUNCA hagas esto
if True:
print("Esta línea usa espacios")
print("Esta línea usa tab") # ¡Error!
Sensibilidad a mayúsculas y minúsculas
Python distingue entre mayúsculas y minúsculas en todo:
Variables:
nombre = "Juan"
Nombre = "María"
NOMBRE = "Pedro"
print(nombre) # Juan
print(Nombre) # María
print(NOMBRE) # Pedro
Funciones:
print("Hola") # ✅ Correcto
Print("Hola") # ❌ Error: Print no existe
PRINT("Hola") # ❌ Error: PRINT no existe
Palabras clave:
if True: # ✅ Correcto
print("Sí")
If True: # ❌ Error: If no es una palabra clave
print("No")
Estructura de líneas
Una instrucción por línea (recomendado):
# ✅ Fácil de leer
print("Primera línea")
print("Segunda línea")
print("Tercera línea")
Múltiples instrucciones en una línea (evítalo):
# ❌ Funciona, pero es difícil de leer
print("Línea 1"); print("Línea 2"); print("Línea 3")
Líneas muy largas (cómo dividirlas):
# ❌ Línea muy larga
mensaje_muy_largo = "Este es un mensaje extremadamente largo que es difícil de leer porque no cabe bien en la pantalla"
# ✅ Dividir con paréntesis
mensaje_muy_largo = ("Este es un mensaje extremadamente largo "
"que ahora es más fácil de leer "
"porque está dividido en varias líneas")
# ✅ Dividir con barra invertida
mensaje_muy_largo = "Este es un mensaje extremadamente largo " \
"que también es fácil de leer"
Espacios en blanco
Espacios alrededor de operadores:
# ✅ Fácil de leer
resultado = a + b * c
nombre = "Juan"
# ❌ Funciona, pero es difícil de leer
resultado=a+b*c
nombre="Juan"
Espacios después de comas:
# ✅ Correcto
print("Hola", "mundo", "desde", "Python")
# ❌ Funciona, pero es menos legible
print("Hola","mundo","desde","Python")
NO uses espacios innecesarios:
# ✅ Correcto
print("Hola")
lista[0]
# ❌ Espacios innecesarios
print ( "Hola" )
lista [ 0 ]
Nombres válidos en Python
Reglas para nombres de variables y funciones:
- Deben empezar con letra o guión bajo
# ✅ Válidos
nombre = "Juan"
_edad = 25
mi_variable = 100
# ❌ Inválidos
2nombre = "Juan" # No puede empezar con número
mi-variable = 100 # No puede tener guiones
- Solo pueden contener letras, números y guiones bajos
# ✅ Válidos
nombre1 = "Juan"
mi_edad = 25
variable_muy_larga = 100
# ❌ Inválidos
mi@variable = 100 # No puede tener @
mi variable = 100 # No puede tener espacios
mi-variable = 100 # No puede tener guiones
- No pueden ser palabras reservadas
# ❌ Estas palabras están reservadas
if = 5 # Error: 'if' es palabra reservada
for = 10 # Error: 'for' es palabra reservada
def = 20 # Error: 'def' es palabra reservada
Convenciones de nombres (no son reglas, pero es buena práctica):
# ✅ Variables y funciones: snake_case (minúsculas con guiones bajos)
mi_nombre = "Juan"
edad_usuario = 25
# ✅ Constantes: MAYÚSCULAS
PI = 3.14159
VELOCIDAD_LUZ = 299792458
# ✅ Clases: PascalCase (lo veremos más adelante)
MiClase = "ejemplo"
Caracteres especiales
Comillas para texto:
# Todas estas formas son válidas
nombre1 = "Juan"
nombre2 = 'María'
mensaje = """Este es un mensaje
que ocupa varias líneas"""
Paréntesis para funciones:
print("Hola") # Los paréntesis son obligatorios
len("Python") # Incluso si no hay argumentos: len()
Dos puntos para bloques de código:
# Los dos puntos son obligatorios antes de un bloque indentado
if edad >= 18: # ← Dos puntos aquí
print("Mayor de edad")
Ejercicio práctico: Detector de errores de sintaxis
Aquí tienes varios ejemplos con errores. ¿Puedes encontrarlos?
# Ejemplo 1
if True
print("Hola")
# Ejemplo 2
if True:
print("Hola")
# Ejemplo 3
Print("Hola mundo")
# Ejemplo 4
mi-nombre = "Juan"
# Ejemplo 5
if True:
print("Línea 1")
print("Línea 2")
Soluciones:
# Ejemplo 1 - Faltan los dos puntos
if True:
print("Hola")
# Ejemplo 2 - Falta indentación
if True:
print("Hola")
# Ejemplo 3 - print va en minúsculas
print("Hola mundo")
# Ejemplo 4 - No se pueden usar guiones en nombres
mi_nombre = "Juan"
# Ejemplo 5 - Indentación inconsistente
if True:
print("Línea 1")
print("Línea 2")
Consejos para evitar errores de sintaxis
1. Configura tu editor correctamente
- Haz que muestre espacios y tabs
- Configura indentación automática de 4 espacios
- Activa el resaltado de sintaxis
2. Lee los mensajes de error
Python te dice exactamente dónde está el problema:
File "mi_programa.py", line 3
print("Hola")
^
IndentationError: expected an indented block
3. Usa un estilo consistente
- Siempre 4 espacios para indentar
- Espacios alrededor de operadores
- Nombres descriptivos en snake_case
4. Practica regularmente
La sintaxis se vuelve natural con la práctica. ¡No te desanimes si al principio cometes errores!
Resumen de reglas importantes
| Regla | ✅ Correcto | ❌ Incorrecto |
|---|---|---|
| Indentación | if True:print("Hola") | if True:print("Hola") |
| Mayúsculas | print("Hola") | Print("Hola") |
| Dos puntos | if True: | if True |
| Nombres | mi_variable = 5 | mi-variable = 5 |
| Espacios | a + b | a+b |
💡 Recuerda: La sintaxis de Python está diseñada para ser legible. Si tu código se ve limpio y organizado, probablemente está bien escrito. ¡La práctica hace al maestro!
Comentarios y Documentación
Los comentarios son como notas que escribes para ti mismo (y otros programadores) para explicar qué hace tu código. Python los ignora completamente, pero son súper importantes para escribir código que sea fácil de entender.
¿Por qué son importantes los comentarios?
Imagínate que escribes un programa hoy y lo revisas en 6 meses. Sin comentarios, probablemente te preguntes: “¿Qué diablos estaba pensando cuando escribí esto?” 😅
Ejemplo sin comentarios:
x = 1000
y = x * 0.16
z = x + y
print(z)
El mismo ejemplo con comentarios:
# Calcular el precio final de un producto con IVA
precio_producto = 1000 # Precio base del producto
iva = precio_producto * 0.16 # IVA del 16%
precio_final = precio_producto + iva # Precio total
print(precio_final) # Mostrar el resultado
¿Cuál es más fácil de entender? ¡Exacto!
Tipos de comentarios en Python
1. Comentarios de una línea
Se escriben con # y Python ignora todo lo que viene después:
# Este es un comentario completo
print("Hola mundo") # Este es un comentario al final de la línea
# Puedes usar comentarios para "desactivar" código temporalmente
# print("Esta línea no se ejecutará")
print("Esta línea sí se ejecutará")
2. Comentarios de múltiples líneas
Python no tiene comentarios de múltiples líneas como otros lenguajes, pero puedes usar varias líneas con #:
# Este es un comentario
# que ocupa varias líneas
# para explicar algo complejo
print("Hola")
3. Docstrings (cadenas de documentación)
Para explicaciones largas, puedes usar comillas triples:
"""
Este es un docstring.
Se usa para documentar funciones, clases o módulos.
Puede ocupar varias líneas y es muy útil
para explicaciones detalladas.
"""
print("Mi programa")
Cuándo y cómo usar comentarios
✅ Buenos comentarios:
1. Explican el “por qué”, no el “qué”
# ✅ BUENO - explica por qué
precio_final = precio * 1.16 # Agregamos IVA del 16%
# ❌ MALO - solo repite lo que hace el código
precio_final = precio * 1.16 # Multiplicamos precio por 1.16
2. Explican lógica compleja
# ✅ BUENO
# Usamos el algoritmo de Luhn para validar números de tarjeta de crédito
# porque es el estándar de la industria bancaria
if validar_tarjeta(numero):
procesar_pago()
3. Advierten sobre cosas importantes
# ✅ BUENO
# CUIDADO: Esta función modifica la lista original
# Si necesitas conservar la original, haz una copia primero
def ordenar_lista(mi_lista):
mi_lista.sort()
4. Explican decisiones de diseño
# ✅ BUENO
# Usamos un diccionario en lugar de una lista
# porque necesitamos búsquedas rápidas por nombre
usuarios = {
"juan": {"edad": 25, "email": "juan@email.com"},
"maria": {"edad": 30, "email": "maria@email.com"}
}
❌ Malos comentarios:
1. Comentarios obvios
# ❌ MALO - es obvio lo que hace
edad = 25 # Asignar 25 a la variable edad
print(edad) # Imprimir la variable edad
2. Comentarios desactualizados
# ❌ MALO - el comentario no coincide con el código
# Calcular descuento del 10%
descuento = precio * 0.20 # ¡En realidad es 20%!
3. Comentarios que insultan
# ❌ MALO - no seas negativo
# Este código es horrible pero funciona
# TODO: Reescribir esta porquería
Comentarios para organizar tu código
Secciones del programa:
# ================================
# CONFIGURACIÓN INICIAL
# ================================
nombre_usuario = "Juan"
edad_usuario = 25
# ================================
# PROCESAMIENTO DE DATOS
# ================================
if edad_usuario >= 18:
print("Mayor de edad")
# ================================
# RESULTADOS FINALES
# ================================
print("Programa terminado")
Separadores visuales:
# --- Datos del usuario ---
nombre = "Juan"
edad = 25
# --- Validaciones ---
if edad >= 18:
print("Válido")
# --- Fin del programa ---
print("Terminado")
Comentarios TODO y FIXME
Estos son comentarios especiales que muchos editores resaltan:
# TODO: Agregar validación de email
email = input("Tu email: ")
# FIXME: Este cálculo no funciona con números negativos
resultado = calcular_raiz(numero)
# HACK: Solución temporal hasta arreglar el bug #123
if sistema == "windows":
ruta = ruta.replace("/", "\\")
# NOTE: Esta función será removida en la versión 2.0
def funcion_antigua():
pass
Documentando tu primer programa
Vamos a tomar un programa simple y documentarlo correctamente:
Antes (sin documentación):
n = input("Nombre: ")
e = int(input("Edad: "))
if e >= 18:
print("Hola", n, "eres mayor")
else:
print("Hola", n, "eres menor")
Después (bien documentado):
"""
Programa: Verificador de Mayoría de Edad
Autor: [Tu nombre]
Fecha: [Fecha actual]
Descripción: Solicita nombre y edad al usuario y determina
si es mayor o menor de edad.
"""
# ================================
# ENTRADA DE DATOS
# ================================
# Solicitar información personal al usuario
nombre_usuario = input("Ingresa tu nombre: ")
edad_usuario = int(input("Ingresa tu edad: "))
# ================================
# PROCESAMIENTO
# ================================
# Verificar mayoría de edad (18 años en México)
if edad_usuario >= 18:
print("Hola", nombre_usuario, "eres mayor de edad")
else:
print("Hola", nombre_usuario, "eres menor de edad")
# ================================
# FIN DEL PROGRAMA
# ================================
# El programa termina aquí
Comentarios en diferentes idiomas
Aunque tu código esté en español, los comentarios técnicos a veces se escriben en inglés:
# Configuración del sistema
API_KEY = "mi_clave_secreta"
# TODO: Add error handling for API failures
# FIXME: Memory leak in data processing function
def procesar_datos():
pass
Esto es normal y está bien. Lo importante es ser consistente.
Herramientas para comentarios
En VS Code:
- Ctrl + / - Comentar/descomentar líneas seleccionadas
- Shift + Alt + A - Comentario de bloque
- Las extensiones pueden resaltar TODO, FIXME, etc.
En Thonny:
- Ctrl + / - Comentar/descomentar
- Ctrl + Shift + / - Comentario de bloque
Ejercicios prácticos
Ejercicio 1: Documenta este código
p = float(input("Precio: "))
d = float(input("Descuento %: "))
df = p * (d / 100)
pf = p - df
print("Precio final:", pf)
Ejercicio 2: Crea un programa documentado
Escribe un programa que:
- Tenga un docstring al inicio
- Pida dos números al usuario
- Calcule y muestre la suma, resta, multiplicación y división
- Use comentarios para explicar cada sección
- Use nombres de variables descriptivos
Ejercicio 3: Encuentra los problemas
¿Qué está mal con estos comentarios?
# Este programa suma dos números
a = 5 # Variable a es igual a 5
b = 10 # Variable b es igual a 10
resultado = a * b # Sumamos a y b
print(resultado) # Imprimimos el resultado
Buenas prácticas para comentarios
1. Escribe comentarios mientras programas
No los dejes para después - es fácil olvidar qué estabas pensando.
2. Mantén los comentarios actualizados
Si cambias el código, actualiza los comentarios.
3. Usa un estilo consistente
Decide un formato y úsalo en todo tu programa.
4. No comentes código obvio
Si el código es claro, no necesita comentarios.
5. Explica el contexto
¿Por qué tomaste esa decisión? ¿Qué problema resuelve?
Plantilla para tus programas
Aquí tienes una plantilla que puedes usar para tus programas:
"""
Programa: [Nombre del programa]
Autor: [Tu nombre]
Fecha: [Fecha]
Versión: 1.0
Descripción:
[Explica qué hace tu programa]
Uso:
[Cómo se usa el programa]
"""
# ================================
# IMPORTACIONES Y CONFIGURACIÓN
# ================================
# [Aquí van los imports si los hay]
# ================================
# FUNCIONES
# ================================
# [Aquí van las funciones si las hay]
# ================================
# PROGRAMA PRINCIPAL
# ================================
if __name__ == "__main__":
# [Aquí va tu código principal]
pass
Resumen
Los comentarios son esenciales para:
- ✅ Explicar código complejo
- ✅ Documentar decisiones de diseño
- ✅ Ayudar a otros programadores (¡y a ti mismo en el futuro!)
- ✅ Organizar secciones de código
- ✅ Marcar tareas pendientes (TODO)
Recuerda: el código se escribe una vez, pero se lee muchas veces. ¡Haz que sea fácil de entender!
💡 Consejo profesional: Un buen programador no es el que escribe código complejo, sino el que escribe código simple y bien documentado que cualquiera puede entender. ¡Los comentarios son tu mejor herramienta para esto!
Ejecutar Código Python
Ya sabes escribir código Python, pero ¿sabías que hay varias formas de ejecutarlo? Cada método tiene sus ventajas y es útil en diferentes situaciones. ¡Vamos a explorarlas todas!
Método 1: Archivos .py (El más común)
Esta es la forma que hemos estado usando. Escribes tu código en un archivo con extensión .py y lo ejecutas desde la terminal.
Paso a paso:
- Crear el archivo
# archivo: mi_programa.py
print("¡Hola desde un archivo Python!")
nombre = "Estudiante"
print(f"Bienvenido, {nombre}")
- Ejecutar desde la terminal
python mi_programa.py
- Resultado
¡Hola desde un archivo Python!
Bienvenido, Estudiante
Ventajas:
- ✅ Puedes guardar y reutilizar tu código
- ✅ Perfecto para programas largos
- ✅ Fácil de compartir con otros
- ✅ Puedes usar control de versiones (Git)
Cuándo usarlo:
- Programas que vas a usar varias veces
- Código que quieres guardar
- Proyectos serios
Método 2: Intérprete Interactivo (REPL)
REPL significa “Read-Eval-Print Loop” (Leer-Evaluar-Imprimir-Repetir). Es perfecto para probar cosas rápidamente.
Cómo acceder:
python
Verás algo así:
Python 3.11.5 (main, Aug 24 2023, 15:18:16)
Type "help", "copyright", "credits" or "license" for more information.
>>>
Ejemplo de uso:
>>> print("¡Hola desde el intérprete!")
¡Hola desde el intérprete!
>>> 2 + 2
4
>>> nombre = "Python"
>>> print(f"Me gusta {nombre}")
Me gusta Python
>>> exit()
Ventajas:
- ✅ Resultados inmediatos
- ✅ Perfecto para experimentar
- ✅ Ideal para cálculos rápidos
- ✅ Puedes probar funciones antes de usarlas en tu programa
Cuándo usarlo:
- Probar una función nueva
- Hacer cálculos rápidos
- Experimentar con código
- Aprender cómo funciona algo
Método 3: Desde tu Editor/IDE
La mayoría de los editores modernos pueden ejecutar Python directamente.
VS Code:
-
Método 1: Botón de Play
- Abre tu archivo .py
- Haz clic en el triángulo ▶️ en la esquina superior derecha
-
Método 2: Atajo de teclado
- Presiona
F5 - O
Ctrl + F5para ejecutar sin debugger
- Presiona
-
Método 3: Terminal integrada
- Presiona `Ctrl + `` (backtick) para abrir terminal
- Ejecuta:
python nombre_archivo.py
Thonny:
- Presiona F5 o haz clic en el botón “Run”
- El resultado aparece en la parte inferior
- Puedes usar el debugger para ver paso a paso
PyCharm:
- Clic derecho en el archivo → “Run”
- Shift + F10 para ejecutar
- Shift + F9 para ejecutar con debugger
Ventajas:
- ✅ No necesitas cambiar de ventana
- ✅ Integración con debugger
- ✅ Fácil acceso a herramientas
- ✅ Resaltado de errores
Método 4: Línea de comandos con -c
Puedes ejecutar código Python directamente desde la terminal sin crear un archivo:
python -c "print('Hola desde la línea de comandos')"
python -c "
import math
print(f'El valor de pi es: {math.pi}')
print(f'La raíz cuadrada de 16 es: {math.sqrt(16)}')
"
Ventajas:
- ✅ Súper rápido para comandos simples
- ✅ Útil en scripts de automatización
- ✅ No crea archivos temporales
Cuándo usarlo:
- Comandos de una línea
- Scripts de automatización
- Cálculos rápidos en la terminal
Método 5: Jupyter Notebooks (Avanzado)
Los notebooks son documentos interactivos que mezclan código, texto y resultados. Son muy populares en ciencia de datos.
Instalación:
pip install jupyter
Uso:
jupyter notebook
Ejemplo de celda:
# Celda 1
print("Esta es la primera celda")
x = 10
# Celda 2
print(f"El valor de x es: {x}")
y = x * 2
print(f"El doble de x es: {y}")
Ventajas:
- ✅ Perfecto para análisis de datos
- ✅ Combina código, texto y gráficos
- ✅ Fácil de compartir resultados
- ✅ Ideal para experimentación
Método 6: Scripts ejecutables (Linux/Mac)
Puedes hacer que tus archivos Python se ejecuten directamente como programas:
Paso 1: Agregar shebang
#!/usr/bin/env python3
print("¡Este script se ejecuta directamente!")
Paso 2: Hacer ejecutable
chmod +x mi_script.py
Paso 3: Ejecutar
./mi_script.py
Comparación de métodos
| Método | Velocidad | Permanencia | Uso típico |
|---|---|---|---|
| Archivos .py | Media | ✅ Permanente | Programas completos |
| Intérprete | ✅ Rápida | ❌ Temporal | Pruebas rápidas |
| Editor/IDE | Media | ✅ Permanente | Desarrollo |
| Línea -c | ✅ Rápida | ❌ Temporal | Comandos simples |
| Jupyter | Media | ✅ Permanente | Análisis de datos |
| Ejecutable | Media | ✅ Permanente | Scripts del sistema |
Consejos para cada método
Para archivos .py:
# Siempre incluye esta línea al final de tus scripts principales
if __name__ == "__main__":
# Tu código principal aquí
print("Ejecutando programa principal")
Para el intérprete:
# Usa help() para obtener ayuda
>>> help(print)
# Usa dir() para ver qué métodos tiene un objeto
>>> dir("hola")
# Usa type() para ver el tipo de una variable
>>> type(42)
Para editores:
- Configura atajos de teclado personalizados
- Usa el debugger para entender tu código
- Aprovecha las extensiones de Python
Ejercicios prácticos
Ejercicio 1: Prueba todos los métodos
Crea este programa simple y ejecútalo de 3 formas diferentes:
# programa_prueba.py
import math
print("=== Calculadora Básica ===")
numero = 16
print(f"Número: {numero}")
print(f"Raíz cuadrada: {math.sqrt(numero)}")
print(f"Cuadrado: {numero ** 2}")
print("=== Fin ===")
- Guárdalo como archivo y ejecútalo con
python programa_prueba.py - Copia el código línea por línea en el intérprete interactivo
- Ejecútalo desde tu editor favorito
Ejercicio 2: Intérprete interactivo
Usa el intérprete para:
- Calcular cuántos segundos hay en un año
- Convertir 100 grados Fahrenheit a Celsius
- Crear una lista con los nombres de 3 amigos
- Mostrar el tercer nombre de la lista
Ejercicio 3: Línea de comandos
Ejecuta estos comandos desde la terminal:
python -c "print('Hola mundo')"
python -c "import datetime; print(f'Hoy es: {datetime.date.today()}')"
python -c "print(' '.join(['Python', 'es', 'genial']))"
Problemas comunes y soluciones
“python no se reconoce como comando”
Problema: Windows no encuentra Python Solución:
- Reinstala Python marcando “Add to PATH”
- O usa
pyen lugar depython
“No such file or directory”
Problema: El archivo no existe o estás en el directorio incorrecto Solución:
# Verificar dónde estás
pwd
# Listar archivos
ls # En Linux/Mac
dir # En Windows
# Cambiar directorio
cd ruta/a/tu/archivo
El programa no hace nada
Problema: Puede que tengas errores de sintaxis Solución:
- Revisa la indentación
- Verifica que no falten dos puntos
: - Lee el mensaje de error completo
“ModuleNotFoundError”
Problema: Intentas importar algo que no está instalado Solución:
pip install nombre_del_modulo
Flujo de trabajo recomendado
Para principiantes, te recomiendo este flujo:
- Experimenta en el intérprete - Prueba ideas rápidas
- Escribe en archivos .py - Para código que quieres guardar
- Ejecuta desde tu editor - Para desarrollo cómodo
- Usa la terminal - Para ejecutar programas finales
Resumen
Ahora conoces 6 formas de ejecutar código Python:
- ✅ Archivos .py - Para programas completos
- ✅ Intérprete interactivo - Para pruebas rápidas
- ✅ Editor/IDE - Para desarrollo cómodo
- ✅ Línea de comandos (-c) - Para comandos simples
- ✅ Jupyter Notebooks - Para análisis de datos
- ✅ Scripts ejecutables - Para automatización
Cada método tiene su lugar. ¡Experimenta con todos y encuentra cuáles prefieres para diferentes situaciones!
💡 Consejo profesional: Los programadores expertos usan diferentes métodos según la situación. El intérprete para probar ideas, archivos .py para programas serios, y la línea de comandos para tareas rápidas. ¡Dominar todos te hace más eficiente!
Capítulo 4: Variables y Tipos de Datos
¡Felicidades! Ya sabes escribir código Python básico. Ahora vamos a aprender sobre variables, que son una de las herramientas más importantes en programación.
La analogía del almacén con cajas
Nota del autor: Cuando enseño programación, me gusta usar analogías que conecten conceptos abstractos con cosas cotidianas. La analogía del “almacén con cajas” es mi favorita para explicar variables y tipos de datos.
Imagínate que eres el encargado de un almacén gigante. Tienes miles de cajas de diferentes tamaños y colores. Cada caja puede guardar un tipo específico de cosa:
- Caja azul pequeña → Solo números enteros (como 5, 10, -3)
- Caja verde mediana → Solo números decimales (como 3.14, -2.5)
- Caja amarilla grande → Solo texto (como “Hola”, “Python es genial”)
- Caja roja pequeña → Solo valores de verdadero/falso
En Python, las variables son exactamente como estas cajas. Cada variable:
- Tiene un nombre (como una etiqueta en la caja)
- Puede guardar un valor (el contenido de la caja)
- Tiene un tipo específico (el tipo de caja que es)
# Creando nuestras "cajas" (variables)
edad = 25 # Caja azul con el número 25
precio = 19.99 # Caja verde con el número 19.99
nombre = "Juan" # Caja amarilla con el texto "Juan"
es_estudiante = True # Caja roja con el valor True
¿Qué son las variables?
Una variable es como una caja etiquetada donde puedes guardar información para usarla después. Es uno de los conceptos más fundamentales en programación.
Ejemplo práctico:
# Sin variables (difícil de entender)
print("Hola, mi nombre es Juan")
print("Juan tiene 25 años")
print("Juan vive en México")
# Con variables (mucho más claro)
nombre = "Juan"
edad = 25
pais = "México"
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#FFAC33" d="M28.84 17.638c-.987 1.044-1.633 3.067-1.438 4.493l.892 6.441c.197 1.427-.701 2.087-1.996 1.469l-5.851-2.796c-1.295-.62-3.408-.611-4.7.018l-5.826 2.842c-1.291.629-2.193-.026-2.007-1.452l.843-6.449c.186-1.427-.475-3.444-1.47-4.481l-4.494-4.688c-.996-1.037-.655-2.102.755-2.365l6.37-1.188c1.41-.263 3.116-1.518 3.793-2.789L16.762.956c.675-1.271 1.789-1.274 2.473-.009L22.33 6.66c.686 1.265 2.4 2.507 3.814 2.758l6.378 1.141c1.412.252 1.761 1.314.774 2.359l-4.456 4.72z"/><path fill="#FFD983" d="M9.783 2.181c1.023 1.413 2.446 4.917 1.717 5.447-.728.531-3.607-1.91-4.63-3.323-1.022-1.413-.935-2.668-.131-3.254.804-.587 2.02-.282 3.044 1.13zm19.348 2.124C28.109 5.718 25.23 8.16 24.5 7.627c-.729-.53.695-4.033 1.719-5.445C27.242.768 28.457.463 29.262 1.051c.803.586.89 1.841-.131 3.254zM16.625 33.291c-.001-1.746.898-5.421 1.801-5.421.897 0 1.798 3.675 1.797 5.42 0 1.747-.804 2.712-1.8 2.71-.994.002-1.798-.962-1.798-2.709zm16.179-9.262c-1.655-.539-4.858-2.533-4.579-3.395.277-.858 4.037-.581 5.69-.041 1.655.54 2.321 1.605 2.013 2.556-.308.95-1.469 1.42-3.124.88zM2.083 20.594c1.655-.54 5.414-.817 5.694.044.276.857-2.928 2.854-4.581 3.392-1.654.54-2.818.07-3.123-.88-.308-.95.354-2.015 2.01-2.556z"/></svg> Usando f-strings (recomendado)
print(f"Hola, mi nombre es {nombre}")
print(f"{nombre} tiene {edad} años")
print(f"{nombre} vive en {pais}")
¿Ves la diferencia? Con variables, si quieres cambiar el nombre de “Juan” a “María”, solo cambias una línea en lugar de tres. ¡Esto hace que tu código sea mucho más fácil de mantener!
Creando tu primera variable
En Python, crear una variable es súper fácil:
# Sintaxis: nombre_variable = valor
mi_nombre = "Tu nombre aquí"
Es como tomar una caja, ponerle una etiqueta que dice “mi_nombre”, y meter dentro el texto “Tu nombre aquí”.
Ejemplos de diferentes tipos de cajas:
# Caja para números enteros (int)
edad = 20
puntos = 1500
temperatura = -5
# Caja para números decimales (float)
altura = 1.75
precio = 29.99
pi = 3.14159
# Caja para texto (str)
nombre = "Ana"
mensaje = "¡Hola mundo!"
email = "ana@email.com"
# Caja para verdadero/falso (bool)
es_mayor_edad = True
tiene_mascota = False
esta_lloviendo = True
🧱 Tipos de datos elementales y compuestos
Nota del autor: Me gusta clasificar los tipos de datos en Python en dos grandes categorías: elementales y compuestos. Esta es mi perspectiva personal que me ha ayudado a enseñar estos conceptos de manera más clara.
Tipos Elementales (Los ladrillos básicos)
Los tipos elementales son los componentes fundamentales que no se pueden descomponer más. Son como los ladrillos individuales con los que construiremos todo lo demás:
1. int (Enteros) - La caja azul
Guarda números enteros (sin decimales):
edad = 25
año_nacimiento = 1998
temperatura = -10
puntos_juego = 0
print(f"La edad es {edad} y su tipo es: {type(edad)}") # <class 'int'>
Ejemplos de uso:
- Edad de una persona
- Cantidad de productos
- Año
- Puntuación en un juego
2. float (Decimales) - La caja verde 🟢
Guarda números con decimales:
altura = 1.75
precio = 19.99
temperatura = 36.5
pi = 3.14159
print(f"La altura es {altura} y su tipo es: {type(altura)}") # <class 'float'>
Ejemplos de uso:
- Precios
- Medidas (altura, peso, distancia)
- Porcentajes
- Constantes matemáticas
3. str (Cadenas de texto) - La caja amarilla 🟡
Guarda texto (siempre entre comillas):
nombre = "María"
apellido = 'González' # Comillas simples también funcionan
mensaje = "¡Hola, cómo estás!"
direccion = "Calle Falsa 123"
print(f"El nombre es {nombre} y su tipo es: {type(nombre)}") # <class 'str'>
Ejemplos de uso:
- Nombres y apellidos
- Direcciones
- Mensajes
- Cualquier texto
4. bool (Booleanos) - La caja roja
Guarda solo dos valores: True o False:
es_estudiante = True
tiene_trabajo = False
esta_casado = True
es_fin_semana = False
print(f"¿Es estudiante? {es_estudiante} - Tipo: {type(es_estudiante)}") # <class 'bool'>
Ejemplos de uso:
- Estados (encendido/apagado)
- Condiciones (sí/no)
- Permisos (permitido/no permitido)
- Cualquier cosa que sea verdadero o falso
5. NoneType - La caja vacía
Representa “nada” o “vacío”:
resultado = None
valor_inicial = None
print(f"El resultado es {resultado} y su tipo es: {type(resultado)}") # <class 'NoneType'>
Tipos Compuestos (Las estructuras construidas)
Nota del autor: En capítulos posteriores veremos en detalle estos tipos compuestos, pero quiero mencionarlos ahora para que tengas una visión completa.
Los tipos compuestos son combinaciones organizadas de tipos elementales. Es como usar nuestros ladrillos básicos para construir estructuras más complejas:
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#662113" d="M4 11v12.375c0 2.042 1.093 2.484 1.093 2.484l11.574 9.099C18.489 36.39 18 33.375 18 33.375V22L4 11z"/><path fill="#C1694F" d="M32 11v12.375c0 2.042-1.063 2.484-1.063 2.484s-9.767 7.667-11.588 9.099C17.526 36.39 18 33.375 18 33.375V22l14-11z"/><path fill="#D99E82" d="M19.289.5c-.753-.61-1.988-.61-2.742 0L4.565 10.029c-.754.61-.754 1.607 0 2.216l12.023 9.646c.754.609 1.989.609 2.743 0l12.104-9.73c.754-.609.754-1.606 0-2.216L19.289.5z"/><path fill="#D99E82" d="M18 35.75c-.552 0-1-.482-1-1.078V21.745c0-.596.448-1.078 1-1.078.553 0 1 .482 1 1.078v12.927c0 .596-.447 1.078-1 1.078z"/><path fill="#99AAB5" d="M28 18.836c0 1.104.104 1.646-1 2.442l-2.469 1.878c-1.104.797-1.531.113-1.531-.992v-2.961c0-.193-.026-.4-.278-.608C20.144 16.47 10.134 8.519 8.31 7.051l4.625-3.678c1.266.926 10.753 8.252 14.722 11.377.197.156.343.328.343.516v3.57z"/><path fill="#CCD6DD" d="M27.656 14.75C23.688 11.625 14.201 4.299 12.935 3.373l-1.721 1.368-2.904 2.31c1.825 1.468 11.834 9.419 14.412 11.544.151.125.217.25.248.371L27.903 15c-.06-.087-.146-.171-.247-.25z"/><path fill="#CCD6DD" d="M28 18.836v-3.57c0-.188-.146-.359-.344-.516-3.968-3.125-13.455-10.451-14.721-11.377l-2.073 1.649c3.393 2.669 12.481 9.681 14.86 11.573.256.204.278.415.278.608v4.836l1-.761c1.104-.797 1-1.338 1-2.442z"/><path fill="#E1E8ED" d="M27.656 14.75C23.688 11.625 14.201 4.299 12.935 3.373l-2.073 1.649c3.393 2.669 12.481 9.681 14.86 11.573.037.029.06.059.087.088L27.903 15c-.06-.087-.146-.171-.247-.25z"/></svg> Lista - colección ordenada y modificable
nombres = ["Ana", "Carlos", "Luis"] # Una caja con compartimentos
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#C1694F" d="M32 34c0 1.104-.896 2-2 2H6c-1.104 0-2-.896-2-2V7c0-1.104.896-2 2-2h24c1.104 0 2 .896 2 2v27z"/><path fill="#FFF" d="M29 32c0 .553-.447 1-1 1H8c-.552 0-1-.447-1-1V9c0-.552.448-1 1-1h20c.553 0 1 .448 1 1v23z"/><path fill="#CCD6DD" d="M25 3h-4c0-1.657-1.343-3-3-3s-3 1.343-3 3h-4c-1.104 0-2 .896-2 2v5h18V5c0-1.104-.896-2-2-2z"/><circle fill="#292F33" cx="18" cy="3" r="2"/><path fill="#99AAB5" d="M20 14c0 .552-.447 1-1 1h-9c-.552 0-1-.448-1-1s.448-1 1-1h9c.553 0 1 .448 1 1zm7 4c0 .552-.447 1-1 1H10c-.552 0-1-.448-1-1s.448-1 1-1h16c.553 0 1 .448 1 1zm0 4c0 .553-.447 1-1 1H10c-.552 0-1-.447-1-1 0-.553.448-1 1-1h16c.553 0 1 .447 1 1zm0 4c0 .553-.447 1-1 1H10c-.552 0-1-.447-1-1 0-.553.448-1 1-1h16c.553 0 1 .447 1 1zm0 4c0 .553-.447 1-1 1h-9c-.552 0-1-.447-1-1 0-.553.448-1 1-1h9c.553 0 1 .447 1 1z"/></svg> Tupla - colección ordenada e inmutable
coordenadas = (10.5, 20.8) # Una caja sellada
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#553788" d="M15 31c0 2.209-.791 4-3 4H5c-4 0-4-14 0-14h7c2.209 0 3 1.791 3 4v6z"/><path fill="#9266CC" d="M34 33h-1V23h1c.553 0 1-.447 1-1s-.447-1-1-1H10c-4 0-4 14 0 14h24c.553 0 1-.447 1-1s-.447-1-1-1z"/><path fill="#CCD6DD" d="M34.172 33H11c-2 0-2-10 0-10h23.172c1.104 0 1.104 10 0 10z"/><path fill="#99AAB5" d="M11.5 25h23.35c-.135-1.175-.36-2-.678-2H11c-1.651 0-1.938 6.808-.863 9.188C9.745 29.229 10.199 25 11.5 25z"/><path fill="#269" d="M12 8c0 2.209-1.791 4-4 4H4C0 12 0 1 4 1h4c2.209 0 4 1.791 4 4v3z"/><path fill="#55ACEE" d="M31 10h-1V3h1c.553 0 1-.447 1-1s-.447-1-1-1H7C3 1 3 12 7 12h24c.553 0 1-.447 1-1s-.447-1-1-1z"/><path fill="#CCD6DD" d="M31.172 10H8c-2 0-2-7 0-7h23.172c1.104 0 1.104 7 0 7z"/><path fill="#99AAB5" d="M8 5h23.925c-.114-1.125-.364-2-.753-2H8C6.807 3 6.331 5.489 6.562 7.5 6.718 6.142 7.193 5 8 5z"/><path fill="#F4900C" d="M20 17c0 2.209-1.791 4-4 4H6c-4 0-4-9 0-9h10c2.209 0 4 1.791 4 4v1z"/><path fill="#FFAC33" d="M35 19h-1v-5h1c.553 0 1-.447 1-1s-.447-1-1-1H15c-4 0-4 9 0 9h20c.553 0 1-.447 1-1s-.447-1-1-1z"/><path fill="#CCD6DD" d="M35.172 19H16c-2 0-2-5 0-5h19.172c1.104 0 1.104 5 0 5z"/><path fill="#99AAB5" d="M16 16h19.984c-.065-1.062-.334-2-.812-2H16c-1.274 0-1.733 2.027-1.383 3.5.198-.839.657-1.5 1.383-1.5z"/></svg> Diccionario - colección de pares clave-valor
persona = {"nombre": "Ana", "edad": 25} # Una caja con etiquetas internas
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><circle fill="#DD2E44" cx="18" cy="18" r="18"/><circle fill="#FFF" cx="18" cy="18" r="13.5"/><circle fill="#DD2E44" cx="18" cy="18" r="10"/><circle fill="#FFF" cx="18" cy="18" r="6"/><circle fill="#DD2E44" cx="18" cy="18" r="3"/><path opacity=".2" d="M18.24 18.282l13.144 11.754s-2.647 3.376-7.89 5.109L17.579 18.42l.661-.138z"/><path fill="#FFAC33" d="M18.294 19c-.255 0-.509-.097-.704-.292-.389-.389-.389-1.018 0-1.407l.563-.563c.389-.389 1.018-.389 1.408 0 .388.389.388 1.018 0 1.407l-.564.563c-.194.195-.448.292-.703.292z"/><path fill="#55ACEE" d="M24.016 6.981c-.403 2.079 0 4.691 0 4.691l7.054-7.388c.291-1.454-.528-3.932-1.718-4.238-1.19-.306-4.079.803-5.336 6.935zm5.003 5.003c-2.079.403-4.691 0-4.691 0l7.388-7.054c1.454-.291 3.932.528 4.238 1.718.306 1.19-.803 4.079-6.935 5.336z"/><path fill="#3A87C2" d="M32.798 4.485L21.176 17.587c-.362.362-1.673.882-2.51.046-.836-.836-.419-2.08-.057-2.443L31.815 3.501s.676-.635 1.159-.152-.176 1.136-.176 1.136z"/></svg> Conjunto - colección desordenada de elementos únicos
colores = {"rojo", "verde", "azul"} # Una caja que elimina duplicados
Intercambiando contenido entre cajas
Una de las cosas geniales de las variables es que puedes cambiar su contenido:
# Empezamos con una caja
mi_caja = "Hola"
print(f"Contenido inicial: {mi_caja}") # Hola
# Cambiamos el contenido de la misma caja
mi_caja = "Adiós"
print(f"Nuevo contenido: {mi_caja}") # Adiós
# Incluso podemos cambiar el tipo de contenido
mi_caja = 42
print(f"Contenido cambiado a número: {mi_caja}") # 42
mi_caja = True
print(f"Contenido cambiado a booleano: {mi_caja}") # True
Esto es como tomar la misma caja, vaciarla, y meter algo completamente diferente. En Python esto es posible porque es un lenguaje de tipado dinámico, lo que significa que una variable puede cambiar de tipo durante la ejecución del programa.
Comprueba tu comprensión: ¿Qué pasaría si intentas sumar
mi_caja + 10después de cada cambio de valor? ¿Funcionaría en todos los casos?
Ejemplo práctico: Perfil de usuario
Vamos a crear un programa que use diferentes tipos de cajas para guardar información de una persona:
# ================================
# INFORMACIÓN PERSONAL
# ================================
# Cajas de texto (str)
nombre = "Ana García"
apellido = "López"
email = "ana.garcia@email.com"
ciudad = "Ciudad de México"
# Cajas de números enteros (int)
edad = 28
año_nacimiento = 1995
numero_hijos = 2
# Cajas de números decimales (float)
altura = 1.65
peso = 58.5
salario = 25000.50
# Cajas de verdadero/falso (bool)
es_estudiante = False
tiene_trabajo = True
esta_casado = True
tiene_mascota = True
# ================================
# MOSTRAR INFORMACIÓN
# ================================
print("=== PERFIL DE USUARIO ===")
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#FFAC33" d="M28.84 17.638c-.987 1.044-1.633 3.067-1.438 4.493l.892 6.441c.197 1.427-.701 2.087-1.996 1.469l-5.851-2.796c-1.295-.62-3.408-.611-4.7.018l-5.826 2.842c-1.291.629-2.193-.026-2.007-1.452l.843-6.449c.186-1.427-.475-3.444-1.47-4.481l-4.494-4.688c-.996-1.037-.655-2.102.755-2.365l6.37-1.188c1.41-.263 3.116-1.518 3.793-2.789L16.762.956c.675-1.271 1.789-1.274 2.473-.009L22.33 6.66c.686 1.265 2.4 2.507 3.814 2.758l6.378 1.141c1.412.252 1.761 1.314.774 2.359l-4.456 4.72z"/><path fill="#FFD983" d="M9.783 2.181c1.023 1.413 2.446 4.917 1.717 5.447-.728.531-3.607-1.91-4.63-3.323-1.022-1.413-.935-2.668-.131-3.254.804-.587 2.02-.282 3.044 1.13zm19.348 2.124C28.109 5.718 25.23 8.16 24.5 7.627c-.729-.53.695-4.033 1.719-5.445C27.242.768 28.457.463 29.262 1.051c.803.586.89 1.841-.131 3.254zM16.625 33.291c-.001-1.746.898-5.421 1.801-5.421.897 0 1.798 3.675 1.797 5.42 0 1.747-.804 2.712-1.8 2.71-.994.002-1.798-.962-1.798-2.709zm16.179-9.262c-1.655-.539-4.858-2.533-4.579-3.395.277-.858 4.037-.581 5.69-.041 1.655.54 2.321 1.605 2.013 2.556-.308.95-1.469 1.42-3.124.88zM2.083 20.594c1.655-.54 5.414-.817 5.694.044.276.857-2.928 2.854-4.581 3.392-1.654.54-2.818.07-3.123-.88-.308-.95.354-2.015 2.01-2.556z"/></svg> Usando f-strings para mostrar información
print(f"Nombre completo: {nombre} {apellido}")
print(f"Email: {email}")
print(f"Ciudad: {ciudad}")
print()
print("=== DATOS PERSONALES ===")
print(f"Edad: {edad} años")
print(f"Año de nacimiento: {año_nacimiento}")
print(f"Altura: {altura} metros")
print(f"Peso: {peso} kg")
print()
print("=== ESTADO ACTUAL ===")
# Usando expresiones condicionales dentro de f-strings
print(f"Estudiante: {'✓ Sí' if es_estudiante else '✗ No'}")
print(f"Trabajo: {'✓ Sí' if tiene_trabajo else '✗ No'}")
if tiene_trabajo:
print(f"Salario: ${salario:,.2f} pesos") # Con formato de miles y 2 decimales
print(f"Estado civil: {'✓ Casado/a' if esta_casado else '✗ Soltero/a'}")
print(f"Mascota: {'✓ Sí' if tiene_mascota else '✗ No'}")
print(f"Número de hijos: {numero_hijos}")
# ================================
# CÁLCULOS CON VARIABLES
# ================================
print("\n=== CÁLCULOS ADICIONALES ===")
imc = peso / (altura ** 2)
print(f"Índice de Masa Corporal: {imc:.2f}")
años_trabajando = edad - 22 # Suponiendo que empezó a trabajar a los 22
print(f"Años aproximados trabajando: {años_trabajando}")
salario_anual = salario * 12
print(f"Salario anual estimado: ${salario_anual:,.2f} pesos")
Comprueba tu comprensión: ¿Cómo modificarías este programa para incluir información sobre estudios universitarios? ¿Qué variables añadirías y de qué tipo serían?
Reglas para nombrar cajas (variables)
Así como no puedes poner cualquier etiqueta en una caja, Python tiene reglas para nombrar variables:
Nombres válidos:
nombre = "Juan"
edad_usuario = 25
mi_variable = 100
_variable_privada = "secreto"
variable2 = "segunda"
CONSTANTE = 3.14159
Nombres inválidos:
2nombre = "Juan" # No puede empezar con número
mi-variable = 100 # No puede tener guiones
mi variable = 100 # No puede tener espacios
if = 25 # No puede ser palabra reservada
Buenas prácticas para nombres:
1. Usa nombres descriptivos
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#77B255" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V4c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v28z"/><path fill="#FFF" d="M29.28 6.362c-1.156-.751-2.704-.422-3.458.736L14.936 23.877l-5.029-4.65c-1.014-.938-2.596-.875-3.533.138-.937 1.014-.875 2.596.139 3.533l7.209 6.666c.48.445 1.09.665 1.696.665.673 0 1.534-.282 2.099-1.139.332-.506 12.5-19.27 12.5-19.27.751-1.159.421-2.707-.737-3.458z"/></svg> BUENO - se entiende qué contiene
nombre_usuario = "Ana"
edad_en_años = 25
precio_producto = 19.99
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> MALO - no se entiende qué es
n = "Ana"
x = 25
p = 19.99
2. Usa snake_case (guiones bajos)
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#77B255" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V4c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v28z"/><path fill="#FFF" d="M29.28 6.362c-1.156-.751-2.704-.422-3.458.736L14.936 23.877l-5.029-4.65c-1.014-.938-2.596-.875-3.533.138-.937 1.014-.875 2.596.139 3.533l7.209 6.666c.48.445 1.09.665 1.696.665.673 0 1.534-.282 2.099-1.139.332-.506 12.5-19.27 12.5-19.27.751-1.159.421-2.707-.737-3.458z"/></svg> BUENO - estilo Python
nombre_completo = "Ana García"
fecha_nacimiento = "1995-05-15"
es_mayor_edad = True
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> MALO - no es el estilo de Python
nombreCompleto = "Ana García" # camelCase
NombreCompleto = "Ana García" # PascalCase
3. Sé consistente
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#77B255" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V4c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v28z"/><path fill="#FFF" d="M29.28 6.362c-1.156-.751-2.704-.422-3.458.736L14.936 23.877l-5.029-4.65c-1.014-.938-2.596-.875-3.533.138-.937 1.014-.875 2.596.139 3.533l7.209 6.666c.48.445 1.09.665 1.696.665.673 0 1.534-.282 2.099-1.139.332-.506 12.5-19.27 12.5-19.27.751-1.159.421-2.707-.737-3.458z"/></svg> BUENO - mismo patrón
nombre_usuario = "Ana"
apellido_usuario = "García"
email_usuario = "ana@email.com"
# <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> MALO - patrones mezclados
nombre_usuario = "Ana"
apellidoUsuario = "García"
EMAIL = "ana@email.com"
Nota del autor: Después de años programando, he aprendido que el tiempo que inviertes en nombrar bien tus variables se recupera con creces cuando tienes que revisar o modificar tu código semanas o meses después. Un buen nombre de variable es como una buena señalización en una carretera: te dice exactamente dónde estás y hacia dónde vas.
Viendo qué hay dentro de las cajas
Python te permite “espiar” dentro de las cajas para ver qué tipo de contenido tienen usando la función type():
# Crear diferentes tipos de cajas
numero = 42
texto = "Hola"
decimal = 3.14
verdadero = True
# Ver qué tipo de caja es cada una
print(f"numero es tipo: {type(numero)}") # <class 'int'>
print(f"texto es tipo: {type(texto)}") # <class 'str'>
print(f"decimal es tipo: {type(decimal)}") # <class 'float'>
print(f"verdadero es tipo: {type(verdadero)}") # <class 'bool'>
Es como tener una máquina de rayos X que te permite ver qué tipo de contenido hay dentro de cada caja sin tener que abrirla.
Ejercicio práctico: Tu información personal
Vamos a crear un programa que use la analogía de las cajas para guardar tu información:
# ================================
# EJERCICIO: MIS CAJAS PERSONALES
# ================================
print("=== CREANDO MIS CAJAS DE INFORMACIÓN ===")
print()
# Caja amarilla para tu nombre
mi_nombre = "Tu nombre aquí"
print(f"<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#662113" d="M4 11v12.375c0 2.042 1.093 2.484 1.093 2.484l11.574 9.099C18.489 36.39 18 33.375 18 33.375V22L4 11z"/><path fill="#C1694F" d="M32 11v12.375c0 2.042-1.063 2.484-1.063 2.484s-9.767 7.667-11.588 9.099C17.526 36.39 18 33.375 18 33.375V22l14-11z"/><path fill="#D99E82" d="M19.289.5c-.753-.61-1.988-.61-2.742 0L4.565 10.029c-.754.61-.754 1.607 0 2.216l12.023 9.646c.754.609 1.989.609 2.743 0l12.104-9.73c.754-.609.754-1.606 0-2.216L19.289.5z"/><path fill="#D99E82" d="M18 35.75c-.552 0-1-.482-1-1.078V21.745c0-.596.448-1.078 1-1.078.553 0 1 .482 1 1.078v12.927c0 .596-.447 1.078-1 1.078z"/><path fill="#99AAB5" d="M28 18.836c0 1.104.104 1.646-1 2.442l-2.469 1.878c-1.104.797-1.531.113-1.531-.992v-2.961c0-.193-.026-.4-.278-.608C20.144 16.47 10.134 8.519 8.31 7.051l4.625-3.678c1.266.926 10.753 8.252 14.722 11.377.197.156.343.328.343.516v3.57z"/><path fill="#CCD6DD" d="M27.656 14.75C23.688 11.625 14.201 4.299 12.935 3.373l-1.721 1.368-2.904 2.31c1.825 1.468 11.834 9.419 14.412 11.544.151.125.217.25.248.371L27.903 15c-.06-.087-.146-.171-.247-.25z"/><path fill="#CCD6DD" d="M28 18.836v-3.57c0-.188-.146-.359-.344-.516-3.968-3.125-13.455-10.451-14.721-11.377l-2.073 1.649c3.393 2.669 12.481 9.681 14.86 11.573.256.204.278.415.278.608v4.836l1-.761c1.104-.797 1-1.338 1-2.442z"/><path fill="#E1E8ED" d="M27.656 14.75C23.688 11.625 14.201 4.299 12.935 3.373l-2.073 1.649c3.393 2.669 12.481 9.681 14.86 11.573.037.029.06.059.087.088L27.903 15c-.06-.087-.146-.171-.247-.25z"/></svg> Caja amarilla (texto): {mi_nombre}")
# Caja azul para tu edad
mi_edad = 25 # Cambia por tu edad real
print(f"<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#662113" d="M4 11v12.375c0 2.042 1.093 2.484 1.093 2.484l11.574 9.099C18.489 36.39 18 33.375 18 33.375V22L4 11z"/><path fill="#C1694F" d="M32 11v12.375c0 2.042-1.063 2.484-1.063 2.484s-9.767 7.667-11.588 9.099C17.526 36.39 18 33.375 18 33.375V22l14-11z"/><path fill="#D99E82" d="M19.289.5c-.753-.61-1.988-.61-2.742 0L4.565 10.029c-.754.61-.754 1.607 0 2.216l12.023 9.646c.754.609 1.989.609 2.743 0l12.104-9.73c.754-.609.754-1.606 0-2.216L19.289.5z"/><path fill="#D99E82" d="M18 35.75c-.552 0-1-.482-1-1.078V21.745c0-.596.448-1.078 1-1.078.553 0 1 .482 1 1.078v12.927c0 .596-.447 1.078-1 1.078z"/><path fill="#99AAB5" d="M28 18.836c0 1.104.104 1.646-1 2.442l-2.469 1.878c-1.104.797-1.531.113-1.531-.992v-2.961c0-.193-.026-.4-.278-.608C20.144 16.47 10.134 8.519 8.31 7.051l4.625-3.678c1.266.926 10.753 8.252 14.722 11.377.197.156.343.328.343.516v3.57z"/><path fill="#CCD6DD" d="M27.656 14.75C23.688 11.625 14.201 4.299 12.935 3.373l-1.721 1.368-2.904 2.31c1.825 1.468 11.834 9.419 14.412 11.544.151.125.217.25.248.371L27.903 15c-.06-.087-.146-.171-.247-.25z"/><path fill="#CCD6DD" d="M28 18.836v-3.57c0-.188-.146-.359-.344-.516-3.968-3.125-13.455-10.451-14.721-11.377l-2.073 1.649c3.393 2.669 12.481 9.681 14.86 11.573.256.204.278.415.278.608v4.836l1-.761c1.104-.797 1-1.338 1-2.442z"/><path fill="#E1E8ED" d="M27.656 14.75C23.688 11.625 14.201 4.299 12.935 3.373l-2.073 1.649c3.393 2.669 12.481 9.681 14.86 11.573.037.029.06.059.087.088L27.903 15c-.06-.087-.146-.171-.247-.25z"/></svg> Caja azul (número entero): {mi_edad}")
# Caja verde para tu altura
mi_altura = 1.70 # Cambia por tu altura real
print(f"<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#662113" d="M4 11v12.375c0 2.042 1.093 2.484 1.093 2.484l11.574 9.099C18.489 36.39 18 33.375 18 33.375V22L4 11z"/><path fill="#C1694F" d="M32 11v12.375c0 2.042-1.063 2.484-1.063 2.484s-9.767 7.667-11.588 9.099C17.526 36.39 18 33.375 18 33.375V22l14-11z"/><path fill="#D99E82" d="M19.289.5c-.753-.61-1.988-.61-2.742 0L4.565 10.029c-.754.61-.754 1.607 0 2.216l12.023 9.646c.754.609 1.989.609 2.743 0l12.104-9.73c.754-.609.754-1.606 0-2.216L19.289.5z"/><path fill="#D99E82" d="M18 35.75c-.552 0-1-.482-1-1.078V21.745c0-.596.448-1.078 1-1.078.553 0 1 .482 1 1.078v12.927c0 .596-.447 1.078-1 1.078z"/><path fill="#99AAB5" d="M28 18.836c0 1.104.104 1.646-1 2.442l-2.469 1.878c-1.104.797-1.531.113-1.531-.992v-2.961c0-.193-.026-.4-.278-.608C20.144 16.47 10.134 8.519 8.31 7.051l4.625-3.678c1.266.926 10.753 8.252 14.722 11.377.197.156.343.328.343.516v3.57z"/><path fill="#CCD6DD" d="M27.656 14.75C23.688 11.625 14.201 4.299 12.935 3.373l-1.721 1.368-2.904 2.31c1.825 1.468 11.834 9.419 14.412 11.544.151.125.217.25.248.371L27.903 15c-.06-.087-.146-.171-.247-.25z"/><path fill="#CCD6DD" d="M28 18.836v-3.57c0-.188-.146-.359-.344-.516-3.968-3.125-13.455-10.451-14.721-11.377l-2.073 1.649c3.393 2.669 12.481 9.681 14.86 11.573.256.204.278.415.278.608v4.836l1-.761c1.104-.797 1-1.338 1-2.442z"/><path fill="#E1E8ED" d="M27.656 14.75C23.688 11.625 14.201 4.299 12.935 3.373l-2.073 1.649c3.393 2.669 12.481 9.681 14.86 11.573.037.029.06.059.087.088L27.903 15c-.06-.087-.146-.171-.247-.25z"/></svg> Caja verde (número decimal): {mi_altura}")
# Caja roja para si eres estudiante
soy_estudiante = True # Cambia por tu situación real
print(f"<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#662113" d="M4 11v12.375c0 2.042 1.093 2.484 1.093 2.484l11.574 9.099C18.489 36.39 18 33.375 18 33.375V22L4 11z"/><path fill="#C1694F" d="M32 11v12.375c0 2.042-1.063 2.484-1.063 2.484s-9.767 7.667-11.588 9.099C17.526 36.39 18 33.375 18 33.375V22l14-11z"/><path fill="#D99E82" d="M19.289.5c-.753-.61-1.988-.61-2.742 0L4.565 10.029c-.754.61-.754 1.607 0 2.216l12.023 9.646c.754.609 1.989.609 2.743 0l12.104-9.73c.754-.609.754-1.606 0-2.216L19.289.5z"/><path fill="#D99E82" d="M18 35.75c-.552 0-1-.482-1-1.078V21.745c0-.596.448-1.078 1-1.078.553 0 1 .482 1 1.078v12.927c0 .596-.447 1.078-1 1.078z"/><path fill="#99AAB5" d="M28 18.836c0 1.104.104 1.646-1 2.442l-2.469 1.878c-1.104.797-1.531.113-1.531-.992v-2.961c0-.193-.026-.4-.278-.608C20.144 16.47 10.134 8.519 8.31 7.051l4.625-3.678c1.266.926 10.753 8.252 14.722 11.377.197.156.343.328.343.516v3.57z"/><path fill="#CCD6DD" d="M27.656 14.75C23.688 11.625 14.201 4.299 12.935 3.373l-1.721 1.368-2.904 2.31c1.825 1.468 11.834 9.419 14.412 11.544.151.125.217.25.248.371L27.903 15c-.06-.087-.146-.171-.247-.25z"/><path fill="#CCD6DD" d="M28 18.836v-3.57c0-.188-.146-.359-.344-.516-3.968-3.125-13.455-10.451-14.721-11.377l-2.073 1.649c3.393 2.669 12.481 9.681 14.86 11.573.256.204.278.415.278.608v4.836l1-.761c1.104-.797 1-1.338 1-2.442z"/><path fill="#E1E8ED" d="M27.656 14.75C23.688 11.625 14.201 4.299 12.935 3.373l-2.073 1.649c3.393 2.669 12.481 9.681 14.86 11.573.037.029.06.059.087.088L27.903 15c-.06-.087-.146-.171-.247-.25z"/></svg> Caja roja (verdadero/falso): {soy_estudiante}")
print()
print("=== INFORMACIÓN DE MIS CAJAS ===")
print(f"Nombre: {mi_nombre} - Tipo: {type(mi_nombre)}")
print(f"Edad: {mi_edad} - Tipo: {type(mi_edad)}")
print(f"Altura: {mi_altura} - Tipo: {type(mi_altura)}")
print(f"Estudiante: {soy_estudiante} - Tipo: {type(soy_estudiante)}")
# Añadamos algunos cálculos
print("\n=== CÁLCULOS CON MIS DATOS ===")
edad_en_meses = mi_edad * 12
print(f"Mi edad en meses: {edad_en_meses}")
altura_en_cm = mi_altura * 100
print(f"Mi altura en centímetros: {altura_en_cm}")
años_hasta_jubilacion = 65 - mi_edad
print(f"Años hasta la jubilación: {años_hasta_jubilacion}")
Tu tarea:
- Copia este código
- Cambia los valores por tu información real
- Ejecuta el programa
- Añade al menos 3 variables más con diferentes tipos de datos
- Crea al menos 2 cálculos adicionales usando tus variables
Desafío adicional: Intenta crear una variable que combine información de otras variables. Por ejemplo, una variable
presentacionque contenga un texto que use tu nombre y edad.
Intercambiando cajas
Una cosa interesante es que puedes tomar el contenido de una caja y ponerlo en otra:
# Crear las cajas originales
caja_a = "Hola"
caja_b = "Mundo"
print("Antes del intercambio:")
print(f"Caja A: {caja_a}")
print(f"Caja B: {caja_b}")
# Intercambiar contenido (necesitamos una caja temporal)
caja_temporal = caja_a # Guardamos el contenido de A
caja_a = caja_b # Ponemos el contenido de B en A
caja_b = caja_temporal # Ponemos el contenido temporal en B
print("Después del intercambio:")
print(f"Caja A: {caja_a}")
print(f"Caja B: {caja_b}")
En Python hay una forma más fácil y elegante:
# Intercambio fácil en Python
caja_a, caja_b = caja_b, caja_a
¡Es como si Python fuera un mago que puede intercambiar el contenido de las cajas instantáneamente! Esta es una característica especial de Python que no todos los lenguajes de programación tienen.
Comprueba tu comprensión: ¿Qué pasaría si intentas intercambiar tres variables a la vez? Por ejemplo:
a, b, c = c, a, b. ¿Cuáles serían los valores finales?
Resumen del capítulo
En este capítulo aprendiste:
- Variables son como cajas que guardan información
- Los tipos elementales son los ladrillos básicos (int, float, str, bool, None)
- Los tipos compuestos son estructuras construidas con tipos elementales
- Puedes cambiar el contenido de las cajas en cualquier momento
- Reglas para nombrar las cajas (variables) en Python
- Buenas prácticas para nombres descriptivos y consistentes
- Cómo ver el tipo de contenido con
type() - Cómo usar f-strings para mostrar variables en texto
¿Qué sigue?
En el siguiente capítulo vamos a aprender sobre conversión de tipos. Descubrirás:
- Cómo cambiar el contenido de una caja azul (int) a una caja verde (float)
- Cómo convertir números a texto y viceversa
- Qué pasa cuando intentas mezclar diferentes tipos de cajas
- Trucos para trabajar con diferentes tipos de datos
- Más sobre f-strings y formateo de texto
¡Ya tienes tus cajas organizadas, ahora vamos a aprender a transformar su contenido! ➡️
Consejo del capítulo: Piensa siempre en las variables como cajas etiquetadas y en los tipos de datos como materiales de construcción. Los tipos elementales son tus ladrillos básicos, y con ellos construirás estructuras más complejas (tipos compuestos) en los próximos capítulos. Esta forma de pensar te ayudará a entender conceptos más avanzados como listas (cajas con compartimentos) y diccionarios (cajas con etiquetas internas). ¡La programación es como organizar y construir en un almacén gigante!
Concepto de Variables
Imagínate que eres el encargado de un almacén gigante. Tienes miles de cajas de diferentes tamaños, colores y formas. Cada caja puede guardar algo específico, y cada una tiene una etiqueta para saber qué contiene. Eso es exactamente lo que son las variables en programación.
¿Qué es una variable?
💭 Nota del autor: Cuando enseño programación, siempre empiezo con esta analogía del almacén porque hace que un concepto abstracto como las “variables” se vuelva algo que puedes visualizar. Verás que esta analogía nos seguirá ayudando cuando lleguemos a conceptos más complejos.
Una variable es como una caja etiquetada en la memoria de tu computadora donde puedes guardar información para usarla después. Es uno de los conceptos más fundamentales en programación, y por suerte, es bastante intuitivo.
La analogía completa del almacén:
# Tu computadora es como un almacén gigante
# Las variables son las cajas etiquetadas
# Los valores son lo que guardas dentro de cada caja
nombre = "Ana" # Caja etiquetada "nombre" con "Ana" adentro
edad = 25 # Caja etiquetada "edad" con 25 adentro
altura = 1.65 # Caja etiquetada "altura" con 1.65 adentro
es_estudiante = True # Caja etiquetada "es_estudiante" con True adentro
¿Ves lo que estamos haciendo? Estamos creando cajas con etiquetas (nombres de variables) y guardando diferentes tipos de información dentro de ellas.
¿Por qué necesitamos variables?
Déjame mostrarte por qué las variables son tan importantes con un ejemplo sencillo:
Sin variables (muy difícil):
print("Hola, mi nombre es Ana")
print("Ana tiene 25 años")
print("Ana mide 1.65 metros")
print("Ana es estudiante")
print("El año que viene Ana tendrá 26 años")
¿Qué pasa si quieres cambiar “Ana” por “Carlos”? ¡Tienes que cambiar 5 líneas! Imagina si tu programa tuviera cientos de líneas… sería un desastre.
Con variables (mucho mejor):
# Creamos nuestras "cajas"
nombre = "Ana"
edad = 25
altura = 1.65
es_estudiante = True
# Usamos las cajas
# 🌟 Usando f-strings (recomendado)
print(f"Hola, mi nombre es {nombre}")
print(f"{nombre} tiene {edad} años")
print(f"{nombre} mide {altura} metros")
print(f"{nombre} es estudiante: {es_estudiante}")
print(f"El año que viene {nombre} tendrá {edad + 1} años")
Ahora, si quieres cambiar “Ana” por “Carlos”, ¡solo cambias una línea! Esto hace que tu código sea mucho más fácil de mantener y modificar.
Anatomía de una variable
Cada variable tiene tres partes principales:
1. Nombre (la etiqueta de la caja)
nombre = "Ana"
# ↑
# Esta es la etiqueta
El nombre es como la etiqueta que le pones a tu caja. Debe ser descriptivo para que sepas qué hay dentro sin tener que abrirla.
2. Operador de asignación (el signo =)
nombre = "Ana"
# ↑
# Esto significa "guardar en"
El signo igual (=) en programación no significa “igual que” como en matemáticas. Significa “guarda el valor de la derecha en la variable de la izquierda”.
3. Valor (el contenido de la caja)
nombre = "Ana"
# ↑
# Esto es lo que guardamos
El valor es lo que realmente estás guardando en la caja. Puede ser texto, números, valores verdadero/falso, y muchas otras cosas que veremos más adelante.
Tipos de cajas en nuestro almacén
💭 Nota del autor: Como mencioné en la sección de tipos de datos, me gusta pensar en los tipos de datos como elementales (básicos) y compuestos. Aquí nos enfocaremos en los tipos elementales, que son como los ladrillos básicos con los que construiremos estructuras más complejas después.
En nuestro almacén de variables, tenemos diferentes tipos de cajas para diferentes tipos de cosas:
🔵 Cajas azules (números enteros - int)
# Estas cajas solo guardan números sin decimales
edad = 25
año = 2024
puntos = 1500
temperatura = -5
# Son perfectas para:
# - Edades
# - Años
# - Cantidades exactas
# - Puntuaciones
🟢 Cajas verdes (números decimales - float)
# Estas cajas guardan números con decimales
altura = 1.75
precio = 29.99
temperatura = 36.5
porcentaje = 85.7
# Son perfectas para:
# - Medidas
# - Precios
# - Temperaturas
# - Porcentajes
🟡 Cajas amarillas (texto - str)
# Estas cajas guardan texto (siempre entre comillas)
nombre = "Ana García"
mensaje = "¡Hola mundo!"
email = "ana@email.com"
direccion = "Calle Falsa 123"
# Son perfectas para:
# - Nombres
# - Mensajes
# - Direcciones
# - Cualquier texto
🔴 Cajas rojas (verdadero/falso - bool)
# Estas cajas solo guardan True o False
es_estudiante = True
tiene_trabajo = False
esta_casado = True
es_fin_semana = False
# Son perfectas para:
# - Estados (sí/no)
# - Condiciones
# - Permisos
# - Cualquier cosa que sea verdadero o falso
Creando y usando variables
Vamos a ver cómo trabajar con estas cajas paso a paso:
Paso 1: Crear la caja
# Sintaxis: nombre_de_la_caja = contenido
mi_nombre = "Tu nombre aquí"
Es como tomar una caja del almacén, ponerle una etiqueta que dice “mi_nombre”, y meter dentro el texto “Tu nombre aquí”.
Paso 2: Usar la caja
mi_nombre = "Ana"
# 🌟 Con f-string (recomendado)
print(f"Hola, {mi_nombre}") # Hola, Ana
print(f"¿Cómo estás, {mi_nombre}?") # ¿Cómo estás, Ana?
# También puedes usar concatenación
print("Hola, " + mi_nombre) # Hola, Ana
Paso 3: Cambiar el contenido de la caja
mi_nombre = "Ana"
print(f"Nombre inicial: {mi_nombre}") # Ana
# Cambiar el contenido
mi_nombre = "Carlos"
print(f"Nombre actualizado: {mi_nombre}") # Carlos
Es como vaciar la caja y meter algo nuevo. ¡Así de simple!
Ejemplo práctico: Organizando información de una tienda
Imagínate que tienes una tienda y necesitas organizar información de productos. Las variables te ayudan a mantener todo ordenado:
# ================================
# INFORMACIÓN DEL PRODUCTO
# ================================
# Cajas amarillas (texto)
nombre_producto = "Laptop Gaming"
marca = "TechPro"
modelo = "X1-2024"
descripcion = "Laptop para gaming de alta gama"
# Cajas azules (números enteros)
cantidad_stock = 15
año_lanzamiento = 2024
garantia_meses = 24
# Cajas verdes (números decimales)
precio = 25999.99
peso_kg = 2.5
pantalla_pulgadas = 15.6
# Cajas rojas (verdadero/falso)
esta_disponible = True
es_nuevo = True
incluye_mouse = False
tiene_descuento = True
# ================================
# MOSTRAR INFORMACIÓN
# ================================
print("=== INFORMACIÓN DEL PRODUCTO ===")
# 🌟 Usando f-strings para mostrar información
print(f"Producto: {nombre_producto}")
print(f"Marca: {marca}")
print(f"Modelo: {modelo}")
print(f"Descripción: {descripcion}")
print()
print("=== ESPECIFICACIONES ===")
print(f"Precio: ${precio:,.2f}") # Formato con separador de miles y 2 decimales
print(f"Peso: {peso_kg} kg")
print(f"Pantalla: {pantalla_pulgadas} pulgadas")
print(f"Año de lanzamiento: {año_lanzamiento}")
print(f"Garantía: {garantia_meses} meses")
print()
print("=== DISPONIBILIDAD ===")
print(f"En stock: {cantidad_stock} unidades")
print(f"Disponible: {'Sí' if esta_disponible else 'No'}") # Expresión condicional
print(f"Producto nuevo: {'Sí' if es_nuevo else 'No'}")
print(f"Incluye mouse: {'Sí' if incluye_mouse else 'No'}")
print(f"Tiene descuento: {'Sí' if tiene_descuento else 'No'}")
💡 Comprueba tu comprensión: ¿Qué pasaría si necesitaras cambiar el precio del producto? ¿Cuántas líneas tendrías que modificar? ¿Y si quisieras añadir un 10% de descuento al precio?
Variables que cambian de contenido
Una de las cosas más útiles de las variables es que puedes cambiar su contenido a medida que tu programa se ejecuta:
# Empezamos con una caja
puntos_juego = 0
print(f"Puntos iniciales: {puntos_juego}") # 0
# El jugador gana puntos
puntos_juego = 100
print(f"Después del primer nivel: {puntos_juego}") # 100
# Gana más puntos
puntos_juego = puntos_juego + 150 # También podemos escribir: puntos_juego += 150
print(f"Después del segundo nivel: {puntos_juego}") # 250
# Pierde puntos
puntos_juego = puntos_juego - 50 # También podemos escribir: puntos_juego -= 50
print(f"Después de perder una vida: {puntos_juego}") # 200
💡 Comprueba tu comprensión: ¿Qué valor tendría
puntos_juegosi después añadimospuntos_juego *= 2? ¿Y si luego añadimospuntos_juego /= 4?
Copiando contenido entre cajas
Puedes tomar el contenido de una caja y copiarlo a otra:
# Caja original
nombre_original = "Ana"
# Copiar el contenido a otra caja
nombre_copia = nombre_original
print(f"Original: {nombre_original}") # Ana
print(f"Copia: {nombre_copia}") # Ana
# Si cambias la copia, el original no se afecta
nombre_copia = "Carlos"
print(f"Original: {nombre_original}") # Ana (no cambió)
print(f"Copia: {nombre_copia}") # Carlos
Esto es importante porque demuestra que cada variable es independiente. Cuando copias el valor, estás creando una nueva caja con el mismo contenido, no vinculando las dos cajas.
Usando variables en operaciones
Las variables son especialmente útiles cuando haces cálculos:
# Información de un rectángulo
largo = 10
ancho = 5
# Calcular área usando las variables
area = largo * ancho
print(f"El área es: {area} unidades cuadradas") # 50
# Calcular perímetro
perimetro = 2 * (largo + ancho)
print(f"El perímetro es: {perimetro} unidades") # 30
# Si cambias las dimensiones, todos los cálculos se actualizan
largo = 15
ancho = 8
# Recalculamos con los nuevos valores
area = largo * ancho
perimetro = 2 * (largo + ancho)
print(f"Nueva área: {area} unidades cuadradas") # 120
print(f"Nuevo perímetro: {perimetro} unidades") # 46
💡 Comprueba tu comprensión: ¿Qué pasaría si definiéramos una nueva variable
altura = 3y quisiéramos calcular el volumen del prisma rectangular? ¿Cómo lo harías?
Ejercicio práctico: Tu almacén personal
Vamos a crear un programa que simule tu almacén personal de información. Copia este código y personalízalo con tu información:
# ================================
# MI ALMACÉN PERSONAL DE VARIABLES
# ================================
print("=== ORGANIZANDO MI ALMACÉN ===")
print()
# Caja 1: Información básica
print("📦 Creando caja amarilla para mi nombre...")
mi_nombre = "Tu nombre aquí" # Cambia esto por tu nombre
print(f" Contenido: {mi_nombre}")
print("📦 Creando caja azul para mi edad...")
mi_edad = 25 # Cambia por tu edad
print(f" Contenido: {mi_edad}")
print("📦 Creando caja verde para mi altura...")
mi_altura = 1.70 # Cambia por tu altura
print(f" Contenido: {mi_altura}")
print("📦 Creando caja roja para si tengo mascota...")
tengo_mascota = True # Cambia según tu situación
print(f" Contenido: {tengo_mascota}")
print()
print("=== INVENTARIO DE MI ALMACÉN ===")
print(f"Nombre: {mi_nombre} - Tipo de caja: {type(mi_nombre)}")
print(f"Edad: {mi_edad} - Tipo de caja: {type(mi_edad)}")
print(f"Altura: {mi_altura} - Tipo de caja: {type(mi_altura)}")
print(f"Tengo mascota: {tengo_mascota} - Tipo de caja: {type(tengo_mascota)}")
print()
print("=== USANDO EL CONTENIDO DE MIS CAJAS ===")
print(f"Hola, soy {mi_nombre}")
print(f"Tengo {mi_edad} años y mido {mi_altura} metros")
if tengo_mascota:
print("¡Y tengo una mascota!")
else:
print("No tengo mascota, pero me gustaría tener una.")
# Calculando con las cajas
edad_en_meses = mi_edad * 12
print(f"Mi edad en meses es aproximadamente: {edad_en_meses}")
# Calculando edad en días (aproximado)
edad_en_dias = mi_edad * 365
print(f"He vivido aproximadamente {edad_en_dias:,} días") # Con formato de miles
💡 Desafío: Añade más variables a tu almacén personal. Por ejemplo, tu película favorita, tu peso, si te gusta programar, etc. Luego, crea algunos cálculos interesantes con esas variables.
Errores comunes con variables
Cuando trabajas con variables, hay algunos errores comunes que debes evitar:
1. Usar una variable antes de crearla
# ❌ ERROR
print(nombre) # Error: name 'nombre' is not defined
nombre = "Ana"
# ✅ CORRECTO
nombre = "Ana"
print(nombre)
Python lee tu código de arriba hacia abajo, así que debes crear la caja antes de intentar ver qué hay dentro.
2. Confundir el nombre con el contenido
# ❌ ERROR - intentar usar el contenido como nombre
"Ana" = 25 # Error: can't assign to literal
# ✅ CORRECTO - el nombre va a la izquierda
nombre = "Ana"
edad = 25
Recuerda: la etiqueta (nombre de la variable) siempre va a la izquierda del signo igual.
3. Olvidar las comillas en texto
# ❌ ERROR
nombre = Ana # Error: name 'Ana' is not defined
# ✅ CORRECTO
nombre = "Ana" # o 'Ana'
Sin comillas, Python piensa que Ana es otra variable, no un texto.
Consejos para organizar tu almacén
Después de años programando, he aprendido algunos trucos para mantener mi “almacén” de variables bien organizado:
1. Agrupa variables relacionadas
# Información de una persona
nombre = "Ana"
apellido = "García"
edad = 25
email = "ana@email.com"
# Información de un producto (separado claramente)
producto_nombre = "Laptop"
producto_precio = 15000
producto_stock = 10
2. Usa nombres que expliquen el contenido
# ✅ BUENO - nombres descriptivos
precio_producto = 100
edad_usuario = 25
nombre_completo = "Ana García"
# ❌ MALO - nombres confusos
p = 100 # ¿p de precio? ¿de peso? ¿de puntos?
x = 25 # ¿qué representa x?
n = "Ana García" # ¿n de nombre? ¿de...?
3. Mantén un orden lógico
# ✅ BUENO - primero las variables, luego los cálculos
base = 10
altura = 5
area = base * altura
# ❌ MALO - todo mezclado
base = 10
area = base * altura # ¿altura? Aún no existe
altura = 5
💡 Consejo personal: Yo siempre comento mis variables cuando trabajo en proyectos grandes. Por ejemplo:
total_ventas = 0 # Acumulador para ventas del día. Esto me ayuda a recordar para qué sirve cada variable cuando reviso mi código semanas después.
Resumen
Las variables son como cajas etiquetadas en el almacén de la memoria de tu computadora:
- ✅ Cada caja tiene un nombre (etiqueta) que debe ser descriptivo
- ✅ Cada caja guarda un valor (contenido) de un tipo específico
- ✅ Puedes cambiar el contenido cuando quieras, pero el tipo puede cambiar
- ✅ Hay diferentes tipos de cajas para diferentes tipos de contenido
- ✅ Usar variables hace tu código más fácil de leer y mantener
En la siguiente sección vamos a explorar en detalle los diferentes tipos de cajas (tipos de datos) que puedes usar en tu almacén de variables.
💡 Recuerda: Cada vez que creas una variable, estás organizando mejor tu almacén de información. Un almacén bien organizado (código con buenas variables) es fácil de encontrar lo que necesitas y hacer cambios cuando sea necesario. ¡La organización es la clave del éxito en programación!
Tipos de Datos Básicos
En nuestro almacén de variables, no todas las cajas son iguales. Cada tipo de caja está diseñada para guardar un tipo específico de información. ¡Vamos a conocer todas las cajas disponibles en Python!
🧱 Una perspectiva personal: Tipos elementales vs compuestos
💭 Nota del autor: Esta es mi perspectiva personal para entender mejor los tipos de datos. No es una definición oficial de Python, pero me ha ayudado mucho a organizar conceptos y espero que te sea útil también.
Desde mi experiencia enseñando Python, me gusta pensar en los tipos de datos como si fueran materiales de construcción en nuestro almacén:
🧱 Tipos Elementales (Los ladrillos básicos)
Son los componentes fundamentales que no se pueden descomponer más. Son como los ladrillos individuales con los que construimos todo lo demás:
- 🔵 int (números enteros):
25,-10,1000 - 🟢 float (números decimales):
3.14,19.99,-2.5 - 🟡 str (texto):
"Ana","Hola mundo","123" - 🔴 bool (verdadero/falso):
True,False - ⚪ None (ausencia de valor):
None
🏗️ Tipos Compuestos (Las estructuras construidas)
Son combinaciones organizadas de tipos elementales. Es como usar nuestros ladrillos básicos para construir estructuras más complejas:
- 📦 Listas:
[25, 30, 35](varios int juntos) - 📋 Tuplas:
("Ana", 25, True)(str, int, bool combinados) - 📚 Diccionarios:
{"nombre": "Ana", "edad": 25}(str como claves, varios tipos como valores) - 🎯 Conjuntos:
{1, 2, 3, 4}(int únicos agrupados)
🔧 La magia de la composición
Lo interesante es que puedes “crear” tipos compuestos usando combinaciones de tipos elementales:
# Tipos elementales (ladrillos básicos)
nombre = "Ana García" # 🟡 str
edad = 28 # 🔵 int
altura = 1.65 # 🟢 float
es_estudiante = True # 🔴 bool
# Tipos compuestos (estructuras construidas con los ladrillos)
persona_lista = [nombre, edad, altura, es_estudiante] # 📦 Lista
persona_tupla = (nombre, edad, altura, es_estudiante) # 📋 Tupla
persona_dict = { # 📚 Diccionario
"nombre": nombre, # str como clave, str como valor
"edad": edad, # str como clave, int como valor
"altura": altura, # str como clave, float como valor
"estudiante": es_estudiante # str como clave, bool como valor
}
print("🧱 Tipos elementales usados:")
print(f" Nombre: {nombre} ({type(nombre).__name__})")
print(f" Edad: {edad} ({type(edad).__name__})")
print(f" Altura: {altura} ({type(altura).__name__})")
print(f" Estudiante: {es_estudiante} ({type(es_estudiante).__name__})")
print("\n🏗️ Tipos compuestos creados:")
print(f" Lista: {persona_lista} ({type(persona_lista).__name__})")
print(f" Tupla: {persona_tupla} ({type(persona_tupla).__name__})")
print(f" Diccionario: {persona_dict} ({type(persona_dict).__name__})")
🎯 ¿Por qué es útil esta perspectiva?
- 📚 Aprendizaje progresivo: Primero dominas los ladrillos básicos, luego aprendes a construir estructuras
- 🔧 Resolución de problemas: Sabes que cualquier estructura compleja está hecha de elementos simples
- 🐛 Depuración: Si algo falla en una estructura compuesta, revisas los elementos individuales
- 💡 Diseño: Planificas mejor qué tipos elementales necesitas para crear tus estructuras
# Ejemplo práctico: Sistema de estudiantes
# Primero definimos los elementos básicos (tipos elementales)
estudiante1_nombre = "Carlos Mendoza" # str
estudiante1_edad = 20 # int
estudiante1_promedio = 8.5 # float
estudiante1_activo = True # bool
estudiante2_nombre = "Ana García" # str
estudiante2_edad = 22 # int
estudiante2_promedio = 9.2 # float
estudiante2_activo = False # bool
# Luego construimos estructuras más complejas (tipos compuestos)
estudiante1 = { # Diccionario usando str, int, float, bool
"nombre": estudiante1_nombre,
"edad": estudiante1_edad,
"promedio": estudiante1_promedio,
"activo": estudiante1_activo
}
estudiante2 = { # Otro diccionario con la misma estructura
"nombre": estudiante2_nombre,
"edad": estudiante2_edad,
"promedio": estudiante2_promedio,
"activo": estudiante2_activo
}
# Y finalmente, estructuras aún más complejas
lista_estudiantes = [estudiante1, estudiante2] # Lista de diccionarios
print("🎓 SISTEMA DE ESTUDIANTES")
print("=" * 40)
for i, estudiante in enumerate(lista_estudiantes, 1):
print(f"Estudiante {i}:")
print(f" 📝 Nombre: {estudiante['nombre']}")
print(f" 🎂 Edad: {estudiante['edad']} años")
print(f" 📊 Promedio: {estudiante['promedio']}")
print(f" ✅ Activo: {estudiante['activo']}")
print()
💡 Reflexión: Observa cómo partimos de 4 tipos elementales simples (str, int, float, bool) y construimos un sistema completo de gestión de estudiantes. ¡Esa es la potencia de la composición!
Los 5 tipos de cajas principales (Tipos Elementales)
🔵 Caja Azul: int (Números Enteros)
Las cajas azules son perfectas para guardar números enteros (sin decimales). Son como cajas resistentes que solo aceptan números completos.
# Creando cajas azules
edad = 25
año_actual = 2024
temperatura = -5
puntos = 0
habitantes = 1000000
# Verificar que son cajas azules
print(type(edad)) # <class 'int'>
¿Cuándo usar cajas azules?
- Edades:
edad = 25 - Años:
año_nacimiento = 1995 - Cantidades exactas:
numero_estudiantes = 30 - Puntuaciones:
puntos_juego = 1500 - Posiciones:
fila = 5,columna = 3
Ejemplos prácticos:
# Información de un estudiante
edad_estudiante = 20
semestre_actual = 6
materias_cursando = 5
creditos_completados = 120
print("=== INFORMACIÓN ACADÉMICA ===")
print("Edad:", edad_estudiante, "años")
print("Semestre:", semestre_actual)
print("Materias este semestre:", materias_cursando)
print("Créditos completados:", creditos_completados)
# Cálculos con cajas azules
creditos_faltantes = 200 - creditos_completados
print("Créditos faltantes:", creditos_faltantes)
Números negativos también son bienvenidos:
temperatura_invierno = -10
deuda = -5000
diferencia_puntos = -25
print("Temperatura:", temperatura_invierno, "°C")
print("Balance:", deuda, "pesos")
🟢 Caja Verde: float (Números Decimales)
Las cajas verdes son especiales para números con decimales. Son como cajas de precisión que pueden guardar fracciones.
# Creando cajas verdes
altura = 1.75
precio = 29.99
temperatura = 36.5
porcentaje = 85.7
pi = 3.14159
# Verificar que son cajas verdes
print(type(altura)) # <class 'float'>
¿Cuándo usar cajas verdes?
- Medidas:
altura = 1.75,peso = 68.5 - Precios:
precio = 199.99 - Temperaturas:
temperatura = 36.5 - Porcentajes:
descuento = 15.5 - Constantes matemáticas:
pi = 3.14159
Ejemplos prácticos:
# Información física de una persona
altura_metros = 1.75
peso_kg = 68.5
temperatura_corporal = 36.8
print("=== DATOS FÍSICOS ===")
print("Altura:", altura_metros, "metros")
print("Peso:", peso_kg, "kg")
print("Temperatura:", temperatura_corporal, "°C")
# Cálculos con cajas verdes
imc = peso_kg / (altura_metros ** 2)
print("IMC:", round(imc, 2)) # Redondeamos a 2 decimales
# Información de compras
precio_producto = 199.99
descuento_porcentaje = 15.5
iva_porcentaje = 16.0
descuento_pesos = precio_producto * (descuento_porcentaje / 100)
precio_con_descuento = precio_producto - descuento_pesos
iva_pesos = precio_con_descuento * (iva_porcentaje / 100)
precio_final = precio_con_descuento + iva_pesos
print("\n=== CÁLCULO DE PRECIO ===")
print("Precio original: $", precio_producto)
print("Descuento (", descuento_porcentaje, "%): $", round(descuento_pesos, 2))
print("Precio con descuento: $", round(precio_con_descuento, 2))
print("IVA (", iva_porcentaje, "%): $", round(iva_pesos, 2))
print("Precio final: $", round(precio_final, 2))
🟡 Caja Amarilla: str (Cadenas de Texto)
Las cajas amarillas son perfectas para guardar texto. Son como cajas mágicas que pueden contener cualquier combinación de letras, números y símbolos, ¡pero siempre entre comillas!
# Creando cajas amarillas
nombre = "Ana García"
mensaje = "¡Hola mundo!"
email = "ana@email.com"
telefono = "555-1234" # Nota: entre comillas porque es texto
direccion = "Calle Falsa 123, Col. Centro"
# Verificar que son cajas amarillas
print(type(nombre)) # <class 'str'>
¿Cuándo usar cajas amarillas?
- Nombres:
nombre = "Ana" - Mensajes:
saludo = "¡Hola!" - Direcciones:
email = "ana@email.com" - Identificadores:
codigo = "ABC123" - Cualquier texto:
descripcion = "Producto de alta calidad"
Formas de crear cajas amarillas:
# Con comillas dobles
nombre = "Ana García"
mensaje = "Ella dijo: 'Hola'"
# Con comillas simples
apellido = 'López'
frase = 'El libro "Python para principiantes" es genial'
# Con comillas triples (para texto largo)
descripcion = """Este es un texto muy largo
que puede ocupar varias líneas
y es perfecto para descripciones detalladas."""
biografia = '''Ana García es una estudiante
de ingeniería en sistemas que le gusta
programar en Python.'''
Ejemplos prácticos:
# Información personal
nombre_completo = "Ana García López"
email_personal = "ana.garcia@email.com"
telefono_celular = "555-123-4567"
ciudad_residencia = "Ciudad de México"
ocupacion = "Estudiante de Ingeniería"
print("=== INFORMACIÓN DE CONTACTO ===")
print("Nombre:", nombre_completo)
print("Email:", email_personal)
print("Teléfono:", telefono_celular)
print("Ciudad:", ciudad_residencia)
print("Ocupación:", ocupacion)
# Mensajes personalizados
saludo_matutino = "¡Buenos días!"
saludo_vespertino = "¡Buenas tardes!"
despedida = "¡Hasta luego!"
print("\n=== MENSAJES ===")
print(saludo_matutino, nombre_completo)
print("Espero que tengas un excelente día.")
print(despedida)
# Información de productos
producto_nombre = "Laptop Gaming Pro"
producto_marca = "TechMaster"
producto_modelo = "GM-2024-X1"
producto_descripcion = "Laptop de alta gama para gaming y trabajo profesional"
print("\n=== INFORMACIÓN DEL PRODUCTO ===")
print("Producto:", producto_nombre)
print("Marca:", producto_marca)
print("Modelo:", producto_modelo)
print("Descripción:", producto_descripcion)
🔴 Caja Roja: bool (Booleanos)
Las cajas rojas son las más simples pero muy importantes. Solo pueden contener dos valores: True (verdadero) o False (falso). Son como interruptores que están encendidos o apagados.
# Creando cajas rojas
es_estudiante = True
tiene_trabajo = False
esta_casado = True
es_fin_semana = False
# Verificar que son cajas rojas
print(type(es_estudiante)) # <class 'bool'>
¿Cuándo usar cajas rojas?
- Estados:
esta_encendido = True - Permisos:
puede_votar = True - Condiciones:
es_mayor_edad = False - Configuraciones:
modo_oscuro = True - Resultados de comparaciones:
es_igual = (5 == 5)
Ejemplos prácticos:
# Estado de un usuario
usuario_activo = True
email_verificado = True
perfil_completo = False
notificaciones_activadas = True
modo_privado = False
print("=== ESTADO DEL USUARIO ===")
print("Usuario activo:", usuario_activo)
print("Email verificado:", email_verificado)
print("Perfil completo:", perfil_completo)
print("Notificaciones:", notificaciones_activadas)
print("Modo privado:", modo_privado)
# Configuración de una aplicación
tema_oscuro = True
sonido_activado = False
actualizaciones_automaticas = True
compartir_ubicacion = False
print("\n=== CONFIGURACIÓN DE LA APP ===")
print("Tema oscuro:", tema_oscuro)
print("Sonido:", sonido_activado)
print("Actualizaciones automáticas:", actualizaciones_automaticas)
print("Compartir ubicación:", compartir_ubicacion)
# Resultados de verificaciones
contraseña_valida = True
edad_suficiente = False
terminos_aceptados = True
print("\n=== VERIFICACIONES ===")
print("Contraseña válida:", contraseña_valida)
print("Edad suficiente:", edad_suficiente)
print("Términos aceptados:", terminos_aceptados)
⚪ Caja Vacía: None (Nada)
La caja vacía es especial. Representa “nada” o “vacío”. Es como tener una caja etiquetada pero sin contenido adentro.
# Creando cajas vacías
resultado = None
valor_inicial = None
respuesta_usuario = None
# Verificar que son cajas vacías
print(type(resultado)) # <class 'NoneType'>
¿Cuándo usar cajas vacías?
- Valores iniciales:
resultado = None - Valores opcionales:
segundo_nombre = None - Indicar ausencia:
fecha_fin = None - Valores por defecto:
configuracion = None
Ejemplos prácticos:
# Información opcional de una persona
nombre = "Ana García"
segundo_nombre = None # No tiene segundo nombre
apellido_materno = "López"
apellido_paterno = None # No se especificó
print("=== INFORMACIÓN PERSONAL ===")
print("Nombre:", nombre)
print("Segundo nombre:", segundo_nombre)
print("Apellido materno:", apellido_materno)
print("Apellido paterno:", apellido_paterno)
# Estado inicial de variables
puntuacion_final = None # Aún no se calcula
fecha_graduacion = None # Aún no se define
trabajo_actual = None # Desempleado
print("\n=== INFORMACIÓN PENDIENTE ===")
print("Puntuación final:", puntuacion_final)
print("Fecha de graduación:", fecha_graduacion)
print("Trabajo actual:", trabajo_actual)
Comparando los tipos de cajas
Vamos a crear un ejemplo que use todos los tipos de cajas:
# ================================
# PERFIL COMPLETO DE USUARIO
# ================================
print("=== CREANDO PERFIL DE USUARIO ===")
print()
# 🟡 Cajas amarillas (texto)
nombre_usuario = "Carlos Mendoza"
email = "carlos.mendoza@email.com"
ciudad = "Guadalajara"
profesion = "Ingeniero de Software"
# 🔵 Cajas azules (números enteros)
edad = 28
años_experiencia = 5
proyectos_completados = 23
# 🟢 Cajas verdes (números decimales)
salario_mensual = 35000.50
altura = 1.78
calificacion_promedio = 4.7
# 🔴 Cajas rojas (verdadero/falso)
esta_empleado = True
busca_trabajo = False
disponible_freelance = True
tiene_auto = True
# ⚪ Cajas vacías (información pendiente)
fecha_ultimo_proyecto = None
siguiente_vacacion = None
# ================================
# MOSTRAR INFORMACIÓN ORGANIZADA
# ================================
print("📋 INFORMACIÓN PERSONAL")
print("Nombre:", nombre_usuario)
print("Email:", email)
print("Ciudad:", ciudad)
print("Profesión:", profesion)
print("Edad:", edad, "años")
print("Altura:", altura, "metros")
print()
print("💼 INFORMACIÓN PROFESIONAL")
print("Años de experiencia:", años_experiencia)
print("Proyectos completados:", proyectos_completados)
print("Salario mensual: $", salario_mensual)
print("Calificación promedio:", calificacion_promedio, "/5.0")
print()
print("✅ ESTADO ACTUAL")
print("Está empleado:", esta_empleado)
print("Busca trabajo:", busca_trabajo)
print("Disponible para freelance:", disponible_freelance)
print("Tiene auto:", tiene_auto)
print()
print("⏳ INFORMACIÓN PENDIENTE")
print("Fecha último proyecto:", fecha_ultimo_proyecto)
print("Siguiente vacación:", fecha_ultimo_proyecto)
print()
print("🔍 TIPOS DE CAJAS UTILIZADAS")
print("nombre_usuario:", type(nombre_usuario))
print("edad:", type(edad))
print("salario_mensual:", type(salario_mensual))
print("esta_empleado:", type(esta_empleado))
print("fecha_ultimo_proyecto:", type(fecha_ultimo_proyecto))
Identificando tipos de cajas
Python te permite “espiar” qué tipo de caja es cada variable:
# Crear diferentes tipos de cajas
mi_nombre = "Ana"
mi_edad = 25
mi_altura = 1.65
soy_estudiante = True
mi_mascota = None
# Espiar qué tipo de caja es cada una
print("=== IDENTIFICANDO TIPOS DE CAJAS ===")
print("mi_nombre es una caja tipo:", type(mi_nombre))
print("mi_edad es una caja tipo:", type(mi_edad))
print("mi_altura es una caja tipo:", type(mi_altura))
print("soy_estudiante es una caja tipo:", type(soy_estudiante))
print("mi_mascota es una caja tipo:", type(mi_mascota))
Ejercicio práctico: Inventario de tu almacén
Vamos a crear un programa que use todos los tipos de cajas:
# ================================
# INVENTARIO DE MI ALMACÉN PERSONAL
# ================================
print("📦 ORGANIZANDO MI ALMACÉN DE VARIABLES")
print("=" * 50)
# Crear una caja de cada tipo
print("\n🟡 Creando caja amarilla (texto)...")
mi_comida_favorita = "Pizza"
print(f" Contenido: {mi_comida_favorita}")
print(f" Tipo de caja: {type(mi_comida_favorita)}")
print("\n🔵 Creando caja azul (número entero)...")
mi_edad = 25 # Cambia por tu edad
print(f" Contenido: {mi_edad}")
print(f" Tipo de caja: {type(mi_edad)}")
print("\n🟢 Creando caja verde (número decimal)...")
mi_estatura = 1.70 # Cambia por tu estatura
print(f" Contenido: {mi_estatura}")
print(f" Tipo de caja: {type(mi_estatura)}")
print("\n🔴 Creando caja roja (verdadero/falso)...")
me_gusta_programar = True # Cambia según tu preferencia
print(f" Contenido: {me_gusta_programar}")
print(f" Tipo de caja: {type(me_gusta_programar)}")
print("\n⚪ Creando caja vacía (None)...")
mi_segundo_apellido = None # Si no tienes segundo apellido
print(f" Contenido: {mi_segundo_apellido}")
print(f" Tipo de caja: {type(mi_segundo_apellido)}")
print("\n" + "=" * 50)
print("📋 RESUMEN DE MI ALMACÉN")
print("=" * 50)
print(f"🟡 Cajas amarillas (str): 1 - Contenido: {mi_comida_favorita}")
print(f"🔵 Cajas azules (int): 1 - Contenido: {mi_edad}")
print(f"🟢 Cajas verdes (float): 1 - Contenido: {mi_estatura}")
print(f"🔴 Cajas rojas (bool): 1 - Contenido: {me_gusta_programar}")
print(f"⚪ Cajas vacías (None): 1 - Contenido: {mi_segundo_apellido}")
print(f"\n📊 Total de cajas en mi almacén: 5")
Consejos para elegir el tipo de caja correcto
1. Para números sin decimales → Caja azul (int)
edad = 25 # ✅ Correcto
edad = 25.0 # ❌ Innecesario (aunque funciona)
2. Para números con decimales → Caja verde (float)
precio = 19.99 # ✅ Correcto
precio = 19 # ❌ Podría perder precisión
3. Para cualquier texto → Caja amarilla (str)
nombre = "Ana" # ✅ Correcto
telefono = "555-1234" # ✅ Correcto (aunque sean números)
4. Para sí/no, verdadero/falso → Caja roja (bool)
es_estudiante = True # ✅ Correcto
es_estudiante = "Sí" # ❌ Menos eficiente
5. Para valores ausentes → Caja vacía (None)
segundo_nombre = None # ✅ Correcto
segundo_nombre = "" # ❌ Cadena vacía, no ausencia
Resumen
🧱 Tipos Elementales (Los fundamentos)
En tu almacén de variables tienes 5 tipos principales de cajas elementales:
- 🔵 Cajas azules (int): Números enteros como 25, -10, 1000
- 🟢 Cajas verdes (float): Números decimales como 3.14, 19.99, -2.5
- 🟡 Cajas amarillas (str): Texto como “Ana”, “Hola mundo”, “123”
- 🔴 Cajas rojas (bool): Solo True o False
- ⚪ Cajas vacías (None): Representan ausencia de valor
🏗️ El camino hacia los tipos compuestos
Estos tipos elementales son tus ladrillos básicos. En capítulos posteriores aprenderás a combinarlos para crear tipos compuestos más sofisticados:
# Hoy aprendiste los ladrillos básicos (tipos elementales)
nombre = "Ana" # 🟡 str
edad = 25 # 🔵 int
activa = True # 🔴 bool
# Próximamente aprenderás a construir estructuras (tipos compuestos)
persona = [nombre, edad, activa] # 📦 Lista (próximo capítulo)
datos = {"nombre": nombre, "edad": edad} # 📚 Diccionario (más adelante)
coordenadas = (10.5, 20.3) # 📋 Tupla (también veremos)
💡 Principios clave
- Domina los elementales primero: Son la base de todo lo demás
- Elige el tipo correcto: Cada tipo tiene su propósito específico
- Piensa en composición: Los tipos complejos se construyen con los simples
- Practica la conversión: Saber cambiar entre tipos es fundamental
Elegir el tipo correcto de caja hace que tu código sea más eficiente y fácil de entender. En la siguiente sección aprenderemos cómo cambiar el contenido de una caja a otro tipo (conversión de tipos).
💡 Consejo del almacenista: Estos tipos elementales son como el alfabeto de la programación. Una vez que los domines, podrás “escribir” estructuras de datos tan complejas como necesites. ¡Recuerda: todo lo complejo está hecho de cosas simples!
Conversión de Tipos y Formateo de Strings
¿Alguna vez has necesitado cambiar el contenido de una caja azul (números enteros) a una caja amarilla (texto)? ¿O transformar el contenido de una caja amarilla en una caja verde (decimales)? ¡En Python esto es posible y muy útil!
La conversión de tipos es como tener una máquina mágica que puede transformar el contenido de un tipo de caja a otro.
🌟 Tres formas de combinar texto y variables
💭 Nota del autor: En mi experiencia enseñando Python, he notado que muchos principiantes se confunden con las diferentes formas de combinar texto y variables. Permíteme mostrarte las tres formas principales, en orden de preferencia.
1. F-strings (Recomendado - Python 3.6+)
Los f-strings son la forma más moderna, legible y eficiente de combinar texto y variables en Python:
nombre = "Ana"
edad = 25
salario = 1500.50
# F-string (prefijo f antes de las comillas)
mensaje = f"Hola {nombre}, tienes {edad} años y ganas ${salario:.2f}"
print(mensaje) # Hola Ana, tienes 25 años y ganas $1500.50
2. Concatenación (Fallback - Universal)
La concatenación es la forma más básica y funciona en todas las versiones de Python:
nombre = "Ana"
edad = 25
salario = 1500.50
# Concatenación (usando el operador +)
mensaje = "Hola " + nombre + ", tienes " + str(edad) + " años y ganas $" + str(salario)
print(mensaje) # Hola Ana, tienes 25 años y ganas $1500.5
3. Format() (Legacy - Código Antiguo)
El método format() fue popular antes de los f-strings:
nombre = "Ana"
edad = 25
salario = 1500.50
# Método format()
mensaje = "Hola {}, tienes {} años y ganas ${:.2f}".format(nombre, edad, salario)
print(mensaje) # Hola Ana, tienes 25 años y ganas $1500.50
🎯 Mi recomendación personal
💭 Nota del autor: Después de años programando en Python, siempre recomiendo usar f-strings cuando sea posible. Son más legibles, más rápidos y hacen que tu código sea más mantenible. Solo usa concatenación para casos muy simples o cuando necesites compatibilidad con versiones antiguas de Python.
¿Qué es la conversión de tipos?
Imagínate que tienes una máquina transformadora en tu almacén. Puedes meter una caja azul con el número 25 y la máquina te devuelve una caja amarilla con el texto "25". ¡El contenido se ve igual, pero ahora es de un tipo diferente!
# Caja azul original
numero = 25
print("Contenido:", numero)
print("Tipo de caja:", type(numero)) # <class 'int'>
# Transformar a caja amarilla
numero_como_texto = str(numero)
print("Contenido transformado:", numero_como_texto)
print("Nuevo tipo de caja:", type(numero_como_texto)) # <class 'str'>
Las máquinas transformadoras de Python
Python tiene varias máquinas transformadoras:
🔄 str() - Transformadora a Caja Amarilla
Convierte cualquier cosa a texto:
# De caja azul a caja amarilla
edad = 25
edad_texto = str(edad)
print("Edad como texto:", edad_texto) # "25"
# De caja verde a caja amarilla
precio = 19.99
precio_texto = str(precio)
print("Precio como texto:", precio_texto) # "19.99"
# De caja roja a caja amarilla
es_estudiante = True
estudiante_texto = str(es_estudiante)
print("Estado como texto:", estudiante_texto) # "True"
🔄 int() - Transformadora a Caja Azul
Convierte a números enteros:
# De caja amarilla a caja azul
edad_texto = "25"
edad_numero = int(edad_texto)
print("Edad como número:", edad_numero) # 25
# De caja verde a caja azul (¡cuidado, pierde decimales!)
precio = 19.99
precio_entero = int(precio)
print("Precio sin decimales:", precio_entero) # 19 (se trunca)
# De caja roja a caja azul
es_verdadero = True
verdadero_numero = int(es_verdadero)
print("True como número:", verdadero_numero) # 1
es_falso = False
falso_numero = int(es_falso)
print("False como número:", falso_numero) # 0
🔄 float() - Transformadora a Caja Verde
Convierte a números decimales:
# De caja amarilla a caja verde
precio_texto = "19.99"
precio_decimal = float(precio_texto)
print("Precio como decimal:", precio_decimal) # 19.99
# De caja azul a caja verde
edad = 25
edad_decimal = float(edad)
print("Edad como decimal:", edad_decimal) # 25.0
# De caja roja a caja verde
es_verdadero = True
verdadero_decimal = float(es_verdadero)
print("True como decimal:", verdadero_decimal) # 1.0
🔄 bool() - Transformadora a Caja Roja
Convierte a verdadero/falso:
# De caja azul a caja roja
numero_positivo = 5
es_verdadero = bool(numero_positivo)
print("5 como booleano:", es_verdadero) # True
numero_cero = 0
es_falso = bool(numero_cero)
print("0 como booleano:", es_falso) # False
# De caja amarilla a caja roja
texto_lleno = "Hola"
texto_verdadero = bool(texto_lleno)
print("'Hola' como booleano:", texto_verdadero) # True
texto_vacio = ""
texto_falso = bool(texto_vacio)
print("'' como booleano:", texto_falso) # False
Ejemplo práctico: Calculadora de edad
Vamos a crear un programa que demuestre la conversión de tipos y las diferentes formas de combinar texto con variables:
# ================================
# CALCULADORA DE EDAD
# ================================
print("=== CALCULADORA DE EDAD ===")
print()
# El usuario ingresa su año de nacimiento como texto
print("Por favor, ingresa tu año de nacimiento:")
año_nacimiento_texto = "1995" # Simular entrada del usuario
print("Entrada del usuario:", año_nacimiento_texto)
print("Tipo de caja:", type(año_nacimiento_texto)) # str
print()
# Transformar de caja amarilla a caja azul para hacer cálculos
print("🔄 Transformando texto a número...")
año_nacimiento = int(año_nacimiento_texto)
print("Año como número:", año_nacimiento)
print("Tipo de caja:", type(año_nacimiento)) # int
print()
# Calcular edad (usando caja azul para el año actual)
año_actual = 2024
edad = año_actual - año_nacimiento
print("Cálculo: ", año_actual, "-", año_nacimiento, "=", edad)
print()
# ================================
# FORMAS DE COMBINAR TEXTO Y VARIABLES
# ================================
print("🔄 Creando mensajes con diferentes métodos...")
print()
# 🌟 MÉTODO 1: F-STRINGS (RECOMENDADO - MODERNO Y FÁCIL)
print("🌟 Método 1: F-strings (Recomendado)")
mensaje_fstring = f"Tienes {edad} años"
print("Resultado:", mensaje_fstring)
print("Código:", 'f"Tienes {edad} años"')
print()
# 🔧 MÉTODO 2: CONCATENACIÓN (FALLBACK - SIMPLE Y UNIVERSAL)
print("🔧 Método 2: Concatenación (Fallback)")
edad_texto = str(edad)
mensaje_concatenacion = "Tienes " + edad_texto + " años"
print("Resultado:", mensaje_concatenacion)
print("Código:", '"Tienes " + str(edad) + " años"')
print()
# 📚 MÉTODO 3: FORMAT() (LEGACY - MÉTODO ANTERIOR)
print("📚 Método 3: format() (Legacy)")
mensaje_format = "Tienes {} años".format(edad)
print("Resultado:", mensaje_format)
print("Código:", '"Tienes {} años".format(edad)')
print()
# Verificar si es mayor de edad (transformar a booleano)
print("🔄 Verificando mayoría de edad...")
es_mayor_edad = edad >= 18
print("¿Es mayor de edad?", es_mayor_edad)
print("Tipo de caja:", type(es_mayor_edad)) # bool
Conversiones automáticas vs manuales
Conversiones automáticas (Python las hace solo):
# Python convierte automáticamente en operaciones mixtas
numero_entero = 5
numero_decimal = 2.5
resultado = numero_entero + numero_decimal # 5 se convierte a 5.0
print("Resultado:", resultado) # 7.5
print("Tipo:", type(resultado)) # float
Conversiones manuales (tú las haces):
# Tú decides cuándo y cómo convertir
edad_texto = "25"
edad_numero = int(edad_texto) # Conversión manual
print("Edad:", edad_numero)
Errores comunes en conversiones
1. Intentar convertir texto no numérico a número
# ❌ ERROR
nombre = "Ana"
# numero = int(nombre) # ValueError: invalid literal for int()
# ✅ CORRECTO - verificar antes
texto = "123"
if texto.isdigit():
numero = int(texto)
print("Conversión exitosa:", numero)
else:
print("No se puede convertir a número")
2. Perder información en conversiones
# ❌ CUIDADO - se pierden decimales
precio = 19.99
precio_entero = int(precio)
print("Precio original:", precio) # 19.99
print("Precio convertido:", precio_entero) # 19 (se perdió .99)
# ✅ MEJOR - usar round() si quieres redondear
precio_redondeado = round(precio)
print("Precio redondeado:", precio_redondeado) # 20
3. Confundir tipos en operaciones
# ❌ ERROR - no puedes sumar texto con números
edad = 25
# mensaje = "Tengo " + edad + " años" # TypeError
# ✅ CORRECTO - convertir a texto primero
mensaje = "Tengo " + str(edad) + " años"
print(mensaje) # "Tengo 25 años"
Ejemplo práctico: Sistema de calificaciones
# ================================
# SISTEMA DE CALIFICACIONES
# ================================
print("=== SISTEMA DE CALIFICACIONES ===")
print()
# Calificaciones ingresadas como texto (simulando entrada de usuario)
calificacion1_texto = "85"
calificacion2_texto = "92"
calificacion3_texto = "78"
nombre_estudiante = "María González"
print("📝 Calificaciones ingresadas:")
# 🌟 Usando f-strings para mostrar información
print(f"Estudiante: {nombre_estudiante}")
print(f"Materia 1: {calificacion1_texto}")
print(f"Materia 2: {calificacion2_texto}")
print(f"Materia 3: {calificacion3_texto}")
print(f"Tipo de datos: {type(calificacion1_texto)}")
print()
# Convertir de texto a números para hacer cálculos
print("🔄 Convirtiendo calificaciones a números...")
cal1 = int(calificacion1_texto)
cal2 = int(calificacion2_texto)
cal3 = int(calificacion3_texto)
# 🌟 F-strings para mostrar conversiones
print(f"Calificación 1: {cal1} - Tipo: {type(cal1)}")
print(f"Calificación 2: {cal2} - Tipo: {type(cal2)}")
print(f"Calificación 3: {cal3} - Tipo: {type(cal3)}")
print()
# Calcular promedio (resultado será decimal)
print("📊 Calculando promedio...")
suma = cal1 + cal2 + cal3
promedio = suma / 3
# 🌟 F-strings con formateo de números
print(f"Suma: {suma}")
print(f"Promedio: {promedio:.2f}")
print(f"Tipo del promedio: {type(promedio)}")
print()
# Redondear promedio
promedio_redondeado = round(promedio, 2)
print(f"Promedio redondeado: {promedio_redondeado}")
print()
# Determinar si aprobó (convertir a booleano)
print("✅ Verificando aprobación...")
aprobo = promedio >= 70
print(f"¿Aprobó? (promedio >= 70): {aprobo}")
print(f"Tipo: {type(aprobo)}")
print()
# Crear mensaje final con los tres métodos
print("📄 Generando reporte final con diferentes métodos...")
print()
estado_texto = "APROBADO" if aprobo else "REPROBADO"
# 🌟 F-string (recomendado)
reporte_fstring = f"Estudiante: {nombre_estudiante} | Promedio: {promedio_redondeado} | Estado: {estado_texto}"
print("🌟 Con f-string:")
print(f" {reporte_fstring}")
print()
# 🔧 Concatenación (fallback)
promedio_texto = str(promedio_redondeado)
reporte_concat = ("Estudiante: " + nombre_estudiante + " | Promedio: " +
promedio_texto + " | Estado: " + estado_texto)
print("🔧 Con concatenación:")
print(f" {reporte_concat}")
print()
# 📚 Format (legacy)
reporte_format = "Estudiante: {} | Promedio: {} | Estado: {}".format(
nombre_estudiante, promedio_redondeado, estado_texto
)
print("📚 Con format:")
print(f" {reporte_format}")
print()
# Reporte detallado con f-strings
print("📋 REPORTE DETALLADO (con f-strings):")
print("=" * 50)
print(f"👤 Estudiante: {nombre_estudiante}")
print(f"📊 Calificaciones individuales:")
print(f" • Materia 1: {cal1}/100")
print(f" • Materia 2: {cal2}/100")
print(f" • Materia 3: {cal3}/100")
print(f"📈 Estadísticas:")
print(f" • Suma total: {suma} puntos")
print(f" • Promedio: {promedio:.2f}/100")
print(f" • Estado: {estado_texto}")
print(f" • Puntos para aprobar: {70 - promedio:.1f}" if not aprobo else f" • Puntos sobre el mínimo: {promedio - 70:.1f}")
Conversiones útiles en la vida real
1. Entrada de usuario (siempre texto)
# Simular entrada de usuario
nombre = "Ana" # input() siempre devuelve texto
edad_texto = "25" # input() siempre devuelve texto
# Convertir edad para cálculos
edad = int(edad_texto)
año_nacimiento = 2024 - edad
# 🌟 F-string (recomendado)
mensaje_fstring = f"Hola {nombre}, naciste aproximadamente en {año_nacimiento}"
print("Con f-string:", mensaje_fstring)
# 🔧 Concatenación (fallback)
mensaje_concat = "Hola " + nombre + ", naciste aproximadamente en " + str(año_nacimiento)
print("Con concatenación:", mensaje_concat)
# 📚 Format (legacy)
mensaje_format = "Hola {}, naciste aproximadamente en {}".format(nombre, año_nacimiento)
print("Con format:", mensaje_format)
2. Formateo de números para mostrar
# Cálculos con decimales
precio_base = 100
descuento = 0.15
precio_final = precio_base * (1 - descuento)
# 🌟 F-string (recomendado) - con formateo automático
mensaje_fstring = f"El precio final es: ${precio_final:.2f}"
print("Con f-string:", mensaje_fstring)
# 🔧 Concatenación (fallback) - necesita conversión manual
precio_texto = str(round(precio_final, 2))
mensaje_concat = "El precio final es: $" + precio_texto
print("Con concatenación:", mensaje_concat)
# 📚 Format (legacy)
mensaje_format = "El precio final es: ${:.2f}".format(precio_final)
print("Con format:", mensaje_format)
3. Validaciones con mensajes
# Verificar si un texto puede convertirse a número
entrada_usuario = "123"
nombre_usuario = "Carlos"
if entrada_usuario.isdigit():
numero = int(entrada_usuario)
# 🌟 F-string (recomendado)
mensaje_fstring = f"¡Perfecto {nombre_usuario}! '{entrada_usuario}' es un número válido: {numero}"
print("Con f-string:", mensaje_fstring)
# 🔧 Concatenación (fallback)
mensaje_concat = ("¡Perfecto " + nombre_usuario + "! '" + entrada_usuario +
"' es un número válido: " + str(numero))
print("Con concatenación:", mensaje_concat)
# 📚 Format (legacy)
mensaje_format = "¡Perfecto {}! '{}' es un número válido: {}".format(
nombre_usuario, entrada_usuario, numero
)
print("Con format:", mensaje_format)
else:
# 🌟 F-string para mensajes de error
error_fstring = f"Lo siento {nombre_usuario}, '{entrada_usuario}' no es un número válido"
print("Error con f-string:", error_fstring)
Tabla de conversiones comunes
| Desde | Hacia | Función | Ejemplo | Resultado |
|---|---|---|---|---|
| int | str | str() | str(25) | "25" |
| int | float | float() | float(25) | 25.0 |
| int | bool | bool() | bool(25) | True |
| float | str | str() | str(19.99) | "19.99" |
| float | int | int() | int(19.99) | 19 |
| float | bool | bool() | bool(19.99) | True |
| str | int | int() | int("25") | 25 |
| str | float | float() | float("19.99") | 19.99 |
| str | bool | bool() | bool("Hola") | True |
| bool | str | str() | str(True) | "True" |
| bool | int | int() | int(True) | 1 |
| bool | float | float() | float(True) | 1.0 |
Ejercicio práctico: Conversor universal
# ================================
# CONVERSOR UNIVERSAL DE TIPOS
# ================================
print("🔄 CONVERSOR UNIVERSAL DE TIPOS")
print("=" * 40)
# Valor original
valor_original = 42
print(f"\n📦 Valor original: {valor_original}")
print(f" Tipo: {type(valor_original)}")
# Convertir a todos los tipos posibles
print("\n🔄 CONVERSIONES:")
# A texto
valor_str = str(valor_original)
print(f"🟡 Como texto (str): '{valor_str}' - Tipo: {type(valor_str)}")
# A decimal
valor_float = float(valor_original)
print(f"🟢 Como decimal (float): {valor_float} - Tipo: {type(valor_float)}")
# A booleano
valor_bool = bool(valor_original)
print(f"🔴 Como booleano (bool): {valor_bool} - Tipo: {type(valor_bool)}")
print("\n" + "=" * 40)
print("🧪 PROBANDO CON DIFERENTES VALORES:")
# Probar con diferentes valores
valores_prueba = [0, -5, 3.14, "123", "Hola", True, False, ""]
for i, valor in enumerate(valores_prueba, 1):
print(f"\n📦 Prueba {i}: {repr(valor)} ({type(valor).__name__})")
# Intentar convertir a booleano (siempre funciona)
print(f" 🔴 bool(): {bool(valor)}")
# Intentar convertir a texto (siempre funciona)
print(f" 🟡 str(): '{str(valor)}'")
# Intentar convertir a número (puede fallar)
try:
if isinstance(valor, str) and valor.replace('.', '').replace('-', '').isdigit():
if '.' in valor:
resultado_float = float(valor)
print(f" 🟢 float(): {resultado_float}")
else:
resultado_int = int(valor)
print(f" 🔵 int(): {resultado_int}")
elif isinstance(valor, (int, float, bool)):
resultado_int = int(valor)
resultado_float = float(valor)
print(f" 🔵 int(): {resultado_int}")
print(f" 🟢 float(): {resultado_float}")
except ValueError:
print(" ❌ No se puede convertir a número")
print("\n" + "=" * 40)
print("📊 COMPARACIÓN DE MÉTODOS DE FORMATEO:")
# Ejemplo con datos complejos
nombre = "Ana García"
edad = 28
salario = 45000.75
es_activa = True
print(f"\n📋 DATOS DE EJEMPLO:")
print(f" Nombre: {nombre}")
print(f" Edad: {edad}")
print(f" Salario: {salario}")
print(f" Activa: {es_activa}")
print(f"\n📝 MENSAJE COMPLEJO CON TRES MÉTODOS:")
# 🌟 F-string (recomendado)
mensaje_fstring = f"Empleada: {nombre}, {edad} años, salario: ${salario:,.2f}, estado: {'Activa' if es_activa else 'Inactiva'}"
print(f"\n🌟 F-string (recomendado):")
print(f" Resultado: {mensaje_fstring}")
print(f" Legibilidad: ⭐⭐⭐⭐⭐")
print(f" Rendimiento: ⭐⭐⭐⭐⭐")
# 🔧 Concatenación (fallback)
estado_texto = "Activa" if es_activa else "Inactiva"
mensaje_concat = ("Empleada: " + nombre + ", " + str(edad) + " años, salario: $" +
f"{salario:,.2f}" + ", estado: " + estado_texto)
print(f"\n🔧 Concatenación (fallback):")
print(f" Resultado: {mensaje_concat}")
print(f" Legibilidad: ⭐⭐")
print(f" Rendimiento: ⭐⭐⭐")
# 📚 Format (legacy)
mensaje_format = "Empleada: {}, {} años, salario: ${:,.2f}, estado: {}".format(
nombre, edad, salario, "Activa" if es_activa else "Inactiva"
)
print(f"\n📚 Format (legacy):")
print(f" Resultado: {mensaje_format}")
print(f" Legibilidad: ⭐⭐⭐")
print(f" Rendimiento: ⭐⭐⭐⭐")
print(f"\n🎯 RECOMENDACIÓN:")
print(f" Usa f-strings siempre que sea posible (Python 3.6+)")
print(f" Usa concatenación para casos simples o compatibilidad")
print(f" Usa format() solo para mantener código legacy")
Consejos para conversiones seguras
1. Siempre verifica antes de convertir
def convertir_a_numero(texto):
if texto.isdigit():
return int(texto)
else:
print(f"'{texto}' no es un número válido")
return None
# Uso seguro
resultado = convertir_a_numero("123") # 123
resultado = convertir_a_numero("abc") # None
2. Usa try/except para conversiones riesgosas
def convertir_seguro(valor, tipo_destino):
try:
if tipo_destino == int:
return int(valor)
elif tipo_destino == float:
return float(valor)
elif tipo_destino == str:
return str(valor)
elif tipo_destino == bool:
return bool(valor)
except ValueError:
print(f"No se puede convertir '{valor}' a {tipo_destino.__name__}")
return None
# Uso
numero = convertir_seguro("123", int) # 123
numero = convertir_seguro("abc", int) # None
3. Recuerda las reglas de conversión a booleano
# Valores que se convierten a False
print(bool(0)) # False
print(bool(0.0)) # False
print(bool("")) # False
print(bool([])) # False (lista vacía)
print(bool(None)) # False
# Todo lo demás se convierte a True
print(bool(1)) # True
print(bool(-1)) # True
print(bool("Hola")) # True
print(bool(" ")) # True (espacio no es vacío)
Resumen
La conversión de tipos es como tener máquinas transformadoras en tu almacén, y combinar texto con variables es una habilidad esencial en Python:
🔄 Conversiones de Tipos:
- ✅
str()convierte cualquier cosa a texto (caja amarilla) - ✅
int()convierte a números enteros (caja azul) - ✅
float()convierte a números decimales (caja verde) - ✅
bool()convierte a verdadero/falso (caja roja) - ✅ Siempre verifica que la conversión sea posible
- ✅ Ten cuidado con la pérdida de información (float a int)
- ✅ Usa try/except para conversiones riesgosas
📝 Formateo de Strings (Orden de Prioridad):
🥇 1. F-strings (Recomendado - Python 3.6+)
nombre = "Ana"
edad = 25
mensaje = f"Hola {nombre}, tienes {edad} años"
Ventajas:
- ✅ Más legible y moderno
- ✅ Mejor rendimiento
- ✅ Formateo automático de números
- ✅ Expresiones dentro de las llaves
🥈 2. Concatenación (Fallback - Universal)
nombre = "Ana"
edad = 25
mensaje = "Hola " + nombre + ", tienes " + str(edad) + " años"
Ventajas:
- ✅ Simple y universal
- ✅ Funciona en todas las versiones
- ✅ Fácil de entender
Desventajas:
- ❌ Requiere conversión manual
- ❌ Menos legible con muchas variables
🥉 3. Format() (Legacy - Código Antiguo)
nombre = "Ana"
edad = 25
mensaje = "Hola {}, tienes {} años".format(nombre, edad)
Cuándo usar:
- 📚 Mantener código legacy
- 📚 Compatibilidad con Python < 3.6
- 📚 Proyectos que ya usan este estilo
🎯 Guía de Decisión Rápida:
# ✅ SIEMPRE PREFIERE ESTO (Python 3.6+):
mensaje = f"Usuario {nombre} tiene {edad} años y gana ${salario:,.2f}"
# 🔧 USA ESTO SI NECESITAS COMPATIBILIDAD:
mensaje = "Usuario " + nombre + " tiene " + str(edad) + " años"
# 📚 USA ESTO SOLO PARA CÓDIGO LEGACY:
mensaje = "Usuario {} tiene {} años".format(nombre, edad)
💡 Consejos Finales:
- Usa f-strings por defecto - Son el estándar moderno
- Concatenación para casos simples - Cuando solo unes 2-3 elementos
- Format() solo para legacy - Mantener código existente
- Siempre convierte tipos - Antes de combinar con texto
- Practica los tres métodos - Para entender código de otros
En el siguiente capítulo aprenderemos sobre operadores y expresiones, donde usaremos estas conversiones y formateos para hacer cálculos y comparaciones más complejas.
💡 Consejo del transformador: Los f-strings son como tener una máquina de última generación en tu almacén. Son más rápidos, más fáciles de usar y hacen que tu código se vea profesional. ¡Úsalos siempre que puedas!
Ejercicios: Variables y Tipos de Datos
¡Es hora de poner en práctica lo que has aprendido! Los ejercicios son la mejor manera de consolidar tu conocimiento y desarrollar tu intuición para la programación.
💭 Nota del autor: Cuando enseño programación, siempre digo que programar es como aprender a tocar un instrumento musical: puedes leer todos los libros que quieras, pero solo mejorarás si practicas regularmente. Estos ejercicios están diseñados para reforzar los conceptos que acabamos de ver y ayudarte a desarrollar tu “intuición de programador”.
🏋️ Ejercicio 1: Creando tu almacén personal
Objetivo: Practicar la creación de variables de diferentes tipos y mostrar su información.
Instrucciones:
-
Crea variables para almacenar tu información personal:
- Nombre (string)
- Edad (int)
- Altura en metros (float)
- ¿Te gusta programar? (bool)
- Al menos 3 variables más de tu elección
-
Muestra toda la información usando f-strings
-
Realiza al menos 3 cálculos con tus variables numéricas
-
Muestra el tipo de cada variable usando
type()
Plantilla de código:
# ================================
# MI ALMACÉN PERSONAL
# ================================
# Información básica (completa con tus datos)
nombre = "Tu nombre"
edad = 0 # Tu edad
altura = 0.0 # Tu altura en metros
te_gusta_programar = True # Cambia según tu preferencia
# Añade al menos 3 variables más
# ...
# ...
# ...
# Muestra la información usando f-strings
print("=== MI INFORMACIÓN PERSONAL ===")
print(f"Nombre: {nombre}")
# Completa con el resto de variables...
# Realiza al menos 3 cálculos
print("\n=== CÁLCULOS ===")
# Ejemplo: edad en meses
edad_en_meses = edad * 12
print(f"Mi edad en meses es: {edad_en_meses}")
# Añade al menos 2 cálculos más...
# Muestra el tipo de cada variable
print("\n=== TIPOS DE VARIABLES ===")
print(f"Variable 'nombre' es de tipo: {type(nombre)}")
# Completa con el resto de variables...
Resultado esperado:
# Código para crear un almacén personal de información
nombre = "Ana García"
edad = 25
altura = 1.65
le_gusta_programar = True
# Realizar cálculos con las variables
edad_en_meses = edad * 12
altura_en_cm = altura * 100
# Mostrar información personal
print("# MI INFORMACIÓN PERSONAL")
print(f"Nombre: {nombre}")
print(f"Edad: {edad} años")
print(f"Altura: {altura} metros")
print(f"¿Me gusta programar?: {'Sí' if le_gusta_programar else 'No'}")
print("...")
# Mostrar cálculos
print("\n# CÁLCULOS")
print(f"Mi edad en meses es: {edad_en_meses}")
print(f"Mi altura en centímetros es: {altura_en_cm}")
print("...")
# Mostrar tipos de variables
print("\n# TIPOS DE VARIABLES")
print(f'Variable "nombre" es de tipo: {type(nombre)}')
print(f'Variable "edad" es de tipo: {type(edad)}')
print("...")
🏋️ Ejercicio 2: Calculadora de IMC
Objetivo: Crear una calculadora de Índice de Masa Corporal (IMC) usando variables y operaciones matemáticas.
Instrucciones:
-
Crea variables para almacenar:
- Nombre de la persona
- Peso en kilogramos (float)
- Altura en metros (float)
-
Calcula el IMC usando la fórmula:
IMC = peso / (altura * altura) -
Determina la categoría de peso según el IMC:
- Menos de 18.5: Bajo peso
- Entre 18.5 y 24.9: Peso normal
- Entre 25.0 y 29.9: Sobrepeso
- 30.0 o más: Obesidad
-
Muestra un informe completo con toda la información
Plantilla de código:
# ================================
# CALCULADORA DE IMC
# ================================
# Datos de la persona (completa con datos reales o inventados)
nombre = "Ana García"
peso = 65.5 # en kilogramos
altura = 1.65 # en metros
# Cálculo del IMC
# Nota: ** es el operador de potencia (se verá en detalle en el Capítulo 5)
# altura ** 2 significa "altura elevado al cuadrado"
imc = peso / (altura ** 2)
# Nota: La determinación de categorías se aprenderá en el Capítulo 6 (Estructuras de Control)
# Por ahora, solo calcularemos el IMC
categoria = "Consulta con un profesional de salud para interpretación"
# Mostrar informe
print("=== INFORME DE IMC ===")
print(f"Nombre: {nombre}")
print(f"Peso: {peso} kg")
print(f"Altura: {altura} m")
print(f"IMC calculado: {imc:.2f}")
print(f"Categoría: {categoria}")
# Añade un mensaje personalizado según la categoría
# ...
Resultado esperado:
## INFORME DE IMC
Nombre: Ana García
Peso: 65.5 kg
Altura: 1.65 m
IMC calculado: 24.06
Categoría: Peso normal
Tu peso está dentro del rango saludable. Sigue así!
🏋️ Ejercicio 3: Conversor de unidades
Objetivo: Practicar la creación de variables, operaciones matemáticas y formateo de strings.
Instrucciones:
-
Crea un programa que convierta una distancia en kilómetros a:
- Metros
- Centímetros
- Millas (1 km = 0.621371 millas)
- Pies (1 km = 3280.84 pies)
-
Muestra los resultados formateados con 2 decimales
-
Incluye un encabezado y una presentación clara de los resultados
Plantilla de código:
# ================================
# CONVERSOR DE UNIDADES
# ================================
# Distancia en kilómetros
distancia_km = 10.0 # Cambia este valor
# Factores de conversión
km_a_metros = 1000
km_a_cm = 100000
km_a_millas = 0.621371
km_a_pies = 3280.84
# Realizar conversiones
# ...
# ...
# ...
# Mostrar resultados
print("## CONVERSOR DE DISTANCIAS")
print(f"Distancia original: {distancia_km} kilómetros")
print("\nEquivalencias:")
# Completa con los resultados formateados...
Resultado esperado:
## CONVERSOR DE DISTANCIAS
Distancia original: 10.0 kilómetros
Equivalencias:
- En metros: 10,000.00 m
- En centímetros: 1,000,000.00 cm
- En millas: 6.21 mi
- En pies: 32,808.40 ft
🏋️ Ejercicio 4: Intercambio de variables
Objetivo: Practicar el intercambio de valores entre variables.
Instrucciones:
- Crea tres variables:
a,byccon valores diferentes - Muestra los valores iniciales
- Intercambia los valores de manera que:
areciba el valor debbreciba el valor deccreciba el valor dea(el valor original)
- Muestra los valores finales
Plantilla de código:
# ================================
# INTERCAMBIO DE VARIABLES
# ================================
# Valores iniciales
a = 5
b = 10
c = 15
# Mostrar valores iniciales
print("=== VALORES INICIALES ===")
print(f"a = {a}")
print(f"b = {b}")
print(f"c = {c}")
# Realizar el intercambio
# ...
# ...
# ...
# Mostrar valores finales
print("\n=== VALORES FINALES ===")
print(f"a = {a}")
print(f"b = {b}")
print(f"c = {c}")
Resultado esperado:
## VALORES INICIALES
a = 5
b = 10
c = 15
## VALORES FINALES
a = 10
b = 15
c = 5
🏋️ Ejercicio 5: Calculadora de descuentos
Objetivo: Practicar operaciones con variables de diferentes tipos y formateo de salida.
Instrucciones:
-
Crea variables para:
- Nombre del producto
- Precio original
- Porcentaje de descuento
- Si el producto está en oferta (booleano)
-
Calcula:
- El monto del descuento
- El precio final después del descuento
- El IVA (16% sobre el precio con descuento)
- El precio final con IVA
-
Muestra un ticket de compra formateado
Plantilla de código:
# ================================
# CALCULADORA DE DESCUENTOS
# ================================
# Información del producto
nombre_producto = "Laptop Gaming Pro"
precio_original = 25000.0
porcentaje_descuento = 15.0 # 15%
en_oferta = True
# Cálculos
# ...
# ...
# ...
# Mostrar ticket
print("## TICKET DE COMPRA")
print(f"Producto: {nombre_producto}")
print(f"Precio original: ${precio_original:,.2f}")
# Completa el ticket con el resto de la información...
Resultado esperado:
## TICKET DE COMPRA
Producto: Laptop Gaming Pro
Precio original: $25,000.00
Descuento (15.0%): $3,750.00
Precio con descuento: $21,250.00
IVA (16.0%): $3,400.00
PRECIO FINAL: $24,650.00
Estado: EN OFERTA!
🏆 Desafío avanzado: Sistema de calificaciones
Objetivo: Integrar todos los conceptos aprendidos en un sistema más complejo.
Instrucciones:
-
Crea variables para almacenar:
- Nombre del estudiante
- Calificaciones de 5 materias diferentes (números del 0 al 100)
- Si el estudiante tiene beca (booleano)
-
Calcula:
- El promedio de calificaciones
- La calificación más alta y más baja
- Si el estudiante aprobó (promedio >= 70)
- Cuántos puntos le faltaron para el siguiente nivel:
- < 70: Puntos para aprobar
- 70-89: Puntos para excelencia
- 90-100: Ya tiene excelencia
-
Muestra un reporte completo y bien formateado
Plantilla de código:
# ================================
# SISTEMA DE CALIFICACIONES
# ================================
# Información del estudiante
nombre_estudiante = "Carlos Mendoza"
calificacion_matematicas = 85
calificacion_espanol = 92
calificacion_historia = 78
calificacion_ciencias = 90
calificacion_ingles = 88
tiene_beca = True
# Cálculos
# ...
# ...
# ...
# Mostrar reporte
print("=== REPORTE DE CALIFICACIONES ===")
print(f"Estudiante: {nombre_estudiante}")
print(f"Estado de beca: {'Activa' if tiene_beca else 'No tiene'}")
print("\n--- Calificaciones ---")
# Completa con las calificaciones y cálculos...
Resultado esperado:
## REPORTE DE CALIFICACIONES
Estudiante: Carlos Mendoza
Estado de beca: Activa
--- Calificaciones ---
Matemáticas: 85
Español: 92
Historia: 78
Ciencias: 90
Inglés: 88
--- Estadísticas ---
Promedio: 86.60
Calificación más alta: 92 (Español)
Calificación más baja: 78 (Historia)
Estado: APROBADO
Puntos para excelencia: 3.40
Felicidades Carlos! Tu desempeño es muy bueno.
💡 Consejos para resolver los ejercicios
- Lee cuidadosamente las instrucciones antes de empezar
- Planifica tu solución antes de escribir código
- Divide el problema en partes más pequeñas
- Prueba tu código con diferentes valores
- Revisa los errores con calma y paciencia
- No te rindas si algo no funciona a la primera
💭 Nota del autor: Cuando me enfrento a un problema de programación, siempre empiezo escribiendo en comentarios los pasos que voy a seguir. Esto me ayuda a organizar mis ideas y a no perderme en el proceso. Te recomiendo hacer lo mismo, especialmente cuando estás empezando.
🎯 Criterios de éxito
Sabrás que has dominado los conceptos de este capítulo cuando:
- ✅ Puedas crear variables de diferentes tipos sin errores
- ✅ Sepas identificar qué tipo de variable es adecuado para cada situación
- ✅ Puedas realizar operaciones entre variables del mismo tipo
- ✅ Entiendas cuándo necesitas convertir entre tipos
- ✅ Puedas formatear la salida de tus programas de manera clara y profesional
¡Buena suerte con los ejercicios! Recuerda que la práctica constante es la clave para dominar la programación. Si te atascas, revisa los ejemplos del capítulo o busca ayuda, pero nunca dejes de intentarlo.
💡 Consejo final: Intenta resolver estos ejercicios sin mirar las soluciones primero. Es normal sentirse frustrado al principio, pero cada error que cometas y corrijas te hará mejor programador. ¡El aprendizaje está en el proceso, no solo en el resultado final!
Operadores y Expresiones en Python
🧭 Navegación:
- Anterior: Variables y Tipos de Datos
- Siguiente: Control de Flujo – Condicionales
¡Bienvenido al centro de operaciones de Python! En esta sección, exploraremos las diferentes herramientas que Python nos ofrece para manipular datos, realizar cálculos y tomar decisiones.
¿Qué son los operadores?
Los operadores son símbolos especiales que realizan operaciones sobre variables y valores. Son como las herramientas de un taller que nos permiten transformar y combinar nuestros datos.
Contenido de esta sección
En esta sección aprenderás sobre:
- Operadores Matemáticos - Suma, resta, multiplicación, división y más
- Operadores de Comparación - Igual, diferente, mayor que, menor que
- Operadores Lógicos - AND, OR, NOT para combinar condiciones
- Operadores de Asignación - Asignar y modificar valores de variables
- Operadores Bit a Bit - Manipulación a nivel de bits
- Operadores de Identidad y Pertenencia - Verificar identidad y pertenencia
- Resumen de Operadores y Expresiones - Combinando operadores en expresiones complejas
¿Por qué son importantes los operadores?
Los operadores son fundamentales en programación porque:
- Nos permiten realizar cálculos matemáticos
- Facilitan la comparación de valores
- Posibilitan la toma de decisiones lógicas
- Ayudan a manipular y transformar datos
- Son la base para construir expresiones complejas
Analogía del almacén
A lo largo de esta sección, usaremos la analogía del almacén que ya conoces:
- Las variables son como cajas que contienen valores
- Los operadores son herramientas que manipulan estas cajas
- Las expresiones son recetas que combinan operadores y variables
Mapa conceptual
OPERADORES EN PYTHON
|
|-- Matemáticos (+, -, *, /, //, %, **)
| |-- Realizan cálculos numéricos
|
|-- Comparación (==, !=, >, <, >=, <=)
| |-- Comparan valores y devuelven booleanos
|
|-- Lógicos (and, or, not)
| |-- Combinan condiciones booleanas
|
|-- Asignación (=, +=, -=, *=, /=, etc.)
| |-- Asignan y modifican valores de variables
|
|-- Bit a bit (&, |, ^, ~, <<, >>)
| |-- Manipulan bits individuales
|
|-- Identidad/Pertenencia (is, is not, in, not in)
|-- Verifican identidad y pertenencia
¡Comencemos nuestro viaje por el mundo de los operadores en Python!
🧭 Navegación:
- Anterior: Variables y Tipos de Datos
- Siguiente: Control de Flujo – Condicionales
Capítulos de esta sección:
Operadores Matemáticos
🧭 Navegación:
- Anterior: Operadores y Expresiones
- Siguiente: Operadores de Comparación
¡Bienvenido al departamento de cálculos de nuestro almacén digital! Los operadores matemáticos son las herramientas fundamentales que nos permiten realizar cálculos con nuestros datos, como si fuéramos contadores con calculadoras súper inteligentes.
🧮 ¿Qué son los operadores matemáticos?
Los operadores matemáticos son símbolos especiales que realizan operaciones aritméticas sobre números. Son como las teclas de una calculadora empresarial que nos permiten procesar información numérica de manera automática.
🏪 Analogía del almacén: La oficina de contabilidad
Imagina que nuestro almacén tiene una oficina de contabilidad donde:
- Los números son como facturas y documentos con cantidades
- Los operadores son las calculadoras y herramientas de cálculo
- Las operaciones son los procedimientos contables que aplicamos
- Los resultados son los balances y reportes finales
📊 Los operadores matemáticos básicos
➕ Suma (+): Acumulando inventario
# En el almacén: Sumamos productos que llegan
inventario_inicial = 50
productos_nuevos = 25
inventario_total = inventario_inicial + productos_nuevos
print(f"Inventario total: {inventario_total} unidades") # 75 unidades
# Ejemplos prácticos
precio_producto = 299.99
impuestos = 48.00
precio_final = precio_producto + impuestos
print(f"Precio final: ${precio_final}") # $347.99
# Suma de múltiples valores
ventas_lunes = 1500
ventas_martes = 2300
ventas_miercoles = 1800
total_ventas = ventas_lunes + ventas_martes + ventas_miercoles
print(f"Ventas de la semana: ${total_ventas}") # $5600
➖ Resta (-): Descontando del inventario
# En el almacén: Restamos productos vendidos
inventario_actual = 100
productos_vendidos = 15
inventario_restante = inventario_actual - productos_vendidos
print(f"Quedan: {inventario_restante} unidades") # 85 unidades
# Calculando descuentos
precio_original = 599.99
descuento = 120.00
precio_con_descuento = precio_original - descuento
print(f"Precio con descuento: ${precio_con_descuento}") # $479.99
# Calculando diferencias
ventas_objetivo = 10000
ventas_reales = 8500
diferencia = ventas_objetivo - ventas_reales
print(f"Faltan ${diferencia} para cumplir objetivo") # Faltan $1500
✖️ Multiplicación (*): Cálculos de volumen
# En el almacén: Calculamos totales por cantidad
precio_unitario = 25.50
cantidad = 12
total_compra = precio_unitario * cantidad
print(f"Total de la compra: ${total_compra}") # $306.00
# Calculando áreas del almacén
largo_almacen = 50 # metros
ancho_almacen = 30 # metros
area_total = largo_almacen * ancho_almacen
print(f"Área del almacén: {area_total} m²") # 1500 m²
# Proyecciones de ventas
ventas_diarias = 450
dias_mes = 30
proyeccion_mensual = ventas_diarias * dias_mes
print(f"Proyección mensual: ${proyeccion_mensual}") # $13500
➗ División (/): Distribución y promedios
# En el almacén: Dividimos costos entre productos
costo_total_envio = 240.00
num_productos = 8
costo_por_producto = costo_total_envio / num_productos
print(f"Costo de envío por producto: ${costo_por_producto}") # $30.0
# Calculando promedios de ventas
ventas_totales = 15600
num_vendedores = 4
promedio_por_vendedor = ventas_totales / num_vendedores
print(f"Promedio por vendedor: ${promedio_por_vendedor}") # $3900.0
# Calculando velocidad de ventas
productos_vendidos = 450
dias_transcurridos = 15
velocidad_ventas = productos_vendidos / dias_transcurridos
print(f"Vendemos {velocidad_ventas} productos por día") # 30.0
🎯 Operadores matemáticos avanzados
🔢 División entera (//): Cálculos exactos sin decimales
# En el almacén: Calculamos cajas completas
productos_totales = 127
productos_por_caja = 12
cajas_completas = productos_totales // productos_por_caja
print(f"Cajas completas: {cajas_completas}") # 10 cajas
# Calculando turnos de trabajo
horas_totales = 65
horas_por_turno = 8
turnos_completos = horas_totales // horas_por_turno
print(f"Turnos completos: {turnos_completos}") # 8 turnos
# Distribución equitativa
bonificacion_total = 5000
num_empleados = 7
bonificacion_por_empleado = bonificacion_total // num_empleados
print(f"Bonificación por empleado: ${bonificacion_por_empleado}") # $714
🔄 Módulo (%): Calculando sobrantes
# En el almacén: Productos que sobran al formar cajas
productos_totales = 127
productos_por_caja = 12
productos_sueltos = productos_totales % productos_por_caja
print(f"Productos sueltos: {productos_sueltos}") # 7 productos
# Calculando días de la semana
dia_actual = 15 # día del mes
dia_semana = dia_actual % 7
print(f"Día de la semana (0=lunes): {dia_semana}") # 1 (martes)
# Verificando números pares o impares
codigo_producto = 12345
if codigo_producto % 2 == 0:
print("El código es par")
else:
print("El código es impar") # El código es impar
⚡ Potenciación (**): Cálculos exponenciales
# En el almacén: Calculamos espacios cúbicos
lado_contenedor = 3 # metros
volumen = lado_contenedor ** 3
print(f"Volumen del contenedor: {volumen} m³") # 27 m³
# Calculando interés compuesto
capital_inicial = 10000
tasa_interes = 1.05 # 5% anual
anos = 3
capital_final = capital_inicial * (tasa_interes ** anos)
print(f"Capital después de {anos} años: ${capital_final:.2f}") # $11576.25
# Crecimiento exponencial de ventas
ventas_base = 1000
factor_crecimiento = 1.15 # 15% mensual
meses = 6
ventas_proyectadas = ventas_base * (factor_crecimiento ** meses)
print(f"Ventas proyectadas: ${ventas_proyectadas:.2f}") # $2313.06
🔧 Orden de las operaciones (Jerarquía)
Python sigue las reglas matemáticas estándar para el orden de las operaciones:
📋 Prioridad de operadores (de mayor a menor)
- Paréntesis
() - Potenciación
** - Multiplicación, División, División entera, Módulo
*,/,//,% - Suma y Resta
+,-
# Ejemplo sin paréntesis
resultado = 2 + 3 * 4 ** 2
print(f"2 + 3 * 4 ** 2 = {resultado}") # 50
# Se calcula: 2 + 3 * 16 = 2 + 48 = 50
# Ejemplo con paréntesis
resultado = (2 + 3) * 4 ** 2
print(f"(2 + 3) * 4 ** 2 = {resultado}") # 80
# Se calcula: 5 * 16 = 80
# Cálculo empresarial complejo
precio_base = 100
descuento = 0.15
impuesto = 0.16
cantidad = 5
# Sin paréntesis (incorrecto)
total_incorrecto = precio_base - descuento * precio_base + impuesto * cantidad
print(f"Cálculo incorrecto: ${total_incorrecto}") # $85.8
# Con paréntesis (correcto)
total_correcto = (precio_base * (1 - descuento) * (1 + impuesto)) * cantidad
print(f"Cálculo correcto: ${total_correcto}") # $493.0
💡 Casos prácticos del almacén
🏷️ Calculadora de precios con descuentos
# Sistema de precios del almacén
def calcular_precio_final(precio_base, descuento_porcentaje, impuesto_porcentaje, cantidad):
"""Calcula el precio final de una compra en el almacén"""
# Convertir porcentajes a decimales
descuento = descuento_porcentaje / 100
impuesto = impuesto_porcentaje / 100
# Aplicar descuento
precio_con_descuento = precio_base * (1 - descuento)
# Aplicar impuesto
precio_con_impuesto = precio_con_descuento * (1 + impuesto)
# Calcular total por cantidad
total_final = precio_con_impuesto * cantidad
return total_final
# Ejemplo de uso
precio_laptop = 1299.99
descuento_oferta = 20 # 20%
iva = 16 # 16%
cantidad_comprada = 3
total = calcular_precio_final(precio_laptop, descuento_oferta, iva, cantidad_comprada)
print(f"\n🏷️ FACTURA DEL ALMACÉN")
print(f"Producto: Laptop Gaming")
print(f"Precio unitario: ${precio_laptop}")
print(f"Descuento: {descuento_oferta}%")
print(f"IVA: {iva}%")
print(f"Cantidad: {cantidad_comprada}")
print(f"TOTAL A PAGAR: ${total:.2f}")
📦 Calculadora de espacios del almacén
# Sistema de gestión de espacios
def calcular_capacidad_almacen(largo, ancho, alto, espacio_por_producto):
"""Calcula cuántos productos caben en el almacén"""
volumen_total = largo * ancho * alto
capacidad_productos = volumen_total // espacio_por_producto
espacio_sobrante = volumen_total % espacio_por_producto
return capacidad_productos, espacio_sobrante
# Dimensiones del almacén
largo_almacen = 25 # metros
ancho_almacen = 15 # metros
alto_almacen = 4 # metros
espacio_por_caja = 2 # metros cúbicos por caja
cajas_que_caben, espacio_libre = calcular_capacidad_almacen(
largo_almacen, ancho_almacen, alto_almacen, espacio_por_caja
)
print(f"\n📦 ANÁLISIS DE CAPACIDAD")
print(f"Dimensiones del almacén: {largo_almacen}m x {ancho_almacen}m x {alto_almacen}m")
print(f"Volumen total: {largo_almacen * ancho_almacen * alto_almacen} m³")
print(f"Cajas que caben: {cajas_que_caben}")
print(f"Espacio libre: {espacio_libre} m³")
💰 Calculadora de ROI (Retorno de Inversión)
# Sistema de análisis financiero
def calcular_roi(inversion_inicial, ganancia_anual, anos):
"""Calcula el retorno de inversión"""
ganancia_total = ganancia_anual * anos
roi_total = ((ganancia_total - inversion_inicial) / inversion_inicial) * 100
roi_anual = roi_total / anos
return roi_total, roi_anual
# Análisis de inversión en nuevo almacén
inversion = 500000 # $500,000
ganancia_por_ano = 120000 # $120,000 anuales
periodo_analisis = 5 # 5 años
roi_total, roi_anual = calcular_roi(inversion, ganancia_por_ano, periodo_analisis)
print(f"\n💰 ANÁLISIS DE INVERSIÓN")
print(f"Inversión inicial: ${inversion:,}")
print(f"Ganancia anual: ${ganancia_por_ano:,}")
print(f"Período: {periodo_analisis} años")
print(f"ROI total: {roi_total:.1f}%")
print(f"ROI anual promedio: {roi_anual:.1f}%")
# Determinar si es buena inversión
if roi_anual >= 15:
print("✅ Excelente inversión")
elif roi_anual >= 10:
print("✅ Buena inversión")
elif roi_anual >= 5:
print("⚠️ Inversión moderada")
else:
print("❌ Inversión no recomendada")
🚨 Comprueba tu comprensión
🎯 Ejercicio 1: Calculadora de nómina
Crea un programa que calcule el salario neto de un empleado del almacén:
# Datos del empleado
salario_base = 15000 # pesos mensuales
horas_extra = 10 # horas trabajadas extra
pago_por_hora_extra = 150 # pesos por hora extra
bono_productividad = 2000 # pesos
# Deducciones
impuesto_renta = 0.10 # 10%
seguro_social = 0.0625 # 6.25%
seguro_medico = 500 # pesos fijos
# ¿Puedes calcular el salario neto?
# Tu código aquí...
🎯 Ejercicio 2: Distribución de productos
En el almacén llegan 1,847 productos que deben empacarse en cajas de 24 unidades:
productos_totales = 1847
productos_por_caja = 24
# Calcula:
# 1. ¿Cuántas cajas completas se pueden formar?
# 2. ¿Cuántos productos quedan sueltos?
# 3. Si cada caja pesa 5.5 kg, ¿cuál es el peso total?
# Tu código aquí...
🎯 Ejercicio 3: Proyección de crecimiento
Las ventas del almacén crecen 8% cada mes. Si este mes vendiste $50,000:
ventas_actuales = 50000
tasa_crecimiento = 0.08 # 8%
# Calcula las ventas proyectadas para los próximos 6 meses
# Tu código aquí...
📝 Puntos clave para recordar
- ✅ Suma (
+): Acumula valores, como inventario que llega - ✅ Resta (
-): Descuenta valores, como productos vendidos - ✅ Multiplicación (
*): Calcula totales por cantidad - ✅ División (
/): Obtiene promedios y distribuciones - ✅ División entera (
//): Calcula unidades completas - ✅ Módulo (
%): Encuentra sobrantes y restos - ✅ Potenciación (
**): Eleva a potencias, útil para cálculos complejos - ✅ Orden de operaciones: Los paréntesis cambian las prioridades
- ✅ Aplicaciones prácticas: Finanzas, inventarios, espacios, ROI
🎯 Lo que has logrado
¡Felicidades! Ahora dominas las herramientas matemáticas fundamentales de Python. Eres como un contador experto del almacén que puede:
- 🧮 Realizar cualquier cálculo empresarial
- 📊 Procesar datos numéricos automáticamente
- 💰 Crear sistemas de precios y facturación
- 📦 Optimizar espacios y recursos
- 📈 Proyectar crecimiento y analizar inversiones
Estos operadores matemáticos son la base de prácticamente todos los sistemas empresariales y aplicaciones que usarás en tu carrera como programador.
🧭 Navegación:
- Anterior: Operadores y Expresiones
- Siguiente: Operadores de Comparación
En esta sección:
Operadores de Comparación
Los operadores de comparación son como los inspectores de calidad de tu almacén: constantemente evalúan y comparan valores para tomar decisiones. Estos operadores te permiten crear condiciones que determinan el flujo de tu programa, como decidir si un producto está en stock, si un precio es competitivo, o si un empleado tiene la experiencia suficiente.
Imagina que eres el supervisor de un almacén y necesitas tomar decisiones basadas en comparaciones: ¿Este producto cuesta más que el límite del presupuesto? ¿Tenemos suficiente inventario? ¿Este empleado es mayor de edad? Los operadores de comparación te dan las herramientas para hacer estas evaluaciones.
Los Seis Operadores de Comparación Fundamentales
1. Igualdad (==)
El operador == verifica si dos valores son iguales.
# Comparaciones básicas
precio_producto = 25.99
precio_limite = 25.99
print(f"¿El precio es igual al límite? {precio_producto == precio_limite}") # True
# Con cadenas
nombre_producto = "Leche"
producto_buscado = "Leche"
print(f"¿Es el producto correcto? {nombre_producto == producto_buscado}") # True
# Con listas
inventario_esperado = [10, 20, 15]
inventario_actual = [10, 20, 15]
print(f"¿El inventario coincide? {inventario_esperado == inventario_actual}") # True
Casos Prácticos de Igualdad
# Sistema de validación de pedidos
class ValidadorPedidos:
def __init__(self):
self.productos_validos = {"leche", "pan", "huevos", "queso"}
self.precio_fijo = {"pan": 2.50, "leche": 3.00}
def validar_pedido(self, producto, cantidad, precio_unitario):
"""Validar un pedido completo"""
errores = []
# Verificar producto válido
if producto not in self.productos_validos:
errores.append(f"Producto '{producto}' no válido")
# Verificar cantidad positiva
if cantidad == 0:
errores.append("La cantidad no puede ser cero")
# Verificar precio para productos con precio fijo
if producto in self.precio_fijo:
precio_correcto = self.precio_fijo[producto]
if precio_unitario != precio_correcto:
errores.append(f"Precio incorrecto para {producto}: esperado ${precio_correcto}, recibido ${precio_unitario}")
return len(errores) == 0, errores
# Ejemplos de validación
validador = ValidadorPedidos()
pedidos_test = [
("pan", 5, 2.50), # Válido
("leche", 0, 3.00), # Error: cantidad cero
("pan", 3, 2.75), # Error: precio incorrecto
("cerveza", 2, 5.00), # Error: producto no válido
]
print("=== VALIDACIÓN DE PEDIDOS ===")
for producto, cantidad, precio in pedidos_test:
valido, errores = validador.validar_pedido(producto, cantidad, precio)
estado = "✅ VÁLIDO" if valido else "❌ INVÁLIDO"
print(f"{producto} (x{cantidad} @${precio}): {estado}")
if errores:
for error in errores:
print(f" - {error}")
2. Desigualdad (!=)
El operador != verifica si dos valores son diferentes.
# Verificar cambios en el inventario
inventario_anterior = {"leche": 50, "pan": 25, "huevos": 100}
inventario_actual = {"leche": 45, "pan": 25, "huevos": 95}
for producto in inventario_anterior:
cantidad_anterior = inventario_anterior[producto]
cantidad_actual = inventario_actual[producto]
if cantidad_actual != cantidad_anterior:
diferencia = cantidad_actual - cantidad_anterior
print(f"{producto}: {cantidad_anterior} → {cantidad_actual} (cambio: {diferencia:+d})")
else:
print(f"{producto}: sin cambios ({cantidad_actual})")
# Control de acceso
def verificar_acceso(usuario_actual, usuario_autorizado):
if usuario_actual != usuario_autorizado:
print(f"❌ Acceso denegado. Usuario: {usuario_actual}")
return False
else:
print(f"✅ Acceso permitido. Bienvenido, {usuario_actual}")
return True
# Ejemplos
verificar_acceso("juan", "juan") # Permitido
verificar_acceso("maria", "juan") # Denegado
3. Menor que (<)
El operador < verifica si el valor de la izquierda es menor que el de la derecha.
# Control de stock mínimo
def verificar_stock_minimo(producto, cantidad_actual, stock_minimo):
if cantidad_actual < stock_minimo:
print(f"⚠️ ALERTA: {producto} tiene stock bajo ({cantidad_actual} < {stock_minimo})")
return True
else:
print(f"✅ {producto}: stock suficiente ({cantidad_actual} unidades)")
return False
# Ejemplos de verificación
productos_inventario = [
("Leche", 15, 20),
("Pan", 45, 30),
("Huevos", 8, 25),
("Queso", 35, 15)
]
print("=== CONTROL DE STOCK MÍNIMO ===")
productos_bajo_stock = []
for producto, cantidad, minimo in productos_inventario:
if verificar_stock_minimo(producto, cantidad, minimo):
productos_bajo_stock.append(producto)
if productos_bajo_stock:
print(f"\n📋 Productos para reordenar: {', '.join(productos_bajo_stock)}")
4. Menor o igual que (<=)
El operador <= verifica si el valor de la izquierda es menor o igual que el de la derecha.
# Sistema de descuentos por volumen
class CalculadorDescuento:
def __init__(self):
# Niveles de descuento por cantidad
self.niveles_descuento = [
(10, 0), # 0-10 unidades: sin descuento
(50, 5), # 11-50 unidades: 5% descuento
(100, 10), # 51-100 unidades: 10% descuento
(500, 15), # 101-500 unidades: 15% descuento
(float('inf'), 20) # 501+ unidades: 20% descuento
]
def calcular_descuento(self, cantidad):
"""Calcular porcentaje de descuento basado en cantidad"""
for limite, descuento in self.niveles_descuento:
if cantidad <= limite:
return descuento
return 0 # Por si acaso, aunque no debería llegar aquí
# Ejemplos de cálculo
calculadora = CalculadorDescuento()
cantidades_test = [5, 25, 75, 150, 600]
print("=== SISTEMA DE DESCUENTOS ===")
for cantidad in cantidades_test:
descuento = calculadora.calcular_descuento(cantidad)
print(f"{cantidad} unidades → {descuento}% de descuento")
# Sistema de clasificación de empleados por experiencia
def clasificar_empleado(años_experiencia):
if años_experiencia <= 1:
return "Principiante"
elif años_experiencia <= 3:
return "Junior"
elif años_experiencia <= 7:
return "Intermedio"
elif años_experiencia <= 15:
return "Senior"
else:
return "Experto"
# Ejemplos
empleados = [
("Ana", 0.5),
("Carlos", 2),
("María", 5),
("Roberto", 12),
("Elena", 20)
]
print("\n=== CLASIFICACIÓN DE EMPLEADOS ===")
for nombre, experiencia in empleados:
categoria = clasificar_empleado(experiencia)
print(f"{nombre} ({experiencia} años): {categoria}")
5. Mayor que (>)
El operador > verifica si el valor de la izquierda es mayor que el de la derecha.
# Sistema de alertas por temperatura
class MonitorTemperatura:
def __init__(self):
self.temperatura_maxima = {
"lacteos": 4,
"carnes": 2,
"congelados": -18,
"ambiente": 25
}
def verificar_temperatura(self, seccion, temperatura_actual):
"""Verificar si la temperatura está dentro del rango seguro"""
if seccion not in self.temperatura_maxima:
return "Sección no reconocida"
temp_max = self.temperatura_maxima[seccion]
if temperatura_actual > temp_max:
diferencia = temperatura_actual - temp_max
return f"🚨 TEMPERATURA ALTA: {temperatura_actual}°C (límite: {temp_max}°C, exceso: +{diferencia}°C)"
else:
return f"✅ Temperatura normal: {temperatura_actual}°C (límite: {temp_max}°C)"
# Sistema de monitoreo
monitor = MonitorTemperatura()
lecturas_temperatura = [
("lacteos", 6),
("carnes", 1),
("congelados", -15),
("ambiente", 28),
("lacteos", 3)
]
print("=== MONITOREO DE TEMPERATURA ===")
for seccion, temp in lecturas_temperatura:
resultado = monitor.verificar_temperatura(seccion, temp)
print(f"{seccion.title()}: {resultado}")
# Control de presupuesto
def evaluar_compra(precio_producto, presupuesto_disponible):
if precio_producto > presupuesto_disponible:
exceso = precio_producto - presupuesto_disponible
return False, f"Exceso de presupuesto: ${exceso:.2f}"
else:
restante = presupuesto_disponible - precio_producto
return True, f"Compra autorizada. Restante: ${restante:.2f}"
# Ejemplos
presupuesto = 1000.00
compras_propuestas = [750.50, 1200.00, 999.99, 1000.01]
print("\n=== CONTROL DE PRESUPUESTO ===")
for precio in compras_propuestas:
autorizada, mensaje = evaluar_compra(precio, presupuesto)
estado = "✅ AUTORIZADA" if autorizada else "❌ RECHAZADA"
print(f"${precio:.2f}: {estado} - {mensaje}")
6. Mayor o igual que (>=)
El operador >= verifica si el valor de la izquierda es mayor o igual que el de la derecha.
# Sistema de control de edad para productos restringidos
class ControlEdad:
def __init__(self):
self.productos_restringidos = {
"alcohol": 18,
"tabaco": 18,
"medicamentos": 16,
"herramientas_electricas": 18,
"productos_quimicos": 21
}
def puede_comprar(self, producto, edad_cliente):
"""Verificar si el cliente puede comprar el producto"""
if producto not in self.productos_restringidos:
return True, "Producto sin restricción de edad"
edad_minima = self.productos_restringidos[producto]
if edad_cliente >= edad_minima:
return True, f"Edad suficiente ({edad_cliente} >= {edad_minima})"
else:
diferencia = edad_minima - edad_cliente
return False, f"Edad insuficiente. Faltan {diferencia} años"
# Ejemplos de control
control = ControlEdad()
transacciones = [
("alcohol", 20),
("tabaco", 17),
("medicamentos", 16),
("productos_quimicos", 19),
("leche", 15) # Sin restricción
]
print("=== CONTROL DE EDAD ===")
for producto, edad in transacciones:
puede, razon = control.puede_comprar(producto, edad)
estado = "✅ PERMITIDO" if puede else "❌ DENEGADO"
print(f"{producto} (cliente {edad} años): {estado} - {razon}")
# Sistema de calificación de rendimiento
def evaluar_rendimiento(puntuacion):
"""Evaluar rendimiento basado en puntuación"""
if puntuacion >= 95:
return "Excelente", "🏆"
elif puntuacion >= 85:
return "Muy bueno", "🥉"
elif puntuacion >= 75:
return "Bueno", "👍"
elif puntuacion >= 65:
return "Satisfactorio", "👌"
else:
return "Necesita mejorar", "📈"
# Evaluaciones de empleados
empleados_evaluacion = [
("Ana", 97),
("Carlos", 88),
("María", 76),
("Roberto", 63),
("Elena", 91)
]
print("\n=== EVALUACIONES DE RENDIMIENTO ===")
for nombre, puntuacion in empleados_evaluacion:
categoria, emoji = evaluar_rendimiento(puntuacion)
print(f"{nombre}: {puntuacion} puntos → {categoria} {emoji}")
Comparaciones con Diferentes Tipos de Datos
Comparaciones Numéricas
# Trabajando con diferentes tipos numéricos
precio_entero = 25
precio_decimal = 25.0
precio_string = "25"
print(f"Entero == Decimal: {precio_entero == precio_decimal}") # True
print(f"Entero == String: {precio_entero == int(precio_string)}") # True (después de conversión)
print(f"Decimal > Entero: {precio_decimal > precio_entero}") # False
# Comparaciones con flotantes - cuidado con la precisión
precio1 = 0.1 + 0.2
precio2 = 0.3
print(f"0.1 + 0.2 == 0.3: {precio1 == precio2}") # False! (problema de precisión)
print(f"Valores: {precio1} vs {precio2}")
# Solución para flotantes
def comparar_flotantes(a, b, tolerancia=1e-9):
return abs(a - b) < tolerancia
print(f"Comparación segura: {comparar_flotantes(precio1, precio2)}") # True
Comparaciones de Cadenas
# Comparaciones alfabéticas
productos = ["Manzana", "Banana", "Cereza", "Durazno"]
# Ordenamiento alfabético
for i in range(len(productos) - 1):
for j in range(i + 1, len(productos)):
if productos[i] > productos[j]: # Comparación alfabética
productos[i], productos[j] = productos[j], productos[i]
print(f"Productos ordenados: {productos}")
# Comparaciones sensibles a mayúsculas/minúsculas
nombre1 = "Juan"
nombre2 = "juan"
print(f"'Juan' == 'juan': {nombre1 == nombre2}") # False
print(f"'Juan' == 'juan' (insensible): {nombre1.lower() == nombre2.lower()}") # True
# Búsqueda de productos
def buscar_producto(lista_productos, producto_buscado, case_sensitive=False):
"""Buscar un producto en la lista"""
if not case_sensitive:
producto_buscado = producto_buscado.lower()
lista_productos = [p.lower() for p in lista_productos]
for i, producto in enumerate(lista_productos):
if producto == producto_buscado:
return i
return -1
productos_almacen = ["Leche", "Pan", "Huevos", "Queso"]
print(f"Buscar 'leche': {buscar_producto(productos_almacen, 'leche')}") # 0 (encontrado)
print(f"Buscar 'HUEVOS': {buscar_producto(productos_almacen, 'HUEVOS')}") # 2 (encontrado)
print(f"Buscar 'Yogur': {buscar_producto(productos_almacen, 'Yogur')}") # -1 (no encontrado)
Aplicaciones Prácticas Avanzadas
Sistema de Gestión de Inventario
class GestorInventario:
def __init__(self):
self.productos = {}
self.alertas_stock = {}
self.historial_movimientos = []
def agregar_producto(self, nombre, cantidad, precio, stock_minimo):
"""Agregar un producto al inventario"""
self.productos[nombre] = {
"cantidad": cantidad,
"precio": precio,
"stock_minimo": stock_minimo
}
self.alertas_stock[nombre] = False
def actualizar_stock(self, nombre, nueva_cantidad, motivo="Actualización manual"):
"""Actualizar el stock de un producto"""
if nombre not in self.productos:
return False, "Producto no encontrado"
cantidad_anterior = self.productos[nombre]["cantidad"]
# Registrar movimiento
movimiento = {
"producto": nombre,
"cantidad_anterior": cantidad_anterior,
"cantidad_nueva": nueva_cantidad,
"diferencia": nueva_cantidad - cantidad_anterior,
"motivo": motivo
}
self.historial_movimientos.append(movimiento)
# Actualizar cantidad
self.productos[nombre]["cantidad"] = nueva_cantidad
return True, f"Stock actualizado: {cantidad_anterior} → {nueva_cantidad}"
def verificar_alertas(self):
"""Verificar qué productos necesitan reabastecimiento"""
alertas = []
for nombre, info in self.productos.items():
cantidad = info["cantidad"]
minimo = info["stock_minimo"]
# Verificar diferentes niveles de alerta
if cantidad == 0:
nivel = "AGOTADO"
urgencia = "🚨"
elif cantidad < minimo:
nivel = "STOCK BAJO"
urgencia = "⚠️"
elif cantidad <= minimo * 1.2: # 20% por encima del mínimo
nivel = "PRECAUCIÓN"
urgencia = "⚡"
else:
continue
alertas.append({
"producto": nombre,
"cantidad": cantidad,
"minimo": minimo,
"nivel": nivel,
"urgencia": urgencia
})
return alertas
def generar_reporte_stock(self):
"""Generar reporte completo del stock"""
print("=" * 60)
print("REPORTE DE INVENTARIO")
print("=" * 60)
for nombre, info in self.productos.items():
cantidad = info["cantidad"]
precio = info["precio"]
minimo = info["stock_minimo"]
valor_total = cantidad * precio
# Determinar estado
if cantidad == 0:
estado = "🚨 AGOTADO"
elif cantidad < minimo:
estado = "⚠️ BAJO"
elif cantidad <= minimo * 1.2:
estado = "⚡ PRECAUCIÓN"
else:
estado = "✅ OK"
print(f"{nombre:20} | {cantidad:3d} u. | ${precio:6.2f} | ${valor_total:8.2f} | {estado}")
# Mostrar alertas
alertas = self.verificar_alertas()
if alertas:
print("\n" + "=" * 40)
print("ALERTAS DE STOCK")
print("=" * 40)
for alerta in alertas:
print(f"{alerta['urgencia']} {alerta['producto']}: {alerta['cantidad']} u. "
f"(mín: {alerta['minimo']}) - {alerta['nivel']}")
# Ejemplo de uso del sistema
gestor = GestorInventario()
# Agregar productos
productos_iniciales = [
("Leche", 45, 3.50, 20),
("Pan", 12, 2.25, 30),
("Huevos", 8, 4.80, 25),
("Queso", 25, 8.90, 15),
("Yogur", 0, 2.75, 10)
]
for nombre, cantidad, precio, minimo in productos_iniciales:
gestor.agregar_producto(nombre, cantidad, precio, minimo)
# Simular algunas ventas
gestor.actualizar_stock("Leche", 38, "Venta")
gestor.actualizar_stock("Pan", 5, "Venta")
gestor.actualizar_stock("Huevos", 3, "Venta")
# Generar reporte
gestor.generar_reporte_stock()
Sistema de Clasificación de Clientes
class ClasificadorClientes:
def __init__(self):
self.criterios = {
"vip": {"compras_min": 50, "valor_min": 5000, "antiguedad_min": 12},
"premium": {"compras_min": 20, "valor_min": 2000, "antiguedad_min": 6},
"regular": {"compras_min": 5, "valor_min": 500, "antiguedad_min": 1},
"nuevo": {"compras_min": 0, "valor_min": 0, "antiguedad_min": 0}
}
def clasificar_cliente(self, num_compras, valor_total, meses_antiguedad):
"""Clasificar cliente basado en sus métricas"""
# Verificar VIP (todos los criterios deben cumplirse)
vip = self.criterios["vip"]
if (num_compras >= vip["compras_min"] and
valor_total >= vip["valor_min"] and
meses_antiguedad >= vip["antiguedad_min"]):
return "VIP", "🌟"
# Verificar Premium
premium = self.criterios["premium"]
if (num_compras >= premium["compras_min"] and
valor_total >= premium["valor_min"] and
meses_antiguedad >= premium["antiguedad_min"]):
return "Premium", "💎"
# Verificar Regular
regular = self.criterios["regular"]
if (num_compras >= regular["compras_min"] and
valor_total >= regular["valor_min"] and
meses_antiguedad >= regular["antiguedad_min"]):
return "Regular", "👤"
# Por defecto, Nuevo
return "Nuevo", "🆕"
def calcular_descuento(self, categoria):
"""Calcular descuento basado en la categoría del cliente"""
descuentos = {
"VIP": 15,
"Premium": 10,
"Regular": 5,
"Nuevo": 0
}
return descuentos.get(categoria, 0)
# Ejemplo de clasificación
clasificador = ClasificadorClientes()
clientes_datos = [
("Ana García", 65, 7500, 18),
("Carlos López", 25, 2800, 8),
("María Rodríguez", 8, 650, 3),
("Roberto Silva", 2, 150, 1),
("Elena Martínez", 45, 4200, 10)
]
print("=== CLASIFICACIÓN DE CLIENTES ===")
for nombre, compras, valor, antiguedad in clientes_datos:
categoria, emoji = clasificador.clasificar_cliente(compras, valor, antiguedad)
descuento = clasificador.calcular_descuento(categoria)
print(f"{nombre:20} | {compras:2d} compras | ${valor:6.0f} | {antiguedad:2d} meses")
print(f"{'':20} | {emoji} {categoria:8} | Descuento: {descuento}%")
print("-" * 60)
Trucos y Consejos Profesionales
Comparaciones Encadenadas
# Python permite encadenar comparaciones de forma elegante
edad = 25
salario = 35000
# En lugar de: edad >= 18 and edad <= 65 and salario >= 30000
if 18 <= edad <= 65 and salario >= 30000:
print("Candidato elegible para el puesto")
# Verificar rangos de valores
temperatura = 22
if 18 <= temperatura <= 25:
print("Temperatura confortable")
# Múltiples comparaciones
precio = 150
if 100 <= precio <= 200:
print("Precio en rango medio")
Comparaciones Seguras con None
def comparar_seguro(valor1, valor2):
"""Comparar valores manejando casos especiales"""
# Manejar None
if valor1 is None and valor2 is None:
return True
if valor1 is None or valor2 is None:
return False
# Comparación normal
return valor1 == valor2
# Ejemplos
print(comparar_seguro(None, None)) # True
print(comparar_seguro(None, 5)) # False
print(comparar_seguro(5, 5)) # True
Tabla de Referencia Rápida
| Operador | Significado | Ejemplo | Resultado |
|---|---|---|---|
== | Igual a | 5 == 5 | True |
!= | No igual a | 5 != 3 | True |
< | Menor que | 3 < 5 | True |
<= | Menor o igual que | 5 <= 5 | True |
> | Mayor que | 7 > 3 | True |
>= | Mayor o igual que | 5 >= 5 | True |
Errores Comunes y Cómo Evitarlos
❌ Error: Confundir asignación (=) con comparación (==)
# ❌ INCORRECTO
precio = 100
if precio = 50: # Error de sintaxis
print("Precio es 50")
# ✅ CORRECTO
precio = 100
if precio == 50: # Comparación
print("Precio es 50")
❌ Error: Comparar flotantes directamente
# ❌ PROBLEMÁTICO
precio1 = 0.1 + 0.2
precio2 = 0.3
if precio1 == precio2: # Puede fallar por precisión
print("Precios iguales")
# ✅ CORRECTO
def flotantes_iguales(a, b, tolerancia=1e-9):
return abs(a - b) < tolerancia
if flotantes_iguales(precio1, precio2):
print("Precios iguales")
Los operadores de comparación son la base para tomar decisiones inteligentes en tus programas. ¡Combínalos con operadores lógicos para crear condiciones poderosas y flexibles!
Operadores Lógicos
Los operadores lógicos son como los supervisores de tu almacén que toman decisiones basadas en múltiples condiciones. ¿Recuerdas cuando hablamos de las condiciones booleanas? Los operadores lógicos te permiten combinar varias de estas condiciones para tomar decisiones más complejas.
Imagina que estás revisando el inventario de tu almacén y necesitas encontrar productos que cumplan con múltiples criterios. Los operadores lógicos te ayudan a combinar estas condiciones de manera elegante.
Los Tres Operadores Lógicos Fundamentales
1. El Operador and (Y)
El operador and es como un supervisor muy estricto: ambas condiciones deben ser verdaderas para que el resultado sea True.
# Verificando inventario del almacén
stock_suficiente = True
precio_razonable = True
# Ambas condiciones deben cumplirse
comprar_producto = stock_suficiente and precio_razonable
print(f"¿Comprar producto? {comprar_producto}") # True
# Si una falla, el resultado es False
stock_suficiente = False
comprar_producto = stock_suficiente and precio_razonable
print(f"¿Comprar producto? {comprar_producto}") # False
Ejemplos Prácticos con and
# Sistema de acceso al almacén
usuario_autorizado = True
horario_laboral = True
sistema_activo = True
acceso_permitido = usuario_autorizado and horario_laboral and sistema_activo
print(f"Acceso permitido: {acceso_permitido}")
# Validación de pedidos
cantidad = 50
precio_unitario = 15.99
pedido_valido = cantidad > 0 and precio_unitario > 0
print(f"Pedido válido: {pedido_valido}")
# Verificación de empleado
edad = 25
experiencia_años = 3
puede_operar_montacargas = edad >= 18 and experiencia_años >= 2
print(f"Puede operar montacargas: {puede_operar_montacargas}")
2. El Operador or (O)
El operador or es más flexible: al menos una condición debe ser verdadera para que el resultado sea True.
# Métodos de pago aceptados
pago_efectivo = False
pago_tarjeta = True
pago_transferencia = False
pago_aceptado = pago_efectivo or pago_tarjeta or pago_transferencia
print(f"Pago aceptado: {pago_aceptado}") # True (al menos uno es True)
# Horarios de atención
es_dia_laborable = False
es_sabado = True
almacen_abierto = es_dia_laborable or es_sabado
print(f"Almacén abierto: {almacen_abierto}") # True
Ejemplos Prácticos con or
# Sistema de alertas
temperatura_alta = False
humedad_alta = True
presion_baja = False
alerta_ambiental = temperatura_alta or humedad_alta or presion_baja
print(f"Activar alerta: {alerta_ambiental}") # True
# Descuentos por volumen
es_cliente_premium = False
compra_mayor_1000 = True
aplicar_descuento = es_cliente_premium or compra_mayor_1000
print(f"Aplicar descuento: {aplicar_descuento}") # True
# Autorización de devolución
producto_defectuoso = False
cliente_insatisfecho = True
error_facturacion = False
autorizar_devolucion = producto_defectuoso or cliente_insatisfecho or error_facturacion
print(f"Autorizar devolución: {autorizar_devolucion}") # True
3. El Operador not (NO)
El operador not es como invertir una decisión: convierte True en False y viceversa.
# Estado del sistema
sistema_funcionando = True
sistema_en_mantenimiento = not sistema_funcionando
print(f"Sistema funcionando: {sistema_funcionando}") # True
print(f"Sistema en mantenimiento: {sistema_en_mantenimiento}") # False
# Control de acceso
acceso_denegado = False
acceso_permitido = not acceso_denegado
print(f"Acceso permitido: {acceso_permitido}") # True
Ejemplos Prácticos con not
# Gestión de inventario
producto_disponible = True
producto_agotado = not producto_disponible
if not producto_agotado:
print("Producto disponible para venta")
# Validación de datos
campo_vacio = False
campo_completo = not campo_vacio
if not campo_vacio:
print("Todos los campos están completos")
# Estado de empleados
empleado_activo = True
empleado_inactivo = not empleado_activo
if not empleado_inactivo:
print("Empleado puede acceder al sistema")
Combinando Operadores Lógicos
La verdadera potencia viene cuando combinas estos operadores para crear lógica más compleja:
# Sistema integral de gestión de almacén
def evaluar_pedido(stock, precio, cliente_premium, pago_confirmado):
# Condiciones básicas
stock_disponible = stock > 0
precio_valido = precio > 0
# Condición de cliente
cliente_valido = cliente_premium or pago_confirmado
# Decisión final
procesar_pedido = stock_disponible and precio_valido and cliente_valido
return procesar_pedido
# Ejemplos de uso
resultado1 = evaluar_pedido(stock=10, precio=25.99, cliente_premium=True, pago_confirmado=False)
print(f"Pedido 1 aprobado: {resultado1}") # True
resultado2 = evaluar_pedido(stock=0, precio=25.99, cliente_premium=True, pago_confirmado=True)
print(f"Pedido 2 aprobado: {resultado2}") # False (sin stock)
resultado3 = evaluar_pedido(stock=5, precio=15.99, cliente_premium=False, pago_confirmado=True)
print(f"Pedido 3 aprobado: {resultado3}") # True
Precedencia de Operadores Lógicos
Python evalúa los operadores lógicos en este orden:
not(primero)and(segundo)or(último)
# Sin paréntesis
resultado = True or False and not True
# Se evalúa como: True or (False and (not True))
# Se evalúa como: True or (False and False)
# Se evalúa como: True or False
# Resultado: True
print(resultado) # True
# Con paréntesis para mayor claridad
resultado_claro = (True or False) and (not True)
# Se evalúa como: True and False
# Resultado: False
print(resultado_claro) # False
Ejemplos del Mundo Real
Sistema de Alarmas del Almacén
def verificar_seguridad(hora, movimiento_detectado, puerta_abierta, personal_autorizado):
# Horario fuera de oficina (antes de 7 AM o después de 6 PM)
fuera_horario = hora < 7 or hora > 18
# Actividad sospechosa
actividad_sospechosa = movimiento_detectado and puerta_abierta
# Condición de alarma
activar_alarma = fuera_horario and actividad_sospechosa and not personal_autorizado
return activar_alarma
# Pruebas del sistema
print("=== PRUEBAS DEL SISTEMA DE ALARMAS ===")
print(f"Caso 1: {verificar_seguridad(hora=20, movimiento_detectado=True, puerta_abierta=True, personal_autorizado=False)}") # True
print(f"Caso 2: {verificar_seguridad(hora=10, movimiento_detectado=True, puerta_abierta=True, personal_autorizado=False)}") # False
print(f"Caso 3: {verificar_seguridad(hora=20, movimiento_detectado=True, puerta_abierta=True, personal_autorizado=True)}") # False
Sistema de Descuentos
def calcular_descuento(cliente_premium, compra_mayor_500, es_cumpleanos, primera_compra):
# Descuento por cliente premium O compra grande
descuento_basico = cliente_premium or compra_mayor_500
# Descuento especial
descuento_especial = es_cumpleanos or primera_compra
# Descuento final
tiene_descuento = descuento_basico or descuento_especial
if tiene_descuento:
if cliente_premium and compra_mayor_500:
return 20 # Descuento máximo
elif descuento_especial:
return 15 # Descuento especial
else:
return 10 # Descuento básico
return 0 # Sin descuento
# Ejemplos
print("=== SISTEMA DE DESCUENTOS ===")
print(f"Cliente premium con compra grande: {calcular_descuento(True, True, False, False)}%") # 20%
print(f"Primera compra: {calcular_descuento(False, False, False, True)}%") # 15%
print(f"Cliente regular: {calcular_descuento(False, False, False, False)}%") # 0%
Trucos y Consejos Profesionales
1. Evaluación Perezosa (Short-circuit Evaluation)
Python es inteligente y no evalúa expresiones innecesarias:
# Con 'and': si el primer valor es False, no evalúa el segundo
stock = 0
precio = 100
# Como stock es 0 (False), no se evalúa precio > 0
resultado = stock > 0 and precio > 0
print(resultado) # False
# Con 'or': si el primer valor es True, no evalúa el segundo
es_admin = True
edad_suficiente = False # No se evalúa porque es_admin ya es True
acceso = es_admin or edad_suficiente
print(acceso) # True
2. Usar Paréntesis para Claridad
# Difícil de leer
resultado = cliente_premium or compra_grande and not producto_agotado or es_oferta
# Más claro
resultado = cliente_premium or (compra_grande and not producto_agotado) or es_oferta
3. Variables Booleanas Descriptivas
# En lugar de esto:
if not (edad < 18 or experiencia < 1):
print("Puede operar")
# Mejor así:
menor_de_edad = edad < 18
sin_experiencia = experiencia < 1
no_calificado = menor_de_edad or sin_experiencia
if not no_calificado:
print("Puede operar")
Ejercicios Prácticos
# 🎯 Ejercicio 1: Sistema de Control de Calidad
def control_calidad(peso, color_correcto, sin_defectos, empaque_intacto):
"""
Un producto pasa control de calidad si:
- Tiene el peso correcto Y color correcto Y sin defectos
- O si tiene empaque intacto Y sin defectos (producto de excepción)
"""
# Tu código aquí
pass
# 🎯 Ejercicio 2: Horario de Atención
def almacen_abierto(dia_semana, hora, es_feriado):
"""
El almacén está abierto si:
- Es día laborable (1-5) Y hora entre 8-18 Y no es feriado
- O es sábado (6) Y hora entre 9-14 Y no es feriado
"""
# Tu código aquí
pass
# 🎯 Ejercicio 3: Sistema de Envío
def calcular_envio(peso, destino_nacional, cliente_premium, compra_mayor_100):
"""
Envío gratis si:
- Es destino nacional Y (cliente premium O compra mayor a $100)
- O peso menor a 5kg Y destino nacional
"""
# Tu código aquí
pass
Resumen de Operadores Lógicos
| Operador | Descripción | Ejemplo | Resultado |
|---|---|---|---|
and | Ambas condiciones verdaderas | True and False | False |
or | Al menos una condición verdadera | True or False | True |
not | Invierte el valor booleano | not True | False |
Los operadores lógicos son fundamentales para crear programas inteligentes que puedan tomar decisiones complejas. ¡Dominarlos te convertirá en un programador mucho más eficiente!
En el próximo capítulo, exploraremos los operadores de comparación que trabajan de la mano con los operadores lógicos para crear condiciones poderosas.
Operadores de Asignación
Los operadores de asignación son como los empleados eficientes de tu almacén que no solo mueven mercancía, sino que también realizan operaciones mientras la transportan. En lugar de hacer dos trabajos separados (calcular y luego asignar), estos operadores combinan ambas acciones en una sola, más eficiente y elegante.
Imagina que tienes un empleado que, mientras mueve cajas, también las cuenta, las clasifica o ajusta su inventario. Los operadores de asignación hacen exactamente eso: toman un valor, realizan una operación con él, y lo guardan de vuelta en la misma variable.
El Operador de Asignación Básico (=)
Antes de explorar los operadores compuestos, recordemos el operador de asignación básico:
# Asignación simple
inventario_leche = 50
precio_producto = 25.99
nombre_cliente = "Ana García"
# El operador = asigna el valor de la derecha a la variable de la izquierda
print(f"Inventario: {inventario_leche}")
print(f"Precio: ${precio_producto}")
print(f"Cliente: {nombre_cliente}")
Operadores de Asignación Compuesta
1. Asignación con Suma (+=)
Suma un valor a la variable y guarda el resultado en la misma variable.
# Sistema de gestión de inventario
stock_inicial = 100
# Llega un nuevo pedido de 25 unidades
stock_inicial += 25 # Equivale a: stock_inicial = stock_inicial + 25
print(f"Stock después de recibir mercancía: {stock_inicial}") # 125
# Venta de 30 unidades (usamos -= que veremos después)
stock_inicial -= 30
print(f"Stock después de venta: {stock_inicial}") # 95
# Ejemplo con strings - concatenación
mensaje_bienvenida = "Bienvenido"
mensaje_bienvenida += " al almacén"
mensaje_bienvenida += " digital"
print(mensaje_bienvenida) # "Bienvenido al almacén digital"
# Ejemplo con listas - agregar elementos
productos_vendidos = ["leche", "pan"]
productos_vendidos += ["huevos", "queso"] # Agregar múltiples elementos
print(f"Productos vendidos: {productos_vendidos}")
2. Asignación con Resta (-=)
# Control de presupuesto
presupuesto_mensual = 5000.00
# Gasto en mercancía
presupuesto_mensual -= 1200.50
print(f"Presupuesto después de compra: ${presupuesto_mensual:.2f}")
# Gasto en salarios
presupuesto_mensual -= 2500.00
print(f"Presupuesto después de salarios: ${presupuesto_mensual:.2f}")
# Ejemplo práctico: sistema de puntos de cliente
class ClienteLoyal:
def __init__(self, nombre, puntos=0):
self.nombre = nombre
self.puntos = puntos
def compra(self, monto):
# 1 punto por cada dólar gastado
self.puntos += int(monto)
print(f"{self.nombre} ganó {int(monto)} puntos. Total: {self.puntos}")
def canjear_puntos(self, puntos_usar):
if self.puntos >= puntos_usar:
self.puntos -= puntos_usar
descuento = puntos_usar * 0.01 # 1 centavo por punto
print(f"{self.nombre} canjeó {puntos_usar} puntos por ${descuento:.2f}")
return descuento
else:
print(f"Puntos insuficientes. Disponibles: {self.puntos}")
return 0
# Ejemplo de uso
cliente = ClienteLoyal("María")
cliente.compra(150.75) # Gana 150 puntos
cliente.compra(89.25) # Gana 89 puntos más
cliente.canjear_puntos(100) # Usa 100 puntos
3. Asignación con Multiplicación (*=)
# Cálculo de precios con inflación
precio_base = 10.50
# Inflación del 8%
precio_base *= 1.08
print(f"Precio con inflación: ${precio_base:.2f}")
# Descuento del 15% (multiplicar por 0.85)
precio_con_descuento = precio_base
precio_con_descuento *= 0.85
print(f"Precio final con descuento: ${precio_con_descuento:.2f}")
# Ejemplo con listas - repetición
etiquetas_promocion = ["OFERTA"]
etiquetas_promocion *= 3 # Repetir 3 veces
print(etiquetas_promocion) # ['OFERTA', 'OFERTA', 'OFERTA']
# Sistema de multiplicadores de ventas
class VendedorComision:
def __init__(self, nombre, ventas_base=0):
self.nombre = nombre
self.ventas = ventas_base
self.multiplicador = 1.0
def establecer_multiplicador(self, categoria_vendedor):
multiplicadores = {
"trainee": 1.0,
"junior": 1.2,
"senior": 1.5,
"lead": 2.0
}
self.multiplicador = multiplicadores.get(categoria_vendedor, 1.0)
def registrar_venta(self, monto):
# Aplicar multiplicador a la venta
venta_ajustada = monto
venta_ajustada *= self.multiplicador
self.ventas += venta_ajustada
print(f"{self.nombre}: ${monto} → ${venta_ajustada:.2f} (x{self.multiplicador})")
vendedor = VendedorComision("Carlos")
vendedor.establecer_multiplicador("senior")
vendedor.registrar_venta(1000) # $1000 → $1500
4. Asignación con División (/=)
# División de gastos entre socios
gasto_total = 1200.00
numero_socios = 3
# Dividir el gasto
gasto_por_socio = gasto_total
gasto_por_socio /= numero_socios
print(f"Cada socio paga: ${gasto_por_socio:.2f}")
# Sistema de promedio de calificaciones
class EvaluadorProducto:
def __init__(self, nombre_producto):
self.nombre = nombre_producto
self.suma_calificaciones = 0
self.numero_evaluaciones = 0
self.promedio = 0
def agregar_calificacion(self, calificacion):
if 1 <= calificacion <= 5:
self.suma_calificaciones += calificacion
self.numero_evaluaciones += 1
# Calcular nuevo promedio
self.promedio = self.suma_calificaciones
self.promedio /= self.numero_evaluaciones
print(f"{self.nombre}: Nueva calificación {calificacion}/5")
print(f"Promedio actual: {self.promedio:.2f}/5 ({self.numero_evaluaciones} evaluaciones)")
else:
print("Calificación debe ser entre 1 y 5")
producto = EvaluadorProducto("Laptop Gaming")
producto.agregar_calificacion(4)
producto.agregar_calificacion(5)
producto.agregar_calificacion(3)
5. Asignación con División Entera (//=)
# Cálculo de cajas necesarias
productos_totales = 157
productos_por_caja = 12
# Calcular cuántas cajas completas se necesitan
cajas_necesarias = productos_totales
cajas_necesarias //= productos_por_caja
print(f"Cajas completas necesarias: {cajas_necesarias}")
# Productos restantes
productos_restantes = productos_totales % productos_por_caja
print(f"Productos en caja parcial: {productos_restantes}")
6. Asignación con Módulo (%=)
# Sistema de turnos rotativos
empleado_actual = 0
total_empleados = 5
def siguiente_turno():
global empleado_actual
empleado_actual += 1
empleado_actual %= total_empleados # Resetear a 0 cuando llegue a 5
return empleado_actual
empleados = ["Ana", "Carlos", "María", "Roberto", "Elena"]
print("Asignación de turnos:")
for dia in range(8):
turno = siguiente_turno()
print(f"Día {dia + 1}: {empleados[turno]}")
7. Asignación con Potencia (**=)
# Cálculo de interés compuesto
capital_inicial = 1000.00
tasa_interes = 0.05 # 5% anual
años = 3
capital_final = capital_inicial
# Aplicar interés compuesto: C * (1 + r)^t
capital_final *= (1 + tasa_interes) ** años
print(f"Capital inicial: ${capital_inicial:.2f}")
print(f"Capital después de {años} años: ${capital_final:.2f}")
print(f"Ganancia: ${capital_final - capital_inicial:.2f}")
# Sistema de niveles exponenciales
experiencia = 100
nivel = 1
# Cada nivel requiere experiencia^1.5 del nivel anterior
while experiencia >= (nivel ** 1.5) * 100:
experiencia -= int((nivel ** 1.5) * 100)
nivel += 1
print(f"Nivel alcanzado: {nivel}")
print(f"Experiencia restante: {experiencia}")
Operadores de Asignación con Operadores Bit a Bit
Asignación con AND (&=), OR (|=), XOR (^=)
# Sistema de permisos usando bits
class SistemaPermisos:
LEER = 1 # 001
ESCRIBIR = 2 # 010
EJECUTAR = 4 # 100
def __init__(self):
self.permisos_usuario = 0 # Sin permisos inicialmente
def otorgar_permiso(self, permiso):
self.permisos_usuario |= permiso # OR para agregar
print(f"Permiso otorgado. Permisos actuales: {bin(self.permisos_usuario)}")
def revocar_permiso(self, permiso):
self.permisos_usuario &= ~permiso # AND con NOT para quitar
print(f"Permiso revocado. Permisos actuales: {bin(self.permisos_usuario)}")
def toggle_permiso(self, permiso):
self.permisos_usuario ^= permiso # XOR para alternar
print(f"Permiso alternado. Permisos actuales: {bin(self.permisos_usuario)}")
def tiene_permiso(self, permiso):
return (self.permisos_usuario & permiso) != 0
# Ejemplo de uso
sistema = SistemaPermisos()
sistema.otorgar_permiso(SistemaPermisos.LEER) # 001
sistema.otorgar_permiso(SistemaPermisos.ESCRIBIR) # 011
sistema.toggle_permiso(SistemaPermisos.EJECUTAR) # 111
sistema.revocar_permiso(SistemaPermisos.ESCRIBIR) # 101
print(f"¿Puede leer? {sistema.tiene_permiso(SistemaPermisos.LEER)}")
print(f"¿Puede escribir? {sistema.tiene_permiso(SistemaPermisos.ESCRIBIR)}")
Aplicaciones Prácticas Avanzadas
Sistema de Inventario Inteligente
class InventarioInteligente:
def __init__(self):
self.productos = {}
self.alertas_stock = {}
self.ventas_del_dia = 0
self.meta_diaria = 1000
def agregar_producto(self, nombre, cantidad, precio_unitario):
if nombre not in self.productos:
self.productos[nombre] = {
"cantidad": 0,
"precio": 0,
"total_vendido": 0,
"ingresos": 0
}
# Usar operadores de asignación para actualizar
self.productos[nombre]["cantidad"] += cantidad
self.productos[nombre]["precio"] = precio_unitario
print(f"Agregado: {cantidad} x {nombre} @ ${precio_unitario}")
print(f"Stock total de {nombre}: {self.productos[nombre]['cantidad']}")
def procesar_venta(self, nombre, cantidad):
if nombre not in self.productos:
print(f"Error: {nombre} no existe en inventario")
return False
producto = self.productos[nombre]
if producto["cantidad"] < cantidad:
print(f"Error: Stock insuficiente de {nombre}")
print(f"Disponible: {producto['cantidad']}, Solicitado: {cantidad}")
return False
# Usar operadores de asignación para procesar la venta
producto["cantidad"] -= cantidad # Reducir stock
producto["total_vendido"] += cantidad # Incrementar vendido
venta_total = cantidad * producto["precio"]
producto["ingresos"] += venta_total # Incrementar ingresos del producto
self.ventas_del_dia += venta_total # Incrementar ventas del día
print(f"Venta procesada: {cantidad} x {nombre} = ${venta_total:.2f}")
print(f"Ventas del día: ${self.ventas_del_dia:.2f} / ${self.meta_diaria:.2f}")
# Verificar progreso hacia la meta
progreso = self.ventas_del_dia / self.meta_diaria
progreso *= 100
print(f"Progreso de meta: {progreso:.1f}%")
return True
def aplicar_descuento_global(self, porcentaje):
"""Aplicar descuento a todos los productos"""
factor_descuento = 1 - (porcentaje / 100)
for nombre, producto in self.productos.items():
precio_original = producto["precio"]
producto["precio"] *= factor_descuento # Usar *= para aplicar descuento
print(f"{nombre}: ${precio_original:.2f} → ${producto['precio']:.2f}")
def reporte_diario(self):
print("\n" + "=" * 50)
print("REPORTE DIARIO DE INVENTARIO")
print("=" * 50)
for nombre, producto in self.productos.items():
print(f"\n{nombre}:")
print(f" Stock actual: {producto['cantidad']}")
print(f" Precio: ${producto['precio']:.2f}")
print(f" Unidades vendidas: {producto['total_vendido']}")
print(f" Ingresos generados: ${producto['ingresos']:.2f}")
print(f"\nVentas totales del día: ${self.ventas_del_dia:.2f}")
meta_restante = self.meta_diaria - self.ventas_del_dia
if meta_restante > 0:
print(f"Falta para meta: ${meta_restante:.2f}")
else:
print("🎉 ¡Meta diaria superada!")
# Ejemplo de uso completo
inventario = InventarioInteligente()
# Agregar productos
inventario.agregar_producto("Laptop", 10, 1200.00)
inventario.agregar_producto("Mouse", 50, 25.99)
inventario.agregar_producto("Teclado", 30, 75.50)
# Procesar ventas
inventario.procesar_venta("Laptop", 2)
inventario.procesar_venta("Mouse", 5)
inventario.procesar_venta("Teclado", 3)
# Aplicar descuento de fin de día
print("\n🏷️ Aplicando descuento del 10% para cerrar el día...")
inventario.aplicar_descuento_global(10)
# Más ventas con precios con descuento
inventario.procesar_venta("Laptop", 1)
inventario.procesar_venta("Mouse", 8)
# Reporte final
inventario.reporte_diario()
Trucos y Consejos Profesionales
1. Operaciones Encadenadas Cuidadosas
# ✅ Correcto: operaciones claras
ventas = 1000
ventas *= 1.15 # Incremento del 15%
ventas -= 50 # Descuento fijo
print(f"Ventas finales: ${ventas:.2f}")
# ⚠️ Cuidado con la precedencia
precio = 100
# Esto puede ser confuso:
precio += 10 * 0.15 # ¿10 * 0.15 luego suma, o (precio + 10) * 0.15?
# Es: precio = precio + (10 * 0.15) = 100 + 1.5 = 101.5
# ✅ Mejor: usar paréntesis para claridad
precio = 100
precio = (precio + 10) * 1.15 # Más claro si esa era la intención
2. Validaciones con Operadores de Asignación
def actualizar_stock_seguro(producto, cantidad_cambio):
"""Actualizar stock de forma segura"""
stock_actual = inventario.get(producto, 0)
# Validar antes de aplicar
if stock_actual + cantidad_cambio < 0:
print(f"Error: Stock no puede ser negativo")
print(f"Stock actual: {stock_actual}, Cambio solicitado: {cantidad_cambio}")
return False
# Aplicar cambio solo si es válido
inventario[producto] = stock_actual
inventario[producto] += cantidad_cambio
print(f"Stock de {producto} actualizado: {stock_actual} → {inventario[producto]}")
return True
# Ejemplo de uso
inventario = {"leche": 50, "pan": 30}
actualizar_stock_seguro("leche", -10) # Válido
actualizar_stock_seguro("pan", -40) # Inválido (resultaría en -10)
3. Operadores de Asignación con Estructuras de Datos
# Con diccionarios
ventas_por_mes = {"enero": 1000, "febrero": 1200}
ventas_por_mes["enero"] += 150 # Actualizar enero
ventas_por_mes["marzo"] = ventas_por_mes.get("marzo", 0) + 800 # Crear marzo si no existe
# Con listas
productos_destacados = ["laptop", "mouse"]
productos_destacados += ["teclado", "monitor"] # Agregar elementos
# productos_destacados *= 2 # Duplicar la lista (cuidado, duplica elementos)
# Con sets
categorias_vendidas = {"electronics", "books"}
categorias_vendidas |= {"clothing", "home"} # Unión de sets (agregar categorías)
print(categorias_vendidas)
Tabla de Referencia Rápida
| Operador | Equivalencia | Descripción | Ejemplo |
|---|---|---|---|
+= | a = a + b | Suma y asigna | stock += 10 |
-= | a = a - b | Resta y asigna | presupuesto -= 100 |
*= | a = a * b | Multiplica y asigna | precio *= 1.1 |
/= | a = a / b | Divide y asigna | total /= 2 |
//= | a = a // b | División entera y asigna | cajas //= 12 |
%= | a = a % b | Módulo y asigna | turno %= 5 |
**= | a = a ** b | Potencia y asigna | capital **= 1.05 |
&= | a = a & b | AND bit a bit y asigna | permisos &= mask |
|= | a = a | b | OR bit a bit y asigna | flags |= new_flag |
^= | a = a ^ b | XOR bit a bit y asigna | estado ^= toggle |
Cuándo Usar Operadores de Asignación
Úsalos cuando:
- Actualices una variable basándote en su valor actual
- Quieras código más conciso y legible
- Realices operaciones incrementales (contadores, acumuladores)
- Modifiques configuraciones o estados gradualmente
Ten cuidado con:
- La precedencia de operadores en expresiones complejas
- Efectos secundarios en objetos mutables
- Operaciones que pueden causar overflow o underflow
Los operadores de asignación hacen que tu código sea más eficiente y expresivo, permitiéndote escribir actualizaciones de variables de manera elegante y profesional. ¡Son herramientas esenciales para todo programador de Python!
Operadores Bit a Bit
Los operadores bit a bit son como los técnicos especializados de tu almacén que trabajan al nivel más detallado posible: manipulando información directamente en el “lenguaje interno” de la computadora. Aunque pueden parecer complejos al principio, estos operadores son increíblemente poderosos para ciertas tareas específicas.
Imagina que cada número en tu computadora está representado como una fila de interruptores (bits) que pueden estar encendidos (1) o apagados (0). Los operadores bit a bit te permiten manipular estos interruptores individuales.
¿Qué Son los Bits?
Antes de explorar los operadores, entendamos qué son los bits:
# Los números se representan internamente como bits
numero = 5
print(f"El número {numero} en binario es: {bin(numero)}") # 0b101
numero = 10
print(f"El número {numero} en binario es: {bin(numero)}") # 0b1010
# Para ver solo los bits sin el prefijo '0b'
numero = 7
binario = bin(numero)[2:] # Remover '0b'
print(f"El número {numero} en binario es: {binario}") # 111
Los Operadores Bit a Bit Fundamentales
1. AND Bit a Bit (&)
El operador & compara cada bit individual. El resultado es 1 solo si ambos bits son 1.
# Ejemplo básico
a = 5 # En binario: 101
b = 3 # En binario: 011
resultado = a & b # 101 & 011 = 001
print(f"{a} & {b} = {resultado}") # 5 & 3 = 1
# Visualización paso a paso
print(f" {a:b} (5)")
print(f"& {b:b} (3)")
print(f"------")
print(f" {resultado:b} ({resultado})")
Casos Prácticos del AND Bit a Bit
# 1. Verificar si un número es par
def es_par(numero):
# Un número es par si su último bit es 0
return (numero & 1) == 0
print(f"4 es par: {es_par(4)}") # True
print(f"5 es par: {es_par(5)}") # False
print(f"8 es par: {es_par(8)}") # True
# 2. Extraer bits específicos (máscaras)
permisos = 0b111 # rwx (read, write, execute)
lectura_permiso = 0b100 # Máscara para verificar permiso de lectura
puede_leer = (permisos & lectura_permiso) != 0
print(f"Puede leer: {puede_leer}") # True
# 3. Sistema de flags en almacén
PRODUCTO_FRAGIL = 0b001 # bit 0
PRODUCTO_PERECEDERO = 0b010 # bit 1
PRODUCTO_VALIOSO = 0b100 # bit 2
# Un producto con múltiples características
producto_especial = PRODUCTO_FRAGIL | PRODUCTO_VALIOSO # 0b101
# Verificar características específicas
es_fragil = (producto_especial & PRODUCTO_FRAGIL) != 0
es_perecedero = (producto_especial & PRODUCTO_PERECEDERO) != 0
es_valioso = (producto_especial & PRODUCTO_VALIOSO) != 0
print(f"Producto frágil: {es_fragil}") # True
print(f"Producto perecedero: {es_perecedero}") # False
print(f"Producto valioso: {es_valioso}") # True
2. OR Bit a Bit (|)
El operador | compara cada bit individual. El resultado es 1 si al menos uno de los bits es 1.
# Ejemplo básico
a = 5 # En binario: 101
b = 3 # En binario: 011
resultado = a | b # 101 | 011 = 111
print(f"{a} | {b} = {resultado}") # 5 | 3 = 7
# Visualización
print(f" {a:b} (5)")
print(f"| {b:b} (3)")
print(f"------")
print(f" {resultado:b} ({resultado})")
Casos Prácticos del OR Bit a Bit
# 1. Combinar permisos o características
PERMISO_LECTURA = 0b100 # 4
PERMISO_ESCRITURA = 0b010 # 2
PERMISO_EJECUCION = 0b001 # 1
# Crear un usuario con permisos de lectura y escritura
permisos_usuario = PERMISO_LECTURA | PERMISO_ESCRITURA
print(f"Permisos usuario: {bin(permisos_usuario)} ({permisos_usuario})") # 0b110 (6)
# 2. Sistema de alertas del almacén
ALERTA_TEMPERATURA = 0b0001 # 1
ALERTA_HUMEDAD = 0b0010 # 2
ALERTA_SEGURIDAD = 0b0100 # 4
ALERTA_INVENTARIO = 0b1000 # 8
# Activar múltiples alertas
alertas_activas = ALERTA_TEMPERATURA | ALERTA_SEGURIDAD
print(f"Alertas activas: {bin(alertas_activas)} ({alertas_activas})") # 0b101 (5)
# Agregar una nueva alerta
alertas_activas = alertas_activas | ALERTA_HUMEDAD
print(f"Alertas después de agregar humedad: {bin(alertas_activas)} ({alertas_activas})") # 0b111 (7)
3. XOR Bit a Bit (^)
El operador ^ (XOR - eXclusive OR) compara cada bit. El resultado es 1 si los bits son diferentes.
# Ejemplo básico
a = 5 # En binario: 101
b = 3 # En binario: 011
resultado = a ^ b # 101 ^ 011 = 110
print(f"{a} ^ {b} = {resultado}") # 5 ^ 3 = 6
# Visualización
print(f" {a:b} (5)")
print(f"^ {b:b} (3)")
print(f"------")
print(f" {resultado:b} ({resultado})")
Casos Prácticos del XOR
# 1. Intercambiar valores sin variable temporal (truco clásico)
a = 15
b = 25
print(f"Antes: a={a}, b={b}")
# Intercambio usando XOR
a = a ^ b
b = a ^ b
a = a ^ b
print(f"Después: a={a}, b={b}")
# 2. Cifrado simple (no usar en producción)
def cifrar_simple(texto, clave):
"""Cifrado XOR simple - solo para demostración"""
cifrado = ""
for char in texto:
cifrado += chr(ord(char) ^ clave)
return cifrado
def descifrar_simple(texto_cifrado, clave):
"""El XOR es reversible con la misma clave"""
return cifrar_simple(texto_cifrado, clave)
# Ejemplo
mensaje = "ALMACEN"
clave = 42
mensaje_cifrado = cifrar_simple(mensaje, clave)
print(f"Mensaje original: {mensaje}")
print(f"Mensaje cifrado: {repr(mensaje_cifrado)}")
mensaje_descifrado = descifrar_simple(mensaje_cifrado, clave)
print(f"Mensaje descifrado: {mensaje_descifrado}")
# 3. Detección de cambios en inventario
inventario_dia1 = 0b10110 # Estado inicial
inventario_dia2 = 0b10010 # Estado después
cambios = inventario_dia1 ^ inventario_dia2
print(f"Productos que cambiaron: {bin(cambios)} ({cambios})")
4. NOT Bit a Bit (~)
El operador ~ invierte todos los bits (complemento).
# Ejemplo básico (cuidado con los números negativos)
a = 5 # En binario: 101
resultado = ~a
print(f"~{a} = {resultado}") # ~5 = -6
# Para entender mejor, trabajemos con números pequeños
# y veamos la representación en 8 bits
def mostrar_bits_8(numero):
if numero >= 0:
return format(numero, '08b')
else:
# Para números negativos, Python usa complemento a 2
return format(numero & 0xFF, '08b')
numero = 5
print(f"Número {numero}: {mostrar_bits_8(numero)}")
print(f"~{numero}: {mostrar_bits_8(~numero)}")
Casos Prácticos del NOT
# 1. Crear máscaras para limpiar bits específicos
TODOS_PERMISOS = 0b111 # 7
QUITAR_ESCRITURA = ~0b010 # Quitar bit de escritura
permisos_actuales = 0b111 # rwx
permisos_nuevos = permisos_actuales & QUITAR_ESCRITURA
print(f"Permisos antes: {bin(permisos_actuales)}")
print(f"Permisos después: {bin(permisos_nuevos & 0b111)}") # Mantener solo 3 bits
# 2. Toggle de estados
def toggle_bit(numero, posicion):
"""Cambia el bit en la posición especificada"""
mascara = 1 << posicion
return numero ^ mascara
estado = 0b1010 # 10
print(f"Estado inicial: {bin(estado)}")
# Toggle bit en posición 0
estado = toggle_bit(estado, 0)
print(f"Después de toggle bit 0: {bin(estado)}")
# Toggle bit en posición 2
estado = toggle_bit(estado, 2)
print(f"Después de toggle bit 2: {bin(estado)}")
5. Desplazamiento de Bits
Desplazamiento a la Izquierda (<<)
# Desplazar a la izquierda es como multiplicar por 2^n
numero = 5 # 101 en binario
resultado = numero << 1 # 1010 en binario
print(f"{numero} << 1 = {resultado}") # 5 << 1 = 10
resultado = numero << 2 # 10100 en binario
print(f"{numero} << 2 = {resultado}") # 5 << 2 = 20
# Equivale a multiplicar por potencias de 2
print(f"5 * 2^1 = {5 * (2**1)}") # 10
print(f"5 * 2^2 = {5 * (2**2)}") # 20
Desplazamiento a la Derecha (>>)
# Desplazar a la derecha es como dividir por 2^n
numero = 20 # 10100 en binario
resultado = numero >> 1 # 1010 en binario
print(f"{numero} >> 1 = {resultado}") # 20 >> 1 = 10
resultado = numero >> 2 # 101 en binario
print(f"{numero} >> 2 = {resultado}") # 20 >> 2 = 5
# Equivale a dividir por potencias de 2 (división entera)
print(f"20 // 2^1 = {20 // (2**1)}") # 10
print(f"20 // 2^2 = {20 // (2**2)}") # 5
Aplicaciones Prácticas en el Almacén
Sistema de Permisos Avanzado
class SistemaPermisos:
# Definir permisos como constantes
LEER_INVENTARIO = 1 << 0 # 0b00001
ESCRIBIR_INVENTARIO = 1 << 1 # 0b00010
ELIMINAR_PRODUCTOS = 1 << 2 # 0b00100
GESTIONAR_USUARIOS = 1 << 3 # 0b01000
ACCESO_REPORTES = 1 << 4 # 0b10000
def __init__(self):
self.usuarios = {}
def agregar_usuario(self, nombre, permisos=0):
"""Agregar usuario con permisos específicos"""
self.usuarios[nombre] = permisos
def otorgar_permiso(self, usuario, permiso):
"""Otorgar un permiso específico al usuario"""
if usuario in self.usuarios:
self.usuarios[usuario] |= permiso
def revocar_permiso(self, usuario, permiso):
"""Revocar un permiso específico del usuario"""
if usuario in self.usuarios:
self.usuarios[usuario] &= ~permiso
def tiene_permiso(self, usuario, permiso):
"""Verificar si el usuario tiene un permiso específico"""
if usuario not in self.usuarios:
return False
return (self.usuarios[usuario] & permiso) != 0
def mostrar_permisos(self, usuario):
"""Mostrar todos los permisos del usuario"""
if usuario not in self.usuarios:
return "Usuario no encontrado"
permisos = self.usuarios[usuario]
resultado = []
if self.tiene_permiso(usuario, self.LEER_INVENTARIO):
resultado.append("Leer inventario")
if self.tiene_permiso(usuario, self.ESCRIBIR_INVENTARIO):
resultado.append("Escribir inventario")
if self.tiene_permiso(usuario, self.ELIMINAR_PRODUCTOS):
resultado.append("Eliminar productos")
if self.tiene_permiso(usuario, self.GESTIONAR_USUARIOS):
resultado.append("Gestionar usuarios")
if self.tiene_permiso(usuario, self.ACCESO_REPORTES):
resultado.append("Acceso a reportes")
return resultado if resultado else ["Sin permisos"]
# Ejemplo de uso
sistema = SistemaPermisos()
# Crear usuarios con diferentes niveles de acceso
# Empleado básico: solo lectura
sistema.agregar_usuario("juan", sistema.LEER_INVENTARIO)
# Supervisor: lectura y escritura
sistema.agregar_usuario("maria", sistema.LEER_INVENTARIO | sistema.ESCRIBIR_INVENTARIO)
# Administrador: todos los permisos
admin_permisos = (sistema.LEER_INVENTARIO |
sistema.ESCRIBIR_INVENTARIO |
sistema.ELIMINAR_PRODUCTOS |
sistema.GESTIONAR_USUARIOS |
sistema.ACCESO_REPORTES)
sistema.agregar_usuario("admin", admin_permisos)
# Probar el sistema
print("=== SISTEMA DE PERMISOS ===")
print(f"Juan puede leer: {sistema.tiene_permiso('juan', sistema.LEER_INVENTARIO)}")
print(f"Juan puede escribir: {sistema.tiene_permiso('juan', sistema.ESCRIBIR_INVENTARIO)}")
print(f"María permisos: {sistema.mostrar_permisos('maria')}")
# Otorgar permiso adicional a Juan
sistema.otorgar_permiso("juan", sistema.ACCESO_REPORTES)
print(f"Juan después de otorgar reportes: {sistema.mostrar_permisos('juan')}")
# Revocar permiso de María
sistema.revocar_permiso("maria", sistema.ESCRIBIR_INVENTARIO)
print(f"María después de revocar escritura: {sistema.mostrar_permisos('maria')}")
Optimización de Espacio con Flags
class ProductoCompacto:
"""Clase que usa bits para almacenar múltiples características booleanas"""
# Flags de características
ES_FRAGIL = 1 << 0 # bit 0
ES_PERECEDERO = 1 << 1 # bit 1
ES_VALIOSO = 1 << 2 # bit 2
REQUIERE_FRIO = 1 << 3 # bit 3
ES_LIQUIDO = 1 << 4 # bit 4
ES_INFLAMABLE = 1 << 5 # bit 5
def __init__(self, nombre, caracteristicas=0):
self.nombre = nombre
self.caracteristicas = caracteristicas
def agregar_caracteristica(self, flag):
"""Agregar una característica"""
self.caracteristicas |= flag
def quitar_caracteristica(self, flag):
"""Quitar una característica"""
self.caracteristicas &= ~flag
def tiene_caracteristica(self, flag):
"""Verificar si tiene una característica"""
return (self.caracteristicas & flag) != 0
def obtener_caracteristicas(self):
"""Obtener lista de todas las características"""
caracteristicas = []
if self.tiene_caracteristica(self.ES_FRAGIL):
caracteristicas.append("Frágil")
if self.tiene_caracteristica(self.ES_PERECEDERO):
caracteristicas.append("Perecedero")
if self.tiene_caracteristica(self.ES_VALIOSO):
caracteristicas.append("Valioso")
if self.tiene_caracteristica(self.REQUIERE_FRIO):
caracteristicas.append("Requiere frío")
if self.tiene_caracteristica(self.ES_LIQUIDO):
caracteristicas.append("Líquido")
if self.tiene_caracteristica(self.ES_INFLAMABLE):
caracteristicas.append("Inflamable")
return caracteristicas
def mostrar_info(self):
"""Mostrar información completa del producto"""
print(f"Producto: {self.nombre}")
print(f"Características: {', '.join(self.obtener_caracteristicas())}")
print(f"Flags (binario): {bin(self.caracteristicas)}")
# Ejemplos de uso
print("=== GESTIÓN COMPACTA DE PRODUCTOS ===")
# Crear productos con diferentes características
leche = ProductoCompacto("Leche")
leche.agregar_caracteristica(ProductoCompacto.ES_PERECEDERO)
leche.agregar_caracteristica(ProductoCompacto.REQUIERE_FRIO)
leche.agregar_caracteristica(ProductoCompacto.ES_LIQUIDO)
cristaleria = ProductoCompacto("Copa de cristal")
cristaleria.agregar_caracteristica(ProductoCompacto.ES_FRAGIL)
cristaleria.agregar_caracteristica(ProductoCompacto.ES_VALIOSO)
gasolina = ProductoCompacto("Gasolina")
gasolina.agregar_caracteristica(ProductoCompacto.ES_LIQUIDO)
gasolina.agregar_caracteristica(ProductoCompacto.ES_INFLAMABLE)
# Mostrar información
leche.mostrar_info()
print()
cristaleria.mostrar_info()
print()
gasolina.mostrar_info()
print("\n=== VERIFICACIONES ESPECÍFICAS ===")
print(f"¿La leche requiere frío? {leche.tiene_caracteristica(ProductoCompacto.REQUIERE_FRIO)}")
print(f"¿La cristalería es inflamable? {cristaleria.tiene_caracteristica(ProductoCompacto.ES_INFLAMABLE)}")
Trucos y Consejos Profesionales
1. Operaciones Rápidas
# Multiplicar/dividir por potencias de 2
numero = 15
# En lugar de: numero * 4
resultado_mult = numero << 2 # Más rápido
print(f"15 * 4 = {resultado_mult}")
# En lugar de: numero // 8
resultado_div = numero >> 3 # Más rápido
print(f"15 // 8 = {resultado_div}")
# Verificar si es potencia de 2
def es_potencia_de_2(n):
return n > 0 and (n & (n - 1)) == 0
print(f"8 es potencia de 2: {es_potencia_de_2(8)}") # True
print(f"10 es potencia de 2: {es_potencia_de_2(10)}") # False
2. Extraer y Manipular Bits Específicos
def extraer_bit(numero, posicion):
"""Extraer el bit en la posición especificada"""
return (numero >> posicion) & 1
def establecer_bit(numero, posicion):
"""Establecer el bit en la posición especificada a 1"""
return numero | (1 << posicion)
def limpiar_bit(numero, posicion):
"""Establecer el bit en la posición especificada a 0"""
return numero & ~(1 << posicion)
# Ejemplos
numero = 0b10110 # 22
print(f"Número original: {bin(numero)} ({numero})")
print(f"Bit en posición 2: {extraer_bit(numero, 2)}")
numero_modificado = establecer_bit(numero, 0)
print(f"Después de establecer bit 0: {bin(numero_modificado)} ({numero_modificado})")
numero_modificado = limpiar_bit(numero, 4)
print(f"Después de limpiar bit 4: {bin(numero_modificado)} ({numero_modificado})")
Tabla de Referencia Rápida
| Operador | Símbolo | Descripción | Ejemplo |
|---|---|---|---|
| AND | & | 1 solo si ambos bits son 1 | 5 & 3 = 1 |
| OR | | | 1 si al menos un bit es 1 | 5 | 3 = 7 |
| XOR | ^ | 1 si los bits son diferentes | 5 ^ 3 = 6 |
| NOT | ~ | Invierte todos los bits | ~5 = -6 |
| Izquierda | << | Desplaza bits a la izquierda | 5 << 1 = 10 |
| Derecha | >> | Desplaza bits a la derecha | 10 >> 1 = 5 |
Cuándo Usar Operadores Bit a Bit
Úsalos cuando:
- Necesites máximo rendimiento en operaciones numéricas
- Trabajes con flags o permisos
- Implementes algoritmos de bajo nivel
- Manejes protocolos de comunicación
- Optimices el uso de memoria
No los uses cuando:
- La legibilidad del código sea más importante que la velocidad
- Trabajes con lógica de negocio general
- El equipo no esté familiarizado con operaciones bit a bit
Los operadores bit a bit son herramientas poderosas que, aunque especializadas, pueden hacer que tu código sea más eficiente y elegante en situaciones específicas. ¡Son el nivel de precisión máximo que puedes alcanzar en programación!
Operadores de Identidad y Pertenencia
Los operadores de identidad y pertenencia son como los inspectores especializados de tu almacén. Mientras que los operadores de comparación verifican si dos productos son similares, estos operadores van más profundo: verifican si dos productos son exactamente el mismo objeto (identidad) o si un producto pertenece a una colección específica (pertenencia).
Imagina que tienes dos cajas idénticas en tu almacén. Aunque contengan lo mismo, son físicamente cajas diferentes. Los operadores de identidad te ayudan a distinguir entre “contenido igual” y “objeto exactamente el mismo”.
Operadores de Identidad
El Operador is
El operador is verifica si dos variables apuntan exactamente al mismo objeto en memoria.
# Ejemplo básico con números pequeños
a = 5
b = 5
print(f"a == b: {a == b}") # True (mismo valor)
print(f"a is b: {a is b}") # True (mismo objeto, Python optimiza números pequeños)
# Ejemplo con listas
lista1 = [1, 2, 3]
lista2 = [1, 2, 3]
lista3 = lista1
print(f"lista1 == lista2: {lista1 == lista2}") # True (mismo contenido)
print(f"lista1 is lista2: {lista1 is lista2}") # False (objetos diferentes)
print(f"lista1 is lista3: {lista1 is lista3}") # True (mismo objeto)
Casos Prácticos del Operador is
# 1. Verificar valores especiales
def procesar_inventario(productos):
if productos is None:
print("⚠️ No se proporcionó lista de productos")
return []
if productos is []: # ❌ INCORRECTO - no usar is con listas vacías
print("Lista vacía")
if productos == []: # ✅ CORRECTO - usar == para comparar contenido
print("Lista vacía")
return []
return productos
# Ejemplos
print(procesar_inventario(None))
print(procesar_inventario([]))
print(procesar_inventario(['producto1', 'producto2']))
# 2. Verificar singleton (objetos únicos)
class AlmacenCentral:
_instancia = None
def __new__(cls):
if cls._instancia is None:
cls._instancia = super().__new__(cls)
return cls._instancia
def __init__(self):
if not hasattr(self, 'inicializado'):
self.productos = []
self.inicializado = True
# Verificar que siempre obtenemos la misma instancia
almacen1 = AlmacenCentral()
almacen2 = AlmacenCentral()
print(f"almacen1 == almacen2: {almacen1 == almacen2}") # True
print(f"almacen1 is almacen2: {almacen1 is almacen2}") # True (mismo objeto)
# 3. Verificar tipos específicos
import types
def analizar_variable(variable):
if variable is True:
return "Es exactamente True"
elif variable is False:
return "Es exactamente False"
elif variable is None:
return "Es None"
elif type(variable) is int:
return f"Es un entero: {variable}"
elif type(variable) is str:
return f"Es una cadena: '{variable}'"
else:
return f"Es de tipo: {type(variable).__name__}"
# Ejemplos
print(analizar_variable(True))
print(analizar_variable(1)) # Diferente de True
print(analizar_variable(None))
print(analizar_variable("")) # Cadena vacía vs None
El Operador is not
El operador is not es la negación de is. Verifica si dos variables NO apuntan al mismo objeto.
# Verificaciones de seguridad
def validar_usuario(usuario):
if usuario is not None:
if usuario.activo is not False: # No es exactamente False
return True
return False
class Usuario:
def __init__(self, nombre, activo=True):
self.nombre = nombre
self.activo = activo
# Ejemplos
usuario1 = Usuario("Juan", True)
usuario2 = Usuario("María", False)
usuario3 = None
print(f"Usuario1 válido: {validar_usuario(usuario1)}") # True
print(f"Usuario2 válido: {validar_usuario(usuario2)}") # False
print(f"Usuario3 válido: {validar_usuario(usuario3)}") # False
# Comparación con listas
productos_originales = ["leche", "pan", "huevos"]
productos_copia = productos_originales.copy()
productos_referencia = productos_originales
print(f"Copia is not original: {productos_copia is not productos_originales}") # True
print(f"Referencia is not original: {productos_referencia is not productos_originales}") # False
Operadores de Pertenencia
El Operador in
El operador in verifica si un elemento pertenece a una colección (lista, tupla, set, diccionario, cadena, etc.).
# Verificación básica de pertenencia
productos_disponibles = ["leche", "pan", "huevos", "queso", "yogur"]
producto_buscado = "pan"
if producto_buscado in productos_disponibles:
print(f"✅ {producto_buscado} está disponible")
else:
print(f"❌ {producto_buscado} no está disponible")
# Con cadenas
codigo_producto = "ABC123DEF"
if "123" in codigo_producto:
print("Código contiene '123'")
# Con diccionarios (verifica llaves por defecto)
inventario = {
"leche": 50,
"pan": 25,
"huevos": 100
}
if "leche" in inventario:
print(f"Tenemos {inventario['leche']} unidades de leche")
Casos Prácticos del Operador in
# 1. Sistema de permisos por roles
class SistemaAcceso:
def __init__(self):
self.roles_admin = {"admin", "superusuario", "gerente"}
self.roles_empleado = {"empleado", "vendedor", "operario"}
self.areas_restringidas = {"almacen_seguro", "oficina_gerencia", "deposito_quimicos"}
def puede_acceder(self, usuario_rol, area):
if usuario_rol in self.roles_admin:
return True # Admins pueden acceder a todo
if area in self.areas_restringidas:
return False # Empleados no pueden acceder a áreas restringidas
return usuario_rol in self.roles_empleado
# Ejemplo de uso
sistema = SistemaAcceso()
print(f"Gerente puede acceder a almacén seguro: {sistema.puede_acceder('gerente', 'almacen_seguro')}") # True
print(f"Empleado puede acceder a almacén seguro: {sistema.puede_acceder('empleado', 'almacen_seguro')}") # False
print(f"Vendedor puede acceder a sala ventas: {sistema.puede_acceder('vendedor', 'sala_ventas')}") # True
# 2. Validación de datos de entrada
def validar_codigo_producto(codigo):
"""Validar que el código de producto tenga el formato correcto"""
caracteres_validos = "ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
caracteres_especiales = ["-", "_"]
if len(codigo) < 3:
return False, "Código muy corto"
for caracter in codigo:
if caracter not in caracteres_validos and caracter not in caracteres_especiales:
return False, f"Caracter inválido: '{caracter}'"
# Verificar que tenga al menos un número
tiene_numero = any(char in "0123456789" for char in codigo)
if not tiene_numero:
return False, "Debe contener al menos un número"
return True, "Código válido"
# Ejemplos de validación
codigos_prueba = ["ABC123", "XYZ", "ABC-123_DEF", "ABC@123", "ABCDEF"]
for codigo in codigos_prueba:
valido, mensaje = validar_codigo_producto(codigo)
print(f"'{codigo}': {mensaje}")
# 3. Filtros de búsqueda inteligente
class BuscadorProductos:
def __init__(self):
self.productos = [
{"nombre": "Leche entera", "categoria": "lacteos", "precio": 2.50, "tags": ["lacteo", "bebida", "nutritivo"]},
{"nombre": "Pan integral", "categoria": "panaderia", "precio": 1.80, "tags": ["cereal", "fibra", "saludable"]},
{"nombre": "Yogur griego", "categoria": "lacteos", "precio": 3.20, "tags": ["lacteo", "proteina", "saludable"]},
{"nombre": "Cerveza artesanal", "categoria": "bebidas", "precio": 4.50, "tags": ["bebida", "alcohol", "artesanal"]},
]
def buscar(self, termino_busqueda, categoria=None, precio_max=None):
"""Buscar productos usando múltiples criterios"""
resultados = []
termino_lower = termino_busqueda.lower()
for producto in self.productos:
# Verificar si el término está en el nombre o tags
nombre_match = termino_lower in producto["nombre"].lower()
tag_match = any(termino_lower in tag for tag in producto["tags"])
if not (nombre_match or tag_match):
continue
# Filtrar por categoría si se especifica
if categoria and categoria not in producto["categoria"]:
continue
# Filtrar por precio máximo si se especifica
if precio_max and producto["precio"] > precio_max:
continue
resultados.append(producto)
return resultados
# Ejemplo de búsqueda
buscador = BuscadorProductos()
print("=== BÚSQUEDAS ===")
print("Búsqueda 'leche':")
for producto in buscador.buscar("leche"):
print(f" - {producto['nombre']} (${producto['precio']})")
print("\nBúsqueda 'saludable' con precio máximo $3:")
for producto in buscador.buscar("saludable", precio_max=3.0):
print(f" - {producto['nombre']} (${producto['precio']})")
print("\nBúsqueda 'bebida' en categoría 'lacteos':")
for producto in buscador.buscar("bebida", categoria="lacteos"):
print(f" - {producto['nombre']} (${producto['precio']})")
El Operador not in
El operador not in verifica si un elemento NO pertenece a una colección.
# Control de productos prohibidos
productos_prohibidos = ["tabaco", "alcohol", "medicamentos_controlados"]
productos_pedido = ["leche", "pan", "tabaco", "yogur"]
productos_validos = []
productos_rechazados = []
for producto in productos_pedido:
if producto not in productos_prohibidos:
productos_validos.append(producto)
else:
productos_rechazados.append(producto)
print(f"Productos válidos: {productos_validos}")
print(f"Productos rechazados: {productos_rechazados}")
# Verificación de disponibilidad
stock_actual = {"leche": 10, "pan": 5, "huevos": 20}
productos_solicitados = ["leche", "pan", "mantequilla", "huevos"]
for producto in productos_solicitados:
if producto not in stock_actual:
print(f"⚠️ {producto} no está en stock")
elif stock_actual[producto] == 0:
print(f"⚠️ {producto} está agotado")
else:
print(f"✅ {producto} disponible: {stock_actual[producto]} unidades")
Aplicaciones Avanzadas
Sistema de Control de Calidad
class ControlCalidad:
def __init__(self):
# Criterios de calidad por categoría
self.criterios_calidad = {
"lacteos": {"temperatura_max": 4, "dias_vencimiento_min": 3},
"carnes": {"temperatura_max": 2, "dias_vencimiento_min": 1},
"vegetales": {"humedad_max": 85, "dias_vencimiento_min": 2},
"enlatados": {"abolladuras": False, "dias_vencimiento_min": 30}
}
# Defectos que causan rechazo automático
self.defectos_criticos = {"moho", "mal_olor", "envase_roto", "fecha_vencida"}
# Certificaciones requeridas
self.certificaciones_requeridas = {"organico", "sin_gluten", "kosher", "halal"}
def evaluar_producto(self, producto):
"""Evaluar si un producto pasa el control de calidad"""
categoria = producto.get("categoria")
defectos = producto.get("defectos", [])
certificaciones = producto.get("certificaciones", [])
# Verificar defectos críticos
for defecto in defectos:
if defecto in self.defectos_criticos:
return False, f"Defecto crítico detectado: {defecto}"
# Verificar criterios específicos de la categoría
if categoria in self.criterios_calidad:
criterios = self.criterios_calidad[categoria]
for criterio, valor_requerido in criterios.items():
if criterio in producto:
valor_actual = producto[criterio]
if "max" in criterio and valor_actual > valor_requerido:
return False, f"Excede {criterio}: {valor_actual} > {valor_requerido}"
elif "min" in criterio and valor_actual < valor_requerido:
return False, f"Por debajo de {criterio}: {valor_actual} < {valor_requerido}"
elif isinstance(valor_requerido, bool) and valor_actual != valor_requerido:
return False, f"Criterio {criterio} no cumplido"
# Verificar certificaciones especiales (si las tiene)
for cert in certificaciones:
if cert not in self.certificaciones_requeridas:
print(f"⚠️ Certificación no reconocida: {cert}")
return True, "Producto aprobado"
# Ejemplos de productos
productos_test = [
{
"nombre": "Leche orgánica",
"categoria": "lacteos",
"temperatura_max": 3,
"dias_vencimiento_min": 5,
"defectos": [],
"certificaciones": ["organico"]
},
{
"nombre": "Carne de res",
"categoria": "carnes",
"temperatura_max": 1,
"dias_vencimiento_min": 2,
"defectos": ["mal_olor"],
"certificaciones": ["halal"]
},
{
"nombre": "Lechuga",
"categoria": "vegetales",
"humedad_max": 80,
"dias_vencimiento_min": 3,
"defectos": [],
"certificaciones": []
}
]
# Evaluar productos
control = ControlCalidad()
print("=== CONTROL DE CALIDAD ===")
for producto in productos_test:
aprobado, mensaje = control.evaluar_producto(producto)
estado = "✅ APROBADO" if aprobado else "❌ RECHAZADO"
print(f"{producto['nombre']}: {estado} - {mensaje}")
Cache Inteligente con Identidad
class CacheInteligente:
def __init__(self):
self.cache = {}
self.objetos_cacheados = set() # Para verificar identidad
def obtener(self, clave, funcion_calculo, *args, **kwargs):
"""Obtener valor del cache o calcularlo si no existe"""
# Verificar si ya está en cache
if clave in self.cache:
valor_cacheado, timestamp = self.cache[clave]
# Verificar si el objeto sigue siendo el mismo (identidad)
if id(valor_cacheado) in self.objetos_cacheados:
print(f"📋 Cache hit para: {clave}")
return valor_cacheado
else:
print(f"⚠️ Objeto cambió, recalculando: {clave}")
del self.cache[clave]
# Calcular nuevo valor
print(f"🔄 Calculando: {clave}")
nuevo_valor = funcion_calculo(*args, **kwargs)
# Guardar en cache
import time
self.cache[clave] = (nuevo_valor, time.time())
self.objetos_cacheados.add(id(nuevo_valor))
return nuevo_valor
def invalidar(self, clave):
"""Invalidar entrada específica del cache"""
if clave in self.cache:
valor, _ = self.cache[clave]
self.objetos_cacheados.discard(id(valor))
del self.cache[clave]
print(f"🗑️ Cache invalidado para: {clave}")
def calcular_inventario_costoso(productos):
"""Simulación de cálculo costoso"""
import time
time.sleep(0.1) # Simular trabajo pesado
total = sum(p.get("precio", 0) * p.get("cantidad", 0) for p in productos)
return {"total": total, "productos": len(productos)}
# Ejemplo de uso
cache = CacheInteligente()
productos_almacen = [
{"nombre": "Leche", "precio": 2.5, "cantidad": 100},
{"nombre": "Pan", "precio": 1.8, "cantidad": 50}
]
# Primera llamada (cálculo)
resultado1 = cache.obtener("inventario_total", calcular_inventario_costoso, productos_almacen)
print(f"Resultado 1: {resultado1}")
# Segunda llamada (cache hit)
resultado2 = cache.obtener("inventario_total", calcular_inventario_costoso, productos_almacen)
print(f"Resultado 2: {resultado2}")
# Verificar identidad
print(f"Mismo objeto: {resultado1 is resultado2}")
# Invalidar y recalcular
cache.invalidar("inventario_total")
resultado3 = cache.obtener("inventario_total", calcular_inventario_costoso, productos_almacen)
print(f"Resultado 3: {resultado3}")
print(f"Nuevo objeto: {resultado1 is not resultado3}")
Mejores Prácticas y Errores Comunes
✅ Casos Correctos
# 1. Usar 'is' con None, True, False
def procesar_datos(datos):
if datos is None:
return "Sin datos"
if datos is True:
return "Procesamiento activado"
if datos is False:
return "Procesamiento desactivado"
return f"Procesando: {datos}"
# 2. Usar 'in' para verificar pertenencia
categorias_validas = {"lacteos", "carnes", "verduras", "frutas"}
if categoria in categorias_validas:
print("Categoría válida")
# 3. Usar '==' para comparar valores
lista1 = [1, 2, 3]
lista2 = [1, 2, 3]
if lista1 == lista2: # Comparar contenido
print("Listas iguales")
❌ Errores Comunes
# 1. NO usar 'is' para comparar valores
numero1 = 1000
numero2 = 1000
if numero1 is numero2: # ❌ INCORRECTO - puede ser impredecible
print("Números iguales")
if numero1 == numero2: # ✅ CORRECTO
print("Números iguales")
# 2. NO usar 'is' con listas vacías
lista = []
if lista is []: # ❌ INCORRECTO
print("Lista vacía")
if lista == []: # ✅ CORRECTO
print("Lista vacía")
if not lista: # ✅ MEJOR - más pythónico
print("Lista vacía")
# 3. Cuidado con la mutabilidad
original = [1, 2, 3]
copia = original.copy()
referencia = original
print(f"original is copia: {original is copia}") # False
print(f"original is referencia: {original is referencia}") # True
print(f"original == copia: {original == copia}") # True
Tabla de Referencia Rápida
| Operador | Propósito | Ejemplo | Resultado |
|---|---|---|---|
is | Identidad (mismo objeto) | a is b | True si son el mismo objeto |
is not | No identidad | a is not b | True si son objetos diferentes |
in | Pertenencia | x in lista | True si x está en lista |
not in | No pertenencia | x not in lista | True si x no está en lista |
Cuándo Usar Cada Operador
Usa is cuando:
- Compares con
None,True, oFalse - Verifices tipos específicos con
type() - Trabajes con singletons
- Necesites verificar identidad de objetos
Usa in y not in cuando:
- Verifiques si un elemento está en una colección
- Busques subcadenas en strings
- Implementes filtros o validaciones
- Trabajes con permisos o listas de control
Los operadores de identidad y pertenencia son herramientas precisas que te permiten hacer verificaciones específicas y eficientes. ¡Dominarlos te dará un control más fino sobre tu código!
Resumen y Expresiones Complejas
Ya hemos explorado todos los tipos de operadores individualmente. Ahora es momento de combinarlos para crear expresiones complejas y poderosas, como un maestro chef que combina ingredientes básicos para crear platos extraordinarios. En tu almacén digital, estas expresiones complejas te permitirán tomar decisiones sofisticadas y automatizar procesos avanzados.
Las expresiones complejas son la verdadera magia de la programación: combinan múltiples operadores, tipos de datos y lógica para resolver problemas del mundo real de manera elegante y eficiente.
Precedencia de Operadores: El Orden Importa
Al igual que las matemáticas, Python tiene un orden específico para evaluar las operaciones. Conocer esta precedencia te evitará errores y te dará control total sobre tus expresiones.
# Precedencia de operadores (de mayor a menor)
resultado = 2 + 3 * 4 # Multiplicación primero: 2 + 12 = 14
print(f"2 + 3 * 4 = {resultado}")
# Usando paréntesis para cambiar el orden
resultado = (2 + 3) * 4 # Suma primero: 5 * 4 = 20
print(f"(2 + 3) * 4 = {resultado}")
# Ejemplo complejo con múltiples operadores
precio_base = 100
descuento = 0.1
cantidad = 5
es_cliente_premium = True
# Sin paréntesis - ¿qué se evalúa primero?
total_confuso = precio_base * cantidad - precio_base * descuento and es_cliente_premium
# Con paréntesis - intención clara
total_claro = (precio_base * cantidad) - (precio_base * descuento * (1 if es_cliente_premium else 0))
print(f"Resultado confuso: {total_confuso}")
print(f"Resultado claro: ${total_claro:.2f}")
Tabla de Precedencia Completa
# Demostrando precedencia con ejemplos prácticos
# 1. Paréntesis (mayor precedencia)
resultado = (5 + 3) * 2 # 16
# 2. Exponenciación (**)
resultado = 2 ** 3 ** 2 # 2 ** (3 ** 2) = 2 ** 9 = 512
# 3. Operadores unarios (+, -, not)
resultado = -5 ** 2 # -(5 ** 2) = -25
resultado = (-5) ** 2 # 25
# 4. Multiplicación, división, módulo (*, /, //, %)
resultado = 10 + 5 * 2 # 10 + 10 = 20
# 5. Suma y resta (+, -)
resultado = 5 * 2 + 3 # 10 + 3 = 13
# 6. Desplazamiento de bits (<<, >>)
resultado = 8 + 4 << 1 # (8 + 4) << 1 = 12 << 1 = 24
# 7. AND bit a bit (&)
resultado = 5 | 3 & 1 # 5 | (3 & 1) = 5 | 1 = 5
# 8. XOR bit a bit (^)
resultado = 5 | 3 ^ 1 # 5 | (3 ^ 1) = 5 | 2 = 7
# 9. OR bit a bit (|)
resultado = 5 + 3 | 1 # (5 + 3) | 1 = 8 | 1 = 9
# 10. Comparaciones (==, !=, <, <=, >, >=, is, is not, in, not in)
resultado = 5 + 3 > 6 # (5 + 3) > 6 = 8 > 6 = True
# 11. NOT lógico (not)
resultado = not 5 > 3 # not (5 > 3) = not True = False
# 12. AND lógico (and)
resultado = True or False and False # True or (False and False) = True or False = True
# 13. OR lógico (or) - menor precedencia
resultado = False and True or True # (False and True) or True = False or True = True
print("Todas las precedencias aplicadas correctamente")
Expresiones del Mundo Real: Sistema de Gestión de Almacén
Sistema de Evaluación de Pedidos
class EvaluadorPedidos:
def __init__(self):
self.inventario = {
"leche": {"cantidad": 100, "precio": 3.50, "categoria": "lacteos", "perecedero": True},
"pan": {"cantidad": 50, "precio": 2.25, "categoria": "panaderia", "perecedero": True},
"arroz": {"cantidad": 200, "precio": 1.80, "categoria": "granos", "perecedero": False},
"pollo": {"cantidad": 30, "precio": 8.90, "categoria": "carnes", "perecedero": True},
"detergente": {"cantidad": 75, "precio": 4.50, "categoria": "limpieza", "perecedero": False}
}
self.descuentos_categoria = {
"lacteos": 0.05, # 5%
"carnes": 0.10, # 10%
"limpieza": 0.15, # 15%
"granos": 0.03 # 3%
}
self.cliente_premium_descuento = 0.08 # 8% adicional
self.descuento_volumen_minimo = 100 # Descuento por volumen si compra > $100
self.descuento_volumen_porcentaje = 0.05 # 5%
def evaluar_pedido(self, pedidos, es_cliente_premium=False, pago_contado=False):
"""
Evaluar un pedido complejo con múltiples reglas de negocio
Reglas:
1. Verificar disponibilidad de stock
2. Aplicar descuentos por categoría
3. Descuento premium si es cliente premium
4. Descuento por volumen si total > $100
5. Descuento adicional por pago de contado
6. Alerta especial para productos perecederos
"""
subtotal = 0
productos_validos = []
productos_rechazados = []
alertas = []
# Fase 1: Validar disponibilidad y calcular subtotal
for producto, cantidad_solicitada in pedidos:
if (producto in self.inventario and
self.inventario[producto]["cantidad"] >= cantidad_solicitada and
cantidad_solicitada > 0):
info_producto = self.inventario[producto]
precio_unitario = info_producto["precio"]
precio_total = precio_unitario * cantidad_solicitada
productos_validos.append({
"producto": producto,
"cantidad": cantidad_solicitada,
"precio_unitario": precio_unitario,
"precio_total": precio_total,
"categoria": info_producto["categoria"],
"perecedero": info_producto["perecedero"]
})
subtotal += precio_total
# Alerta para productos perecederos en grandes cantidades
if info_producto["perecedero"] and cantidad_solicitada > 10:
alertas.append(f"⚠️ {producto}: Gran cantidad de producto perecedero ({cantidad_solicitada} unidades)")
else:
razon = ("Producto no existe" if producto not in self.inventario else
f"Stock insuficiente (disponible: {self.inventario[producto]['cantidad']})"
if self.inventario[producto]["cantidad"] < cantidad_solicitada else
"Cantidad inválida")
productos_rechazados.append({
"producto": producto,
"cantidad": cantidad_solicitada,
"razon": razon
})
# Fase 2: Aplicar descuentos complejos
descuento_total = 0
detalle_descuentos = []
# Descuentos por categoría
for item in productos_validos:
categoria = item["categoria"]
if categoria in self.descuentos_categoria:
descuento_categoria = item["precio_total"] * self.descuentos_categoria[categoria]
descuento_total += descuento_categoria
detalle_descuentos.append(f"Descuento {categoria}: -${descuento_categoria:.2f}")
# Descuento cliente premium (aplica sobre el subtotal después de descuentos por categoría)
if es_cliente_premium:
descuento_premium = (subtotal - descuento_total) * self.cliente_premium_descuento
descuento_total += descuento_premium
detalle_descuentos.append(f"Descuento Premium: -${descuento_premium:.2f}")
# Descuento por volumen (aplica si el subtotal supera el mínimo)
if subtotal > self.descuento_volumen_minimo:
descuento_volumen = (subtotal - descuento_total) * self.descuento_volumen_porcentaje
descuento_total += descuento_volumen
detalle_descuentos.append(f"Descuento por volumen: -${descuento_volumen:.2f}")
# Descuento por pago de contado (aplica sobre el total después de otros descuentos)
if pago_contado:
descuento_contado = (subtotal - descuento_total) * 0.03 # 3%
descuento_total += descuento_contado
detalle_descuentos.append(f"Descuento pago contado: -${descuento_contado:.2f}")
# Cálculos finales
total_final = subtotal - descuento_total
porcentaje_descuento_total = (descuento_total / subtotal * 100) if subtotal > 0 else 0
# Fase 3: Evaluación final y recomendaciones
recomendaciones = []
# Recomendar cliente premium si no lo es y compra mucho
if not es_cliente_premium and subtotal > 150:
ahorro_potencial = subtotal * self.cliente_premium_descuento
recomendaciones.append(f"💡 Considera membresía Premium (ahorrarías ${ahorro_potencial:.2f} en esta compra)")
# Recomendar completar productos para mayor descuento
if subtotal < self.descuento_volumen_minimo:
faltante = self.descuento_volumen_minimo - subtotal
recomendaciones.append(f"💡 Agrega ${faltante:.2f} más para descuento por volumen")
# Verificar productos perecederos sin descuento
productos_perecederos_sin_descuento = [
item["producto"] for item in productos_validos
if item["perecedero"] and item["categoria"] not in self.descuentos_categoria
]
if productos_perecederos_sin_descuento:
recomendaciones.append(f"⏰ Productos perecederos: {', '.join(productos_perecederos_sin_descuento)}")
return {
"pedido_valido": len(productos_validos) > 0,
"productos_validos": productos_validos,
"productos_rechazados": productos_rechazados,
"subtotal": subtotal,
"descuento_total": descuento_total,
"total_final": total_final,
"porcentaje_descuento": porcentaje_descuento_total,
"detalle_descuentos": detalle_descuentos,
"alertas": alertas,
"recomendaciones": recomendaciones
}
# Ejemplo de uso del sistema
evaluador = EvaluadorPedidos()
# Pedido complejo
pedido_ejemplo = [
("leche", 15), # Producto perecedero con descuento
("pollo", 5), # Producto perecedero con descuento alto
("arroz", 8), # Producto no perecedero con descuento bajo
("detergente", 3), # Producto no perecedero con descuento alto
("yogur", 2) # Producto que no existe
]
# Evaluar diferentes escenarios
escenarios = [
("Cliente Regular - Tarjeta", False, False),
("Cliente Premium - Tarjeta", True, False),
("Cliente Regular - Contado", False, True),
("Cliente Premium - Contado", True, True)
]
print("=" * 80)
print("EVALUACIÓN DE PEDIDOS COMPLEJOS")
print("=" * 80)
for nombre_escenario, es_premium, pago_contado in escenarios:
print(f"\n🔍 ESCENARIO: {nombre_escenario}")
print("-" * 50)
resultado = evaluador.evaluar_pedido(pedido_ejemplo, es_premium, pago_contado)
# Mostrar productos válidos
if resultado["productos_validos"]:
print("✅ PRODUCTOS ACEPTADOS:")
for item in resultado["productos_validos"]:
print(f" - {item['producto']}: {item['cantidad']} x ${item['precio_unitario']:.2f} = ${item['precio_total']:.2f}")
# Mostrar productos rechazados
if resultado["productos_rechazados"]:
print("\n❌ PRODUCTOS RECHAZADOS:")
for item in resultado["productos_rechazados"]:
print(f" - {item['producto']} ({item['cantidad']} unidades): {item['razon']}")
# Mostrar cálculos financieros
print(f"\n💰 RESUMEN FINANCIERO:")
print(f" Subtotal: ${resultado['subtotal']:.2f}")
if resultado["detalle_descuentos"]:
print(" Descuentos aplicados:")
for descuento in resultado["detalle_descuentos"]:
print(f" • {descuento}")
print(f" Total descuentos: -${resultado['descuento_total']:.2f} ({resultado['porcentaje_descuento']:.1f}%)")
print(f" 🎯 TOTAL FINAL: ${resultado['total_final']:.2f}")
# Mostrar alertas y recomendaciones
if resultado["alertas"]:
print("\n⚠️ ALERTAS:")
for alerta in resultado["alertas"]:
print(f" {alerta}")
if resultado["recomendaciones"]:
print("\n💡 RECOMENDACIONES:")
for recomendacion in resultado["recomendaciones"]:
print(f" {recomendacion}")
print("\n" + "=" * 50)
Expresiones Condicionales Avanzadas
Sistema de Clasificación Inteligente
class ClasificadorInteligente:
"""Sistema que combina múltiples criterios para clasificar elementos"""
@staticmethod
def clasificar_empleado(edad, experiencia, rendimiento, certificaciones, idiomas):
"""
Clasificar empleado usando expresiones complejas
Criterios de clasificación:
- Junior: edad 18-25, experiencia < 2 años, rendimiento > 70
- Senior: experiencia >= 5 años, rendimiento > 80, certificaciones >= 2
- Lead: experiencia >= 8 años, rendimiento > 85, certificaciones >= 3, idiomas >= 2
- Especialista: certificaciones >= 5, rendimiento > 90
"""
# Expresiones complejas que combinan múltiples operadores
es_junior = (18 <= edad <= 25 and
experiencia < 2 and
rendimiento > 70 and
not (certificaciones >= 3 or idiomas >= 2))
es_senior = (experiencia >= 5 and
rendimiento > 80 and
certificaciones >= 2 and
not (experiencia >= 8 and certificaciones >= 3))
es_lead = (experiencia >= 8 and
rendimiento > 85 and
certificaciones >= 3 and
idiomas >= 2 and
not (certificaciones >= 5 and rendimiento > 90))
es_especialista = (certificaciones >= 5 and
rendimiento > 90)
# Evaluación con prioridad
if es_especialista:
return "Especialista", "🏅", 5000
elif es_lead:
return "Lead", "👑", 4000
elif es_senior:
return "Senior", "⭐", 3000
elif es_junior:
return "Junior", "🌱", 2000
else:
return "Trainee", "📚", 1500
@staticmethod
def evaluar_riesgo_credito(ingresos, deudas, historial_credito, edad, empleo_estable):
"""
Evaluar riesgo crediticio con lógica compleja
"""
# Relación deuda-ingreso
ratio_deuda = deudas / ingresos if ingresos > 0 else float('inf')
# Expresión compleja para determinar riesgo
riesgo_bajo = (ingresos >= 3000 and
ratio_deuda <= 0.3 and
historial_credito >= 750 and
empleo_estable and
edad >= 25)
riesgo_medio = (not riesgo_bajo and
ingresos >= 2000 and
ratio_deuda <= 0.5 and
historial_credito >= 650 and
empleo_estable)
riesgo_alto = (not (riesgo_bajo or riesgo_medio) and
ingresos >= 1000 and
ratio_deuda <= 0.7 and
historial_credito >= 500)
if riesgo_bajo:
return "Bajo", "✅", 0.05 # 5% interés
elif riesgo_medio:
return "Medio", "⚠️", 0.12 # 12% interés
elif riesgo_alto:
return "Alto", "⚡", 0.25 # 25% interés
else:
return "Muy Alto", "❌", None # No aprobado
# Ejemplos de clasificación
print("=" * 60)
print("SISTEMA DE CLASIFICACIÓN INTELIGENTE")
print("=" * 60)
# Datos de empleados para clasificar
empleados_datos = [
("Ana", 23, 1.5, 75, 1, 1), # Junior
("Carlos", 30, 6, 85, 3, 1), # Senior
("María", 35, 10, 88, 4, 3), # Lead
("Roberto", 28, 7, 92, 6, 2), # Especialista
("Elena", 22, 0.5, 65, 0, 1) # Trainee
]
print("🏢 CLASIFICACIÓN DE EMPLEADOS:")
for nombre, edad, exp, rend, cert, idiomas in empleados_datos:
categoria, emoji, salario = ClasificadorInteligente.clasificar_empleado(
edad, exp, rend, cert, idiomas
)
print(f"{emoji} {nombre}: {categoria} (${salario:,})")
print(f" Edad: {edad}, Exp: {exp} años, Rend: {rend}%, Cert: {cert}, Idiomas: {idiomas}")
print("\n💳 EVALUACIÓN DE RIESGO CREDITICIO:")
clientes_credito = [
("Cliente A", 5000, 1000, 800, 30, True), # Bajo riesgo
("Cliente B", 2500, 1000, 700, 28, True), # Medio riesgo
("Cliente C", 1500, 800, 600, 25, False), # Alto riesgo
("Cliente D", 800, 600, 450, 20, False) # Muy alto riesgo
]
for nombre, ingresos, deudas, historial, edad, empleo in clientes_credito:
riesgo, emoji, interes = ClasificadorInteligente.evaluar_riesgo_credito(
ingresos, deudas, historial, edad, empleo
)
aprobacion = "APROBADO" if interes else "RECHAZADO"
interes_str = f"{interes*100:.1f}%" if interes else "N/A"
print(f"{emoji} {nombre}: {riesgo} - {aprobacion} (Interés: {interes_str})")
print(f" Ingresos: ${ingresos:,}, Deudas: ${deudas:,}, Score: {historial}")
Expresiones con Operadores Ternarios
Python permite crear expresiones condicionales compactas usando el operador ternario.
# Sintaxis: valor_si_verdadero if condicion else valor_si_falso
def procesar_inventario(productos):
"""Procesar inventario con expresiones ternarias elegantes"""
resultados = []
for nombre, cantidad, precio in productos:
# Expresiones ternarias anidadas y complejas
estado = ("AGOTADO" if cantidad == 0 else
"BAJO" if cantidad < 10 else
"CRÍTICO" if cantidad < 5 else
"NORMAL")
urgencia = ("🚨" if cantidad == 0 else
"⚠️" if cantidad < 10 else
"⚡" if cantidad < 5 else
"✅")
# Expresión compleja para calcular descuento
descuento = (0.20 if cantidad == 0 else # 20% para liquidación
0.15 if cantidad < 5 else # 15% por cantidad crítica
0.10 if cantidad < 10 else # 10% por cantidad baja
0.05 if precio > 50 else # 5% para productos caros
0.0) # Sin descuento
precio_final = precio * (1 - descuento)
# Mensaje personalizado usando expresiones ternarias
mensaje = (f"¡LIQUIDACIÓN! {descuento*100:.0f}% OFF" if descuento >= 0.15 else
f"Oferta especial: {descuento*100:.0f}% descuento" if descuento > 0 else
"Precio regular")
resultados.append({
"nombre": nombre,
"cantidad": cantidad,
"precio_original": precio,
"precio_final": precio_final,
"descuento": descuento,
"estado": estado,
"urgencia": urgencia,
"mensaje": mensaje
})
return resultados
# Ejemplo de uso
productos_inventario = [
("Laptop Gaming", 0, 1200.00), # Agotado
("Mouse Inalámbrico", 3, 45.00), # Crítico
("Teclado Mecánico", 8, 85.00), # Bajo
("Monitor 4K", 15, 350.00), # Normal, producto caro
("Audífonos", 25, 30.00) # Normal, producto barato
]
print("=" * 70)
print("PROCESAMIENTO DE INVENTARIO CON EXPRESIONES TERNARIAS")
print("=" * 70)
resultados = procesar_inventario(productos_inventario)
for item in resultados:
print(f"{item['urgencia']} {item['nombre']}")
print(f" Estado: {item['estado']} | Cantidad: {item['cantidad']}")
print(f" Precio: ${item['precio_original']:.2f} → ${item['precio_final']:.2f}")
print(f" {item['mensaje']}")
print()
Expresiones Lambda y Funciones de Orden Superior
Las expresiones lambda te permiten crear funciones pequeñas e inline para transformar datos.
# Procesamiento avanzado de datos con lambdas
ventas_datos = [
{"producto": "Laptop", "cantidad": 5, "precio": 1000, "vendedor": "Ana", "mes": "Enero"},
{"producto": "Mouse", "cantidad": 15, "precio": 25, "vendedor": "Carlos", "mes": "Enero"},
{"producto": "Teclado", "cantidad": 8, "precio": 75, "vendedor": "Ana", "mes": "Febrero"},
{"producto": "Monitor", "cantidad": 3, "precio": 300, "vendedor": "María", "mes": "Febrero"},
{"producto": "Laptop", "cantidad": 2, "precio": 1000, "vendedor": "Carlos", "mes": "Marzo"},
]
print("=" * 60)
print("ANÁLISIS DE VENTAS CON EXPRESIONES LAMBDA")
print("=" * 60)
# 1. Calcular total de ventas por producto
ventas_con_total = list(map(
lambda venta: {**venta, "total": venta["cantidad"] * venta["precio"]},
ventas_datos
))
print("💰 VENTAS CON TOTALES:")
for venta in ventas_con_total:
print(f" {venta['producto']}: {venta['cantidad']} x ${venta['precio']} = ${venta['total']:,}")
# 2. Filtrar ventas importantes (total > $500)
ventas_importantes = list(filter(
lambda venta: venta["cantidad"] * venta["precio"] > 500,
ventas_datos
))
print(f"\n🎯 VENTAS IMPORTANTES (>$500): {len(ventas_importantes)} transacciones")
# 3. Agrupar ventas por vendedor usando expresiones complejas
from collections import defaultdict
ventas_por_vendedor = defaultdict(lambda: {"total_ventas": 0, "productos_vendidos": 0, "transacciones": 0})
for venta in ventas_datos:
vendedor = venta["vendedor"]
total_venta = venta["cantidad"] * venta["precio"]
ventas_por_vendedor[vendedor]["total_ventas"] += total_venta
ventas_por_vendedor[vendedor]["productos_vendidos"] += venta["cantidad"]
ventas_por_vendedor[vendedor]["transacciones"] += 1
print("\n👥 RESUMEN POR VENDEDOR:")
for vendedor, stats in ventas_por_vendedor.items():
promedio = stats["total_ventas"] / stats["transacciones"]
print(f" {vendedor}: ${stats['total_ventas']:,} ({stats['productos_vendidos']} productos, promedio: ${promedio:.0f})")
# 4. Ranking de productos usando lambdas complejas
from functools import reduce
# Agrupar por producto y calcular métricas
productos_stats = {}
for venta in ventas_datos:
producto = venta["producto"]
if producto not in productos_stats:
productos_stats[producto] = {"ventas": [], "total_cantidad": 0, "total_ingresos": 0}
productos_stats[producto]["ventas"].append(venta)
productos_stats[producto]["total_cantidad"] += venta["cantidad"]
productos_stats[producto]["total_ingresos"] += venta["cantidad"] * venta["precio"]
# Crear ranking usando lambda para ordenar
ranking_productos = sorted(
productos_stats.items(),
key=lambda item: (
item[1]["total_ingresos"], # Criterio principal: ingresos
item[1]["total_cantidad"], # Criterio secundario: cantidad
len(item[1]["ventas"]) # Criterio terciario: frecuencia
),
reverse=True
)
print("\n🏆 RANKING DE PRODUCTOS:")
for i, (producto, stats) in enumerate(ranking_productos, 1):
print(f" {i}. {producto}: ${stats['total_ingresos']:,} ({stats['total_cantidad']} unidades)")
# 5. Análisis predictivo usando expresiones complejas
tendencias = {}
for venta in ventas_datos:
mes = venta["mes"]
if mes not in tendencias:
tendencias[mes] = {"ingresos": 0, "unidades": 0}
tendencias[mes]["ingresos"] += venta["cantidad"] * venta["precio"]
tendencias[mes]["unidades"] += venta["cantidad"]
# Calcular crecimiento mes a mes
meses_ordenados = ["Enero", "Febrero", "Marzo"]
print("\n📈 TENDENCIAS MENSUALES:")
for i, mes in enumerate(meses_ordenados):
if mes in tendencias:
ingresos = tendencias[mes]["ingresos"]
unidades = tendencias[mes]["unidades"]
if i > 0:
mes_anterior = meses_ordenados[i-1]
if mes_anterior in tendencias:
crecimiento = ((ingresos - tendencias[mes_anterior]["ingresos"]) /
tendencias[mes_anterior]["ingresos"] * 100)
tendencia_emoji = "📈" if crecimiento > 0 else "📉" if crecimiento < 0 else "➡️"
print(f" {mes}: ${ingresos:,} ({unidades} unidades) {tendencia_emoji} {crecimiento:+.1f}%")
else:
print(f" {mes}: ${ingresos:,} ({unidades} unidades)")
else:
print(f" {mes}: ${ingresos:,} ({unidades} unidades) [Base]")
Mejores Prácticas para Expresiones Complejas
1. Usar Variables Intermedias para Claridad
# ❌ Expresión difícil de leer
resultado = (precio * cantidad * (1 - descuento) * (1 + impuesto)
if stock > cantidad and cliente_valido and pago_confirmado
else 0)
# ✅ Dividir en pasos claros
tiene_stock = stock > cantidad
transaccion_valida = cliente_valido and pago_confirmado
precio_base = precio * cantidad
precio_con_descuento = precio_base * (1 - descuento)
precio_final = precio_con_descuento * (1 + impuesto)
resultado = precio_final if tiene_stock and transaccion_valida else 0
2. Documentar Expresiones Complejas
def calcular_score_cliente(compras, valor_total, antiguedad, devoluciones):
"""
Calcular score del cliente basado en múltiples factores
Fórmula: (compras * 10 + valor_total / 100 + antiguedad * 5) / (devoluciones + 1)
- Más compras = mejor score
- Mayor valor total = mejor score
- Mayor antigüedad = mejor score
- Más devoluciones = peor score
"""
# Componentes del score
puntos_compras = compras * 10 # 10 puntos por compra
puntos_valor = valor_total / 100 # 1 punto por cada $100
puntos_antiguedad = antiguedad * 5 # 5 puntos por mes de antigüedad
# Penalización por devoluciones (evitar división por cero)
factor_devoluciones = devoluciones + 1
# Score final
score = (puntos_compras + puntos_valor + puntos_antiguedad) / factor_devoluciones
return min(score, 1000) # Máximo 1000 puntos
3. Validar Entrada para Expresiones Complejas
def calcular_precio_dinamico(base, modificadores):
"""
Calcular precio dinámico con validaciones robustas
"""
# Validaciones de entrada
if not isinstance(base, (int, float)) or base <= 0:
raise ValueError("El precio base debe ser un número positivo")
if not isinstance(modificadores, dict):
raise ValueError("Los modificadores deben ser un diccionario")
# Valores por defecto para evitar errores
descuento = max(0, min(1, modificadores.get("descuento", 0))) # Entre 0 y 1
impuesto = max(0, modificadores.get("impuesto", 0)) # Mínimo 0
factor_demanda = max(0.1, modificadores.get("demanda", 1)) # Mínimo 0.1
# Expresión compleja con validaciones
precio_final = (base *
(1 - descuento) *
(1 + impuesto) *
factor_demanda)
return round(precio_final, 2)
# Ejemplo de uso seguro
try:
precio = calcular_precio_dinamico(100, {
"descuento": 0.1,
"impuesto": 0.16,
"demanda": 1.2
})
print(f"Precio calculado: ${precio}")
except ValueError as e:
print(f"Error en cálculo: {e}")
Resumen: Dominando las Expresiones Complejas
Las expresiones complejas son como las recetas maestras de la programación: combinan ingredientes básicos (operadores) para crear soluciones poderosas. Al dominar estos conceptos, puedes:
- Escribir código más expresivo: Una línea bien construida puede reemplazar múltiples líneas de lógica
- Tomar decisiones sofisticadas: Combinar múltiples criterios en evaluaciones complejas
- Procesar datos eficientemente: Usar lambdas y funciones de orden superior para transformaciones elegantes
- Crear sistemas inteligentes: Implementar lógica de negocio avanzada de manera clara y mantenible
Principios Clave para Recordar:
- Precedencia importa: Usa paréntesis para clarificar el orden de evaluación
- Legibilidad es clave: Divide expresiones complejas en pasos comprensibles
- Valida entradas: Las expresiones complejas son más propensas a errores
- Documenta lógica: Explica el “por qué” detrás de expresiones complicadas
- Prueba exhaustivamente: Expresiones complejas necesitan casos de prueba diversos
¡Con estas herramientas, puedes crear programas que tomen decisiones inteligentes y procesen información de manera sofisticada, como un verdadero maestro de la automatización de almacenes!
Quiz: Operadores y Expresiones
🧭 Navegación:
- Volver a: Resumen de Operadores y Expresiones
¡Es hora de poner a prueba tus conocimientos sobre operadores y expresiones en Python! Este quiz cubre todos los tipos de operadores que hemos visto en esta sección.
Instrucciones
- Lee cada pregunta cuidadosamente
- Intenta responder sin mirar las soluciones
- Al final, compara tus respuestas con las soluciones proporcionadas
- Cada respuesta correcta vale 1 punto
Preguntas
1. Operadores Matemáticos
¿Cuál es el resultado de la siguiente expresión?
resultado = 20 - 5 * 2 + 10 / 2
a) 5.0 b) 10.0 c) 15.0 d) 20.0
2. Operadores de Comparación
¿Cuál de las siguientes expresiones evalúa a True?
a) 5 > 7
b) "abc" > "abd"
c) 10 <= 10
d) 5 != 5
3. Operadores Lógicos
¿Cuál es el resultado de la siguiente expresión?
not (True and False) or (True or False)
a) True
b) False
c) Error de sintaxis
d) Depende del contexto
4. Operadores de Asignación
¿Qué valor tendrá x después de ejecutar este código?
x = 10
x += 5
x *= 2
x //= 3
a) 8 b) 9 c) 10 d) 11
5. Operadores Bit a Bit
¿Cuál es el resultado de 5 & 3?
a) 0 b) 1 c) 7 d) 8
6. Operadores de Identidad
¿Cuál de las siguientes afirmaciones es correcta?
a) is compara valores, mientras que == compara identidad
b) is y == son siempre equivalentes
c) is compara identidad, mientras que == compara valores
d) is solo funciona con números, mientras que == funciona con cualquier tipo
7. Operadores de Pertenencia
¿Cuál es el resultado de la siguiente expresión?
"a" in "Python"
a) True
b) False
c) Error de sintaxis
d) None
8. Precedencia de Operadores
¿Cuál es el resultado de la siguiente expresión?
2 ** 3 * 2 + 10 // 5
a) 18 b) 16 c) 20 d) 64
9. Expresiones Complejas
¿Cuál es el resultado de la siguiente expresión?
x = 5
y = 10
z = 0
resultado = x < y and y > z or x / z
a) True
b) False
c) Error (división por cero)
d) None
10. Aplicación Práctica
¿Qué código verificaría correctamente si un número es divisible por 2 y por 3, pero no por 5?
a) numero % 2 == 0 and numero % 3 == 0 and numero % 5 != 0
b) numero % 2 == 0 or numero % 3 == 0 and numero % 5 != 0
c) numero % 2 == 0 and numero % 3 == 0 or numero % 5 != 0
d) not (numero % 2 or numero % 3) and numero % 5
Soluciones
Haz clic para ver las respuestas
1. Operadores Matemáticos
Respuesta: c) 15.0
Explicación:
resultado = 20 - 5 * 2 + 10 / 2
= 20 - 10 + 5.0
= 10 + 5.0
= 15.0
2. Operadores de Comparación
Respuesta: c) 10 <= 10
Explicación:
5 > 7esFalseporque 5 no es mayor que 7"abc" > "abd"esFalseporque “abc” viene antes que “abd” en orden lexicográfico10 <= 10esTrueporque 10 es igual a 105 != 5esFalseporque 5 es igual a 5
3. Operadores Lógicos
Respuesta: a) True
Explicación:
not (True and False) or (True or False)
= not (False) or (True)
= True or True
= True
4. Operadores de Asignación
Respuesta: c) 10
Explicación:
x = 10
x += 5 # x = 10 + 5 = 15
x *= 2 # x = 15 * 2 = 30
x //= 3 # x = 30 // 3 = 10
5. Operadores Bit a Bit
Respuesta: b) 1
Explicación:
5 en binario: 101
3 en binario: 011
5 & 3: 001 (1 en decimal)
6. Operadores de Identidad
Respuesta: c) is compara identidad, mientras que == compara valores
Explicación:
isverifica si dos variables se refieren al mismo objeto en memoria==verifica si dos variables tienen el mismo valor
7. Operadores de Pertenencia
Respuesta: b) False
Explicación: La letra “a” no está presente en la cadena “Python”.
8. Precedencia de Operadores
Respuesta: a) 18
Explicación:
2 ** 3 * 2 + 10 // 5
= 8 * 2 + 10 // 5
= 8 * 2 + 2
= 16 + 2
= 18
9. Expresiones Complejas
Respuesta: a) True
Explicación: Debido a la evaluación en cortocircuito, Python evalúa:
x < y and y > z or x / z
= 5 < 10 and 10 > 0 or x / z
= True and True or x / z
= True or x / z
Como el primer operando de or es True, Python no evalúa el segundo operando (x / z), evitando así el error de división por cero.
10. Aplicación Práctica
Respuesta: a) numero % 2 == 0 and numero % 3 == 0 and numero % 5 != 0
Explicación:
numero % 2 == 0: Verifica si el número es divisible por 2numero % 3 == 0: Verifica si el número es divisible por 3numero % 5 != 0: Verifica si el número NO es divisible por 5
Puntuación
- 9-10 puntos: ¡Excelente! Dominas los operadores en Python.
- 7-8 puntos: Muy bien. Tienes un buen entendimiento, pero repasa algunos conceptos.
- 5-6 puntos: Aceptable. Necesitas reforzar tu comprensión de algunos operadores.
- Menos de 5 puntos: Recomendamos revisar nuevamente los capítulos sobre operadores.
🧭 Navegación:
- Volver a: Resumen de Operadores y Expresiones
Control de Flujo – Condicionales
🧭 Navegación:
- Anterior: Operadores y Expresiones
- Siguiente: Control de Flujo – Bucles
¡Bienvenido al centro de decisiones de tu almacén! Hasta ahora has aprendido a organizar cajas (variables), usar herramientas (operadores), y hacer comparaciones. Ahora viene lo más emocionante: ¡hacer que tu programa piense y tome decisiones como tú!
Los condicionales son como tener un gerente súper inteligente en tu almacén que puede evaluar situaciones y decidir qué hacer en cada caso.
El gerente inteligente de tu almacén 🧠
Imagínate que contratas a un gerente para tu almacén que es capaz de:
- Evaluar situaciones usando las herramientas de comparación
- Tomar decisiones basadas en esas evaluaciones
- Ejecutar diferentes acciones según cada situación
- Manejar múltiples escenarios complejos
# El gerente en acción
edad = 17
# El gerente evalúa y decide
if edad >= 18:
print(f"Eres mayor de edad, puedes votar")
else:
print(f"Eres menor de edad, aún no puedes votar")
Este gerente usa la palabra mágica if (si) para evaluar condiciones y tomar decisiones.
¿Qué es el control de flujo?
El control de flujo es la capacidad de tu programa para tomar diferentes caminos según las circunstancias. Es como tener un mapa con múltiples rutas y elegir cuál tomar según las condiciones del momento.
Mi perspectiva personal: Siempre pienso en los condicionales como en las bifurcaciones de un camino. Cada
ifes un punto donde el programa debe decidir qué ruta tomar. Esta forma de pensar me ayuda a visualizar el flujo del programa y a entender cómo se comportará en diferentes situaciones.
Contenido de este capítulo
En este capítulo aprenderás sobre:
- Condicionales - El gerente inteligente que toma decisiones
- Sentencias if/elif/else
- Condiciones simples y complejas
- Condicionales anidados
¿Por qué son importantes los condicionales?
Los condicionales son fundamentales porque:
- Permiten que los programas tomen decisiones basadas en condiciones
- Hacen que el código sea adaptable a diferentes situaciones
- Son la base de toda lógica de negocio
- Permiten crear programas interactivos y dinámicos
Analogía del almacén
Los condicionales son como el gerente inteligente que toma decisiones:
- Si llega un cliente VIP → atención prioritaria
- Si el inventario es bajo → realizar pedido
- Si es viernes → preparar reporte semanal
Mapa conceptual
CONDICIONALES (Toma de decisiones)
|
|-- if (si)
| |-- Condición simple
| |-- Bloque de código
|
|-- elif (sino si)
| |-- Múltiples condiciones
| |-- Evaluación secuencial
|
|-- else (sino)
|-- Caso por defecto
|-- Captura todo lo demás
¡Comencemos a darle inteligencia a tus programas!
🧭 Navegación:
- Anterior: Operadores y Expresiones
- Siguiente: Control de Flujo – Bucles
Contenido de este capítulo:
- Introducción a Condicionales (página actual)
- Condicionales
Condicionales: El Gerente Inteligente
🧭 Navegación:
- Anterior: Control de Flujo – Condicionales
- Siguiente: Control de Flujo – Bucles
¡Bienvenido al centro de decisiones de tu almacén! Hasta ahora has aprendido a organizar cajas (variables), usar herramientas (operadores), y hacer comparaciones. Ahora viene lo más emocionante: ¡hacer que tu programa piense y tome decisiones como tú!
Los condicionales son como tener un gerente súper inteligente en tu almacén que puede evaluar situaciones y decidir qué hacer en cada caso.
El gerente inteligente de tu almacén 🧠
Imagínate que contratas a un gerente para tu almacén que es capaz de:
- Evaluar situaciones usando las herramientas de comparación
- Tomar decisiones basadas en esas evaluaciones
- Ejecutar diferentes acciones según cada situación
- Manejar múltiples escenarios complejos
# El gerente en acción
edad = 17
# El gerente evalúa y decide
if edad >= 18:
print(f"Eres mayor de edad, puedes votar")
else:
print(f"Eres menor de edad, aún no puedes votar")
Este gerente usa la palabra mágica if (si) para evaluar condiciones y tomar decisiones.
¿Qué es el control de flujo?
El control de flujo es la capacidad de tu programa para tomar diferentes caminos según las circunstancias. Es como tener un mapa con múltiples rutas y elegir cuál tomar según las condiciones del momento.
Sin control de flujo (aburrido):
# El programa siempre hace lo mismo
print("Buenos días")
print("¿Cómo estás?")
print("Que tengas buen día")
Con control de flujo (¡inteligente!):
import datetime
hora_actual = datetime.datetime.now().hour
# El programa se adapta a la situación
if hora_actual < 12:
print("¡Buenos días!")
elif hora_actual < 18:
print("¡Buenas tardes!")
else:
print("¡Buenas noches!")
print("¿Cómo estás?")
print("Que tengas buen día")
🔍 Mi perspectiva personal: Siempre pienso en los condicionales como en las bifurcaciones de un camino. Cada
ifes un punto donde el programa debe decidir qué ruta tomar. Esta forma de pensar me ayuda a visualizar el flujo del programa y a entender cómo se comportará en diferentes situaciones.
La estructura básica: if (si)
La estructura más básica es if (si). Es como preguntarle al gerente: “Si esta condición es verdadera, ¿qué hago?”
Sintaxis básica:
if condicion:
# Código que se ejecuta si la condición es True
accion_a_realizar()
Ejemplo práctico:
# ================================
# DETECTOR DE TEMPERATURA
# ================================
temperatura = 35
print("🌡️ DETECTOR DE TEMPERATURA")
print(f"Temperatura actual: {temperatura} °C")
# El gerente evalúa la temperatura
if temperatura > 30:
print("🔥 ¡Hace mucho calor!")
print("💧 Recuerda hidratarte")
print("🏠 Considera usar aire acondicionado")
print("📊 Reporte de temperatura completado")
Nota importante: Fíjate en la indentación (espacios al inicio). Todo el código que está indentado después del if solo se ejecuta si la condición es verdadera.
La estructura completa: if-else (si-sino)
A veces el gerente necesita decidir entre dos opciones: “Si pasa esto, haz A; si no, haz B”.
Sintaxis:
if condicion:
# Código si la condición es True
hacer_esto()
else:
# Código si la condición es False
hacer_esto_otro()
Ejemplo práctico:
# ================================
# SISTEMA DE ACCESO
# ================================
contraseña_correcta = "python123"
contraseña_ingresada = "python123" # Simular entrada del usuario
print("🔐 SISTEMA DE ACCESO")
print("Verificando credenciales...")
# El gerente evalúa las credenciales
if contraseña_ingresada == contraseña_correcta:
print("✅ Acceso concedido")
print("🏠 Bienvenido al sistema")
print("📊 Cargando panel de control...")
else:
print("❌ Acceso denegado")
print("🚫 Contraseña incorrecta")
print("🔄 Intenta nuevamente")
print("🔚 Proceso de autenticación completado")
La estructura múltiple: if-elif-else (si-sino si-sino)
Para situaciones más complejas, el gerente puede evaluar múltiples condiciones en orden:
Sintaxis:
if primera_condicion:
# Código para la primera condición
hacer_a()
elif segunda_condicion:
# Código para la segunda condición
hacer_b()
elif tercera_condicion:
# Código para la tercera condición
hacer_c()
else:
# Código si ninguna condición es verdadera
hacer_por_defecto()
Ejemplo práctico:
# ================================
# CALCULADORA DE CALIFICACIONES
# ================================
calificacion = 85
print("📊 CALCULADORA DE CALIFICACIONES")
print(f"Calificación obtenida: {calificacion}")
print()
# El gerente evalúa múltiples rangos
if calificacion >= 90:
print("🏆 ¡EXCELENTE!")
print("⭐ Calificación: A")
print("🎉 ¡Felicidades por tu excelente desempeño!")
elif calificacion >= 80:
print("😊 ¡MUY BIEN!")
print("⭐ Calificación: B")
print("👍 Buen trabajo, sigue así")
elif calificacion >= 70:
print("🙂 BIEN")
print("⭐ Calificación: C")
print("📚 Puedes mejorar con más estudio")
elif calificacion >= 60:
print("😐 REGULAR")
print("⭐ Calificación: D")
print("⚠️ Necesitas esforzarte más")
else:
print("😞 INSUFICIENTE")
print("⭐ Calificación: F")
print("📖 Es importante que estudies más")
print()
print("📋 Evaluación completada")
Condiciones complejas
El gerente puede evaluar condiciones muy complejas usando las herramientas que aprendimos en el capítulo anterior:
Usando operadores lógicos:
# ================================
# SISTEMA DE DESCUENTOS INTELIGENTE
# ================================
edad_cliente = 25
es_estudiante = True
compra_total = 500
es_primera_compra = False
es_cliente_premium = False
print("🛒 SISTEMA DE DESCUENTOS INTELIGENTE")
print("=" * 40)
print("👤 Información del cliente:")
print(f"Edad: {edad_cliente}")
print(f"Es estudiante: {es_estudiante}")
print(f"Compra total: ${compra_total}")
print(f"Primera compra: {es_primera_compra}")
print(f"Cliente premium: {es_cliente_premium}")
print()
# El gerente evalúa múltiples condiciones complejas
print("🔍 Evaluando descuentos disponibles...")
print()
# Descuento por edad (tercera edad o joven)
if edad_cliente >= 65 or edad_cliente <= 25:
if edad_cliente >= 65:
print("👴 Descuento tercera edad: 15%")
descuento_edad = 15
else:
print("👶 Descuento joven: 10%")
descuento_edad = 10
else:
descuento_edad = 0
# Descuento por estudiante
if es_estudiante and edad_cliente <= 30:
print("🎓 Descuento estudiante: 12%")
descuento_estudiante = 12
else:
descuento_estudiante = 0
# Descuento por monto de compra
if compra_total >= 1000:
print("💰 Descuento compra alta: 20%")
descuento_compra = 20
elif compra_total >= 500:
print("💵 Descuento compra media: 10%")
descuento_compra = 10
else:
descuento_compra = 0
# Descuento especial
if es_primera_compra and compra_total >= 200:
print("🎁 Descuento primera compra: 15%")
descuento_especial = 15
elif es_cliente_premium:
print("⭐ Descuento cliente premium: 25%")
descuento_especial = 25
else:
descuento_especial = 0
# Calcular el mejor descuento
descuento_maximo = max(descuento_edad, descuento_estudiante,
descuento_compra, descuento_especial)
print()
print("🎯 RESULTADO:")
if descuento_maximo > 0:
ahorro = compra_total * (descuento_maximo / 100)
precio_final = compra_total - ahorro
print("✅ ¡Tienes descuento!")
print(f"Descuento aplicado: {descuento_maximo}%")
print(f"Ahorro: ${round(ahorro, 2)}")
print(f"Precio final: ${round(precio_final, 2)}")
else:
print("❌ No hay descuentos disponibles")
print(f"Precio final: ${compra_total}")
Condicionales anidados
A veces el gerente necesita tomar decisiones dentro de otras decisiones:
# ================================
# SISTEMA DE RECOMENDACIÓN DE ACTIVIDADES
# ================================
clima = "soleado" # "soleado", "lluvioso", "nublado"
temperatura = 25
tiene_dinero = True
tiene_tiempo = True
print("🌤️ SISTEMA DE RECOMENDACIÓN DE ACTIVIDADES")
print("=" * 50)
print(f"Clima: {clima}")
print(f"Temperatura: {temperatura} °C")
print(f"Tiene dinero: {tiene_dinero}")
print(f"Tiene tiempo: {tiene_tiempo}")
print()
print("🤔 Analizando opciones...")
print()
# Primera decisión: evaluar el clima
if clima == "soleado":
print("☀️ ¡Qué buen día!")
# Segunda decisión: evaluar la temperatura
if temperatura >= 25:
print("🏖️ Perfecto para actividades al aire libre")
# Tercera decisión: evaluar recursos
if tiene_dinero and tiene_tiempo:
print("🎯 RECOMENDACIONES:")
print(" • Ir a la playa")
print(" • Hacer un picnic en el parque")
print(" • Visitar un parque de diversiones")
elif tiene_tiempo:
print("🎯 RECOMENDACIONES (sin costo):")
print(" • Caminar en el parque")
print(" • Hacer ejercicio al aire libre")
print(" • Visitar lugares gratuitos")
elif tiene_dinero:
print("🎯 RECOMENDACIONES (rápidas):")
print(" • Tomar un café en terraza")
print(" • Comprar helado")
else:
print("🎯 RECOMENDACIÓN:")
print(" • Sentarse en el parque a disfrutar el sol")
else:
print("🧥 Hace un poco de frío, pero se puede salir")
if tiene_dinero and tiene_tiempo:
print("🎯 RECOMENDACIONES:")
print(" • Ir al cine")
print(" • Visitar un museo")
print(" • Ir a un café")
else:
print("🎯 RECOMENDACIÓN:")
print(" • Dar un paseo corto")
elif clima == "lluvioso":
print("🌧️ Está lloviendo")
if tiene_dinero:
print("🎯 RECOMENDACIONES (lugares cerrados):")
print(" • Ir al cine")
print(" • Visitar un centro comercial")
print(" • Ir a un café")
else:
print("🎯 RECOMENDACIONES (en casa):")
print(" • Leer un libro")
print(" • Ver películas")
print(" • Cocinar algo especial")
else: # clima nublado
print("☁️ Día nublado")
print("🎯 RECOMENDACIÓN:")
print(" • Actividades flexibles que se puedan mover adentro si es necesario")
print()
print("🌟 ¡Que disfrutes tu día!")
Operador ternario: Decisiones en una línea
Python ofrece una forma compacta de tomar decisiones simples en una sola línea:
Sintaxis:
valor_si_verdadero if condicion else valor_si_falso
Ejemplo práctico:
# ================================
# VERIFICADOR DE EDAD RÁPIDO
# ================================
edad = 20
# Versión normal con if-else
if edad >= 18:
estado = "Mayor de edad"
else:
estado = "Menor de edad"
print(f"Versión normal: {estado}")
# Versión con operador ternario
estado = "Mayor de edad" if edad >= 18 else "Menor de edad"
print(f"Versión ternaria: {estado}")
# Uso práctico en una función
def calcular_precio(precio_base, es_miembro):
descuento = 0.15 if es_miembro else 0
return precio_base * (1 - descuento)
precio_normal = calcular_precio(100, False)
precio_miembro = calcular_precio(100, True)
print(f"Precio normal: ${precio_normal}")
print(f"Precio miembro: ${precio_miembro}")
Buenas prácticas para condicionales
1. Usa nombres descriptivos para condiciones complejas:
# ❌ CONFUSO
if edad >= 18 and (ingresos > 30000 or tiene_aval) and historial_crediticio > 650:
aprobar_prestamo()
# ✅ CLARO
es_mayor_edad = edad >= 18
tiene_ingresos_suficientes = ingresos > 30000 or tiene_aval
buen_historial_crediticio = historial_crediticio > 650
if es_mayor_edad and tiene_ingresos_suficientes and buen_historial_crediticio:
aprobar_prestamo()
2. Ordena las condiciones de más específica a más general:
# ✅ CORRECTO - de específico a general
if calificacion >= 95:
print("Excelencia académica")
elif calificacion >= 90:
print("Muy bueno")
elif calificacion >= 80:
print("Bueno")
else:
print("Necesita mejorar")
3. Evita condicionales demasiado anidados:
# ❌ DIFÍCIL DE LEER
if condicion1:
if condicion2:
if condicion3:
if condicion4:
hacer_algo()
# ✅ MÁS CLARO
if condicion1 and condicion2 and condicion3 and condicion4:
hacer_algo()
Comprueba tu comprensión 🧠
-
¿Qué imprimirá el siguiente código?
x = 15 y = 10 if x > y: print("A") elif x == y: print("B") else: print("C") -
¿Cuál es la diferencia entre
if-elif-elsey múltiples sentenciasifindependientes? -
Escribe un código que determine si un año es bisiesto usando condicionales.
-
¿Qué valor tendrá
resultadoen este código?a = 5 b = 10 resultado = "Mayor" if a > b else "Menor o igual"
Soluciones
-
El código imprimirá
"A"porquex > yes verdadero (15 > 10). -
Diferencia entre
if-elif-elsey múltiplesif:- En una estructura
if-elif-else, solo se ejecuta el bloque de la primera condición que sea verdadera. - Con múltiples sentencias
ifindependientes, se evalúan todas las condiciones y se ejecutan todos los bloques cuyas condiciones sean verdaderas. Ejemplo:
# Con if-elif-else (solo se ejecuta uno) if x > 10: print("Mayor que 10") elif x > 5: print("Mayor que 5") # No se ejecuta aunque sea verdadero si x > 10 # Con múltiples if (se ejecutan todos los verdaderos) if x > 10: print("Mayor que 10") if x > 5: print("Mayor que 5") # Se ejecuta si x > 5, independientemente de x > 10 - En una estructura
-
Código para determinar si un año es bisiesto:
año = 2024 if (año % 4 == 0 and año % 100 != 0) or (año % 400 == 0): print(f"{año} es un año bisiesto") else: print(f"{año} no es un año bisiesto") -
El valor de
resultadoserá"Menor o igual"porquea > bes falso (5 no es mayor que 10).
Ejercicio práctico: Sistema de evaluación médica
Vamos a crear un sistema complejo que combine todo lo aprendido:
# ================================
# SISTEMA DE EVALUACIÓN MÉDICA BÁSICA
# ================================
print("🏥 SISTEMA DE EVALUACIÓN MÉDICA BÁSICA")
print("=" * 45)
# Datos del paciente
nombre_paciente = "Ana García"
edad = 45
temperatura = 38.2
presion_sistolica = 140
presion_diastolica = 85
frecuencia_cardiaca = 95
tiene_sintomas_respiratorios = True
tiene_dolor_pecho = False
toma_medicamentos = True
print("👤 INFORMACIÓN DEL PACIENTE:")
print(f"Nombre: {nombre_paciente}")
print(f"Edad: {edad} años")
print(f"Temperatura: {temperatura} °C")
print(f"Presión arterial: {presion_sistolica}/{presion_diastolica} mmHg")
print(f"Frecuencia cardíaca: {frecuencia_cardiaca} bpm")
print(f"Síntomas respiratorios: {tiene_sintomas_respiratorios}")
print(f"Dolor en el pecho: {tiene_dolor_pecho}")
print(f"Toma medicamentos: {toma_medicamentos}")
print()
print("🔍 EVALUACIÓN MÉDICA:")
print("=" * 25)
# Evaluación de signos vitales
signos_normales = True
alertas = []
# Evaluar temperatura
if temperatura >= 38.0:
if temperatura >= 39.5:
print("🚨 FIEBRE ALTA - Requiere atención inmediata")
signos_normales = False
alertas.append("Fiebre alta")
else:
print("⚠️ Fiebre moderada - Monitorear")
alertas.append("Fiebre moderada")
elif temperatura <= 35.0:
print("🚨 HIPOTERMIA - Requiere atención")
signos_normales = False
alertas.append("Hipotermia")
else:
print("✅ Temperatura normal")
# Evaluar presión arterial
if presion_sistolica >= 140 or presion_diastolica >= 90:
if presion_sistolica >= 160 or presion_diastolica >= 100:
print("🚨 HIPERTENSIÓN SEVERA - Atención urgente")
signos_normales = False
alertas.append("Hipertensión severa")
else:
print("⚠️ Hipertensión leve - Monitorear")
alertas.append("Hipertensión leve")
elif presion_sistolica <= 90 or presion_diastolica <= 60:
print("⚠️ Presión baja - Monitorear")
alertas.append("Hipotensión")
else:
print("✅ Presión arterial normal")
# Evaluar frecuencia cardíaca
if frecuencia_cardiaca >= 100:
if frecuencia_cardiaca >= 120:
print("🚨 TAQUICARDIA SEVERA - Atención urgente")
signos_normales = False
alertas.append("Taquicardia severa")
else:
print("⚠️ Taquicardia leve - Monitorear")
alertas.append("Taquicardia leve")
elif frecuencia_cardiaca <= 50:
print("⚠️ Bradicardia - Monitorear")
alertas.append("Bradicardia")
else:
print("✅ Frecuencia cardíaca normal")
# Evaluar síntomas adicionales
if tiene_dolor_pecho:
print("🚨 DOLOR EN EL PECHO - Evaluación cardiológica urgente")
signos_normales = False
alertas.append("Dolor torácico")
if tiene_sintomas_respiratorios:
if temperatura >= 38.0:
print("⚠️ Síntomas respiratorios con fiebre - Posible infección")
alertas.append("Síntomas respiratorios con fiebre")
else:
print("ℹ️ Síntomas respiratorios - Evaluación necesaria")
alertas.append("Síntomas respiratorios")
print()
print("🎯 EVALUACIÓN FINAL:")
print("=" * 20)
# Determinar nivel de prioridad
if not signos_normales or tiene_dolor_pecho:
if (temperatura >= 39.5 or presion_sistolica >= 160 or
presion_diastolica >= 100 or frecuencia_cardiaca >= 120 or tiene_dolor_pecho):
prioridad = "EMERGENCIA"
color = "🔴"
else:
prioridad = "URGENTE"
color = "🟡"
elif len(alertas) > 0:
prioridad = "PRIORITARIO"
color = "🟠"
else:
prioridad = "NORMAL"
color = "🟢"
print(f"{color} NIVEL DE PRIORIDAD: {prioridad}")
print()
# Recomendaciones específicas
if prioridad == "EMERGENCIA":
print("🚨 ACCIÓN INMEDIATA REQUERIDA:")
print(" • Atención médica urgente")
print(" • Considerar llamar ambulancia")
print(" • No esperar - ir a emergencias")
elif prioridad == "URGENTE":
print("⚠️ ATENCIÓN MÉDICA NECESARIA:")
print(" • Consultar médico hoy mismo")
print(" • Monitorear signos vitales")
print(" • Tener medicamentos a mano")
elif prioridad == "PRIORITARIO":
print("📋 SEGUIMIENTO RECOMENDADO:")
print(" • Agendar cita médica pronto")
print(" • Monitorear síntomas")
print(" • Mantener medicación actual")
else:
print("✅ ESTADO NORMAL:")
print(" • Continuar con cuidados habituales")
print(" • Chequeo médico de rutina")
# Consideraciones especiales por edad
if edad >= 65:
print()
print("👴 CONSIDERACIONES POR EDAD:")
print(" • Paciente de riesgo por edad avanzada")
print(" • Monitoreo más frecuente recomendado")
if toma_medicamentos:
print(" • Revisar interacciones medicamentosas")
# Resumen de alertas
if alertas:
print()
print("📋 RESUMEN DE ALERTAS:")
for i, alerta in enumerate(alertas, 1):
print(f" {i}. {alerta}")
print()
print("⚕️ Evaluación completada")
print("📞 En caso de emergencia, contactar servicios médicos")
¡Ahora tienes el poder de hacer que tu programa tome decisiones inteligentes! En el próximo capítulo, aprenderás a automatizar tareas repetitivas con bucles.
🧭 Navegación:
- Anterior: Control de Flujo – Condicionales
- Siguiente: Control de Flujo – Bucles
Contenido de este capítulo:
- Control de Flujo – Condicionales
- Condicionales (página actual)
Control de Flujo – Bucles
🧭 Navegación:
- Anterior: Control de Flujo – Condicionales
- Siguiente: Estructuras de Datos
¡Bienvenido al departamento de automatización de tu almacén! Ahora que tu gerente inteligente sabe tomar decisiones, es momento de conocer a los robots que pueden repetir tareas automáticamente sin cansarse nunca.
Los bucles son como robots especialistas en tu almacén que pueden realizar tareas repetitivas de forma eficiente y precisa.
Los robots trabajadores de tu almacén 🤖
Imagínate que contratas diferentes tipos de robots para tu almacén:
- Robot For - Especialista en procesar listas de elementos uno por uno
- Robot While - Persistente que trabaja mientras una condición sea verdadera
- Supervisores - Que pueden dar órdenes especiales como
breakycontinue
# Los robots en acción
productos = ["manzanas", "naranjas", "plátanos"]
# Robot For procesando la lista
for producto in productos:
print(f"Robot For: Procesando {producto}")
# Robot While trabajando con contador
contador = 0
while contador < 3:
print(f"Robot While: Trabajo número {contador + 1}")
contador += 1
¿Por qué necesitamos bucles?
Los bucles son fundamentales para la automatización porque:
- Eliminan código repetitivo - No necesitas escribir la misma operación múltiples veces
- Procesan grandes cantidades de datos - Pueden manejar listas de miles de elementos
- Automatizan tareas - Realizan trabajos que serían imposibles manualmente
- Hacen el código escalable - El mismo código funciona con 10 o 10,000 elementos
Mi perspectiva personal: Siempre visualizo los bucles como una cinta transportadora que va pasando elementos uno a uno frente a un trabajador. Cada elemento se detiene brevemente para ser procesado y luego continúa su camino. Esta imagen mental me ayuda a entender cómo Python maneja cada elemento de una secuencia.
Contenido de este capítulo
En este capítulo aprenderás sobre:
-
Bucles For - El robot especialista que procesa listas
- Iteración sobre secuencias
- Función range()
- Enumerate y zip
-
Bucles While - El robot persistente que trabaja mientras una condición sea verdadera
- Bucles basados en condiciones
- Contadores y acumuladores
- Evitar bucles infinitos
-
Control de Bucles - Comandos especiales para tus robots
- Break para detener bucles
- Continue para saltar iteraciones
- Else en bucles
-
Patrones Comunes - Recetas probadas para problemas frecuentes
- Acumuladores y contadores
- Búsqueda y filtrado
- Transformación de datos
Analogía del almacén
En tu almacén automatizado:
- Los bucles for son como robots especialistas que procesan listas de elementos
- Los bucles while son como robots persistentes que trabajan hasta cumplir un objetivo
- Los comandos break/continue son como instrucciones especiales para los robots
Mapa conceptual
BUCLES (Repetición automatizada)
|
|-- for (para cada elemento)
| |-- Iteración sobre secuencias
| |-- range(), enumerate(), zip()
| |-- Procesa elementos conocidos
|
|-- while (mientras)
| |-- Condición de continuación
| |-- Contadores y acumuladores
| |-- Trabajo hasta completar objetivo
|
|-- Control de bucles
|-- break (romper/salir)
|-- continue (saltar/siguiente)
|-- else (cuando termine normalmente)
¡Comencemos a automatizar tareas con el poder de la repetición!
🧭 Navegación:
- Anterior: Control de Flujo – Condicionales
- Siguiente: Estructuras de Datos
Capítulos de esta sección:
- Introducción a Bucles (página actual)
- Bucles For
- Bucles While
- Control de Bucles
- Patrones Comunes
Bucles For: El Robot Especialista
🧭 Navegación:
- Anterior: Control Flow – Loops
- Siguiente: Bucles While
¡Bienvenido al departamento de automatización de tu almacén! Ahora que tu gerente inteligente sabe tomar decisiones, es momento de conocer a los robots que pueden repetir tareas automáticamente sin cansarse nunca.
El bucle for es como un robot especialista en tu almacén que puede procesar listas de elementos uno por uno, sin errores y sin quejarse.
El robot especialista de tu almacén 🤖
Imagínate que contratas a un robot especialista para tu almacén que puede:
- Procesar listas de elementos uno por uno
- Trabajar con secuencias de cualquier tipo
- Realizar la misma tarea para cada elemento
- Llevar la cuenta de los elementos procesados
- Transformar datos de forma sistemática
# El robot especialista en acción
productos = ["manzanas", "naranjas", "plátanos", "uvas"]
# El robot procesa cada producto
for producto in productos:
print(f"Procesando: {producto}")
print(f"✅ {producto} agregado al inventario")
print("---")
Este robot usa la palabra mágica for para saber exactamente qué elementos procesar y en qué orden.
🔍 Mi perspectiva personal: Siempre visualizo los bucles for como una cinta transportadora que va pasando elementos uno a uno frente a un trabajador. Cada elemento se detiene brevemente para ser procesado y luego continúa su camino. Esta imagen mental me ayuda a entender cómo Python maneja cada elemento de una secuencia.
¿Por qué necesitamos bucles for?
Los bucles for son fundamentales para la automatización porque eliminan la necesidad de escribir código repetitivo. Compara estas dos formas de hacer lo mismo:
Sin bucles (tedioso y propenso a errores):
# Procesar 5 productos manualmente
print(f"Procesando producto 1")
print(f"Procesando producto 2")
print(f"Procesando producto 3")
print(f"Procesando producto 4")
print(f"Procesando producto 5")
Con bucles (elegante y escalable):
# Procesar cualquier cantidad de productos automáticamente
for i in range(1, 6):
print(f"Procesando producto {i}")
La diferencia se vuelve aún más dramática cuando necesitas procesar decenas, cientos o miles de elementos.
Sintaxis básica del bucle for
La estructura básica de un bucle for en Python es:
for elemento in secuencia:
# Código que se ejecuta para cada elemento
procesar(elemento)
Donde:
elementoes una variable que tomará el valor de cada elemento de la secuenciasecuenciaes cualquier objeto iterable (lista, tupla, string, etc.)- El código indentado se ejecutará una vez para cada elemento
Iterando sobre diferentes tipos de secuencias
Ejemplo con lista de productos:
# ================================
# PROCESADOR DE INVENTARIO
# ================================
productos = ["laptop", "mouse", "teclado", "monitor", "audífonos"]
precios = [15000, 500, 800, 8000, 1200]
print("🏪 PROCESADOR DE INVENTARIO")
print("=" * 30)
# El robot procesa cada producto
for producto in productos:
print(f"📦 Procesando: {producto}")
print(f" ✅ Verificado en almacén")
print(f" 📊 Actualizado en sistema")
print()
print("🎯 Procesamiento completado")
print(f"Total de productos procesados: {len(productos)}")
Ejemplo con cadenas de texto:
# ================================
# ANALIZADOR DE TEXTO
# ================================
mensaje = "Python"
print("🔤 ANALIZADOR DE TEXTO")
print("=" * 25)
print(f"Analizando texto: '{mensaje}'")
print()
# El robot procesa cada carácter
for caracter in mensaje:
print(f"Carácter: '{caracter}'")
# Análisis del carácter
if caracter.isupper():
print(" 📏 Tipo: Mayúscula")
elif caracter.islower():
print(" 📏 Tipo: Minúscula")
elif caracter.isdigit():
print(" 📏 Tipo: Dígito")
else:
print(" 📏 Tipo: Especial")
# Código ASCII
print(f" 🔢 Código ASCII: {ord(caracter)}")
print()
print(f"✅ Análisis completado: {len(mensaje)} caracteres procesados")
Ejemplo con diccionarios:
# ================================
# GESTOR DE CONFIGURACIÓN
# ================================
configuracion = {
"tema": "oscuro",
"fuente": "Roboto",
"tamaño": 14,
"notificaciones": True,
"idioma": "español"
}
print("⚙️ GESTOR DE CONFIGURACIÓN")
print("=" * 30)
# Iterar sobre claves
print("📋 CLAVES DE CONFIGURACIÓN:")
for clave in configuracion.keys():
print(f" • {clave}")
print()
# Iterar sobre valores
print("📊 VALORES DE CONFIGURACIÓN:")
for valor in configuracion.values():
print(f" • {valor}")
print()
# Iterar sobre pares clave-valor
print("🔧 CONFIGURACIÓN COMPLETA:")
for clave, valor in configuracion.items():
print(f" • {clave}: {valor}")
La función range(): Generando secuencias numéricas
La función range() es una herramienta poderosa que genera secuencias numéricas automáticamente:
Sintaxis de range():
range(inicio, fin, paso)
inicio: Valor inicial (incluido) - por defecto es 0fin: Valor final (excluido)paso: Incremento entre valores - por defecto es 1
Ejemplos con range():
# ================================
# GENERADOR DE CÓDIGOS DE BARRAS
# ================================
print("🏷️ GENERADOR DE CÓDIGOS DE BARRAS")
print("=" * 35)
# Generar 10 códigos de barras (1-10)
for numero in range(1, 11):
codigo_barras = f"PROD-{numero:04d}" # Formato con ceros: PROD-0001
print(f"Código generado: {codigo_barras}")
print()
print("✅ Generación de códigos completada")
Diferentes formas de usar range():
# ================================
# EJEMPLOS DE RANGE()
# ================================
print("🔢 EJEMPLOS DE RANGE()")
print("=" * 25)
# range con un solo argumento (fin)
print("📊 range(5):")
for i in range(5): # 0, 1, 2, 3, 4
print(f" • Valor: {i}")
print()
# range con inicio y fin
print("📊 range(5, 10):")
for i in range(5, 10): # 5, 6, 7, 8, 9
print(f" • Valor: {i}")
print()
# range con inicio, fin y paso
print("📊 range(0, 20, 5):")
for i in range(0, 20, 5): # 0, 5, 10, 15
print(f" • Valor: {i}")
print()
# range con paso negativo (cuenta regresiva)
print("📊 range(10, 0, -2):")
for i in range(10, 0, -2): # 10, 8, 6, 4, 2
print(f" • Valor: {i}")
print()
print("✅ Ejemplos completados")
Funciones útiles para bucles for
enumerate(): Obtener índice y valor
La función enumerate() te permite obtener tanto el índice como el valor de cada elemento:
# ================================
# REPORTE DE VENTAS DIARIAS
# ================================
ventas_semana = [1200, 1500, 980, 1800, 2100, 2500, 1900]
dias_semana = ["Lunes", "Martes", "Miércoles", "Jueves", "Viernes", "Sábado", "Domingo"]
print("📊 REPORTE DE VENTAS SEMANALES")
print("=" * 35)
# El robot procesa cada día con su posición
for indice, venta in enumerate(ventas_semana):
dia = dias_semana[indice]
print(f"📅 {dia}: ${venta:,}")
# Análisis automático
if venta > 2000:
print(" 🎉 ¡Excelente día de ventas!")
elif venta > 1500:
print(" 👍 Buen día de ventas")
elif venta > 1000:
print(" 📈 Día promedio")
else:
print(" ⚠️ Día por debajo del promedio")
print()
# Estadísticas automáticas
total_ventas = sum(ventas_semana)
promedio_diario = total_ventas / len(ventas_semana)
mejor_dia = max(ventas_semana)
peor_dia = min(ventas_semana)
print("📈 ESTADÍSTICAS SEMANALES:")
print(f"Total de ventas: ${total_ventas:,}")
print(f"Promedio diario: ${promedio_diario:,.2f}")
print(f"Mejor día: ${mejor_dia:,}")
print(f"Peor día: ${peor_dia:,}")
zip(): Combinar múltiples secuencias
La función zip() te permite iterar sobre múltiples secuencias al mismo tiempo:
# ================================
# COMBINADOR DE DATOS
# ================================
nombres = ["Ana", "Carlos", "Elena", "David"]
edades = [28, 35, 42, 31]
ciudades = ["Madrid", "Barcelona", "Sevilla", "Valencia"]
print("👥 COMBINADOR DE DATOS")
print("=" * 25)
# El robot procesa elementos de múltiples listas simultáneamente
for nombre, edad, ciudad in zip(nombres, edades, ciudades):
print(f"👤 {nombre}")
print(f" 🎂 Edad: {edad} años")
print(f" 🏙️ Ciudad: {ciudad}")
print()
print("✅ Procesamiento completado")
Comprensión de listas: Bucles for en una línea
Las comprensiones de listas son una forma elegante y concisa de crear listas usando bucles for en una sola línea:
Sintaxis básica:
nueva_lista = [expresion for elemento in secuencia]
Ejemplos de comprensión de listas:
# ================================
# TRANSFORMADOR DE DATOS
# ================================
numeros = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print("🔄 TRANSFORMADOR DE DATOS")
print("=" * 30)
# Forma tradicional con bucle for
cuadrados_tradicional = []
for numero in numeros:
cuadrados_tradicional.append(numero ** 2)
print("📊 Cuadrados (forma tradicional):")
print(f" {cuadrados_tradicional}")
# Forma moderna con comprensión de listas
cuadrados_comprension = [numero ** 2 for numero in numeros]
print("📊 Cuadrados (comprensión de listas):")
print(f" {cuadrados_comprension}")
# Comprensión con condición
pares = [numero for numero in numeros if numero % 2 == 0]
print("📊 Números pares:")
print(f" {pares}")
# Comprensión con transformación y condición
pares_cuadrados = [numero ** 2 for numero in numeros if numero % 2 == 0]
print("📊 Cuadrados de números pares:")
print(f" {pares_cuadrados}")
# Comprensión con strings
nombres = ["Ana", "Carlos", "Elena", "David"]
longitudes = [len(nombre) for nombre in nombres]
print("📊 Longitud de nombres:")
print(f" Nombres: {nombres}")
print(f" Longitudes: {longitudes}")
print("✅ Transformaciones completadas")
Bucles for anidados: Robots trabajando en equipo
Puedes tener bucles dentro de otros bucles, como robots trabajando en diferentes niveles:
# ================================
# ORGANIZADOR DE ALMACÉN POR SECCIONES
# ================================
almacen = {
"Electrónicos": ["laptop", "mouse", "teclado"],
"Ropa": ["camisa", "pantalón", "zapatos"],
"Hogar": ["mesa", "silla", "lámpara"]
}
print("🏪 ORGANIZADOR DE ALMACÉN")
print("=" * 30)
# Robot principal recorre secciones
for seccion, productos in almacen.items():
print(f"📂 SECCIÓN: {seccion}")
print("-" * 20)
# Robot secundario organiza productos en cada sección
for indice, producto in enumerate(productos, 1):
print(f" {indice}. 📦 {producto}")
print(f" ✅ Ubicado en {seccion}")
print(f" 📊 Total en {seccion}: {len(productos)} productos")
print()
print("🎯 Organización completada")
Generando patrones con bucles anidados:
# ================================
# GENERADOR DE PATRONES
# ================================
print("🎨 GENERADOR DE PATRONES")
print("=" * 25)
# Patrón de triángulo
print("📐 Patrón de triángulo:")
for i in range(1, 6):
print("*" * i)
print()
# Patrón de cuadrado
print("🔲 Patrón de cuadrado:")
for i in range(5):
print("* " * 5)
print()
# Patrón de pirámide
print("🔺 Patrón de pirámide:")
for i in range(1, 6):
espacios = " " * (5 - i)
estrellas = "*" * (2 * i - 1)
print(f"{espacios}{estrellas}")
print()
# Patrón de tablero de ajedrez
print("🏁 Patrón de tablero de ajedrez:")
for i in range(4):
print("⬜⬛" * 4)
print("⬛⬜" * 4)
print()
print("✅ Generación de patrones completada")
Ejemplo práctico completo: Analizador de datos de ventas
# ================================
# ANALIZADOR DE DATOS DE VENTAS
# ================================
# Datos de ventas por producto y región
ventas = [
{"producto": "Laptop", "region": "Norte", "unidades": 50, "precio": 1200},
{"producto": "Laptop", "region": "Sur", "unidades": 35, "precio": 1200},
{"producto": "Tablet", "region": "Norte", "unidades": 80, "precio": 300},
{"producto": "Tablet", "region": "Sur", "unidades": 68, "precio": 300},
{"producto": "Móvil", "region": "Norte", "unidades": 100, "precio": 800},
{"producto": "Móvil", "region": "Sur", "unidades": 120, "precio": 800},
{"producto": "Auriculares", "region": "Norte", "unidades": 200, "precio": 100},
{"producto": "Auriculares", "region": "Sur", "unidades": 220, "precio": 100},
]
print("📊 ANALIZADOR DE DATOS DE VENTAS")
print("=" * 40)
# 1. Calcular ventas totales
total_unidades = 0
total_ingresos = 0
for venta in ventas:
unidades = venta["unidades"]
ingreso = unidades * venta["precio"]
total_unidades += unidades
total_ingresos += ingreso
print("📈 RESUMEN GENERAL:")
print(f"Total de unidades vendidas: {total_unidades:,}")
print(f"Total de ingresos: ${total_ingresos:,}")
print()
# 2. Ventas por producto
print("📦 VENTAS POR PRODUCTO:")
productos = {}
for venta in ventas:
producto = venta["producto"]
unidades = venta["unidades"]
ingreso = unidades * venta["precio"]
if producto in productos:
productos[producto]["unidades"] += unidades
productos[producto]["ingresos"] += ingreso
else:
productos[producto] = {
"unidades": unidades,
"ingresos": ingreso
}
# Ordenar productos por ingresos (de mayor a menor)
productos_ordenados = sorted(
productos.items(),
key=lambda x: x[1]["ingresos"],
reverse=True
)
for producto, datos in productos_ordenados:
print(f"🏷️ {producto}:")
print(f" Unidades: {datos['unidades']:,}")
print(f" Ingresos: ${datos['ingresos']:,}")
print(f" % del total: {(datos['ingresos'] / total_ingresos) * 100:.1f}%")
print()
# 3. Ventas por región
print("🗺️ VENTAS POR REGIÓN:")
regiones = {}
for venta in ventas:
region = venta["region"]
unidades = venta["unidades"]
ingreso = unidades * venta["precio"]
if region in regiones:
regiones[region]["unidades"] += unidades
regiones[region]["ingresos"] += ingreso
else:
regiones[region] = {
"unidades": unidades,
"ingresos": ingreso
}
for region, datos in regiones.items():
print(f"📍 {region}:")
print(f" Unidades: {datos['unidades']:,}")
print(f" Ingresos: ${datos['ingresos']:,}")
print(f" % del total: {(datos['ingresos'] / total_ingresos) * 100:.1f}%")
print()
# 4. Producto más vendido por región
print("🏆 PRODUCTO MÁS VENDIDO POR REGIÓN:")
productos_por_region = {}
for venta in ventas:
region = venta["region"]
producto = venta["producto"]
unidades = venta["unidades"]
if region not in productos_por_region:
productos_por_region[region] = {}
if producto in productos_por_region[region]:
productos_por_region[region][producto] += unidades
else:
productos_por_region[region][producto] = unidades
for region, productos in productos_por_region.items():
# Encontrar el producto más vendido
producto_mas_vendido = max(productos.items(), key=lambda x: x[1])
print(f"📍 {region}:")
print(f" Producto estrella: {producto_mas_vendido[0]}")
print(f" Unidades vendidas: {producto_mas_vendido[1]:,}")
print()
print("✅ Análisis completado")
Buenas prácticas para bucles for
1. Usa nombres descriptivos para las variables de iteración:
# ❌ CONFUSO
for x in data:
process(x)
# ✅ CLARO
for producto in inventario:
procesar_producto(producto)
2. Evita modificar la colección durante la iteración:
# ❌ PELIGROSO
for elemento in lista:
if condicion(elemento):
lista.remove(elemento) # Puede causar comportamiento inesperado
# ✅ SEGURO
lista = [elemento for elemento in lista if not condicion(elemento)]
3. Usa enumerate() cuando necesites el índice:
# ❌ MENOS PYTHÓNICO
for i in range(len(lista)):
elemento = lista[i]
print(f"{i}: {elemento}")
# ✅ MÁS PYTHÓNICO
for i, elemento in enumerate(lista):
print(f"{i}: {elemento}")
4. Prefiere comprensiones de listas para transformaciones simples:
# ❌ MÁS VERBOSO
resultado = []
for x in numeros:
resultado.append(x * 2)
# ✅ MÁS CONCISO
resultado = [x * 2 for x in numeros]
Comprueba tu comprensión 🧠
-
¿Qué imprimirá el siguiente código?
for i in range(5): print(i, end=" ") -
¿Cuál es la diferencia entre
range(5)yrange(1, 6)? -
Escribe una comprensión de lista que genere los cuadrados de los números impares del 1 al 10.
-
¿Qué hace la función
enumerate()y por qué es útil?
Soluciones
-
El código imprimirá:
0 1 2 3 4Explicación:
range(5)genera los números del 0 al 4 (5 números en total). El parámetroend=" "en la funciónprint()hace que los números se impriman en la misma línea separados por espacios en lugar de saltos de línea. -
Diferencia entre
range(5)yrange(1, 6):range(5)genera los números: 0, 1, 2, 3, 4 (comienza en 0 por defecto)range(1, 6)genera los números: 1, 2, 3, 4, 5 (comienza en 1 y termina antes del 6) Ambos generan 5 números, pero con diferentes valores iniciales y finales.
-
Comprensión de lista para los cuadrados de números impares del 1 al 10:
cuadrados_impares = [x**2 for x in range(1, 11) if x % 2 != 0] # Resultado: [1, 9, 25, 49, 81] -
La función
enumerate()devuelve pares de (índice, valor) para cada elemento de una secuencia. Es útil cuando necesitas tanto el índice como el valor durante la iteración, evitando tener que mantener un contador separado.Ejemplo:
frutas = ["manzana", "banana", "cereza"] for i, fruta in enumerate(frutas): print(f"{i}: {fruta}")Salida:
0: manzana 1: banana 2: cereza
Ejercicio práctico: Generador de informes
# ================================
# GENERADOR DE INFORMES DE ESTUDIANTES
# ================================
estudiantes = [
{"nombre": "Ana García", "calificaciones": [85, 90, 78, 92, 88]},
{"nombre": "Carlos López", "calificaciones": [75, 82, 79, 65, 68]},
{"nombre": "Elena Martínez", "calificaciones": [92, 97, 94, 90, 95]},
{"nombre": "David Rodríguez", "calificaciones": [60, 55, 68, 72, 65]},
{"nombre": "Sofía Pérez", "calificaciones": [88, 84, 90, 86, 82]}
]
print("📝 GENERADOR DE INFORMES DE ESTUDIANTES")
print("=" * 45)
# Procesar cada estudiante
for i, estudiante in enumerate(estudiantes, 1):
nombre = estudiante["nombre"]
calificaciones = estudiante["calificaciones"]
# Calcular estadísticas
promedio = sum(calificaciones) / len(calificaciones)
calificacion_maxima = max(calificaciones)
calificacion_minima = min(calificaciones)
# Determinar estado
if promedio >= 90:
estado = "Excelente"
emoji = "🏆"
elif promedio >= 80:
estado = "Bueno"
emoji = "👍"
elif promedio >= 70:
estado = "Satisfactorio"
emoji = "😊"
elif promedio >= 60:
estado = "Suficiente"
emoji = "😐"
else:
estado = "Insuficiente"
emoji = "⚠️"
# Generar informe
print(f"INFORME #{i}: {nombre}")
print("-" * 30)
print(f"Calificaciones: {calificaciones}")
print(f"Promedio: {promedio:.1f}")
print(f"Calificación más alta: {calificacion_maxima}")
print(f"Calificación más baja: {calificacion_minima}")
print(f"Estado: {emoji} {estado}")
# Mostrar calificaciones individuales
print("\nDesglose de calificaciones:")
materias = ["Matemáticas", "Ciencias", "Historia", "Literatura", "Inglés"]
for materia, calificacion in zip(materias, calificaciones):
if calificacion >= 90:
nivel = "Excelente"
elif calificacion >= 80:
nivel = "Bueno"
elif calificacion >= 70:
nivel = "Satisfactorio"
elif calificacion >= 60:
nivel = "Suficiente"
else:
nivel = "Insuficiente"
print(f" • {materia}: {calificacion} - {nivel}")
print("\n" + "=" * 45 + "\n")
print("✅ Generación de informes completada")
¡Ahora tienes el poder de automatizar tareas repetitivas con bucles for! En el próximo capítulo, aprenderás sobre los bucles while, que te permitirán repetir tareas mientras una condición sea verdadera.
🧭 Navegación:
- Anterior: Control Flow – Loops
- Siguiente: Bucles While
Capítulos de esta sección:
- Control de Flujo – Bucles
- Bucles For (página actual)
- Bucles While
- Control de Bucles
- Patrones Comunes
Bucles While: El Robot Persistente
🧭 Navegación:
- Anterior: Bucles For
- Siguiente: Control de Bucles
¡Bienvenido al centro de monitoreo de tu almacén! Después de conocer al robot especialista (bucle for), es momento de presentarte al robot persistente: el bucle while.
El bucle while es como un robot vigilante en tu almacén que sigue trabajando mientras una condición sea verdadera, sin importar cuánto tiempo tome.
El robot persistente de tu almacén 🤖
Imagínate que contratas a un robot persistente para tu almacén que puede:
- Trabajar indefinidamente mientras una condición sea verdadera
- Monitorear sistemas hasta que ocurra un evento específico
- Procesar datos hasta que se cumplan ciertos criterios
- Esperar hasta que algo importante suceda
- Repetir tareas un número variable de veces
# El robot persistente en acción
inventario = 100
umbral_minimo = 20
# El robot monitorea el inventario
while inventario > umbral_minimo:
print(f"Inventario actual: {inventario} unidades")
print("Vendiendo 10 unidades...")
inventario -= 10
print("---")
print(f"¡Alerta! Inventario bajo: {inventario} unidades")
print("Solicitando reabastecimiento...")
Este robot usa la palabra mágica while para saber cuándo debe seguir trabajando y cuándo debe detenerse.
🔍 Mi perspectiva personal: Siempre pienso en los bucles while como un guardia de seguridad que vigila constantemente una puerta. No sabe cuánto tiempo tendrá que vigilar, pero sabe exactamente qué condición debe cumplirse para terminar su turno. Esta imagen me ayuda a recordar que siempre debe haber una condición clara de salida.
¿Cuándo usar while en lugar de for?
Los bucles for y while tienen propósitos diferentes:
- Bucle for: Cuando sabes exactamente cuántas iteraciones necesitas o quieres procesar todos los elementos de una secuencia.
- Bucle while: Cuando no sabes cuántas iteraciones necesitas y dependes de una condición que puede cambiar durante la ejecución.
Ejemplos de situaciones ideales para while:
- Esperar a que el usuario ingrese una respuesta válida
- Procesar datos hasta encontrar un valor específico
- Ejecutar un juego hasta que el jugador pierda
- Monitorear un sistema hasta que ocurra un evento
- Implementar algoritmos que requieren un número variable de pasos
Sintaxis básica del bucle while
La estructura básica de un bucle while en Python es:
while condicion:
# Código que se ejecuta mientras la condición sea True
hacer_algo()
# IMPORTANTE: Asegúrate de que la condición cambie eventualmente
Donde:
condiciones una expresión que se evalúa comoTrueoFalse- El código indentado se ejecuta repetidamente mientras la condición sea
True - Es crucial que algo dentro del bucle eventualmente cambie la condición a
False, o tendrás un bucle infinito
Ejemplos básicos de bucles while
Contador simple:
# ================================
# CONTADOR DE INVENTARIO
# ================================
print("📦 CONTADOR DE INVENTARIO")
print("=" * 25)
contador = 1
total_productos = 5
# El robot cuenta mientras haya productos
while contador <= total_productos:
print(f"Contando producto #{contador}")
print(f" 📋 Registrado en sistema")
contador += 1 # CRUCIAL: incrementar el contador
print()
print(f"✅ Conteo completado: {total_productos} productos")
Procesamiento hasta una condición:
# ================================
# PROCESADOR DE PEDIDOS
# ================================
print("🛒 PROCESADOR DE PEDIDOS")
print("=" * 25)
pedidos_pendientes = 8
capacidad_diaria = 3
dia = 1
print(f"Pedidos pendientes iniciales: {pedidos_pendientes}")
print(f"Capacidad de procesamiento diaria: {capacidad_diaria}")
print()
# Procesar pedidos hasta que no queden pendientes
while pedidos_pendientes > 0:
# Determinar cuántos pedidos procesar hoy
pedidos_hoy = min(capacidad_diaria, pedidos_pendientes)
pedidos_pendientes -= pedidos_hoy
print(f"Día {dia}:")
print(f" 📦 Pedidos procesados: {pedidos_hoy}")
print(f" 📋 Pedidos pendientes: {pedidos_pendientes}")
print()
dia += 1
print(f"✅ Todos los pedidos han sido procesados en {dia-1} días")
Bucles while con entrada del usuario
Los bucles while son perfectos para interactuar con el usuario hasta que proporcione una entrada válida:
# ================================
# SISTEMA DE AUTENTICACIÓN
# ================================
contraseña_correcta = "python123"
intentos_maximos = 3
intentos_actuales = 0
print("🔐 SISTEMA DE AUTENTICACIÓN")
print("=" * 30)
# En un programa real, usaríamos input() para obtener la contraseña del usuario
# Aquí simularemos diferentes entradas para mostrar el funcionamiento
contraseñas_simuladas = ["clave123", "python", "python123"]
# El robot sigue pidiendo contraseña hasta que sea correcta o se agoten los intentos
while intentos_actuales < intentos_maximos:
# Simular entrada del usuario
contraseña_ingresada = contraseñas_simuladas[intentos_actuales]
intentos_actuales += 1
print(f"Intento #{intentos_actuales}")
print(f"Contraseña ingresada: {contraseña_ingresada}")
if contraseña_ingresada == contraseña_correcta:
print("✅ Acceso concedido")
print("🏠 Bienvenido al sistema")
break # Salir del bucle
else:
intentos_restantes = intentos_maximos - intentos_actuales
if intentos_restantes > 0:
print(f"❌ Contraseña incorrecta")
print(f"Te quedan {intentos_restantes} intentos")
else:
print("🚫 Acceso denegado - Demasiados intentos fallidos")
print("🔒 Cuenta bloqueada temporalmente")
print("🔚 Proceso de autenticación terminado")
Bucles while con condiciones complejas
Puedes usar operadores lógicos para crear condiciones más complejas:
# ================================
# MONITOR DE RECURSOS DEL SISTEMA
# ================================
print("📊 MONITOR DE RECURSOS DEL SISTEMA")
print("=" * 35)
# Estado inicial del sistema
cpu_usage = 75
memory_usage = 60
disk_space = 50
is_monitoring = True
minutes = 0
print("Iniciando monitoreo del sistema...")
print("Presione Ctrl+C para detener (simulado con límite de 10 minutos)")
print()
# Monitorear mientras el sistema esté en niveles aceptables y el monitoreo esté activo
while (cpu_usage < 90 and memory_usage < 85 and disk_space < 95) and is_monitoring:
minutes += 1
print(f"Minuto {minutes} - Estado del sistema:")
print(f" CPU: {cpu_usage}%")
print(f" Memoria: {memory_usage}%")
print(f" Disco: {disk_space}%")
# Simular cambios en el sistema
cpu_usage += 2 if minutes % 2 == 0 else -1
memory_usage += 3 if minutes % 3 == 0 else 1
disk_space += 1
# Limitar valores
cpu_usage = min(100, max(0, cpu_usage))
memory_usage = min(100, max(0, memory_usage))
disk_space = min(100, max(0, disk_space))
# Simular detención después de 10 minutos
if minutes >= 10:
is_monitoring = False
print()
# Determinar por qué se detuvo el monitoreo
if not is_monitoring:
print("Monitoreo detenido manualmente")
elif cpu_usage >= 90:
print("⚠️ ¡Alerta! Uso de CPU crítico")
elif memory_usage >= 85:
print("⚠️ ¡Alerta! Uso de memoria crítico")
elif disk_space >= 95:
print("⚠️ ¡Alerta! Espacio en disco crítico")
print("Monitoreo finalizado")
El peligro de los bucles infinitos
Un bucle infinito ocurre cuando la condición del while nunca se vuelve falsa. Esto puede bloquear tu programa:
# ❌ PELIGRO: Bucle infinito
# while True:
# print("¡Esto nunca terminará!")
Para evitar bucles infinitos:
- Asegúrate de que la condición eventualmente se vuelva falsa
- Incluye una cláusula de escape (como
break) - Verifica que las variables en la condición se actualicen dentro del bucle
Ejemplo de bucle infinito controlado:
# ================================
# SIMULADOR DE SERVICIO CONTINUO
# ================================
print("🔄 SIMULADOR DE SERVICIO CONTINUO")
print("=" * 35)
contador = 0
max_iteraciones = 5 # En un servicio real, esto sería infinito
print("Iniciando servicio...")
print("(Limitado a 5 iteraciones para la demostración)")
print()
# Bucle "infinito" controlado
while True:
contador += 1
print(f"Iteración #{contador}")
print(" ✅ Servicio ejecutándose")
# Cláusula de escape para la demostración
if contador >= max_iteraciones:
print(" ⚠️ Límite de demostración alcanzado")
break
print()
print("Servicio detenido")
Bucles while con else
Al igual que los bucles for, los bucles while pueden tener una cláusula else que se ejecuta cuando la condición se vuelve falsa (pero no si el bucle termina con break):
# ================================
# BUSCADOR DE PRODUCTOS
# ================================
print("🔍 BUSCADOR DE PRODUCTOS")
print("=" * 25)
productos = ["laptop", "mouse", "teclado", "monitor", "auriculares"]
producto_buscado = "impresora"
print(f"Buscando: {producto_buscado}")
print(f"En inventario: {productos}")
print()
# Inicializar variables
encontrado = False
indice = 0
# Buscar mientras haya elementos por revisar
while indice < len(productos):
print(f"Revisando posición {indice}: {productos[indice]}")
if productos[indice] == producto_buscado:
encontrado = True
print(f"✅ ¡Producto encontrado en posición {indice}!")
break
indice += 1
else:
# Este bloque se ejecuta si el while termina normalmente (sin break)
print("❌ Producto no encontrado en el inventario")
print("Búsqueda finalizada")
Ejemplo práctico completo: Simulador de cajero automático
# ================================
# SIMULADOR DE CAJERO AUTOMÁTICO
# ================================
print("🏧 SIMULADOR DE CAJERO AUTOMÁTICO")
print("=" * 35)
# Datos de la cuenta
saldo = 1000
pin_correcto = "1234"
intentos_pin = 3
sesion_activa = False
# Función para mostrar el menú
def mostrar_menu():
print("\n=== MENÚ PRINCIPAL ===")
print("1. Consultar saldo")
print("2. Retirar dinero")
print("3. Depositar dinero")
print("4. Salir")
return input("Seleccione una opción (1-4): ")
# Autenticación
print("Bienvenido a su cajero automático")
while intentos_pin > 0 and not sesion_activa:
# En un programa real, usaríamos input() para obtener el PIN
pin_ingresado = "1234" # Simular entrada correcta
if pin_ingresado == pin_correcto:
print("✅ PIN correcto")
sesion_activa = True
else:
intentos_pin -= 1
if intentos_pin > 0:
print(f"❌ PIN incorrecto. Le quedan {intentos_pin} intentos")
else:
print("🚫 Demasiados intentos fallidos. Tarjeta bloqueada")
# Menú principal
if sesion_activa:
print("\n¡Bienvenido a su cuenta!")
opcion = ""
while opcion != "4" and sesion_activa:
opcion = mostrar_menu()
if opcion == "1":
# Consultar saldo
print(f"\n💰 Su saldo actual es: ${saldo}")
elif opcion == "2":
# Retirar dinero
print("\n=== RETIRO DE DINERO ===")
# En un programa real, usaríamos input() para obtener la cantidad
cantidad = 300 # Simular entrada
if cantidad > saldo:
print("❌ Fondos insuficientes")
elif cantidad <= 0:
print("❌ Cantidad inválida")
else:
saldo -= cantidad
print(f"✅ Ha retirado ${cantidad}")
print(f"💰 Nuevo saldo: ${saldo}")
elif opcion == "3":
# Depositar dinero
print("\n=== DEPÓSITO DE DINERO ===")
# En un programa real, usaríamos input() para obtener la cantidad
cantidad = 500 # Simular entrada
if cantidad <= 0:
print("❌ Cantidad inválida")
else:
saldo += cantidad
print(f"✅ Ha depositado ${cantidad}")
print(f"💰 Nuevo saldo: ${saldo}")
elif opcion == "4":
# Salir
print("\n👋 Gracias por usar nuestro cajero automático")
print("Sesión finalizada")
sesion_activa = False
else:
print("\n❌ Opción inválida. Por favor, seleccione una opción válida (1-4)")
print("\n🔚 Programa terminado")
Buenas prácticas para bucles while
1. Asegúrate de que la condición eventualmente se vuelva falsa:
# ❌ PELIGROSO
# contador = 10
# while contador > 0:
# print(contador)
# # Olvidamos decrementar el contador
# ✅ SEGURO
contador = 10
while contador > 0:
print(contador)
contador -= 1 # Aseguramos que la condición eventualmente sea falsa
2. Usa break para salir del bucle en casos especiales:
while True:
respuesta = input("¿Continuar? (s/n): ")
if respuesta.lower() == 'n':
break # Salir del bucle cuando el usuario responda 'n'
3. Evita condiciones demasiado complejas:
# ❌ DIFÍCIL DE LEER
while x > 0 and y < 100 and not z or w == 10:
# Código...
# ✅ MÁS CLARO
condicion1 = x > 0 and y < 100
condicion2 = not z or w == 10
while condicion1 and condicion2:
# Código...
4. Considera usar for cuando conozcas el número de iteraciones:
# ❌ MENOS PYTHÓNICO
i = 0
while i < 10:
print(i)
i += 1
# ✅ MÁS PYTHÓNICO
for i in range(10):
print(i)
Comprueba tu comprensión 🧠
-
¿Cuál es la principal diferencia entre un bucle
fory un buclewhile? -
¿Qué imprimirá el siguiente código?
x = 5 while x > 0: print(x, end=" ") x -= 1 -
¿Qué sucede si la condición de un bucle
whilenunca se vuelve falsa? -
Escribe un bucle
whileque calcule la suma de los números del 1 al 10.
Soluciones
-
La principal diferencia entre un bucle
fory un buclewhilees:- Un bucle
forse utiliza para iterar sobre una secuencia conocida de elementos o un número conocido de veces. - Un bucle
whilese ejecuta mientras una condición sea verdadera, sin importar cuántas iteraciones sean necesarias. En resumen, usamosforcuando sabemos cuántas veces queremos iterar, ywhilecuando no lo sabemos y dependemos de una condición.
- Un bucle
-
El código imprimirá:
5 4 3 2 1Explicación: El bucle comienza con
x = 5y se ejecuta mientrasx > 0. En cada iteración, imprime el valor dexy luego lo decrementa en 1. El bucle se detiene cuandoxllega a 0. -
Si la condición de un bucle
whilenunca se vuelve falsa, se produce un “bucle infinito”. El programa seguirá ejecutando el código dentro del bucle indefinidamente, lo que puede hacer que el programa se bloquee o consuma recursos excesivamente. En entornos de desarrollo, generalmente necesitarás forzar la terminación del programa (por ejemplo, con Ctrl+C). -
Bucle
whilepara calcular la suma de los números del 1 al 10:suma = 0 numero = 1 while numero <= 10: suma += numero numero += 1 print(f"La suma de los números del 1 al 10 es: {suma}") # 55
Ejercicio práctico: Juego de adivinanza
# ================================
# JUEGO DE ADIVINANZA
# ================================
import random
print("🎮 JUEGO DE ADIVINANZA")
print("=" * 25)
# Configuración del juego
numero_secreto = random.randint(1, 100)
intentos_maximos = 7
intentos_realizados = 0
adivinado = False
print("He pensado un número entre 1 y 100.")
print(f"Tienes {intentos_maximos} intentos para adivinarlo.")
print()
# Bucle principal del juego
while intentos_realizados < intentos_maximos and not adivinado:
# En un programa real, usaríamos input() para obtener la respuesta
# Aquí simularemos diferentes respuestas para mostrar el funcionamiento
if intentos_realizados == 0:
intento = 50 # Primera suposición: justo en medio
elif numero_secreto > intento:
intento += max(1, (100 - intento) // 2) # Simular que el jugador va más alto
else:
intento -= max(1, intento // 2) # Simular que el jugador va más bajo
intentos_realizados += 1
print(f"Intento #{intentos_realizados}: {intento}")
# Comprobar la respuesta
if intento == numero_secreto:
adivinado = True
print(f"🎉 ¡Correcto! El número era {numero_secreto}")
print(f"Lo has adivinado en {intentos_realizados} intentos")
elif intento < numero_secreto:
print("📈 Demasiado bajo. Intenta un número más alto.")
else:
print("📉 Demasiado alto. Intenta un número más bajo.")
print()
# Mensaje final
if not adivinado:
print(f"❌ Se acabaron los intentos. El número era {numero_secreto}")
print("Gracias por jugar")
¡Ahora tienes el poder de crear bucles que se ejecutan mientras una condición sea verdadera! En el próximo capítulo, aprenderás técnicas avanzadas para controlar el flujo de tus bucles.
🧭 Navegación:
- Anterior: Bucles For
- Siguiente: Control de Bucles
Capítulos de esta sección:
- Control de Flujo – Bucles
- Bucles For
- Bucles While (página actual)
- Control de Bucles
- Patrones Comunes
Control de Bucles: Comandos Especiales para tus Robots
🧭 Navegación:
- Anterior: Bucles While
- Siguiente: Patrones Comunes
¡Bienvenido al centro de control avanzado de tu almacén! Ahora que conoces a tus robots trabajadores (bucles for y while), es momento de aprender los comandos especiales que te permiten controlar su comportamiento con mayor precisión.
Los comandos de control de bucles son como el control remoto de tus robots, permitiéndote detenerlos, hacer que salten tareas o ejecuten acciones especiales cuando terminan su trabajo.
El control remoto de tus robots 🎮
Imagínate que tienes un control remoto para tus robots con botones especiales:
- Botón BREAK: Detiene completamente al robot y lo saca del bucle
- Botón CONTINUE: Hace que el robot salte a la siguiente iteración
- Botón ELSE: Programa una acción especial para cuando el robot termine su trabajo normalmente
# El control remoto en acción
productos = ["laptop", "mouse", "teclado", "monitor", "impresora"]
producto_agotado = "teclado"
print("🔍 VERIFICACIÓN DE INVENTARIO")
print("=" * 30)
# El robot verifica cada producto
for producto in productos:
print(f"Verificando: {producto}")
# Si encontramos el producto agotado, detenemos la verificación
if producto == producto_agotado:
print(f"❌ ¡{producto} está agotado!")
print("🛑 Deteniendo verificación para hacer un pedido urgente")
break
print(f"✅ {producto} disponible en inventario")
print()
print("Verificación finalizada")
🔍 Mi perspectiva personal: Siempre pienso en
breakycontinuecomo “palancas de emergencia” que deben usarse estratégicamente. Son herramientas poderosas, pero si abusas de ellas, tu código puede volverse difícil de seguir. Usobreakcuando encuentro exactamente lo que estaba buscando y no tiene sentido seguir iterando, ycontinuecuando quiero saltar un caso especial sin anidar más condiciones.
El comando break: Detener el bucle inmediatamente
El comando break detiene la ejecución del bucle y continúa con el código que sigue después del bucle:
Ejemplo con for:
# ================================
# BÚSQUEDA DE PRODUCTO ESPECÍFICO
# ================================
productos = ["laptop", "mouse", "teclado", "tablet", "monitor"]
producto_buscado = "tablet"
print("🔍 BÚSQUEDA DE PRODUCTO")
print("=" * 25)
for i, producto in enumerate(productos):
print(f"Revisando posición {i}: {producto}")
if producto == producto_buscado:
print(f"✅ ¡Producto encontrado: {producto}!")
print(f" Ubicación: Estante {i+1}")
print("🛑 Deteniendo búsqueda")
break # Salir del bucle inmediatamente
print(" ⏭️ Continuando búsqueda...")
print("🔚 Búsqueda terminada")
Ejemplo con while:
# ================================
# SISTEMA DE AUTENTICACIÓN
# ================================
contraseña_correcta = "python123"
intentos_maximos = 3
intentos = 0
print("🔐 SISTEMA DE AUTENTICACIÓN")
print("=" * 30)
# Simular diferentes intentos
contraseñas_simuladas = ["clave123", "python", "python123"]
while intentos < intentos_maximos:
# Simular entrada del usuario
contraseña = contraseñas_simuladas[intentos]
intentos += 1
print(f"Intento #{intentos}: {contraseña}")
if contraseña == contraseña_correcta:
print("✅ Acceso concedido")
print("🏠 Bienvenido al sistema")
break # Salir del bucle si la contraseña es correcta
print("❌ Contraseña incorrecta")
print(f"Intentos restantes: {intentos_maximos - intentos}")
print()
if intentos == intentos_maximos and contraseña != contraseña_correcta:
print("🚫 Demasiados intentos fallidos")
print("🔒 Cuenta bloqueada temporalmente")
print("🔚 Proceso de autenticación terminado")
El comando continue: Saltar a la siguiente iteración
El comando continue salta el resto del código en la iteración actual y pasa a la siguiente iteración:
Ejemplo con for:
# ================================
# PROCESADOR DE PEDIDOS
# ================================
pedidos = [
{"id": 1, "estado": "pendiente", "total": 500},
{"id": 2, "estado": "cancelado", "total": 300},
{"id": 3, "estado": "pendiente", "total": 800},
{"id": 4, "estado": "cancelado", "total": 150},
{"id": 5, "estado": "pendiente", "total": 1200}
]
print("📋 PROCESADOR DE PEDIDOS PENDIENTES")
print("=" * 40)
total_procesado = 0
for pedido in pedidos:
print(f"Revisando pedido #{pedido['id']}")
# Saltar pedidos cancelados
if pedido["estado"] == "cancelado":
print(" ❌ Pedido cancelado - Saltando")
continue # Ir al siguiente pedido
# Este código solo se ejecuta para pedidos no cancelados
print(f" ✅ Procesando pedido por ${pedido['total']}")
total_procesado += pedido["total"]
print(f" 📦 Pedido #{pedido['id']} completado")
print()
print("📊 RESUMEN:")
print(f"Total procesado: ${total_procesado}")
Ejemplo con while:
# ================================
# VALIDADOR DE ENTRADAS
# ================================
print("🔢 VALIDADOR DE ENTRADAS NUMÉRICAS")
print("=" * 35)
# Simular diferentes entradas del usuario
entradas_simuladas = ["abc", "123", "-5", "0", "42"]
indice = 0
# En un programa real, usaríamos input() en un bucle while True
while indice < len(entradas_simuladas):
# Simular entrada del usuario
entrada = entradas_simuladas[indice]
indice += 1
print(f"Procesando entrada: '{entrada}'")
# Validar que sea un número
if not entrada.lstrip('-').isdigit():
print(" ❌ Error: Debe ingresar un número")
print(" ⏭️ Saltando al siguiente intento")
continue
# Convertir a entero
numero = int(entrada)
# Validar que sea positivo
if numero <= 0:
print(" ❌ Error: El número debe ser positivo")
print(" ⏭️ Saltando al siguiente intento")
continue
# Si llegamos aquí, la entrada es válida
print(f" ✅ Entrada válida: {numero}")
print(f" 📊 El cuadrado de {numero} es {numero ** 2}")
print()
print("🔚 Proceso de validación terminado")
La cláusula else en bucles: Acción al completar
Python permite añadir una cláusula else a los bucles for y while. El código en el bloque else se ejecuta cuando el bucle termina normalmente (sin break):
Ejemplo con for:
# ================================
# VERIFICADOR DE CALIDAD
# ================================
productos = ["laptop", "mouse", "teclado", "monitor", "auriculares"]
umbral_calidad = 8
calidades = [9, 8, 7, 9, 9] # Calificaciones de 1 a 10
print("🔍 VERIFICADOR DE CALIDAD")
print("=" * 30)
# Verificar la calidad de cada producto
for i, producto in enumerate(productos):
calidad = calidades[i]
print(f"Verificando {producto}: calidad {calidad}/10")
if calidad < umbral_calidad:
print(f"❌ {producto} no cumple el estándar mínimo de calidad")
print("🛑 Deteniendo verificación - Se requiere revisión")
break
print(f"✅ {producto} aprobado")
print()
else:
# Este bloque se ejecuta si el bucle termina normalmente (sin break)
print("🎉 ¡Todos los productos cumplen con el estándar de calidad!")
print("📦 Lote aprobado para distribución")
print("🔚 Verificación finalizada")
Ejemplo con while:
# ================================
# MONITOR DE TEMPERATURA
# ================================
print("🌡️ MONITOR DE TEMPERATURA")
print("=" * 30)
# Simular lecturas de temperatura
temperaturas = [22, 23, 24, 25, 26]
umbral_alerta = 30
indice = 0
# Monitorear mientras haya lecturas disponibles
while indice < len(temperaturas):
temperatura = temperaturas[indice]
indice += 1
print(f"Lectura #{indice}: {temperatura}°C")
if temperatura >= umbral_alerta:
print(f"⚠️ ¡Alerta! Temperatura por encima del umbral: {temperatura}°C")
print("🛑 Activando sistema de enfriamiento")
break
print("✅ Temperatura normal")
print()
else:
# Este bloque se ejecuta si el bucle termina sin break
print("📊 Monitoreo completo: Todas las temperaturas están dentro del rango normal")
print("✅ No se requieren acciones adicionales")
print("🔚 Monitoreo finalizado")
Combinando break, continue y else
Puedes combinar estos comandos para crear lógicas de control sofisticadas:
# ================================
# SISTEMA DE PROCESAMIENTO DE ARCHIVOS
# ================================
archivos = [
{"nombre": "datos.csv", "tamaño": 1024, "corrupto": False},
{"nombre": "imagen.jpg", "tamaño": 2048, "corrupto": False},
{"nombre": "documento.pdf", "tamaño": 3072, "corrupto": True},
{"nombre": "video.mp4", "tamaño": 4096, "corrupto": False},
{"nombre": "audio.mp3", "tamaño": 5120, "corrupto": False}
]
tamaño_maximo = 4000
total_procesado = 0
print("📁 SISTEMA DE PROCESAMIENTO DE ARCHIVOS")
print("=" * 40)
for archivo in archivos:
nombre = archivo["nombre"]
tamaño = archivo["tamaño"]
corrupto = archivo["corrupto"]
print(f"Procesando: {nombre}")
# Verificar si el archivo está corrupto
if corrupto:
print(f" ❌ Archivo corrupto: {nombre}")
print(" ⚠️ Se requiere intervención manual")
print(" 🛑 Deteniendo procesamiento")
break
# Verificar tamaño del archivo
if tamaño > tamaño_maximo:
print(f" ⚠️ Archivo demasiado grande: {tamaño} KB")
print(" ⏭️ Saltando al siguiente archivo")
continue
# Procesar archivo
print(f" ✅ Procesando archivo: {nombre} ({tamaño} KB)")
total_procesado += tamaño
print(f" 📊 Total procesado: {total_procesado} KB")
print()
else:
print("🎉 ¡Todos los archivos han sido procesados correctamente!")
print(f"📊 Total de datos procesados: {total_procesado} KB")
print("🔚 Procesamiento finalizado")
Bucles anidados y control de flujo
El control de flujo se vuelve especialmente útil en bucles anidados:
# ================================
# BUSCADOR DE PRODUCTOS EN ALMACENES
# ================================
almacenes = [
{"nombre": "Central", "productos": ["laptop", "tablet", "smartphone"]},
{"nombre": "Norte", "productos": ["monitor", "teclado", "mouse"]},
{"nombre": "Sur", "productos": ["impresora", "scanner", "tablet"]}
]
producto_buscado = "tablet"
encontrado = False
print("🔍 BUSCADOR DE PRODUCTOS EN ALMACENES")
print("=" * 40)
print(f"Buscando: {producto_buscado}")
print()
# Buscar en cada almacén
for almacen in almacenes:
nombre_almacen = almacen["nombre"]
productos = almacen["productos"]
print(f"Buscando en Almacén {nombre_almacen}:")
# Buscar en los productos de este almacén
for i, producto in enumerate(productos):
print(f" Revisando producto #{i+1}: {producto}")
if producto == producto_buscado:
print(f" ✅ ¡Producto encontrado en Almacén {nombre_almacen}!")
encontrado = True
break # Salir del bucle interno
print(f" Búsqueda en Almacén {nombre_almacen} completada")
print()
if encontrado:
break # Salir del bucle externo si ya encontramos el producto
if encontrado:
print(f"🎯 {producto_buscado} encontrado. Búsqueda exitosa.")
else:
print(f"❌ {producto_buscado} no encontrado en ningún almacén.")
print("🔚 Búsqueda finalizada")
Patrones avanzados de control de bucles
Patrón: Búsqueda con bandera
# ================================
# BUSCADOR CON BANDERA
# ================================
datos = [10, 25, 3, 8, 42, 15, 7]
objetivo = 42
encontrado = False # Bandera
print("🔍 BUSCADOR CON BANDERA")
print("=" * 25)
print(f"Buscando: {objetivo}")
print(f"En datos: {datos}")
print()
# Buscar el objetivo
for i, valor in enumerate(datos):
print(f"Revisando posición {i}: {valor}")
if valor == objetivo:
encontrado = True # Activar la bandera
posicion = i
break
# Usar la bandera para determinar el resultado
if encontrado:
print(f"✅ Valor {objetivo} encontrado en posición {posicion}")
else:
print(f"❌ Valor {objetivo} no encontrado")
print("🔚 Búsqueda finalizada")
Patrón: Bucle y medio
# ================================
# PATRÓN DE BUCLE Y MEDIO
# ================================
print("🔄 PATRÓN DE BUCLE Y MEDIO")
print("=" * 25)
# Simular entrada de usuario
entradas_simuladas = ["", "0", "negativo", "-5", "10"]
indice = 0
# Bucle externo que se repite hasta obtener una entrada válida
while True:
# Simular entrada del usuario
if indice >= len(entradas_simuladas):
break
entrada = entradas_simuladas[indice]
indice += 1
print(f"Procesando entrada: '{entrada}'")
# Validar que no esté vacía
if not entrada:
print(" ❌ Error: La entrada no puede estar vacía")
continue
# Validar que sea un número
try:
numero = int(entrada)
except ValueError:
print(" ❌ Error: Debe ingresar un número")
continue
# Validar que sea positivo
if numero <= 0:
print(" ❌ Error: El número debe ser positivo")
continue
# Si llegamos aquí, la entrada es válida
print(f" ✅ Entrada válida: {numero}")
break # Salir del bucle con una entrada válida
print("🔚 Proceso de validación terminado")
Buenas prácticas para el control de bucles
1. Usa break con moderación:
# ❌ ABUSO DE BREAK
for item in lista:
if condicion1:
break
if condicion2:
break
if condicion3:
break
# Código...
# ✅ MÁS CLARO
for item in lista:
if condicion1 or condicion2 or condicion3:
break
# Código...
2. Prefiere continue sobre if anidados:
# ❌ MUCHOS IFS ANIDADOS
for item in lista:
if condicion_valida:
if otra_condicion_valida:
if tercera_condicion_valida:
# Código...
# ✅ MÁS PLANO CON CONTINUE
for item in lista:
if not condicion_valida:
continue
if not otra_condicion_valida:
continue
if not tercera_condicion_valida:
continue
# Código...
3. Usa else para casos de éxito:
# Buscar un elemento
for item in lista:
if item == objetivo:
print("Encontrado")
break
else:
print("No encontrado") # Se ejecuta si no se encontró el objetivo
4. Evita bucles anidados profundos:
# ❌ DIFÍCIL DE SEGUIR
for a in lista_a:
for b in lista_b:
for c in lista_c:
for d in lista_d:
# Código...
# ✅ EXTRAER A FUNCIONES
def procesar_listas_c_d(a, b):
for c in lista_c:
for d in lista_d:
# Código...
for a in lista_a:
for b in lista_b:
procesar_listas_c_d(a, b)
Comprueba tu comprensión 🧠
-
¿Cuál es la diferencia entre
breakycontinue? -
¿Qué imprimirá el siguiente código?
for i in range(5): if i == 3: continue print(i, end=" ") -
¿Cuándo se ejecuta el bloque
elsede un bucle? -
¿Qué imprimirá este código?
for i in range(3): if i == 10: break print(i, end=" ") else: print("Fin", end=" ")
Soluciones
-
Diferencia entre
breakycontinue:break: Termina completamente el bucle y continúa con el código después del bucle.continue: Salta el resto del código en la iteración actual y pasa a la siguiente iteración del bucle.
-
El código imprimirá:
0 1 2 4Explicación: Cuando
ies igual a 3, la instruccióncontinuehace que se salte elprint()y se pase a la siguiente iteración. Por lo tanto, se imprimen todos los números del 0 al 4 excepto el 3. -
El bloque
elsede un bucle se ejecuta cuando el bucle termina normalmente, es decir, cuando se han completado todas las iteraciones sin encontrar una instrucciónbreak. Si el bucle termina debido a unbreak, el bloqueelseno se ejecuta. -
El código imprimirá:
0 1 2 FinExplicación: El bucle itera sobre los valores 0, 1 y 2, imprimiendo cada uno. La condición
if i == 10nunca se cumple, por lo que elbreaknunca se ejecuta. Como el bucle termina normalmente (sinbreak), se ejecuta el bloqueelseque imprime “Fin”.
Ejercicio práctico: Sistema de procesamiento de pedidos
# ================================
# SISTEMA DE PROCESAMIENTO DE PEDIDOS
# ================================
pedidos = [
{"id": 101, "cliente": "Ana García", "productos": ["laptop", "mouse"], "pagado": True},
{"id": 102, "cliente": "Carlos López", "productos": [], "pagado": True},
{"id": 103, "cliente": "Elena Martínez", "productos": ["monitor", "teclado"], "pagado": False},
{"id": 104, "cliente": "David Rodríguez", "productos": ["tablet"], "pagado": True},
{"id": 105, "cliente": "Sofía Pérez", "productos": ["impresora", "scanner", "papel"], "pagado": True}
]
print("📦 SISTEMA DE PROCESAMIENTO DE PEDIDOS")
print("=" * 40)
pedidos_procesados = 0
pedidos_con_error = 0
# Procesar cada pedido
for pedido in pedidos:
id_pedido = pedido["id"]
cliente = pedido["cliente"]
productos = pedido["productos"]
pagado = pedido["pagado"]
print(f"Procesando pedido #{id_pedido} de {cliente}")
# Verificar si el pedido está vacío
if not productos:
print(f" ⚠️ Error: Pedido vacío")
print(f" ⏭️ Saltando al siguiente pedido")
pedidos_con_error += 1
print()
continue
# Verificar si el pedido está pagado
if not pagado:
print(f" ⚠️ Error: Pedido no pagado")
print(f" ⏭️ Saltando al siguiente pedido")
pedidos_con_error += 1
print()
continue
# Procesar productos
print(f" ✅ Verificando {len(productos)} productos:")
for i, producto in enumerate(productos, 1):
print(f" {i}. {producto}")
# Simular procesamiento exitoso
print(f" ✅ Pedido #{id_pedido} procesado correctamente")
pedidos_procesados += 1
print()
else:
print("🎉 ¡Todos los pedidos han sido revisados!")
# Mostrar resumen
print("📊 RESUMEN DE PROCESAMIENTO:")
print(f"Pedidos procesados: {pedidos_procesados}")
print(f"Pedidos con error: {pedidos_con_error}")
print(f"Total de pedidos: {len(pedidos)}")
if pedidos_con_error == 0:
print("✅ Procesamiento completado sin errores")
else:
print(f"⚠️ {pedidos_con_error} pedidos requieren atención")
print("🔚 Proceso finalizado")
¡Ahora tienes el poder de controlar tus bucles con precisión! En el próximo capítulo, aprenderás patrones comunes que combinan todo lo que has aprendido para resolver problemas frecuentes en programación.
🧭 Navegación:
- Anterior: Bucles While
- Siguiente: Patrones Comunes
Capítulos de esta sección:
- Control de Flujo – Bucles
- Bucles For
- Bucles While
- Control de Bucles (página actual)
- Patrones Comunes
Patrones Comunes: Recetas Probadas para Problemas Frecuentes
🧭 Navegación:
- Anterior: Control de Bucles
- Siguiente: Estructuras de Datos
¡Bienvenido al departamento de soluciones eficientes de tu almacén! Ahora que conoces todas las herramientas de control de flujo, es momento de aprender algunos patrones comunes que los programadores experimentados utilizan para resolver problemas frecuentes.
Los patrones comunes son como recetas probadas que combinan condicionales y bucles para resolver tareas específicas de manera eficiente y elegante.
El libro de recetas de tu almacén 📚
Imagínate que tienes un libro de recetas con soluciones optimizadas para las tareas más comunes en tu almacén:
- Recetas de búsqueda: Encontrar elementos específicos
- Recetas de filtrado: Seleccionar elementos que cumplan ciertos criterios
- Recetas de transformación: Modificar elementos de forma sistemática
- Recetas de acumulación: Combinar elementos para obtener resultados
- Recetas de validación: Verificar que los datos cumplan ciertos requisitos
# Una receta en acción
numeros = [10, 25, 3, 8, 42, 15, 7]
# Receta para encontrar el máximo
maximo = numeros[0] # Empezamos asumiendo que el primero es el máximo
for numero in numeros[1:]: # Revisamos el resto
if numero > maximo:
maximo = numero # Actualizamos si encontramos uno mayor
print(f"El número máximo es: {maximo}") # 42
🔍 Mi perspectiva personal: Dominar estos patrones comunes fue un punto de inflexión en mi carrera como programador. Pasé de escribir código que “simplemente funcionaba” a escribir código elegante, eficiente y fácil de mantener. Estos patrones son como las piezas fundamentales de un juego de construcción: una vez que los dominas, puedes combinarlos para resolver problemas cada vez más complejos.
Patrón 1: Búsqueda lineal
Este patrón te permite encontrar un elemento específico en una colección:
# ================================
# BUSCADOR DE ELEMENTOS
# ================================
productos = ["laptop", "mouse", "teclado", "monitor", "auriculares"]
producto_buscado = "teclado"
print("🔍 BUSCADOR DE ELEMENTOS")
print("=" * 25)
print(f"Buscando: {producto_buscado}")
print(f"En lista: {productos}")
print()
# Inicializar variables
encontrado = False
posicion = -1
# Buscar el elemento
for i, producto in enumerate(productos):
print(f"Revisando posición {i}: {producto}")
if producto == producto_buscado:
encontrado = True
posicion = i
print(f" ✅ ¡Elemento encontrado!")
break
print(" ⏭️ Continuando búsqueda...")
# Mostrar resultado
if encontrado:
print(f"\n🎯 {producto_buscado} encontrado en posición {posicion}")
else:
print(f"\n❌ {producto_buscado} no encontrado en la lista")
print("🔚 Búsqueda finalizada")
Variante: Búsqueda de todos los elementos que cumplen un criterio
# ================================
# BUSCADOR DE MÚLTIPLES ELEMENTOS
# ================================
productos = ["laptop", "mouse", "teclado", "monitor", "teclado", "auriculares"]
producto_buscado = "teclado"
print("🔍 BUSCADOR DE MÚLTIPLES ELEMENTOS")
print("=" * 35)
print(f"Buscando todas las ocurrencias de: {producto_buscado}")
print(f"En lista: {productos}")
print()
# Inicializar variables
posiciones = []
# Buscar todas las ocurrencias
for i, producto in enumerate(productos):
print(f"Revisando posición {i}: {producto}")
if producto == producto_buscado:
posiciones.append(i)
print(f" ✅ ¡Elemento encontrado!")
else:
print(" ⏭️ Continuando búsqueda...")
# Mostrar resultado
if posiciones:
print(f"\n🎯 {producto_buscado} encontrado en {len(posiciones)} posiciones: {posiciones}")
else:
print(f"\n❌ {producto_buscado} no encontrado en la lista")
print("🔚 Búsqueda finalizada")
Patrón 2: Filtrado
Este patrón te permite seleccionar elementos que cumplen ciertos criterios:
# ================================
# FILTRADOR DE ELEMENTOS
# ================================
productos = [
{"nombre": "laptop", "precio": 1200, "disponible": True},
{"nombre": "mouse", "precio": 25, "disponible": True},
{"nombre": "teclado", "precio": 50, "disponible": False},
{"nombre": "monitor", "precio": 300, "disponible": True},
{"nombre": "auriculares", "precio": 80, "disponible": False}
]
print("🔍 FILTRADOR DE ELEMENTOS")
print("=" * 25)
# Filtrar productos disponibles
productos_disponibles = []
for producto in productos:
if producto["disponible"]:
productos_disponibles.append(producto)
print(f"Productos disponibles: {len(productos_disponibles)}")
for producto in productos_disponibles:
print(f" • {producto['nombre']} - ${producto['precio']}")
print()
# Filtrar productos económicos (menos de $100)
productos_economicos = []
for producto in productos:
if producto["precio"] < 100:
productos_economicos.append(producto)
print(f"Productos económicos: {len(productos_economicos)}")
for producto in productos_economicos:
print(f" • {producto['nombre']} - ${producto['precio']}")
print()
# Filtrar productos disponibles Y económicos
productos_disponibles_economicos = []
for producto in productos:
if producto["disponible"] and producto["precio"] < 100:
productos_disponibles_economicos.append(producto)
print(f"Productos disponibles y económicos: {len(productos_disponibles_economicos)}")
for producto in productos_disponibles_economicos:
print(f" • {producto['nombre']} - ${producto['precio']}")
print()
# Versión con comprensión de listas
productos_filtrados = [p for p in productos if p["disponible"] and p["precio"] < 100]
print(f"Usando comprensión de listas: {len(productos_filtrados)} productos")
for producto in productos_filtrados:
print(f" • {producto['nombre']} - ${producto['precio']}")
print("🔚 Filtrado finalizado")
Patrón 3: Transformación (Mapeo)
Este patrón te permite aplicar una transformación a cada elemento de una colección:
# ================================
# TRANSFORMADOR DE ELEMENTOS
# ================================
precios = [100, 25, 50, 300, 80]
print("🔄 TRANSFORMADOR DE ELEMENTOS")
print("=" * 30)
print(f"Precios originales: {precios}")
print()
# Aplicar descuento del 10%
precios_con_descuento = []
for precio in precios:
precio_descuento = precio * 0.9 # 10% de descuento
precios_con_descuento.append(precio_descuento)
print(f"Precios con 10% de descuento: {precios_con_descuento}")
print()
# Aplicar impuesto del 21%
precios_con_impuesto = []
for precio in precios:
precio_impuesto = precio * 1.21 # 21% de impuesto
precios_con_impuesto.append(precio_impuesto)
print(f"Precios con 21% de impuesto: {precios_con_impuesto}")
print()
# Versión con comprensión de listas
precios_formateados = [f"${precio:.2f}" for precio in precios]
print(f"Precios formateados: {precios_formateados}")
print()
# Transformación de objetos
productos = [
{"nombre": "laptop", "precio": 1200},
{"nombre": "mouse", "precio": 25},
{"nombre": "teclado", "precio": 50}
]
# Añadir campo de precio con impuesto
for producto in productos:
producto["precio_con_impuesto"] = producto["precio"] * 1.21
print("Productos con precio e impuesto:")
for producto in productos:
print(f" • {producto['nombre']}: ${producto['precio']} (con impuesto: ${producto['precio_con_impuesto']:.2f})")
print("🔚 Transformación finalizada")
Patrón 4: Acumulación
Este patrón te permite combinar elementos para obtener un resultado acumulado:
# ================================
# ACUMULADOR DE VALORES
# ================================
ventas = [1200, 300, 800, 550, 1000, 450]
print("📊 ACUMULADOR DE VALORES")
print("=" * 25)
print(f"Ventas diarias: {ventas}")
print()
# Calcular suma total
total_ventas = 0
for venta in ventas:
total_ventas += venta
print(f"Total de ventas: ${total_ventas}")
print()
# Calcular promedio
promedio_ventas = total_ventas / len(ventas)
print(f"Promedio de ventas: ${promedio_ventas:.2f}")
print()
# Encontrar máximo y mínimo
venta_maxima = ventas[0]
venta_minima = ventas[0]
dia_maximo = 1
dia_minimo = 1
for i, venta in enumerate(ventas, 1):
if venta > venta_maxima:
venta_maxima = venta
dia_maximo = i
if venta < venta_minima:
venta_minima = venta
dia_minimo = i
print(f"Venta máxima: ${venta_maxima} (Día {dia_maximo})")
print(f"Venta mínima: ${venta_minima} (Día {dia_minimo})")
print()
# Contar ventas por encima del promedio
ventas_sobre_promedio = 0
for venta in ventas:
if venta > promedio_ventas:
ventas_sobre_promedio += 1
print(f"Días con ventas sobre el promedio: {ventas_sobre_promedio}")
print("🔚 Análisis finalizado")
Variante: Acumulación con diccionarios
# ================================
# CONTADOR DE FRECUENCIAS
# ================================
votos = ["A", "B", "A", "C", "B", "B", "A", "C", "A", "D", "B", "A"]
print("📊 CONTADOR DE FRECUENCIAS")
print("=" * 25)
print(f"Votos: {votos}")
print()
# Contar frecuencia de cada opción
frecuencias = {}
for voto in votos:
if voto in frecuencias:
frecuencias[voto] += 1
else:
frecuencias[voto] = 1
print("Resultados de la votación:")
for opcion, cantidad in frecuencias.items():
print(f" • Opción {opcion}: {cantidad} votos")
print()
# Encontrar la opción ganadora
opcion_ganadora = ""
max_votos = 0
for opcion, cantidad in frecuencias.items():
if cantidad > max_votos:
max_votos = cantidad
opcion_ganadora = opcion
print(f"🏆 La opción ganadora es: {opcion_ganadora} con {max_votos} votos")
print("🔚 Conteo finalizado")
Patrón 5: Validación
Este patrón te permite verificar que los datos cumplan ciertos requisitos:
# ================================
# VALIDADOR DE DATOS
# ================================
datos_usuario = {
"nombre": "Ana García",
"email": "ana@ejemplo.com",
"edad": 25,
"contraseña": "Abc123!"
}
print("✅ VALIDADOR DE DATOS")
print("=" * 25)
print("Validando datos de usuario:")
for campo, valor in datos_usuario.items():
print(f" • {campo}: {valor}")
print()
# Inicializar variables
errores = []
# Validar nombre
if not datos_usuario["nombre"]:
errores.append("El nombre no puede estar vacío")
elif len(datos_usuario["nombre"]) < 3:
errores.append("El nombre debe tener al menos 3 caracteres")
# Validar email
email = datos_usuario["email"]
if not email:
errores.append("El email no puede estar vacío")
elif "@" not in email or "." not in email:
errores.append("El email debe contener '@' y '.'")
# Validar edad
edad = datos_usuario["edad"]
if not isinstance(edad, int):
errores.append("La edad debe ser un número entero")
elif edad < 18:
errores.append("Debes ser mayor de edad (18+)")
elif edad > 120:
errores.append("La edad parece incorrecta")
# Validar contraseña
contraseña = datos_usuario["contraseña"]
if len(contraseña) < 6:
errores.append("La contraseña debe tener al menos 6 caracteres")
elif not any(c.isupper() for c in contraseña):
errores.append("La contraseña debe contener al menos una mayúscula")
elif not any(c.islower() for c in contraseña):
errores.append("La contraseña debe contener al menos una minúscula")
elif not any(c.isdigit() for c in contraseña):
errores.append("La contraseña debe contener al menos un número")
elif not any(c in "!@#$%^&*" for c in contraseña):
errores.append("La contraseña debe contener al menos un carácter especial")
# Mostrar resultado
if errores:
print("❌ Validación fallida:")
for error in errores:
print(f" • {error}")
else:
print("✅ Todos los datos son válidos")
print("🔚 Validación finalizada")
Patrón 6: Agrupación
Este patrón te permite organizar elementos en grupos según ciertos criterios:
# ================================
# AGRUPADOR DE ELEMENTOS
# ================================
productos = [
{"nombre": "laptop", "categoria": "electrónica", "precio": 1200},
{"nombre": "camisa", "categoria": "ropa", "precio": 25},
{"nombre": "pantalón", "categoria": "ropa", "precio": 35},
{"nombre": "tablet", "categoria": "electrónica", "precio": 300},
{"nombre": "zapatos", "categoria": "ropa", "precio": 80},
{"nombre": "monitor", "categoria": "electrónica", "precio": 250}
]
print("📊 AGRUPADOR DE ELEMENTOS")
print("=" * 25)
print(f"Total de productos: {len(productos)}")
print()
# Agrupar por categoría
productos_por_categoria = {}
for producto in productos:
categoria = producto["categoria"]
if categoria not in productos_por_categoria:
productos_por_categoria[categoria] = []
productos_por_categoria[categoria].append(producto)
# Mostrar grupos
print("Productos agrupados por categoría:")
for categoria, lista_productos in productos_por_categoria.items():
print(f"📁 {categoria.upper()} ({len(lista_productos)} productos):")
for producto in lista_productos:
print(f" • {producto['nombre']} - ${producto['precio']}")
# Calcular precio promedio de la categoría
precio_total = sum(p["precio"] for p in lista_productos)
precio_promedio = precio_total / len(lista_productos)
print(f" 📊 Precio promedio: ${precio_promedio:.2f}")
print()
print("🔚 Agrupación finalizada")
Patrón 7: Combinación de colecciones
Este patrón te permite trabajar con múltiples colecciones relacionadas:
# ================================
# COMBINADOR DE COLECCIONES
# ================================
clientes = [
{"id": 1, "nombre": "Ana García"},
{"id": 2, "nombre": "Carlos López"},
{"id": 3, "nombre": "Elena Martínez"}
]
pedidos = [
{"cliente_id": 1, "producto": "laptop", "cantidad": 1},
{"cliente_id": 2, "producto": "monitor", "cantidad": 2},
{"cliente_id": 1, "producto": "mouse", "cantidad": 1},
{"cliente_id": 3, "producto": "teclado", "cantidad": 1},
{"cliente_id": 2, "producto": "auriculares", "cantidad": 1},
{"cliente_id": 1, "producto": "tablet", "cantidad": 1}
]
print("🔄 COMBINADOR DE COLECCIONES")
print("=" * 30)
print(f"Clientes: {len(clientes)}")
print(f"Pedidos: {len(pedidos)}")
print()
# Crear informe de pedidos por cliente
print("INFORME DE PEDIDOS POR CLIENTE:")
print("=" * 30)
for cliente in clientes:
cliente_id = cliente["id"]
nombre = cliente["nombre"]
print(f"👤 Cliente: {nombre}")
# Encontrar todos los pedidos de este cliente
pedidos_cliente = []
for pedido in pedidos:
if pedido["cliente_id"] == cliente_id:
pedidos_cliente.append(pedido)
# Mostrar pedidos
if pedidos_cliente:
print(f" 📦 Pedidos ({len(pedidos_cliente)}):")
for i, pedido in enumerate(pedidos_cliente, 1):
print(f" {i}. {pedido['producto']} (x{pedido['cantidad']})")
else:
print(" ❌ No tiene pedidos")
print()
print("🔚 Informe finalizado")
Patrón 8: Procesamiento por lotes
Este patrón te permite procesar grandes cantidades de datos en grupos más pequeños:
# ================================
# PROCESADOR POR LOTES
# ================================
datos = list(range(1, 101)) # Lista de números del 1 al 100
tamaño_lote = 10
print("📦 PROCESADOR POR LOTES")
print("=" * 25)
print(f"Total de elementos: {len(datos)}")
print(f"Tamaño de lote: {tamaño_lote}")
print()
# Procesar por lotes
total_lotes = (len(datos) + tamaño_lote - 1) // tamaño_lote # Redondeo hacia arriba
for i in range(total_lotes):
# Calcular índices del lote actual
inicio = i * tamaño_lote
fin = min(inicio + tamaño_lote, len(datos))
lote_actual = datos[inicio:fin]
print(f"Procesando lote {i+1}/{total_lotes} (elementos {inicio+1}-{fin}):")
# Procesar cada elemento del lote
suma_lote = 0
for elemento in lote_actual:
suma_lote += elemento
print(f" • Elementos: {lote_actual}")
print(f" • Suma del lote: {suma_lote}")
print()
print("🔚 Procesamiento por lotes finalizado")
Comprueba tu comprensión 🧠
-
¿Qué patrón utilizarías para encontrar todos los productos con precio mayor a $100?
-
¿Cuál es la diferencia entre el patrón de transformación y el patrón de acumulación?
-
Escribe un código que utilice el patrón de validación para verificar si una contraseña cumple con los siguientes requisitos: al menos 8 caracteres, al menos una mayúscula, al menos un número.
-
¿Qué patrón utilizarías para contar cuántas veces aparece cada letra en una cadena de texto?
Soluciones
-
Para encontrar todos los productos con precio mayor a $100, utilizaría el patrón de filtrado:
productos = [ {"nombre": "laptop", "precio": 1200}, {"nombre": "mouse", "precio": 25}, {"nombre": "teclado", "precio": 50}, {"nombre": "monitor", "precio": 300} ] productos_caros = [] for producto in productos: if producto["precio"] > 100: productos_caros.append(producto) # Alternativa con comprensión de listas: # productos_caros = [p for p in productos if p["precio"] > 100] -
Diferencia entre transformación y acumulación:
- Transformación (Mapeo): Aplica una operación a cada elemento de una colección para crear una nueva colección con los resultados. La cantidad de elementos de entrada y salida es la misma.
- Acumulación: Combina todos los elementos de una colección para producir un único resultado (como una suma, promedio, máximo, etc.).
-
Código para validar una contraseña:
def validar_contraseña(contraseña): errores = [] if len(contraseña) < 8: errores.append("La contraseña debe tener al menos 8 caracteres") if not any(c.isupper() for c in contraseña): errores.append("La contraseña debe contener al menos una mayúscula") if not any(c.isdigit() for c in contraseña): errores.append("La contraseña debe contener al menos un número") return errores # Ejemplo de uso contraseña = "password123" errores = validar_contraseña(contraseña) if errores: print("Contraseña inválida:") for error in errores: print(f"- {error}") else: print("Contraseña válida") -
Para contar cuántas veces aparece cada letra en una cadena de texto, utilizaría el patrón de acumulación con diccionarios (contador de frecuencias):
texto = "programacion" frecuencias = {} for letra in texto: if letra in frecuencias: frecuencias[letra] += 1 else: frecuencias[letra] = 1 # Alternativa con defaultdict: # from collections import defaultdict # frecuencias = defaultdict(int) # for letra in texto: # frecuencias[letra] += 1
Ejercicio práctico: Sistema de análisis de ventas
# ================================
# SISTEMA DE ANÁLISIS DE VENTAS
# ================================
ventas = [
{"fecha": "2023-01-15", "producto": "laptop", "categoria": "electrónica", "cantidad": 1, "precio": 1200},
{"fecha": "2023-01-15", "producto": "mouse", "categoria": "electrónica", "cantidad": 3, "precio": 25},
{"fecha": "2023-01-16", "producto": "camisa", "categoria": "ropa", "cantidad": 2, "precio": 30},
{"fecha": "2023-01-17", "producto": "laptop", "categoria": "electrónica", "cantidad": 1, "precio": 1200},
{"fecha": "2023-01-18", "producto": "pantalón", "categoria": "ropa", "cantidad": 1, "precio": 50},
{"fecha": "2023-01-19", "producto": "monitor", "categoria": "electrónica", "cantidad": 2, "precio": 300},
{"fecha": "2023-01-20", "producto": "zapatos", "categoria": "ropa", "cantidad": 1, "precio": 80},
{"fecha": "2023-01-20", "producto": "teclado", "categoria": "electrónica", "cantidad": 4, "precio": 45}
]
print("📊 SISTEMA DE ANÁLISIS DE VENTAS")
print("=" * 35)
print(f"Total de transacciones: {len(ventas)}")
print()
# 1. Calcular ventas totales (patrón de acumulación)
total_ventas = 0
total_unidades = 0
for venta in ventas:
importe = venta["cantidad"] * venta["precio"]
total_ventas += importe
total_unidades += venta["cantidad"]
print(f"💰 VENTAS TOTALES: ${total_ventas:,.2f}")
print(f"📦 UNIDADES VENDIDAS: {total_unidades}")
print()
# 2. Agrupar ventas por categoría (patrón de agrupación)
ventas_por_categoria = {}
for venta in ventas:
categoria = venta["categoria"]
importe = venta["cantidad"] * venta["precio"]
if categoria in ventas_por_categoria:
ventas_por_categoria[categoria] += importe
else:
ventas_por_categoria[categoria] = importe
print("📊 VENTAS POR CATEGORÍA:")
for categoria, importe in ventas_por_categoria.items():
porcentaje = (importe / total_ventas) * 100
print(f" • {categoria}: ${importe:,.2f} ({porcentaje:.1f}%)")
print()
# 3. Encontrar el producto más vendido (patrones de acumulación y búsqueda)
ventas_por_producto = {}
for venta in ventas:
producto = venta["producto"]
cantidad = venta["cantidad"]
if producto in ventas_por_producto:
ventas_por_producto[producto] += cantidad
else:
ventas_por_producto[producto] = cantidad
producto_mas_vendido = ""
max_cantidad = 0
for producto, cantidad in ventas_por_producto.items():
if cantidad > max_cantidad:
max_cantidad = cantidad
producto_mas_vendido = producto
print(f"🏆 PRODUCTO MÁS VENDIDO: {producto_mas_vendido} ({max_cantidad} unidades)")
print()
# 4. Analizar ventas por día (patrón de agrupación)
ventas_por_dia = {}
for venta in ventas:
fecha = venta["fecha"]
importe = venta["cantidad"] * venta["precio"]
if fecha in ventas_por_dia:
ventas_por_dia[fecha]["importe"] += importe
ventas_por_dia[fecha]["transacciones"] += 1
else:
ventas_por_dia[fecha] = {"importe": importe, "transacciones": 1}
print("📅 VENTAS POR DÍA:")
for fecha, datos in ventas_por_dia.items():
print(f" • {fecha}: ${datos['importe']:,.2f} ({datos['transacciones']} transacciones)")
print("🔚 Análisis finalizado")
¡Ahora tienes un arsenal de patrones comunes para resolver problemas frecuentes en programación! En el próximo capítulo, aprenderás a visualizar el flujo de tus programas con diagramas.
🧭 Navegación:
- Anterior: Control de Bucles
- Siguiente: Estructuras de Datos
Capítulos de esta sección:
- Control de Flujo – Bucles
- Bucles For
- Bucles While
- Control de Bucles
- Patrones Comunes (página actual)
Estructuras de Datos en Python
🧭 Navegación:
- Anterior: Control de Flujo – Bucles
- Siguiente: Funciones – Bloques de Construcción para Reutilización
¡Bienvenido al sistema de almacenamiento avanzado de tu almacén! En esta sección, aprenderás a organizar y manipular datos de manera eficiente usando diferentes tipos de contenedores especializados.
¿Qué son las estructuras de datos?
Las estructuras de datos son como sistemas de almacenamiento especializados en tu almacén:
- Listas: Estanterías flexibles donde puedes añadir, quitar y reorganizar elementos
- Diccionarios: Sistema de inventario con etiquetas para acceso rápido
- Tuplas: Paquetes sellados que no pueden modificarse una vez creados
- Conjuntos (Sets): Estaciones de clasificación que eliminan duplicados automáticamente
Estas estructuras te permiten almacenar, organizar y manipular datos de manera eficiente según tus necesidades específicas.
Contenido de esta sección
En esta sección aprenderás sobre:
-
Listas - Estanterías flexibles para almacenar secuencias de elementos
- Creación y acceso a elementos
- Métodos para manipular listas
- Listas por comprensión
-
Diccionarios - Sistema de inventario con pares clave-valor
- Creación y acceso a valores
- Operaciones comunes
- Diccionarios anidados
-
Tuplas - Contenedores inmutables para datos que no deben cambiar
- Creación y características
- Cuándo usar tuplas vs listas
- Desempaquetado de tuplas
-
Conjuntos (Sets) - Colecciones sin duplicados para operaciones matemáticas
- Creación y operaciones
- Operaciones de conjuntos
- Aplicaciones prácticas
¿Por qué son importantes las estructuras de datos?
Las estructuras de datos son fundamentales en programación porque:
- Permiten organizar información de manera lógica y eficiente
- Ofrecen operaciones especializadas para diferentes tipos de datos
- Mejoran el rendimiento de tus programas
- Facilitan la resolución de problemas complejos
- Son la base para algoritmos y estructuras más avanzadas
Analogía del almacén
A lo largo de esta sección, continuaremos con la analogía del almacén:
- Las listas son como estanterías o cintas transportadoras donde puedes colocar elementos en secuencia
- Los diccionarios son como un sistema de inventario con códigos de barras para acceso instantáneo
- Las tuplas son como paquetes sellados que garantizan que su contenido no cambiará
- Los conjuntos son como estaciones de clasificación que automáticamente eliminan duplicados
Mapa conceptual
ESTRUCTURAS DE DATOS
|
|-- Listas (Secuencias mutables)
| |-- Creación y acceso
| |-- Métodos (append, insert, remove...)
| |-- Listas por comprensión
|
|-- Diccionarios (Mapeo clave-valor)
| |-- Creación y acceso
| |-- Métodos (keys, values, items...)
| |-- Diccionarios anidados
|
|-- Tuplas (Secuencias inmutables)
| |-- Creación y características
| |-- Desempaquetado
| |-- Casos de uso
|
|-- Conjuntos (Colecciones sin duplicados)
|-- Creación y operaciones
|-- Operaciones matemáticas
|-- Aplicaciones prácticas
¡Comencemos nuestro viaje por el mundo de las estructuras de datos en Python!
🧭 Navegación:
- Anterior: Control de Flujo – Bucles
- Siguiente: Funciones – Bloques de Construcción para Reutilización
Capítulos de esta sección:
- Introducción a Estructuras de Datos (página actual)
- Listas
- Diccionarios
- Tuplas
- Conjuntos (Sets)
- Quiz: Estructuras de Datos
Listas: Las Estanterías Flexibles
🧭 Navegación:
- Anterior: Introducción a Estructuras de Datos
- Siguiente: Diccionarios
¡Bienvenido a la sección de estanterías de nuestro almacén! En este capítulo, aprenderás sobre las listas, una de las estructuras de datos más versátiles y utilizadas en Python.
📚 Las estanterías inteligentes de tu almacén
Imagina que en tu almacén acabas de instalar un sistema de estanterías modular súper avanzado. Estas estanterías tienen características especiales:
- Se expanden automáticamente cuando necesitas más espacio
- Mantienen el orden exacto de los productos que colocas
- Numeran automáticamente cada posición (empezando desde 0)
- Permiten reorganizar los productos fácilmente
- Aceptan cualquier tipo de producto en cualquier posición
En Python, las listas funcionan exactamente así: son colecciones ordenadas y modificables que pueden contener cualquier tipo de datos.
# Tu estantería modular en acción
productos = ["laptop", "mouse", "teclado", "monitor"]
print("📦 Estantería de productos:")
for posicion, producto in enumerate(productos):
print(f"Posición {posicion}: {producto}")
# Resultado:
# Posición 0: laptop
# Posición 1: mouse
# Posición 2: teclado
# Posición 3: monitor
🔍 Mi perspectiva: Cuando empecé a programar, me costaba entender por qué la primera posición era 0 y no 1. Con el tiempo, me di cuenta de que es como medir distancias: el primer elemento está a 0 pasos del inicio, el segundo a 1 paso, y así sucesivamente. Esta forma de pensar me ayudó mucho.
Características principales de las listas
1. ✅ Ordenadas: Mantienen el orden de inserción
Las listas son como una cinta transportadora que mantiene el orden exacto de los productos:
pasos_proceso = ["recibir", "verificar", "almacenar", "etiquetar", "enviar"]
print(f"Primer paso: {pasos_proceso[0]}") # recibir
print(f"Último paso: {pasos_proceso[-1]}") # enviar
2. ✅ Modificables (Mutables): Puedes cambiar su contenido
Puedes añadir, quitar o cambiar productos en tu estantería en cualquier momento:
inventario = ["laptop", "mouse", "teclado"]
# Añadir un producto nuevo
inventario.append("monitor")
# Cambiar un producto existente
inventario[1] = "mouse_gaming"
print(inventario) # ['laptop', 'mouse_gaming', 'teclado', 'monitor']
3. ✅ Permiten duplicados: El mismo elemento puede aparecer varias veces
A diferencia de otras estructuras, las listas permiten tener múltiples copias del mismo elemento:
pedidos_dia = ["laptop", "mouse", "laptop", "teclado", "laptop"]
print(f"Laptops pedidas hoy: {pedidos_dia.count('laptop')}") # 3
4. ✅ Indexadas: Acceso directo a cualquier posición
Puedes acceder instantáneamente a cualquier producto conociendo su posición:
productos = ["A", "B", "C", "D", "E"]
print(f"Primero: {productos[0]}") # A
print(f"Tercero: {productos[2]}") # C
print(f"Último: {productos[-1]}") # E
Creando tus propias estanterías (listas)
Hay varias formas de crear listas en Python, igual que hay diferentes formas de montar estanterías en un almacén:
Método 1: Estantería vacía lista para llenar
# Estantería completamente vacía
productos = []
inventario = list() # Otra forma de crear una lista vacía
Método 2: Estantería con productos iniciales
# Estantería ya con productos
frutas = ["manzana", "naranja", "plátano", "uva"]
numeros = [1, 2, 3, 4, 5]
Método 3: Estantería con productos variados
Las listas pueden contener cualquier tipo de datos, incluso otras listas:
# Información completa de un producto
producto_info = ["Laptop Dell XPS", 15.6, True, 999.99, ["negro", "plata"]]
print(f"Nombre: {producto_info[0]}")
print(f"Tamaño: {producto_info[1]} pulgadas")
print(f"Disponible: {producto_info[2]}")
print(f"Precio: ${producto_info[3]}")
print(f"Colores disponibles: {producto_info[4][0]} y {producto_info[4][1]}")
Método 4: Estantería con secuencias numéricas
# Crear lista de números con range()
numeros_pares = list(range(0, 11, 2)) # [0, 2, 4, 6, 8, 10]
print(f"Números pares hasta 10: {numeros_pares}")
Método 5: Estantería con generación automática (comprensión de listas)
# Generar lista con una fórmula
cuadrados = [x**2 for x in range(1, 6)] # [1, 4, 9, 16, 25]
print(f"Cuadrados del 1 al 5: {cuadrados}")
Accediendo a los productos en tus estanterías
Acceso por índice: Conocer la posición exacta
productos = ["laptop", "mouse", "teclado", "monitor", "webcam"]
# Índices positivos (desde el inicio)
print(f"Primer producto: {productos[0]}") # laptop
print(f"Tercer producto: {productos[2]}") # teclado
# Índices negativos (desde el final)
print(f"Último producto: {productos[-1]}") # webcam
print(f"Penúltimo producto: {productos[-2]}") # monitor
Slicing: Obtener secciones de estantería
El slicing (rebanado) es como seleccionar una sección completa de tu estantería:
productos = ["A", "B", "C", "D", "E", "F", "G", "H"]
# Sintaxis: lista[inicio:fin:paso]
# (fin no está incluido en el resultado)
# Primeros 3 productos
print(f"Primeros 3: {productos[:3]}") # ['A', 'B', 'C']
# Últimos 3 productos
print(f"Últimos 3: {productos[-3:]}") # ['F', 'G', 'H']
# Del tercero al sexto
print(f"Del 3 al 6: {productos[2:6]}") # ['C', 'D', 'E', 'F']
# Productos en posiciones pares
print(f"Posiciones pares: {productos[::2]}") # ['A', 'C', 'E', 'G']
# Invertir el orden
print(f"Orden inverso: {productos[::-1]}") # ['H', 'G', 'F', 'E', 'D', 'C', 'B', 'A']
🔍 Mi perspectiva: El slicing fue uno de los conceptos que más me costó dominar al principio, pero una vez que lo entiendes, se convierte en una herramienta increíblemente poderosa. Yo lo visualizo como cortar rebanadas de un pan: defines dónde empiezas a cortar, dónde terminas, y qué tan gruesas son las rebanadas.
Operaciones básicas con estanterías
1. Añadir productos a tu estantería
productos = ["laptop", "mouse"]
# append() - Añadir al final de la estantería
productos.append("teclado")
print(productos) # ['laptop', 'mouse', 'teclado']
# insert() - Colocar en una posición específica
productos.insert(1, "monitor") # Insertar en posición 1
print(productos) # ['laptop', 'monitor', 'mouse', 'teclado']
# extend() - Añadir múltiples productos de una vez
nuevos_productos = ["webcam", "altavoces"]
productos.extend(nuevos_productos)
print(productos) # ['laptop', 'monitor', 'mouse', 'teclado', 'webcam', 'altavoces']
2. Quitar productos de tu estantería
productos = ["laptop", "mouse", "teclado", "monitor", "mouse", "webcam"]
# remove() - Quitar la primera ocurrencia de un producto
productos.remove("mouse") # Elimina el primer "mouse"
print(productos) # ['laptop', 'teclado', 'monitor', 'mouse', 'webcam']
# pop() - Quitar y devolver un producto
ultimo = productos.pop() # Quita el último
print(f"Producto retirado: {ultimo}") # webcam
print(productos) # ['laptop', 'teclado', 'monitor', 'mouse']
segundo = productos.pop(1) # Quita el de posición 1
print(f"Producto retirado: {segundo}") # teclado
print(productos) # ['laptop', 'monitor', 'mouse']
# del - Eliminar por índice o sección
del productos[0] # Elimina el primero
print(productos) # ['monitor', 'mouse']
# clear() - Vaciar completamente la estantería
productos_temp = ["a", "b", "c"]
productos_temp.clear()
print(productos_temp) # []
3. Buscar y contar productos
inventario = ["laptop", "mouse", "laptop", "teclado", "mouse", "laptop"]
# count() - Contar cuántas veces aparece un producto
laptops = inventario.count("laptop")
print(f"Laptops en inventario: {laptops}") # 3
# index() - Encontrar la posición de un producto
posicion_mouse = inventario.index("mouse")
print(f"Primer mouse en posición: {posicion_mouse}") # 1
# in - Verificar si un producto existe
if "webcam" in inventario:
print("Tenemos webcams en stock")
else:
print("No tenemos webcams en stock") # Este se ejecuta
4. Organizar tu estantería
# Datos de ejemplo
numeros = [64, 34, 25, 12, 22, 11, 90]
nombres = ["Carlos", "Ana", "Pedro", "María", "Luis"]
# sort() - Ordenar la estantería original
numeros.sort() # Orden ascendente
print(f"Números ordenados: {numeros}") # [11, 12, 22, 25, 34, 64, 90]
nombres.sort(reverse=True) # Orden descendente
print(f"Nombres en orden Z-A: {nombres}") # ['Pedro', 'María', 'Luis', 'Carlos', 'Ana']
# sorted() - Crear una copia ordenada sin modificar la original
precios = [299.99, 49.99, 89.99, 159.99]
precios_ordenados = sorted(precios)
print(f"Precios ordenados: {precios_ordenados}")
print(f"Precios originales: {precios}") # Sin cambios
# reverse() - Invertir el orden
productos = ["A", "B", "C", "D"]
productos.reverse()
print(f"Productos invertidos: {productos}") # ['D', 'C', 'B', 'A']
Técnicas avanzadas para gestionar tus estanterías
1. Comprensiones de listas: La forma elegante de llenar estanterías
Las comprensiones de listas son como tener robots que llenan tu estantería siguiendo reglas específicas:
# Sintaxis: [expresión for elemento in iterable if condición]
# Crear lista de cuadrados
numeros = [1, 2, 3, 4, 5]
cuadrados = [x**2 for x in numeros]
print(f"Cuadrados: {cuadrados}") # [1, 4, 9, 16, 25]
# Filtrar números pares
pares = [x for x in range(1, 11) if x % 2 == 0]
print(f"Números pares: {pares}") # [2, 4, 6, 8, 10]
# Procesar strings
nombres = ["ana", "carlos", "maría", "pedro"]
nombres_titulo = [nombre.title() for nombre in nombres]
print(f"Nombres formateados: {nombres_titulo}") # ['Ana', 'Carlos', 'María', 'Pedro']
2. Listas anidadas: Estanterías con compartimentos
Las listas anidadas son como estanterías con compartimentos o cajones, cada uno conteniendo su propia colección de elementos:
# Crear matriz 3x3 (como una estantería con 3 niveles y 3 compartimentos por nivel)
matriz = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
# Acceder a elementos específicos
print(f"Elemento en fila 1, columna 2: {matriz[1][2]}") # 6
# Ejemplo práctico: inventario por categorías
inventario_tienda = [
["Laptop Dell", "Laptop HP", "Laptop Lenovo"], # Laptops
["Mouse Logitech", "Mouse Razer"], # Mouses
["Teclado mecánico", "Teclado inalámbrico"] # Teclados
]
print("📦 Inventario por categorías:")
categorias = ["Laptops", "Mouses", "Teclados"]
for i, categoria in enumerate(categorias):
print(f"\n{categoria}:")
for producto in inventario_tienda[i]:
print(f" - {producto}")
3. Operaciones matemáticas con listas
# Datos de ventas mensuales
ventas = [1200, 1500, 1800, 1400, 1600, 2000, 1750, 1900, 1650, 1800, 2100, 2300]
# Operaciones básicas
total_ventas = sum(ventas)
promedio = sum(ventas) / len(ventas)
maximo = max(ventas)
minimo = min(ventas)
print(f"📊 Análisis de ventas anuales:")
print(f" Total: ${total_ventas:,}")
print(f" Promedio mensual: ${promedio:,.2f}")
print(f" Mejor mes: ${maximo:,}")
print(f" Peor mes: ${minimo:,}")
# Encontrar posiciones de máximo y mínimo
mes_mejor = ventas.index(maximo) + 1 # +1 porque los meses empiezan en 1
mes_peor = ventas.index(minimo) + 1
print(f" El mejor mes fue el mes {mes_mejor}")
print(f" El peor mes fue el mes {mes_peor}")
Aplicaciones prácticas de las listas
1. Sistema de gestión de inventario
def gestionar_inventario():
"""Sistema simple de gestión de inventario usando listas"""
# Inventario inicial
inventario = [
{"id": 1, "nombre": "Laptop", "stock": 5, "precio": 800},
{"id": 2, "nombre": "Mouse", "stock": 10, "precio": 25},
{"id": 3, "nombre": "Teclado", "stock": 8, "precio": 60}
]
# Mostrar inventario actual
print("\n📦 INVENTARIO ACTUAL:")
print("-" * 50)
print(f"{'ID':<5}{'PRODUCTO':<15}{'STOCK':<10}{'PRECIO':<10}{'VALOR':<10}")
print("-" * 50)
valor_total = 0
for item in inventario:
valor_item = item["stock"] * item["precio"]
valor_total += valor_item
print(f"{item['id']:<5}{item['nombre']:<15}{item['stock']:<10}${item['precio']:<9}${valor_item:<9}")
print("-" * 50)
print(f"Valor total del inventario: ${valor_total:,.2f}")
# Productos con poco stock (menos de 10 unidades)
poco_stock = [item["nombre"] for item in inventario if item["stock"] < 10]
print(f"\n⚠️ Productos con poco stock: {', '.join(poco_stock)}")
# Producto más caro
producto_mas_caro = max(inventario, key=lambda x: x["precio"])
print(f"💰 Producto más caro: {producto_mas_caro['nombre']} (${producto_mas_caro['precio']})")
# Ejecutar el sistema
gestionar_inventario()
2. Análisis de datos de ventas
def analizar_ventas(datos_ventas):
"""Analiza datos de ventas y genera reporte usando listas"""
# Extraer información
productos = [venta["producto"] for venta in datos_ventas]
cantidades = [venta["cantidad"] for venta in datos_ventas]
precios = [venta["precio"] for venta in datos_ventas]
totales = [venta["cantidad"] * venta["precio"] for venta in datos_ventas]
# Análisis básico
total_ingresos = sum(totales)
venta_promedio = sum(totales) / len(totales)
producto_mas_vendido = max(set(productos), key=productos.count)
# Top 3 ventas más altas
ventas_con_total = [(datos_ventas[i], totales[i]) for i in range(len(datos_ventas))]
top_ventas = sorted(ventas_con_total, key=lambda x: x[1], reverse=True)[:3]
# Generar reporte
print("\n📊 REPORTE DE VENTAS")
print("=" * 50)
print(f"Total de transacciones: {len(datos_ventas)}")
print(f"Ingresos totales: ${total_ingresos:,.2f}")
print(f"Venta promedio: ${venta_promedio:.2f}")
print(f"Producto más vendido: {producto_mas_vendido}")
print(f"\n🏆 Top 3 ventas más altas:")
for i, (venta, total) in enumerate(top_ventas, 1):
print(f" {i}. {venta['producto']} - ${total:.2f}")
# Datos de ejemplo
ventas_mes = [
{"producto": "Laptop", "cantidad": 2, "precio": 800},
{"producto": "Mouse", "cantidad": 5, "precio": 25},
{"producto": "Teclado", "cantidad": 3, "precio": 60},
{"producto": "Laptop", "cantidad": 1, "precio": 800},
{"producto": "Monitor", "cantidad": 2, "precio": 300},
{"producto": "Mouse", "cantidad": 10, "precio": 25}
]
analizar_ventas(ventas_mes)
Consejos y mejores prácticas
1. Rendimiento y eficiencia
# ✅ Bueno: usar comprensiones de lista
numeros_pares = [x for x in range(1000) if x % 2 == 0]
# ❌ Menos eficiente: bucle tradicional con append
numeros_pares = []
for x in range(1000):
if x % 2 == 0:
numeros_pares.append(x)
# ✅ Bueno: usar extend() para añadir múltiples elementos
lista.extend([1, 2, 3, 4])
# ❌ Menos eficiente: múltiples append()
lista.append(1)
lista.append(2)
lista.append(3)
lista.append(4)
2. Evitar errores comunes
# ❌ Error: modificar lista mientras se itera
numeros = [1, 2, 3, 4, 5]
for numero in numeros:
if numero % 2 == 0:
numeros.remove(numero) # ¡Problemático!
# ✅ Correcto: crear nueva lista
numeros = [1, 2, 3, 4, 5]
numeros_impares = [n for n in numeros if n % 2 != 0]
# ❌ Error: no verificar índices
lista = [1, 2, 3]
# print(lista[5]) # IndexError!
# ✅ Correcto: verificar antes de acceder
if 5 < len(lista):
print(lista[5])
else:
print("Índice fuera de rango")
🔍 Mi perspectiva: Uno de los errores más comunes que veo en mis estudiantes es modificar una lista mientras la recorren. Esto puede causar comportamientos inesperados porque los índices cambian durante la iteración. Siempre recomiendo crear una nueva lista en lugar de modificar la original durante un bucle.
Comprueba tu comprensión
Ejercicio 1: Filtrado de productos
Escribe una función que, dada una lista de productos con sus precios, devuelva una nueva lista con los productos que cuestan menos de 50 dólares.
Ver solución
def filtrar_productos_economicos(productos):
return [producto for producto in productos if producto["precio"] < 50]
# Ejemplo de uso
inventario = [
{"nombre": "Teclado", "precio": 45.99},
{"nombre": "Monitor", "precio": 199.99},
{"nombre": "Mouse", "precio": 25.50},
{"nombre": "Disco duro", "precio": 89.99},
{"nombre": "Webcam", "precio": 39.99}
]
productos_economicos = filtrar_productos_economicos(inventario)
print("Productos económicos:")
for producto in productos_economicos:
print(f"- {producto['nombre']}: ${producto['precio']}")
Resultado:
Productos económicos:
- Teclado: $45.99
- Mouse: $25.5
- Webcam: $39.99
Ejercicio 2: Organización de inventario
Crea una función que organice una lista de productos en categorías, utilizando listas anidadas.
Ver solución
def organizar_por_categorias(productos):
categorias = {}
# Agrupar productos por categoría
for producto in productos:
categoria = producto["categoria"]
if categoria not in categorias:
categorias[categoria] = []
categorias[categoria].append(producto["nombre"])
# Convertir a lista de listas
resultado = []
for categoria, productos in categorias.items():
resultado.append([categoria, productos])
return resultado
# Ejemplo de uso
productos = [
{"nombre": "Laptop Dell", "categoria": "Computadoras"},
{"nombre": "Mouse Logitech", "categoria": "Accesorios"},
{"nombre": "Teclado Mecánico", "categoria": "Accesorios"},
{"nombre": "Monitor LG", "categoria": "Monitores"},
{"nombre": "Laptop HP", "categoria": "Computadoras"}
]
inventario_organizado = organizar_por_categorias(productos)
print("Inventario por categorías:")
for categoria in inventario_organizado:
print(f"\n{categoria[0]}:")
for producto in categoria[1]:
print(f" - {producto}")
Resultado:
Inventario por categorías:
Computadoras:
- Laptop Dell
- Laptop HP
Accesorios:
- Mouse Logitech
- Teclado Mecánico
Monitores:
- Monitor LG
Ejercicio 3: Análisis de ventas semanales
Analiza las ventas semanales de una tienda y calcula estadísticas importantes:
# Código para analizar ventas semanales
ventas_semana = {
"Lunes": 1200.50,
"Martes": 890.75,
"Miércoles": 1300.25,
"Jueves": 1500.80,
"Viernes": 2100.00,
"Sábado": 1850.50,
"Domingo": 900.00
}
# Calcular estadísticas
total_ventas = sum(ventas_semana.values())
dias = len(ventas_semana)
promedio = total_ventas / dias
# Encontrar días por encima del promedio
dias_buenos = [dia for dia, venta in ventas_semana.items() if venta > promedio]
# Encontrar mejor y peor día
mejor_dia = max(ventas_semana.items(), key=lambda x: x[1])
peor_dia = min(ventas_semana.items(), key=lambda x: x[1])
# Mostrar resultados
print("📊 ANÁLISIS DE VENTAS SEMANALES")
print(f"Promedio de ventas: ${promedio:.2f}")
print(f"Días por encima del promedio: {', '.join(dias_buenos)}")
print(f"Mejor día: {mejor_dia[0]} (${mejor_dia[1]:.2f})")
print(f"Peor día: {peor_dia[0]} (${peor_dia[1]:.2f})")
Ejemplo de salida esperada:
📊 ANÁLISIS DE VENTAS SEMANALES
Promedio de ventas: $1,428.57
Días por encima del promedio: Jueves, Viernes, Sábado
Mejor día: Viernes ($2,100.00)
Peor día: Domingo ($900.00)
Ejercicio 3: Análisis de ventas semanales
Escribe una función que analice las ventas diarias de una semana y calcule: el día con más ventas, el día con menos ventas, y el promedio de ventas.
Ver solución
def analizar_ventas_semanales(ventas):
dias = ["Lunes", "Martes", "Miércoles", "Jueves", "Viernes", "Sábado", "Domingo"]
# Verificar que tenemos datos para 7 días
if len(ventas) != 7:
return "Error: Se necesitan datos de 7 días"
# Calcular estadísticas
total = sum(ventas)
promedio = total / 7
max_ventas = max(ventas)
min_ventas = min(ventas)
dia_max = dias[ventas.index(max_ventas)]
dia_min = dias[ventas.index(min_ventas)]
# Días por encima del promedio
dias_buenos = [dias[i] for i, venta in enumerate(ventas) if venta > promedio]
return {
"total": total,
"promedio": promedio,
"mejor_dia": dia_max,
"peor_dia": dia_min,
"ventas_max": max_ventas,
"ventas_min": min_ventas,
"dias_buenos": dias_buenos
}
# Ejemplo de uso
ventas_semana = [1200, 980, 1100, 1500, 2100, 1800, 900]
resultado = analizar_ventas_semanales(ventas_semana)
print("\n📊 ANÁLISIS DE VENTAS SEMANALES")
print(f"Total de ventas: ${resultado['total']:,.2f}")
print(f"Promedio diario: ${resultado['promedio']:,.2f}")
print(f"Mejor día: {resultado['mejor_dia']} (${resultado['ventas_max']:,.2f})")
print(f"Peor día: {resultado['peor_dia']} (${resultado['ventas_min']:,.2f})")
print(f"Días por encima del promedio: {', '.join(resultado['dias_buenos'])}")
Resultado:
📊 ANÁLISIS DE VENTAS SEMANALES
Total de ventas: $9,580.00
Promedio diario: $1,368.57
Mejor día: Viernes ($2,100.00)
Peor día: Domingo ($900.00)
Días por encima del promedio: Miércoles, Jueves, Viernes, Sábado
Resumen
Las listas en Python son como estanterías flexibles en tu almacén de datos:
- ✅ Ordenadas: Mantienen el orden de los elementos
- ✅ Modificables: Puedes añadir, quitar o cambiar elementos
- ✅ Indexadas: Acceso directo a cualquier posición
- ✅ Permiten duplicados: El mismo valor puede aparecer varias veces
Operaciones clave que debes recordar:
- Crear:
[],list(), comprensiones de lista - Acceder:
lista[índice],lista[inicio:fin:paso] - Añadir:
append(),insert(),extend() - Eliminar:
remove(),pop(),del,clear() - Buscar:
index(),count(),in - Ordenar:
sort(),sorted(),reverse()
Las listas son una de las herramientas más versátiles en Python, y dominarlas te permitirá resolver una amplia variedad de problemas de programación de manera eficiente.
🧭 Navegación:
- Anterior: Introducción a Estructuras de Datos
- Siguiente: Diccionarios
Capítulos de esta sección:
- Introducción a Estructuras de Datos
- Listas (página actual)
- Diccionarios
- Tuplas
- Conjuntos (Sets)
- Quiz: Estructuras de Datos
Diccionarios: El Sistema de Inventario Inteligente
🧭 Navegación:
¡Bienvenido al sistema de inventario inteligente de nuestro almacén! En este capítulo, aprenderás sobre los diccionarios, una estructura de datos extremadamente poderosa y versátil en Python.
🏷️ El sistema de inventario con etiquetas inteligentes
Imagina que acabas de implementar un sistema de inventario ultra moderno en tu almacén. Este sistema tiene características especiales:
- Cada producto tiene un código único (como un código de barras o QR)
- Puedes encontrar cualquier producto instantáneamente solo con su código
- No importa cuántos productos tengas - la búsqueda siempre es igual de rápida
- Cada código está asociado a toda la información del producto
- Nunca hay códigos duplicados - cada uno es único
En Python, los diccionarios funcionan exactamente así: son colecciones de pares clave-valor donde cada clave es única y te permite acceder instantáneamente a su valor asociado.
# Tu sistema de inventario inteligente en acción
inventario = {
"LAP001": {"nombre": "Laptop Dell", "precio": 800, "stock": 5},
"MOU001": {"nombre": "Mouse Logitech", "precio": 25, "stock": 20},
"TEC001": {"nombre": "Teclado Mecánico", "precio": 60, "stock": 15}
}
print("🏷️ Sistema de inventario inteligente:")
codigo = "LAP001"
producto = inventario[codigo]
print(f"Código {codigo}: {producto['nombre']}")
print(f"Precio: ${producto['precio']}")
print(f"Stock: {producto['stock']} unidades")
# ¡Búsqueda instantánea sin importar el tamaño del inventario!
🔍 Mi perspectiva: Cuando empecé a programar, me costaba entender la diferencia entre listas y diccionarios. Todo cambió cuando me di cuenta de que las listas son como buscar productos recorriendo cada estante, mientras que los diccionarios son como usar un escáner de código de barras: ¡instantáneo! Esta analogía transformó mi forma de estructurar datos.
Características principales de los diccionarios
1. ✅ Pares clave-valor: Cada elemento tiene una etiqueta única
Los diccionarios almacenan información en pares clave-valor, donde la clave es como el código de barras y el valor es toda la información asociada:
empleado = {
"id": "E12345", # clave: "id", valor: "E12345"
"nombre": "Ana García", # clave: "nombre", valor: "Ana García"
"edad": 28, # clave: "edad", valor: 28
"puesto": "Gerente", # clave: "puesto", valor: "Gerente"
"salario": 75000 # clave: "salario", valor: 75000
}
print(f"Empleado: {empleado['nombre']}")
print(f"Puesto: {empleado['puesto']}")
2. ✅ Ordenados por inserción (Python ≥ 3.7): Mantienen el orden
A partir de Python 3.7, los diccionarios mantienen el orden en que se agregaron los elementos:
proceso_pedido = {
"recibir": "Pedido recibido",
"verificar": "Stock verificado",
"procesar": "Pedido procesado",
"enviar": "Pedido enviado"
}
print("Pasos del proceso:")
for paso, estado in proceso_pedido.items():
print(f"- {paso}: {estado}")
# Se imprime en el mismo orden en que se definieron
3. ✅ Modificables (Mutables): Puedes actualizar la información
Puedes añadir, cambiar o eliminar información en cualquier momento:
producto = {"nombre": "Laptop", "precio": 800}
# Actualizar el precio
producto["precio"] = 750
# Añadir información nueva
producto["descuento"] = 0.1
producto["stock"] = 5
# Eliminar información
del producto["descuento"]
print(f"Producto actualizado: {producto}")
4. ✅ Claves únicas: No puede haber códigos duplicados
Si intentas usar la misma clave dos veces, la segunda sobrescribe a la primera:
config = {
"host": "localhost",
"puerto": 8080,
"host": "servidor.com" # Esta sobrescribe la anterior
}
print(config) # {'host': 'servidor.com', 'puerto': 8080}
5. ✅ Acceso súper rápido: Búsqueda instantánea
La búsqueda por clave es O(1) - tiempo constante, sin importar el tamaño del diccionario:
# Igual de rápido con 10 elementos o 10,000,000
gran_inventario = {f"PROD{i}": f"Producto {i}" for i in range(1000000)}
producto = gran_inventario["PROD500000"] # ¡Instantáneo!
print(f"Producto encontrado: {producto}")
Creando tu propio sistema de inventario (diccionarios)
Hay varias formas de crear diccionarios en Python:
Método 1: Diccionario vacío listo para llenar
# Diccionario completamente vacío
inventario = {}
tambien_vacio = dict() # Otra forma de crear un diccionario vacío
Método 2: Diccionario con elementos iniciales
# Diccionario ya con productos
stock = {
"laptop": 15,
"mouse": 50,
"teclado": 30,
"monitor": 8
}
Método 3: Diccionario usando dict() con argumentos nombrados
# Crear diccionario con argumentos nombrados
empleado = dict(nombre="Ana", edad=28, departamento="Ventas")
print(empleado) # {'nombre': 'Ana', 'edad': 28, 'departamento': 'Ventas'}
Método 4: Diccionario a partir de pares clave-valor
# Crear diccionario a partir de lista de tuplas (clave, valor)
datos = [("nombre", "Carlos"), ("edad", 35), ("ciudad", "Madrid")]
persona = dict(datos)
print(persona) # {'nombre': 'Carlos', 'edad': 35, 'ciudad': 'Madrid'}
Método 5: Diccionario por comprensión
# Generar diccionario con una fórmula
cuadrados = {x: x**2 for x in range(1, 6)}
print(cuadrados) # {1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
Método 6: Diccionario con zip()
# Combinar dos listas en un diccionario
claves = ["nombre", "edad", "puesto"]
valores = ["María", 30, "Analista"]
empleado = dict(zip(claves, valores))
print(empleado) # {'nombre': 'María', 'edad': 30, 'puesto': 'Analista'}
Operaciones básicas con diccionarios
1. Accediendo a la información
producto = {"nombre": "Laptop", "precio": 800, "stock": 5}
# Acceso directo (puede causar error si la clave no existe)
nombre = producto["nombre"]
print(f"Nombre: {nombre}")
# get() - acceso seguro con valor por defecto
precio = producto.get("precio", 0) # 800
descuento = producto.get("descuento", 0) # 0 (valor por defecto)
print(f"Precio: ${precio}, Descuento: {descuento}%")
# setdefault() - obtener o establecer valor por defecto
garantia = producto.setdefault("garantia", "1 año") # Si no existe, la crea
print(f"Garantía: {garantia}")
print(producto) # Ahora incluye 'garantia': '1 año'
🔍 Mi perspectiva: Siempre recomiendo usar get() en lugar de acceso directo con corchetes cuando no estás 100% seguro de que la clave existe. Me ha salvado de muchos errores en producción, especialmente cuando trabajo con datos que vienen de APIs externas.
2. Explorando el inventario
producto = {"nombre": "Laptop", "precio": 800, "stock": 5, "categoria": "Electrónicos"}
# keys() - obtener todas las claves
claves = producto.keys()
print(f"Información disponible: {list(claves)}")
# values() - obtener todos los valores
valores = producto.values()
print(f"Valores: {list(valores)}")
# items() - obtener pares clave-valor
pares = producto.items()
print(f"Pares clave-valor: {list(pares)}")
# Iteración sobre el diccionario
print("\nDetalles del producto:")
for clave, valor in producto.items():
print(f"- {clave}: {valor}")
3. Actualizando el inventario
inventario = {"laptop": 10, "mouse": 25}
# Agregar/modificar elementos
inventario["teclado"] = 15 # Agregar nuevo
inventario["laptop"] = 12 # Modificar existente
# update() - actualizar con otro diccionario
nuevos_productos = {"monitor": 8, "webcam": 20}
inventario.update(nuevos_productos)
# update() con argumentos nombrados
inventario.update(altavoces=12, microfono=8)
print(f"Inventario actualizado: {inventario}")
4. Eliminando productos
inventario = {"laptop": 10, "mouse": 25, "teclado": 15, "monitor": 8, "webcam": 20}
# pop() - eliminar y devolver valor
stock_mouse = inventario.pop("mouse")
print(f"Stock de mouse eliminado: {stock_mouse}")
print(f"Inventario: {inventario}")
# pop() con valor por defecto (no genera error si la clave no existe)
stock_tablet = inventario.pop("tablet", 0)
print(f"Stock de tablet: {stock_tablet}")
# popitem() - eliminar y devolver último par (Python ≥ 3.7)
ultimo_item = inventario.popitem()
print(f"Último item eliminado: {ultimo_item}")
# del - eliminar por clave
del inventario["teclado"]
print(f"Después de eliminar teclado: {inventario}")
# clear() - vaciar completamente
inventario_temp = {"a": 1, "b": 2}
inventario_temp.clear()
print(f"Inventario vacío: {inventario_temp}")
Técnicas avanzadas para gestionar tu inventario
1. Diccionarios anidados: Información detallada y estructurada
Los diccionarios anidados te permiten organizar información compleja de manera jerárquica:
# Sistema de inventario con categorías y productos
inventario_completo = {
"electrónicos": {
"laptops": {
"LAP001": {"nombre": "Laptop Dell XPS", "precio": 1200, "stock": 5},
"LAP002": {"nombre": "MacBook Pro", "precio": 1800, "stock": 3}
},
"smartphones": {
"CEL001": {"nombre": "iPhone 13", "precio": 999, "stock": 10},
"CEL002": {"nombre": "Samsung S21", "precio": 850, "stock": 8}
}
},
"muebles": {
"sillas": {
"SIL001": {"nombre": "Silla Ergonómica", "precio": 250, "stock": 15}
},
"mesas": {
"MES001": {"nombre": "Mesa de Oficina", "precio": 350, "stock": 7}
}
}
}
# Acceder a información anidada
laptop_dell = inventario_completo["electrónicos"]["laptops"]["LAP001"]
print(f"Producto: {laptop_dell['nombre']}, Precio: ${laptop_dell['precio']}")
# Añadir nuevo producto a una categoría existente
inventario_completo["electrónicos"]["smartphones"]["CEL003"] = {
"nombre": "Google Pixel",
"precio": 799,
"stock": 12
}
# Añadir nueva categoría
inventario_completo["accesorios"] = {
"auriculares": {
"AUR001": {"nombre": "Auriculares Bluetooth", "precio": 89, "stock": 20}
}
}
2. Diccionarios por comprensión: Generación automática
Las comprensiones de diccionarios te permiten crear y transformar diccionarios de manera concisa:
# Crear diccionario de precios con IVA incluido
productos = {"laptop": 800, "mouse": 25, "teclado": 60, "monitor": 300}
productos_con_iva = {nombre: precio * 1.21 for nombre, precio in productos.items()}
print(f"Precios con IVA: {productos_con_iva}")
# Filtrar productos caros
productos_caros = {nombre: precio for nombre, precio in productos.items() if precio > 100}
print(f"Productos caros: {productos_caros}")
# Crear diccionario con formato específico
nombres = ["Ana", "Carlos", "María", "Pedro"]
ids_empleados = {nombre: f"EMP{i+1:03d}" for i, nombre in enumerate(nombres)}
print(f"IDs de empleados: {ids_empleados}")
3. Fusión y comparación de diccionarios
# Fusionar diccionarios (Python ≥ 3.9)
inventario_sede_a = {"laptop": 10, "mouse": 20, "teclado": 15}
inventario_sede_b = {"monitor": 8, "laptop": 5, "webcam": 12}
# Usando el operador | (Python 3.9+)
inventario_total = inventario_sede_a | inventario_sede_b
print(f"Inventario total: {inventario_total}")
# En versiones anteriores
from collections import ChainMap
inventario_combinado = dict(ChainMap(inventario_sede_b, inventario_sede_a))
print(f"Inventario combinado: {inventario_combinado}")
# Comparar diccionarios
config_predeterminada = {"tema": "claro", "notificaciones": True, "idioma": "es"}
config_usuario = {"tema": "oscuro", "idioma": "es"}
# Encontrar diferencias
diferencias = {k: config_usuario[k] for k in config_usuario
if k in config_predeterminada and config_usuario[k] != config_predeterminada[k]}
print(f"Configuraciones personalizadas: {diferencias}")
4. Copia de diccionarios: Superficial vs. Profunda
original = {"a": 1, "b": [2, 3, 4], "c": {"x": 10}}
# copy() - copia superficial
copia_superficial = original.copy()
copia_superficial["a"] = 999
copia_superficial["b"].append(5) # ¡Modifica el original también!
print(f"Original después de modificar copia superficial: {original}")
# La lista en 'b' se modificó en ambos diccionarios
# deepcopy() - copia profunda
import copy
copia_profunda = copy.deepcopy(original)
copia_profunda["b"].append(6) # No afecta el original
print(f"Original después de modificar copia profunda: {original}")
# La lista en 'b' no se modificó en el original
Aplicaciones prácticas de los diccionarios
1. Sistema de gestión de inventario
def gestionar_inventario():
"""Sistema simple de gestión de inventario usando diccionarios"""
# Inventario inicial
inventario = {
"LAP001": {"nombre": "Laptop", "precio": 800, "stock": 5, "categoria": "Electrónicos"},
"MOU001": {"nombre": "Mouse", "precio": 25, "stock": 10, "categoria": "Accesorios"},
"TEC001": {"nombre": "Teclado", "precio": 60, "stock": 8, "categoria": "Accesorios"}
}
# Función para añadir producto
def agregar_producto(codigo, nombre, precio, stock, categoria):
if codigo in inventario:
print(f"⚠️ El código {codigo} ya existe. Use otro código.")
return False
inventario[codigo] = {
"nombre": nombre,
"precio": precio,
"stock": stock,
"categoria": categoria
}
print(f"✅ Producto {codigo} ({nombre}) agregado correctamente.")
return True
# Función para actualizar stock
def actualizar_stock(codigo, cantidad):
if codigo not in inventario:
print(f"❌ El código {codigo} no existe en el inventario.")
return False
inventario[codigo]["stock"] += cantidad
print(f"✅ Stock de {inventario[codigo]['nombre']} actualizado a {inventario[codigo]['stock']} unidades.")
return True
# Función para mostrar inventario
def mostrar_inventario():
print("\n📦 INVENTARIO ACTUAL:")
print("-" * 60)
print(f"{'CÓDIGO':<10}{'PRODUCTO':<20}{'PRECIO':<10}{'STOCK':<10}{'CATEGORÍA':<15}")
print("-" * 60)
for codigo, datos in inventario.items():
print(f"{codigo:<10}{datos['nombre']:<20}${datos['precio']:<9}{datos['stock']:<10}{datos['categoria']:<15}")
# Función para buscar por categoría
def buscar_por_categoria(categoria):
productos = {codigo: datos for codigo, datos in inventario.items()
if datos["categoria"].lower() == categoria.lower()}
if not productos:
print(f"❌ No hay productos en la categoría '{categoria}'.")
return
print(f"\n🔍 Productos en categoría '{categoria}':")
for codigo, datos in productos.items():
print(f" • {datos['nombre']} (${datos['precio']}) - Stock: {datos['stock']}")
# Demostración del sistema
mostrar_inventario()
# Agregar nuevo producto
agregar_producto("MON001", "Monitor 24\"", 200, 3, "Electrónicos")
# Actualizar stock
actualizar_stock("MOU001", 5) # Añadir 5 unidades
actualizar_stock("TEC001", -2) # Restar 2 unidades
# Mostrar inventario actualizado
mostrar_inventario()
# Buscar por categoría
buscar_por_categoria("Accesorios")
# Ejecutar el sistema
gestionar_inventario()
2. Análisis de datos de ventas
def analizar_ventas(datos_ventas):
"""Analiza datos de ventas agrupados por diferentes criterios"""
# Inicializar diccionarios para análisis
ventas_por_mes = {}
ventas_por_producto = {}
ventas_por_vendedor = {}
# Procesar cada venta
for venta in datos_ventas:
fecha = venta["fecha"]
mes = fecha[:7] # "2024-01"
producto = venta["producto"]
vendedor = venta["vendedor"]
total = venta["total"]
# Agrupar por mes
if mes not in ventas_por_mes:
ventas_por_mes[mes] = {"total": 0, "cantidad": 0}
ventas_por_mes[mes]["total"] += total
ventas_por_mes[mes]["cantidad"] += 1
# Agrupar por producto
if producto not in ventas_por_producto:
ventas_por_producto[producto] = {"total": 0, "cantidad": 0}
ventas_por_producto[producto]["total"] += total
ventas_por_producto[producto]["cantidad"] += 1
# Agrupar por vendedor
if vendedor not in ventas_por_vendedor:
ventas_por_vendedor[vendedor] = {"total": 0, "cantidad": 0}
ventas_por_vendedor[vendedor]["total"] += total
ventas_por_vendedor[vendedor]["cantidad"] += 1
# Generar reporte
print("\n📊 ANÁLISIS DE VENTAS")
print("=" * 50)
# Reporte por mes
print("\n📅 VENTAS POR MES:")
for mes, datos in sorted(ventas_por_mes.items()):
promedio = datos["total"] / datos["cantidad"]
print(f" {mes}: ${datos['total']:,.2f} ({datos['cantidad']} ventas, promedio: ${promedio:.2f})")
# Top 3 productos
top_productos = sorted(
ventas_por_producto.items(),
key=lambda x: x[1]["total"],
reverse=True
)[:3]
print(f"\n🏆 TOP 3 PRODUCTOS:")
for i, (producto, datos) in enumerate(top_productos, 1):
print(f" {i}. {producto}: ${datos['total']:,.2f} ({datos['cantidad']} ventas)")
# Top vendedores
top_vendedores = sorted(
ventas_por_vendedor.items(),
key=lambda x: x[1]["total"],
reverse=True
)
print(f"\n👑 VENDEDORES POR DESEMPEÑO:")
for i, (vendedor, datos) in enumerate(top_vendedores, 1):
print(f" {i}. {vendedor}: ${datos['total']:,.2f} ({datos['cantidad']} ventas)")
# Datos de ejemplo
ventas_ejemplo = [
{"fecha": "2024-01-15", "producto": "Laptop", "vendedor": "Ana", "total": 1200},
{"fecha": "2024-01-20", "producto": "Mouse", "vendedor": "Carlos", "total": 45},
{"fecha": "2024-01-25", "producto": "Laptop", "vendedor": "Ana", "total": 1200},
{"fecha": "2024-02-10", "producto": "Teclado", "vendedor": "María", "total": 120},
{"fecha": "2024-02-15", "producto": "Monitor", "vendedor": "Carlos", "total": 400},
{"fecha": "2024-02-20", "producto": "Laptop", "vendedor": "Ana", "total": 1200},
]
# Realizar análisis
analizar_ventas(ventas_ejemplo)
Consejos y mejores prácticas
1. Verificación de claves
# ❌ Propenso a errores
def procesar_usuario(usuario):
nombre = usuario["nombre"] # KeyError si no existe
email = usuario["email"] # KeyError si no existe
# ...
# ✅ Más seguro
def procesar_usuario_seguro(usuario):
if "nombre" in usuario and "email" in usuario:
# Procesar usuario
print(f"Procesando usuario: {usuario['nombre']}")
else:
print("Datos de usuario incompletos")
2. Uso de defaultdict para valores por defecto
from collections import defaultdict
# Contador de palabras
texto = "este es un ejemplo de texto este texto es un ejemplo"
palabras = texto.split()
# ❌ Forma tradicional
contador = {}
for palabra in palabras:
if palabra in contador:
contador[palabra] += 1
else:
contador[palabra] = 1
# ✅ Con defaultdict
contador_mejorado = defaultdict(int)
for palabra in palabras:
contador_mejorado[palabra] += 1
print(f"Contador: {dict(contador_mejorado)}")
3. Evitar modificar durante la iteración
# ❌ Error: modificar diccionario durante iteración
productos = {"laptop": 800, "mouse": 25, "teclado": 60}
for producto, precio in productos.items():
if precio < 100:
del productos[producto] # ¡Error! Modifica durante iteración
# ✅ Correcto: crear nuevo diccionario
productos = {"laptop": 800, "mouse": 25, "teclado": 60}
productos_caros = {p: precio for p, precio in productos.items() if precio >= 100}
print(f"Productos caros: {productos_caros}")
🔍 Mi perspectiva: Uno de los errores más comunes que veo en mis estudiantes es modificar un diccionario mientras lo recorren. Esto puede causar comportamientos impredecibles y errores difíciles de depurar. Siempre recomiendo crear un nuevo diccionario con los elementos filtrados en lugar de modificar el original durante la iteración.
Comprueba tu comprensión
Ejercicio 1: Contador de frecuencia
Escribe una función que reciba una cadena de texto y devuelva un diccionario con la frecuencia de cada carácter.
Ver solución
def contar_caracteres(texto):
"""Cuenta la frecuencia de cada carácter en un texto."""
frecuencia = {}
for caracter in texto:
if caracter in frecuencia:
frecuencia[caracter] += 1
else:
frecuencia[caracter] = 1
return frecuencia
# Ejemplo de uso
texto = "programación en python"
resultado = contar_caracteres(texto)
print("Frecuencia de caracteres:")
for caracter, cantidad in sorted(resultado.items()):
print(f"'{caracter}': {cantidad}")
Resultado:
Frecuencia de caracteres:
' ': 2
'a': 2
'c': 1
'e': 1
'g': 1
'h': 1
'i': 1
'm': 1
'n': 2
'o': 2
'p': 2
'r': 2
't': 1
'y': 1
'ó': 1
Ejercicio 2: Fusión de inventarios
Crea una función que combine dos diccionarios de inventario, sumando las cantidades de productos que aparecen en ambos.
Ver solución
def fusionar_inventarios(inv1, inv2):
"""Fusiona dos inventarios sumando las cantidades de productos comunes."""
resultado = inv1.copy() # Comenzar con una copia del primer inventario
# Añadir o actualizar con elementos del segundo inventario
for producto, cantidad in inv2.items():
if producto in resultado:
resultado[producto] += cantidad # Sumar si ya existe
else:
resultado[producto] = cantidad # Añadir si es nuevo
return resultado
# Ejemplo de uso
inventario_almacen1 = {"laptop": 5, "mouse": 10, "teclado": 8}
inventario_almacen2 = {"monitor": 4, "laptop": 3, "impresora": 2}
inventario_total = fusionar_inventarios(inventario_almacen1, inventario_almacen2)
print("Inventario fusionado:")
for producto, cantidad in sorted(inventario_total.items()):
print(f"- {producto}: {cantidad} unidades")
Resultado:
Inventario fusionado:
- impresora: 2 unidades
- laptop: 8 unidades
- monitor: 4 unidades
- mouse: 10 unidades
- teclado: 8 unidades
Ejercicio 2: Fusión de inventarios
Combina dos inventarios en uno solo, sumando las cantidades de productos duplicados:
# Código para fusionar inventarios
inventario_tienda1 = {
"laptop": 5,
"mouse": 10,
"teclado": 8,
"monitor": 4
}
inventario_tienda2 = {
"laptop": 3,
"impresora": 2,
"mouse": 0,
"teclado": 0
}
# Fusionar inventarios
inventario_fusionado = {}
# Agregar todos los productos de la tienda 1
for producto, cantidad in inventario_tienda1.items():
inventario_fusionado[producto] = cantidad
# Agregar o actualizar con productos de la tienda 2
for producto, cantidad in inventario_tienda2.items():
if producto in inventario_fusionado:
inventario_fusionado[producto] += cantidad
else:
inventario_fusionado[producto] = cantidad
# Mostrar inventario fusionado
print("Inventario fusionado:")
for producto, cantidad in sorted(inventario_fusionado.items()):
print(f"- {producto}: {cantidad} unidades")
Ejemplo de salida esperada:
Inventario fusionado:
- impresora: 2 unidades
- laptop: 8 unidades
- monitor: 4 unidades
- mouse: 10 unidades
- teclado: 8 unidades
Ejercicio 3: Análisis de ventas por categoría
Escribe una función que analice un conjunto de ventas y calcule el total vendido por categoría de producto.
Ver solución
# Código para analizar ventas por categoría
def analizar_ventas_por_categoria(ventas, productos):
"""
Analiza ventas y calcula totales por categoría.
Args:
ventas: Lista de diccionarios con información de ventas
productos: Diccionario con información de productos (incluye categoría)
"""
# Inicializar diccionario para totales por categoría
totales_por_categoria = {}
# Procesar cada venta
for venta in ventas:
producto_id = venta["producto_id"]
cantidad = venta["cantidad"]
precio = venta["precio"]
# Obtener categoría del producto
if producto_id in productos:
categoria = productos[producto_id]["categoria"]
# Calcular total de esta venta
total_venta = cantidad * precio
# Actualizar total de la categoría
if categoria in totales_por_categoria:
totales_por_categoria[categoria] += total_venta
else:
totales_por_categoria[categoria] = total_venta
# Mostrar resultados
print("Ventas por categoría:")
for categoria, total in sorted(totales_por_categoria.items()):
print(f"- {categoria}: ${total:,.2f}")
return totales_por_categoria
# Datos de ejemplo
productos = {
"p1": {"nombre": "Laptop", "categoria": "Electrónicos"},
"p2": {"nombre": "Mouse", "categoria": "Accesorios"},
"p3": {"nombre": "Monitor", "categoria": "Periféricos"},
"p4": {"nombre": "Teclado", "categoria": "Accesorios"},
"p5": {"nombre": "Smartphone", "categoria": "Electrónicos"}
}
ventas = [
{"producto_id": "p1", "cantidad": 3, "precio": 1200.00},
{"producto_id": "p2", "cantidad": 5, "precio": 25.00},
{"producto_id": "p3", "cantidad": 2, "precio": 200.00},
{"producto_id": "p4", "cantidad": 7, "precio": 45.00},
{"producto_id": "p5", "cantidad": 1, "precio": 300.00}
]
# Ejecutar análisis
analizar_ventas_por_categoria(ventas, productos)
Ejemplo de salida esperada:
Ventas por categoría:
- Accesorios: $365.00
- Electrónicos: $3,900.00
- Periféricos: $400.00
def analizar_ventas_por_categoria(ventas, productos):
"""
Analiza ventas y calcula totales por categoría.
Args:
ventas: Lista de diccionarios con información de ventas
productos: Diccionario con información de productos (incluye categoría)
Returns:
Diccionario con totales por categoría
"""
ventas_por_categoria = {}
for venta in ventas:
codigo_producto = venta["producto"]
cantidad = venta["cantidad"]
# Obtener información del producto
if codigo_producto in productos:
producto_info = productos[codigo_producto]
categoria = producto_info["categoria"]
precio = producto_info["precio"]
# Calcular importe de esta venta
importe = precio * cantidad
# Actualizar total de la categoría
if categoria in ventas_por_categoria:
ventas_por_categoria[categoria] += importe
else:
ventas_por_categoria[categoria] = importe
return ventas_por_categoria
# Datos de ejemplo
productos = {
"P001": {"nombre": "Laptop", "precio": 1200, "categoria": "Electrónicos"},
"P002": {"nombre": "Mouse", "precio": 25, "categoria": "Accesorios"},
"P003": {"nombre": "Monitor", "precio": 300, "categoria": "Electrónicos"},
"P004": {"nombre": "Teclado", "precio": 80, "categoria": "Accesorios"},
"P005": {"nombre": "Impresora", "precio": 200, "categoria": "Periféricos"}
}
ventas = [
{"producto": "P001", "cantidad": 2, "fecha": "2024-01-15"},
{"producto": "P002", "cantidad": 5, "fecha": "2024-01-16"},
{"producto": "P003", "cantidad": 1, "fecha": "2024-01-20"},
{"producto": "P001", "cantidad": 1, "fecha": "2024-02-05"},
{"producto": "P004", "cantidad": 3, "fecha": "2024-02-10"},
{"producto": "P005", "cantidad": 2, "fecha": "2024-02-15"}
]
resultado = analizar_ventas_por_categoria(ventas, productos)
print("\nVentas por categoría:")
for categoria, total in sorted(resultado.items(), key=lambda x: x[1], reverse=True):
print(f"- {categoria}: ${total:,.2f}")
Resultado:
Ventas por categoría:
- Electrónicos: $3,900.00
- Periféricos: $400.00
Ejercicio 3: Análisis de ventas por categoría
# Ejemplo de salida esperada
print("Ventas por categoría:")
print("- Electrónicos: $3,900.00")
print("- Accesorios: $365.00")
print("- Periféricos: $400.00")
Resumen
Los diccionarios en Python son como un sistema de inventario inteligente en tu almacén de datos:
- ✅ Pares clave-valor: Cada elemento tiene una etiqueta única (clave) y un valor asociado
- ✅ Acceso instantáneo: Búsqueda por clave extremadamente rápida (O(1))
- ✅ Modificables: Puedes añadir, cambiar o eliminar elementos fácilmente
- ✅ Claves únicas: No puede haber claves duplicadas
- ✅ Ordenados: Mantienen el orden de inserción (desde Python 3.7)
Operaciones clave que debes recordar:
- Crear:
{},dict(), comprensiones de diccionario - Acceder:
dict[key],get(),setdefault() - Modificar:
dict[key] = value,update(),pop(),del - Iterar:
keys(),values(),items()
Los diccionarios son una de las estructuras de datos más poderosas en Python, y dominarlos te permitirá organizar y manipular datos de manera eficiente en tus aplicaciones.
🧭 Navegación:
Capítulos de esta sección:
- Introducción a Estructuras de Datos
- Listas
- Diccionarios (página actual)
- Tuplas
- Conjuntos (Sets)
- Quiz: Estructuras de Datos
Tuplas en Python
🧭 Navegación:
- Anterior: Diccionarios
- Siguiente: Conjuntos (Sets)
- Volver al Índice de Estructuras de Datos
Introducción a las Tuplas
Imagina que en tu almacén tienes una sección especial para paquetes sellados que contienen productos que no deben ser alterados una vez empaquetados. Estos paquetes tienen una etiqueta de seguridad que indica “No modificar” y están diseñados para mantener su integridad durante todo el proceso logístico.
Las tuplas en Python funcionan exactamente así: son colecciones ordenadas de elementos que, una vez creadas, no pueden ser modificadas. Esta característica las hace perfectas para almacenar datos que deben permanecer constantes a lo largo de la ejecución de tu programa.
🔍 Perspectiva personal: Cuando trabajo con datos que no deben cambiar (como coordenadas geográficas, configuraciones fijas o valores de referencia), siempre uso tuplas. Me dan la seguridad de que estos valores permanecerán intactos, evitando errores accidentales en mi código.
Creando Tuplas
Crear una tupla es similar a crear una lista, pero utilizamos paréntesis () en lugar de corchetes []:
# Tupla de productos no modificables
productos_basicos = ("arroz", "frijoles", "aceite", "sal")
# Tupla de coordenadas (x, y, z)
ubicacion_almacen = (40.7128, -74.0060, 10)
# Tupla de información de contacto
contacto_emergencia = ("Juan Pérez", "Supervisor", "555-123-4567")
También puedes crear una tupla sin paréntesis, simplemente separando los elementos con comas:
# Esto también es una tupla
dimensiones = 20, 30, 15 # (ancho, alto, profundidad)
print(type(dimensiones)) # <class 'tuple'>
Tupla de un solo elemento
Para crear una tupla con un solo elemento, necesitas incluir una coma después del elemento:
# Esto NO es una tupla, es un string
no_es_tupla = ("único elemento")
print(type(no_es_tupla)) # <class 'str'>
# Esto SÍ es una tupla
es_tupla = ("único elemento",) # ¡Nota la coma!
print(type(es_tupla)) # <class 'tuple'>
🔍 Perspectiva personal: La primera vez que intenté crear una tupla de un solo elemento, olvidé la coma y pasé horas depurando mi código. ¡No cometas mi error!
Tupla vacía
También puedes crear una tupla vacía:
tupla_vacia = ()
print(type(tupla_vacia)) # <class 'tuple'>
Accediendo a los Elementos de una Tupla
Al igual que las listas, puedes acceder a los elementos de una tupla mediante índices:
productos = ("laptop", "monitor", "teclado", "mouse", "cables")
# Acceder al primer elemento (índice 0)
print(productos[0]) # "laptop"
# Acceder al último elemento (índice -1)
print(productos[-1]) # "cables"
# Acceder a un rango de elementos (slicing)
print(productos[1:3]) # ("monitor", "teclado")
Inmutabilidad: La Característica Clave
La característica más importante de las tuplas es que son inmutables, lo que significa que no puedes modificar, añadir o eliminar elementos después de crear la tupla:
coordenadas = (10, 20, 30)
# Intentar modificar un elemento
try:
coordenadas[0] = 15 # Esto generará un error
except TypeError as e:
print(f"Error: {e}") # Error: 'tuple' object does not support item assignment
# Intentar añadir un elemento
try:
coordenadas.append(40) # Esto generará un error
except AttributeError as e:
print(f"Error: {e}") # Error: 'tuple' object has no attribute 'append'
🔍 Perspectiva personal: La inmutabilidad puede parecer una limitación, pero en realidad es una ventaja. Cuando trabajo en equipos grandes, usar tuplas para datos críticos me asegura que nadie (¡ni siquiera yo mismo!) pueda modificarlos accidentalmente.
Operaciones con Tuplas
Aunque no puedes modificar una tupla, puedes realizar varias operaciones con ellas:
1. Concatenación
Puedes unir dos o más tuplas para crear una nueva:
productos_oficina = ("laptop", "monitor", "teclado")
accesorios = ("mouse", "webcam", "auriculares")
# Concatenar tuplas
todos_productos = productos_oficina + accesorios
print(todos_productos) # ("laptop", "monitor", "teclado", "mouse", "webcam", "auriculares")
2. Multiplicación
Puedes repetir una tupla multiplicándola por un número:
patron = (1, 2, 3)
patron_repetido = patron * 3
print(patron_repetido) # (1, 2, 3, 1, 2, 3, 1, 2, 3)
3. Verificar si un elemento existe
productos = ("laptop", "monitor", "teclado", "mouse")
print("teclado" in productos) # True
print("impresora" in productos) # False
4. Longitud, mínimo, máximo y suma
numeros = (10, 5, 8, 3, 12)
print(len(numeros)) # 5
print(min(numeros)) # 3
print(max(numeros)) # 12
print(sum(numeros)) # 38
Desempaquetado de Tuplas
Una de las características más útiles de las tuplas es el desempaquetado, que te permite asignar los elementos de una tupla a variables individuales:
# Desempaquetado básico
dimensiones = (100, 50, 25)
ancho, alto, profundidad = dimensiones
print(f"Ancho: {ancho} cm") # Ancho: 100 cm
print(f"Alto: {alto} cm") # Alto: 50 cm
print(f"Profundidad: {profundidad} cm") # Profundidad: 25 cm
El desempaquetado es especialmente útil para intercambiar valores sin necesidad de una variable temporal:
# Intercambio de valores
a = 5
b = 10
print(f"Antes - a: {a}, b: {b}") # Antes - a: 5, b: 10
# Intercambio usando tuplas
a, b = b, a
print(f"Después - a: {a}, b: {b}") # Después - a: 10, b: 5
Desempaquetado con asterisco
Si tienes una tupla con más elementos de los que quieres desempaquetar individualmente, puedes usar el operador * para recoger los elementos restantes en una lista:
inventario = ("Laptop Dell", 10, 899.99, "Disponible", "A-12", "Electrónicos")
# Desempaquetar los primeros 3 elementos y recoger el resto
producto, cantidad, precio, *detalles = inventario
print(f"Producto: {producto}") # Producto: Laptop Dell
print(f"Cantidad: {cantidad}") # Cantidad: 10
print(f"Precio: ${precio}") # Precio: $899.99
print(f"Detalles adicionales: {detalles}") # Detalles adicionales: ['Disponible', 'A-12', 'Electrónicos']
También puedes usar el operador * en cualquier posición:
# El asterisco puede estar en cualquier posición
numeros = (1, 2, 3, 4, 5, 6, 7)
primero, *medio, ultimo = numeros
print(f"Primero: {primero}") # Primero: 1
print(f"Medio: {medio}") # Medio: [2, 3, 4, 5, 6]
print(f"Último: {ultimo}") # Último: 7
🔍 Perspectiva personal: El desempaquetado con asterisco es una de mis características favoritas de Python. Me permite escribir código más limpio y expresivo, especialmente cuando trabajo con funciones que devuelven múltiples valores.
Tuplas vs Listas: ¿Cuándo usar cada una?
| Característica | Tuplas | Listas |
|---|---|---|
| Mutabilidad | Inmutables (no se pueden modificar) | Mutables (se pueden modificar) |
| Sintaxis | Paréntesis () | Corchetes [] |
| Rendimiento | Ligeramente más rápidas | Ligeramente más lentas |
| Uso de memoria | Menor | Mayor |
| Casos de uso | Datos que no deben cambiar | Datos que necesitan ser modificados |
Usa tuplas cuando:
- Necesites datos inmutables: Valores que no deben cambiar, como coordenadas, configuraciones o constantes.
- Quieras mejorar el rendimiento: Las tuplas son ligeramente más eficientes que las listas.
- Necesites claves para diccionarios: A diferencia de las listas, las tuplas pueden ser usadas como claves en diccionarios.
- Quieras comunicar intención: Usar una tupla indica a otros programadores que esos datos no deben cambiar.
Usa listas cuando:
- Necesites modificar la colección: Añadir, eliminar o cambiar elementos.
- Trabajes con datos homogéneos: Colecciones de elementos del mismo tipo que pueden crecer o reducirse.
- Necesites operaciones específicas de listas: Como
sort(),append(),extend(), etc.
Tuplas como Claves de Diccionarios
A diferencia de las listas, las tuplas pueden ser usadas como claves en diccionarios porque son inmutables:
# Usando tuplas como claves en un diccionario
# Cada clave es una coordenada (x, y)
ubicaciones = {
(0, 0): "Entrada principal",
(10, 5): "Área de electrónicos",
(20, 15): "Almacén de alimentos",
(30, 30): "Salida de emergencia"
}
# Acceder a un valor usando una tupla como clave
print(ubicaciones[(10, 5)]) # "Área de electrónicos"
# Intentar usar una lista como clave generará un error
try:
ubicaciones_error = {[0, 0]: "Esto no funcionará"}
except TypeError as e:
print(f"Error: {e}") # Error: unhashable type: 'list'
Métodos de Tuplas
Las tuplas tienen menos métodos que las listas debido a su inmutabilidad, pero aún así ofrecen algunos métodos útiles:
productos = ("laptop", "monitor", "teclado", "mouse", "laptop", "cables")
# count(): Contar ocurrencias de un elemento
print(productos.count("laptop")) # 2
# index(): Encontrar la posición de un elemento
print(productos.index("teclado")) # 2
# Intentar encontrar un elemento que no existe generará un error
try:
print(productos.index("impresora"))
except ValueError as e:
print(f"Error: {e}") # Error: tuple.index(x): x not in tuple
Tuplas Anidadas
Al igual que las listas, las tuplas pueden contener otras tuplas:
# Tupla de productos con sus detalles (nombre, precio, stock)
inventario = (
("Laptop", 999.99, 10),
("Monitor", 299.50, 15),
("Teclado", 89.99, 30),
("Mouse", 24.99, 50)
)
# Acceder a elementos de tuplas anidadas
print(f"Producto: {inventario[0][0]}") # Producto: Laptop
print(f"Precio: ${inventario[0][1]}") # Precio: $999.99
print(f"Stock: {inventario[0][2]} unidades") # Stock: 10 unidades
# Iterar sobre tuplas anidadas
print("\nInventario completo:")
for producto, precio, stock in inventario:
print(f"{producto}: ${precio:.2f} - {stock} unidades disponibles")
Conversión entre Tuplas y Listas
Puedes convertir fácilmente entre tuplas y listas:
# Convertir una lista a tupla
lista_productos = ["laptop", "monitor", "teclado", "mouse"]
tupla_productos = tuple(lista_productos)
print(tupla_productos) # ("laptop", "monitor", "teclado", "mouse")
# Convertir una tupla a lista
tupla_numeros = (1, 2, 3, 4, 5)
lista_numeros = list(tupla_numeros)
print(lista_numeros) # [1, 2, 3, 4, 5]
🔍 Perspectiva personal: A veces necesito la flexibilidad de modificar una colección, pero también quiero asegurarme de que ciertos datos permanezcan inmutables. En estos casos, convierto entre listas y tuplas según sea necesario.
Aplicaciones Prácticas de las Tuplas
1. Registro de datos inmutables
# Registro de transacciones (id, fecha, monto, tipo)
transacciones = [
(1001, "2023-07-15", 1299.99, "venta"),
(1002, "2023-07-15", 499.50, "venta"),
(1003, "2023-07-16", 1299.99, "devolución"),
(1004, "2023-07-17", 899.99, "venta")
]
# Calcular el total de ventas
total_ventas = 0
for transaccion in transacciones:
if transaccion[3] == "venta":
total_ventas += transaccion[2]
elif transaccion[3] == "devolución":
total_ventas -= transaccion[2]
print(f"Total de ventas: ${total_ventas:.2f}") # Total de ventas: $1799.98
2. Retorno múltiple de funciones
def obtener_estadisticas(numeros):
"""Calcula varias estadísticas de una lista de números."""
total = sum(numeros)
promedio = total / len(numeros)
minimo = min(numeros)
maximo = max(numeros)
return (total, promedio, minimo, maximo)
# Usar la función y desempaquetar los resultados
ventas_semana = [1200, 1500, 900, 1100, 1800, 2000, 1300]
total, promedio, minimo, maximo = obtener_estadisticas(ventas_semana)
print(f"Ventas totales: ${total}")
print(f"Promedio diario: ${promedio:.2f}")
print(f"Venta mínima: ${minimo}")
print(f"Venta máxima: ${maximo}")
3. Coordenadas y puntos geométricos
# Representar puntos en un espacio 3D
puntos = [
(0, 0, 0), # Origen
(10, 0, 0), # 10 unidades en el eje X
(0, 10, 0), # 10 unidades en el eje Y
(0, 0, 10) # 10 unidades en el eje Z
]
# Calcular la distancia desde el origen a cada punto
import math
def distancia_desde_origen(punto):
x, y, z = punto
return math.sqrt(x**2 + y**2 + z**2)
for i, punto in enumerate(puntos):
print(f"Distancia del punto {i} al origen: {distancia_desde_origen(punto):.2f} unidades")
Comprueba tu comprensión
Vamos a poner a prueba tu comprensión de las tuplas con algunos ejercicios prácticos:
Ejercicio 1: Creación y acceso a tuplas
¿Qué imprimirá el siguiente código?
datos = ("Python", 3.9, 2023, [1, 2, 3])
print(datos[1])
print(datos[-1][0])
Ver solución
# Resultado:
print(version_info[1]) # 3.9
print(version_info[-1][0]) # 1
El primer print accede al segundo elemento de la tupla (índice 1), que es 3.9.
El segundo print accede al último elemento de la tupla (índice -1), que es la lista [1, 2, 3], y luego al primer elemento de esa lista (índice 0), que es 1.
Ejercicio 2: Inmutabilidad y modificación
¿Qué sucederá al ejecutar este código?
datos = ("Python", 3.9, 2023, [1, 2, 3])
datos[3].append(4)
print(datos)
Ver solución
# Resultado:
version_info = ("Python", 3.9, 2023, [1, 2, 3, 4])
version_info[3].append(5) # Modificamos la lista dentro de la tupla
print(version_info) # ("Python", 3.9, 2023, [1, 2, 3, 4, 5])
Aunque la tupla en sí es inmutable (no podemos cambiar sus elementos directamente), el cuarto elemento es una lista, que sí es mutable. Por lo tanto, podemos modificar la lista dentro de la tupla usando métodos como append().
Ejercicio 3: Desempaquetado de tuplas
¿Qué valores tendrán las variables después de ejecutar este código?
datos = (1, 2, 3, 4, 5, 6, 7)
a, *b, c, d = datos
Ver solución
# Código:
numeros = (1, 2, 3, 4, 5, 6, 7)
a, *b, c, d = numeros
# Resultado:
print(a) # 1
print(b) # [2, 3, 4, 5]
print(c) # 6
print(d) # 7
El desempaquetado asigna el primer valor a a, los valores del medio a b (como una lista gracias al operador *), y los dos últimos valores a c y d respectivamente.
Ejercicio 4: Aplicación práctica
Escribe una función que reciba una lista de coordenadas (x, y) y devuelva la coordenada más cercana al origen (0, 0) y su distancia.
Ver solución
import math
def punto_mas_cercano(coordenadas):
"""
Encuentra el punto más cercano al origen (0, 0) y su distancia.
Args:
coordenadas: Lista de tuplas (x, y)
Returns:
Tupla con el punto más cercano y su distancia al origen
"""
if not coordenadas:
return None, None
# Función para calcular la distancia al origen
def distancia_origen(punto):
x, y = punto
return math.sqrt(x**2 + y**2)
# Encontrar el punto con la distancia mínima
punto_cercano = min(coordenadas, key=distancia_origen)
distancia = distancia_origen(punto_cercano)
return punto_cercano, distancia
# Ejemplo de uso
puntos = [(3, 4), (1, 2), (5, 6), (2, 1)]
punto, distancia = punto_mas_cercano(puntos)
print(f"El punto más cercano al origen es {punto} con una distancia de {distancia:.2f}")
# Salida: El punto más cercano al origen es (1, 2) con una distancia de 2.24
Esta función utiliza la función min() con un argumento key para encontrar el punto con la menor distancia al origen. La distancia se calcula utilizando el teorema de Pitágoras.
Resumen
Las tuplas son estructuras de datos inmutables que ofrecen varias ventajas:
- Inmutabilidad: Una vez creadas, no pueden ser modificadas
- Eficiencia: Son más rápidas y usan menos memoria que las listas
- Seguridad: Garantizan que los datos no cambiarán
- Versatilidad: Pueden ser usadas como claves en diccionarios
- Desempaquetado: Permiten asignar múltiples valores de forma concisa
Recuerda nuestra analogía del almacén: las tuplas son como paquetes sellados que garantizan que su contenido permanecerá intacto durante todo el proceso. Son ideales para datos que deben permanecer constantes, como configuraciones, coordenadas o registros históricos.
En el próximo capítulo, exploraremos los conjuntos (sets), que son como estaciones de clasificación que automáticamente eliminan duplicados y permiten operaciones matemáticas como uniones e intersecciones.
🧭 Navegación:
- Anterior: Diccionarios
- Siguiente: Conjuntos (Sets)
- Volver al Índice de Estructuras de Datos
Conjuntos (Sets) en Python
🧭 Navegación:
- Anterior: Tuplas
- Siguiente: Quiz: Estructuras de Datos
- Volver al Índice de Estructuras de Datos
Introducción a los Conjuntos
Imagina que en tu almacén tienes estaciones de clasificación especiales que automáticamente eliminan duplicados y organizan los elementos de manera eficiente. Estas estaciones están diseñadas para responder rápidamente a preguntas como: “¿Contiene este elemento?”, “¿Qué elementos tienen en común estas dos colecciones?” o “¿Qué elementos están en una colección pero no en la otra?”.
Los conjuntos (sets) en Python funcionan exactamente así: son colecciones desordenadas de elementos únicos que permiten operaciones matemáticas de conjuntos como uniones, intersecciones y diferencias.
🔍 Perspectiva personal: Cuando necesito eliminar duplicados de una lista o verificar pertenencia de manera eficiente, los conjuntos son mi primera opción. Son increíblemente rápidos para estas operaciones y simplifican enormemente el código.
Creando Conjuntos
Puedes crear un conjunto utilizando llaves {} o la función set():
# Crear un conjunto con llaves
frutas = {"manzana", "naranja", "plátano", "pera", "manzana"}
print(frutas) # {'naranja', 'plátano', 'manzana', 'pera'}
# Nota: Los duplicados se eliminan automáticamente
# Crear un conjunto a partir de una lista
colores_lista = ["rojo", "azul", "verde", "azul", "amarillo", "rojo"]
colores = set(colores_lista)
print(colores) # {'verde', 'amarillo', 'rojo', 'azul'}
# Crear un conjunto vacío
# Importante: {} crea un diccionario vacío, no un conjunto
conjunto_vacio = set()
print(type(conjunto_vacio)) # <class 'set'>
diccionario_vacio = {}
print(type(diccionario_vacio)) # <class 'dict'>
🔍 Perspectiva personal: Un error común que cometí al principio fue intentar crear un conjunto vacío con {}, ¡pero eso crea un diccionario vacío! Siempre usa set() para crear un conjunto vacío.
Características de los Conjuntos
Los conjuntos en Python tienen varias características importantes:
- Elementos únicos: No permiten duplicados
- Desordenados: No mantienen un orden específico
- Mutables: Puedes añadir o eliminar elementos
- Elementos inmutables: Solo pueden contener elementos inmutables (números, strings, tuplas, pero no listas o diccionarios)
- Optimizados para verificar pertenencia: La operación
ines muy rápida
# Demostración de características
numeros = {1, 2, 3, 4, 5, 5, 4, 3}
print(numeros) # {1, 2, 3, 4, 5} - Sin duplicados
# Los conjuntos son desordenados
# El orden de impresión puede variar
print({3, 1, 4, 2, 5}) # Podría ser {1, 2, 3, 4, 5} u otro orden
# Verificación de pertenencia (muy eficiente)
print(3 in numeros) # True
print(6 in numeros) # False
# Intentar añadir elementos inmutables
try:
conjunto_invalido = {1, 2, [3, 4]} # Esto generará un error
except TypeError as e:
print(f"Error: {e}") # Error: unhashable type: 'list'
# Las tuplas son inmutables, por lo que pueden estar en un conjunto
conjunto_valido = {1, 2, (3, 4)}
print(conjunto_valido) # {1, 2, (3, 4)}
Operaciones con Conjuntos
Añadir y Eliminar Elementos
# Crear un conjunto
inventario = {"laptop", "monitor", "teclado"}
print(f"Inventario inicial: {inventario}")
# Añadir un elemento
inventario.add("mouse")
print(f"Después de añadir: {inventario}")
# Añadir varios elementos
inventario.update(["webcam", "auriculares", "altavoces"])
print(f"Después de update: {inventario}")
# Eliminar un elemento (genera error si no existe)
inventario.remove("webcam")
print(f"Después de remove: {inventario}")
# Eliminar un elemento (no genera error si no existe)
inventario.discard("impresora") # No existe, pero no genera error
print(f"Después de discard: {inventario}")
# Eliminar y devolver un elemento arbitrario
elemento = inventario.pop()
print(f"Elemento eliminado: {elemento}")
print(f"Después de pop: {inventario}")
# Eliminar todos los elementos
inventario.clear()
print(f"Después de clear: {inventario}") # set()
Operaciones Matemáticas de Conjuntos
Los conjuntos en Python soportan todas las operaciones matemáticas estándar de teoría de conjuntos:
# Definir dos conjuntos
a = {1, 2, 3, 4, 5}
b = {4, 5, 6, 7, 8}
# Unión (elementos en A o B)
union = a | b # También: a.union(b)
print(f"Unión: {union}") # {1, 2, 3, 4, 5, 6, 7, 8}
# Intersección (elementos en A y B)
interseccion = a & b # También: a.intersection(b)
print(f"Intersección: {interseccion}") # {4, 5}
# Diferencia (elementos en A pero no en B)
diferencia = a - b # También: a.difference(b)
print(f"Diferencia (A-B): {diferencia}") # {1, 2, 3}
# Diferencia simétrica (elementos en A o B pero no en ambos)
dif_simetrica = a ^ b # También: a.symmetric_difference(b)
print(f"Diferencia simétrica: {dif_simetrica}") # {1, 2, 3, 6, 7, 8}
🔍 Perspectiva personal: Visualizo estas operaciones como si estuviera moviendo productos entre diferentes estaciones de clasificación en el almacén. La unión combina todos los productos, la intersección muestra solo los productos comunes, y la diferencia muestra los productos exclusivos de una estación.
Verificación de Subconjuntos y Superconjuntos
# Definir conjuntos para verificación
frutas = {"manzana", "naranja", "plátano", "pera", "uva"}
citricos = {"naranja", "limón", "lima"}
frutas_tropicales = {"plátano", "piña", "mango"}
solo_naranjas = {"naranja"}
# Verificar si un conjunto es subconjunto de otro
print(solo_naranjas.issubset(frutas)) # True
print(solo_naranjas <= frutas) # True (operador de subconjunto)
# Verificar si un conjunto es superconjunto de otro
print(frutas.issuperset(solo_naranjas)) # True
print(frutas >= solo_naranjas) # True (operador de superconjunto)
# Verificar si dos conjuntos son disjuntos (no tienen elementos en común)
print(citricos.isdisjoint(frutas_tropicales)) # True
print(citricos.isdisjoint(frutas)) # False (tienen "naranja" en común)
Comprensiones de Conjuntos
Al igual que las listas y los diccionarios, los conjuntos también admiten comprensiones:
# Crear un conjunto de cuadrados de números del 1 al 10
cuadrados = {x**2 for x in range(1, 11)}
print(cuadrados) # {1, 4, 9, 16, 25, 36, 49, 64, 81, 100}
# Crear un conjunto de vocales en una cadena
texto = "Python es un lenguaje de programación versátil y poderoso"
vocales = {letra.lower() for letra in texto if letra.lower() in "aeiou"}
print(vocales) # {'e', 'a', 'i', 'o', 'u'}
# Crear un conjunto de números pares del 1 al 20
pares = {x for x in range(1, 21) if x % 2 == 0}
print(pares) # {2, 4, 6, 8, 10, 12, 14, 16, 18, 20}
Conjuntos Inmutables (frozenset)
Python también ofrece una versión inmutable de los conjuntos llamada frozenset. Una vez creado, un frozenset no puede ser modificado:
# Crear un frozenset
colores_inmutables = frozenset(["rojo", "verde", "azul"])
print(colores_inmutables) # frozenset({'verde', 'azul', 'rojo'})
# Intentar modificar un frozenset generará un error
try:
colores_inmutables.add("amarillo")
except AttributeError as e:
print(f"Error: {e}") # Error: 'frozenset' object has no attribute 'add'
# Los frozensets pueden ser usados como claves en diccionarios
paletas = {
frozenset(["rojo", "verde", "azul"]): "RGB",
frozenset(["cian", "magenta", "amarillo", "negro"]): "CMYK"
}
print(paletas[frozenset(["rojo", "verde", "azul"])]) # "RGB"
🔍 Perspectiva personal: Los frozenset son útiles cuando necesitas la eficiencia de los conjuntos para verificar pertenencia, pero también necesitas inmutabilidad, como al usar conjuntos como claves en un diccionario.
Aplicaciones Prácticas de los Conjuntos
1. Eliminar duplicados de una lista
# Lista con elementos duplicados
numeros_con_duplicados = [1, 2, 3, 2, 4, 5, 3, 6, 1, 7]
# Eliminar duplicados manteniendo el orden
numeros_sin_duplicados = list(dict.fromkeys(numeros_con_duplicados))
print(f"Sin duplicados (manteniendo orden): {numeros_sin_duplicados}")
# Eliminar duplicados (sin mantener el orden)
numeros_sin_duplicados_set = list(set(numeros_con_duplicados))
print(f"Sin duplicados (sin mantener orden): {numeros_sin_duplicados_set}")
2. Encontrar elementos únicos y comunes entre listas
# Listas de productos en diferentes almacenes
almacen_a = ["laptop", "monitor", "teclado", "mouse", "impresora", "scanner"]
almacen_b = ["laptop", "tablet", "smartphone", "monitor", "cables", "accesorios"]
# Convertir a conjuntos
set_a = set(almacen_a)
set_b = set(almacen_b)
# Productos en ambos almacenes
productos_comunes = set_a & set_b
print(f"Productos en ambos almacenes: {productos_comunes}")
# Productos únicos del almacén A
productos_unicos_a = set_a - set_b
print(f"Productos únicos del almacén A: {productos_unicos_a}")
# Productos únicos del almacén B
productos_unicos_b = set_b - set_a
print(f"Productos únicos del almacén B: {productos_unicos_b}")
# Todos los productos disponibles
todos_productos = set_a | set_b
print(f"Todos los productos disponibles: {todos_productos}")
3. Verificar si una lista contiene todos los elementos requeridos
# Ingredientes requeridos para una receta
ingredientes_requeridos = {"harina", "huevos", "azúcar", "leche", "mantequilla"}
# Ingredientes disponibles en la cocina
ingredientes_disponibles = {"harina", "huevos", "azúcar", "sal", "levadura", "mantequilla"}
# Verificar si tenemos todos los ingredientes requeridos
if ingredientes_requeridos.issubset(ingredientes_disponibles):
print("¡Tenemos todos los ingredientes para la receta!")
else:
# Encontrar qué ingredientes faltan
faltantes = ingredientes_requeridos - ingredientes_disponibles
print(f"Faltan los siguientes ingredientes: {faltantes}")
4. Análisis de texto
def analizar_texto(texto):
"""Analiza un texto y devuelve estadísticas sobre las palabras."""
# Convertir a minúsculas y dividir en palabras
palabras = texto.lower().split()
# Eliminar signos de puntuación
palabras = [palabra.strip(".,;:!?()[]{}\"'") for palabra in palabras]
# Contar palabras únicas
palabras_unicas = set(palabras)
return {
"total_palabras": len(palabras),
"palabras_unicas": len(palabras_unicas),
"palabras_comunes": sorted(palabras_unicas)[:5] if len(palabras_unicas) >= 5 else sorted(palabras_unicas)
}
# Ejemplo de uso
texto_ejemplo = """
Python es un lenguaje de programación versátil y poderoso.
Python es fácil de aprender y tiene una sintaxis clara.
Los programadores disfrutan usando Python para diversos proyectos.
"""
resultado = analizar_texto(texto_ejemplo)
print(f"Total de palabras: {resultado['total_palabras']}")
print(f"Palabras únicas: {resultado['palabras_unicas']}")
print(f"Algunas palabras comunes: {resultado['palabras_comunes']}")
Rendimiento de los Conjuntos
Los conjuntos en Python están implementados como tablas hash, lo que los hace extremadamente eficientes para operaciones como verificar pertenencia, añadir elementos y eliminar elementos. Estas operaciones tienen una complejidad de tiempo promedio de O(1), lo que significa que son muy rápidas incluso con conjuntos grandes.
import time
# Comparar rendimiento entre lista y conjunto para verificar pertenencia
def comparar_rendimiento(n):
# Crear una lista y un conjunto con n elementos
lista = list(range(n))
conjunto = set(range(n))
# Elemento a buscar (peor caso)
elemento = n - 1
# Medir tiempo para lista
inicio = time.time()
elemento in lista
tiempo_lista = time.time() - inicio
# Medir tiempo para conjunto
inicio = time.time()
elemento in conjunto
tiempo_conjunto = time.time() - inicio
return tiempo_lista, tiempo_conjunto
# Probar con diferentes tamaños
tamaños = [1000, 10000, 100000, 1000000]
print("Comparación de rendimiento (verificación de pertenencia):")
print("Tamaño\t\tTiempo Lista\tTiempo Conjunto\tVeces más rápido")
print("-" * 70)
for n in tamaños:
tiempo_lista, tiempo_conjunto = comparar_rendimiento(n)
veces_mas_rapido = tiempo_lista / tiempo_conjunto if tiempo_conjunto > 0 else "∞"
print(f"{n:,}\t\t{tiempo_lista:.6f}s\t{tiempo_conjunto:.6f}s\t{veces_mas_rapido:.1f}x")
🔍 Perspectiva personal: La primera vez que vi la diferencia de rendimiento entre buscar en una lista vs. buscar en un conjunto con miles de elementos, quedé impresionado. Los conjuntos pueden ser cientos o miles de veces más rápidos para estas operaciones.
Conjuntos vs Listas vs Diccionarios: ¿Cuándo usar cada uno?
| Estructura | Características | Casos de uso |
|---|---|---|
| Conjuntos | - Elementos únicos - Desordenados - Operaciones matemáticas de conjuntos - Verificación de pertenencia O(1) | - Eliminar duplicados - Verificar pertenencia eficientemente - Operaciones matemáticas entre colecciones |
| Listas | - Permite duplicados - Ordenados por índice - Acceso por posición - Verificación de pertenencia O(n) | - Cuando el orden importa - Cuando necesitas duplicados - Cuando necesitas acceder por índice |
| Diccionarios | - Pares clave-valor - Claves únicas - Acceso por clave O(1) | - Mapeo de valores - Búsqueda rápida por clave - Almacenar propiedades de objetos |
Usa conjuntos cuando:
- Necesites elementos únicos: Eliminar duplicados automáticamente
- La verificación de pertenencia sea crítica: Operaciones
inmuy rápidas - Necesites operaciones matemáticas de conjuntos: Uniones, intersecciones, diferencias
- El orden no sea importante: Los conjuntos no mantienen un orden específico
Comprueba tu comprensión
Vamos a poner a prueba tu comprensión de los conjuntos con algunos ejercicios prácticos:
Ejercicio 1: Operaciones básicas con conjuntos
¿Qué imprimirá el siguiente código?
a = {1, 2, 3, 4}
b = {3, 4, 5, 6}
print(a | b)
print(a & b)
print(a - b)
print(b - a)
Ver solución
# Código:
a = {1, 2, 3, 4}
b = {3, 4, 5, 6}
# Resultados:
print(a | b) # {1, 2, 3, 4, 5, 6}
print(a & b) # {3, 4}
print(a - b) # {1, 2}
print(b - a) # {5, 6}
a | bes la unión: todos los elementos que están enao enba & bes la intersección: elementos comunes aayba - bes la diferencia: elementos enapero no enbb - aes la diferencia: elementos enbpero no ena
Ejercicio 2: Eliminar duplicados manteniendo el orden
Escribe una función que elimine los duplicados de una lista manteniendo el orden original de los elementos.
Ver solución
def eliminar_duplicados_ordenados(lista):
"""
Elimina duplicados de una lista manteniendo el orden original.
Args:
lista: Lista con posibles duplicados
Returns:
Lista sin duplicados, manteniendo el orden original
"""
return list(dict.fromkeys(lista))
# Ejemplo de uso
numeros = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
print(eliminar_duplicados_ordenados(numeros)) # [3, 1, 4, 5, 9, 2, 6]
Esta solución utiliza un diccionario para mantener el orden (en Python 3.7+, los diccionarios mantienen el orden de inserción). Al convertir la lista a un diccionario con las claves como elementos de la lista, automáticamente se eliminan los duplicados mientras se preserva el orden.
Ejercicio 3: Encontrar elementos únicos en múltiples listas
Escribe una función que tome varias listas y devuelva los elementos que aparecen en una y solo una de las listas.
Ver solución
def elementos_unicos(*listas):
"""
Encuentra elementos que aparecen en exactamente una de las listas.
Args:
*listas: Múltiples listas
Returns:
Conjunto con elementos que aparecen en exactamente una lista
"""
if not listas:
return set()
# Convertir todas las listas a conjuntos
conjuntos = [set(lista) for lista in listas]
# Unión de todos los conjuntos
todos = set().union(*conjuntos)
# Elementos que aparecen en más de una lista
comunes = set()
for i, conjunto_a in enumerate(conjuntos):
for j, conjunto_b in enumerate(conjuntos):
if i < j: # Evitar comparar un conjunto consigo mismo o repetir comparaciones
comunes.update(conjunto_a & conjunto_b)
# Elementos únicos = todos - comunes
return todos - comunes
# Ejemplo de uso
lista1 = [1, 2, 3, 4, 5]
lista2 = [4, 5, 6, 7, 8]
lista3 = [7, 8, 9, 10]
unicos = elementos_unicos(lista1, lista2, lista3)
print(unicos) # {1, 2, 3, 6, 9, 10}
Esta función convierte cada lista a un conjunto, encuentra la unión de todos los conjuntos, y luego resta los elementos que aparecen en más de una lista.
Ejercicio 4: Verificar anagramas
Escribe una función que determine si dos palabras son anagramas (contienen exactamente las mismas letras).
Ver solución
def son_anagramas(palabra1, palabra2):
"""
Verifica si dos palabras son anagramas.
Args:
palabra1: Primera palabra
palabra2: Segunda palabra
Returns:
True si son anagramas, False en caso contrario
"""
# Eliminar espacios y convertir a minúsculas
palabra1 = palabra1.lower().replace(" ", "")
palabra2 = palabra2.lower().replace(" ", "")
# Verificar si tienen las mismas letras
return set(palabra1) == set(palabra2) and len(palabra1) == len(palabra2)
# Ejemplos de uso
print(son_anagramas("amor", "roma")) # True
print(son_anagramas("listen", "silent")) # True
print(son_anagramas("hello", "world")) # False
print(son_anagramas("astronomer", "moon starer")) # True
Esta función convierte ambas palabras a conjuntos y verifica si contienen las mismas letras. También verifica que tengan la misma longitud, ya que dos palabras con diferentes cantidades de las mismas letras no son anagramas (por ejemplo, “aab” y “aba” tienen las mismas letras pero no son anagramas).
Resumen
Los conjuntos son estructuras de datos poderosas y eficientes que ofrecen varias ventajas:
- Elementos únicos: Eliminan automáticamente los duplicados
- Operaciones matemáticas: Soportan uniones, intersecciones y diferencias
- Eficiencia: Verificación de pertenencia extremadamente rápida (O(1))
- Flexibilidad: Pueden ser mutables (set) o inmutables (frozenset)
Recuerda nuestra analogía del almacén: los conjuntos son como estaciones de clasificación que automáticamente eliminan duplicados y permiten operaciones eficientes entre diferentes grupos de elementos. Son ideales para eliminar duplicados, verificar pertenencia eficientemente y realizar operaciones matemáticas entre colecciones.
Con esto, hemos completado nuestro recorrido por las principales estructuras de datos en Python:
- Listas: Estanterías flexibles para secuencias ordenadas
- Diccionarios: Sistema de inventario con etiquetas para acceso rápido
- Tuplas: Paquetes sellados que no pueden modificarse
- Conjuntos: Estaciones de clasificación que eliminan duplicados
Cada una tiene sus propias fortalezas y casos de uso, y dominarlas te permitirá elegir la herramienta adecuada para cada tarea en tus proyectos de Python.
🧭 Navegación:
- Anterior: Tuplas
- Siguiente: Quiz: Estructuras de Datos
- Volver al Índice de Estructuras de Datos
Diagramas de Estructuras de Datos
En esta sección visualizaremos las diferentes estructuras de datos en Python para ayudar a comprender cómo se organizan y cómo se accede a los elementos.
Diagrama de Listas
Las listas son colecciones ordenadas y mutables de elementos:
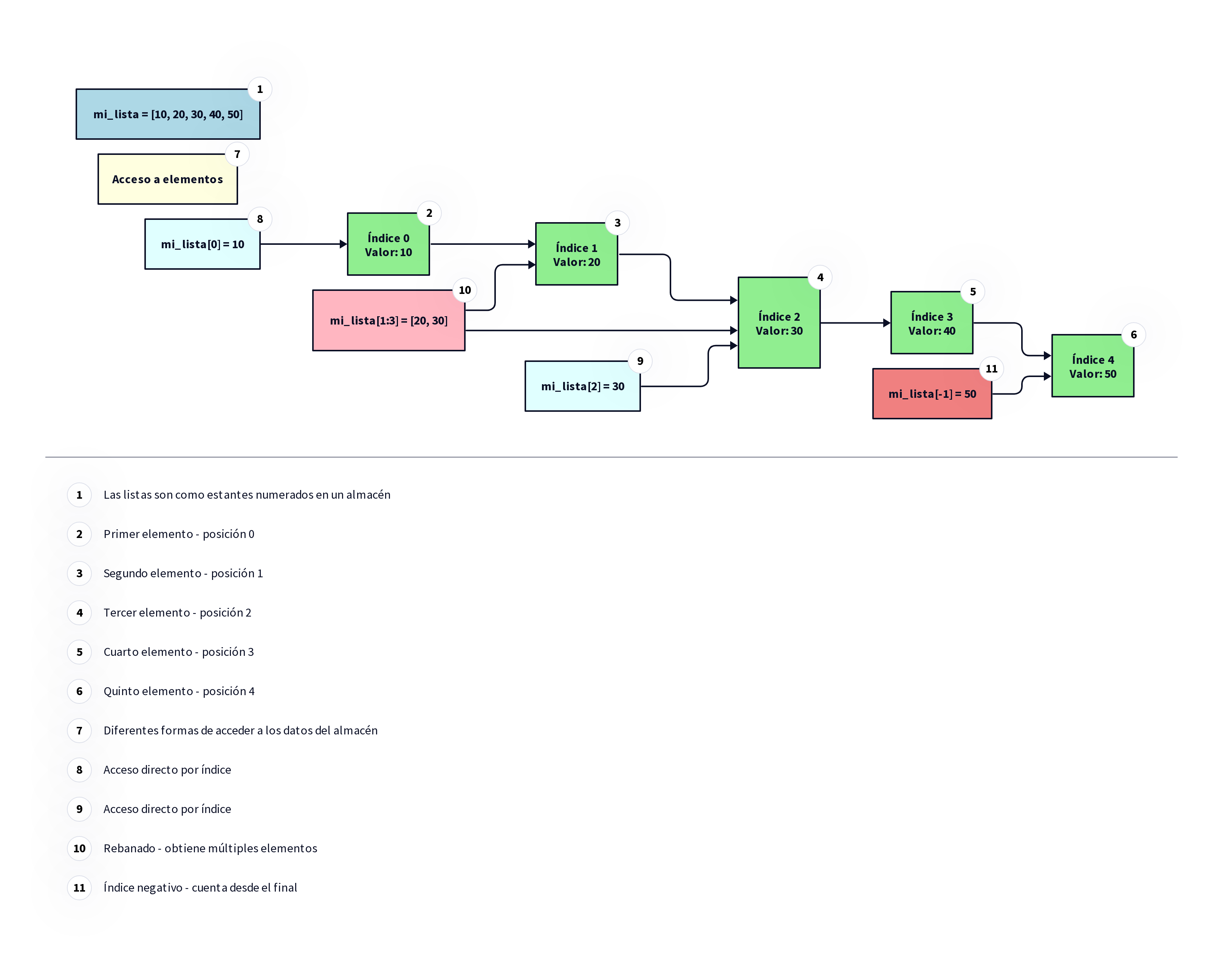
Diagrama de Diccionarios
Los diccionarios son colecciones no ordenadas de pares clave-valor:
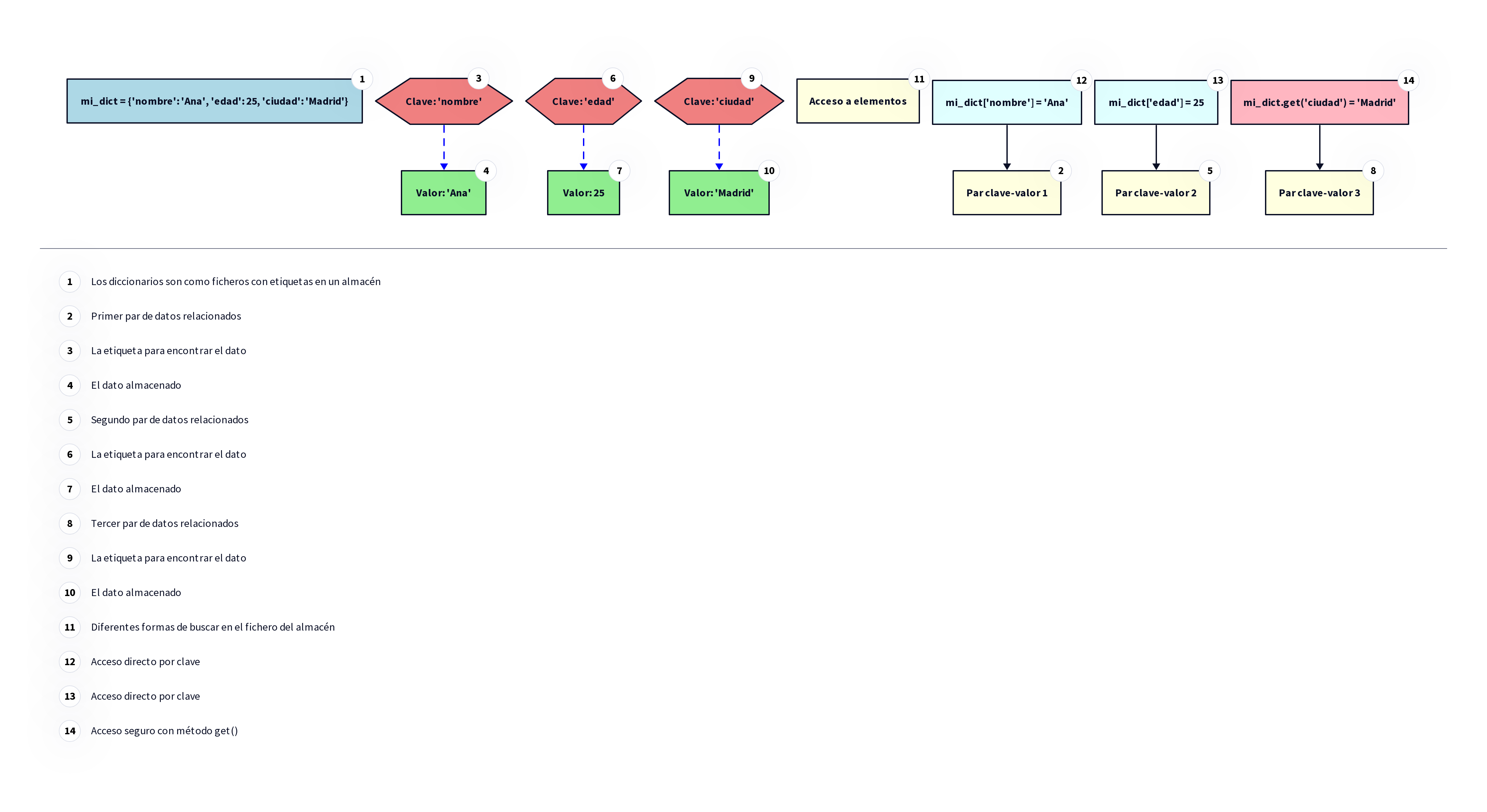
Diagrama de Tuplas
Las tuplas son colecciones ordenadas e inmutables de elementos:
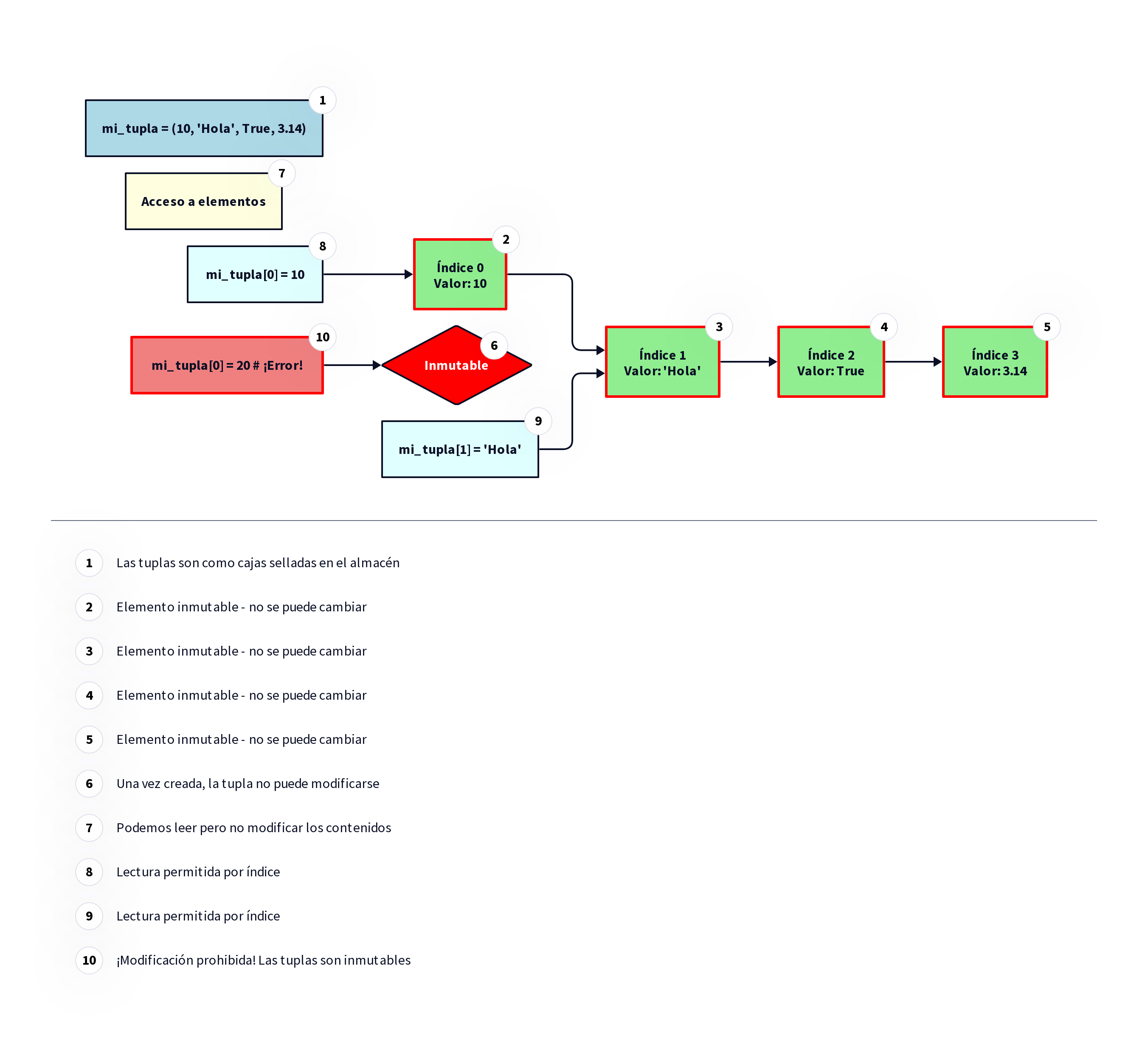
Diagrama de Conjuntos (Sets)
Los conjuntos son colecciones no ordenadas de elementos únicos:
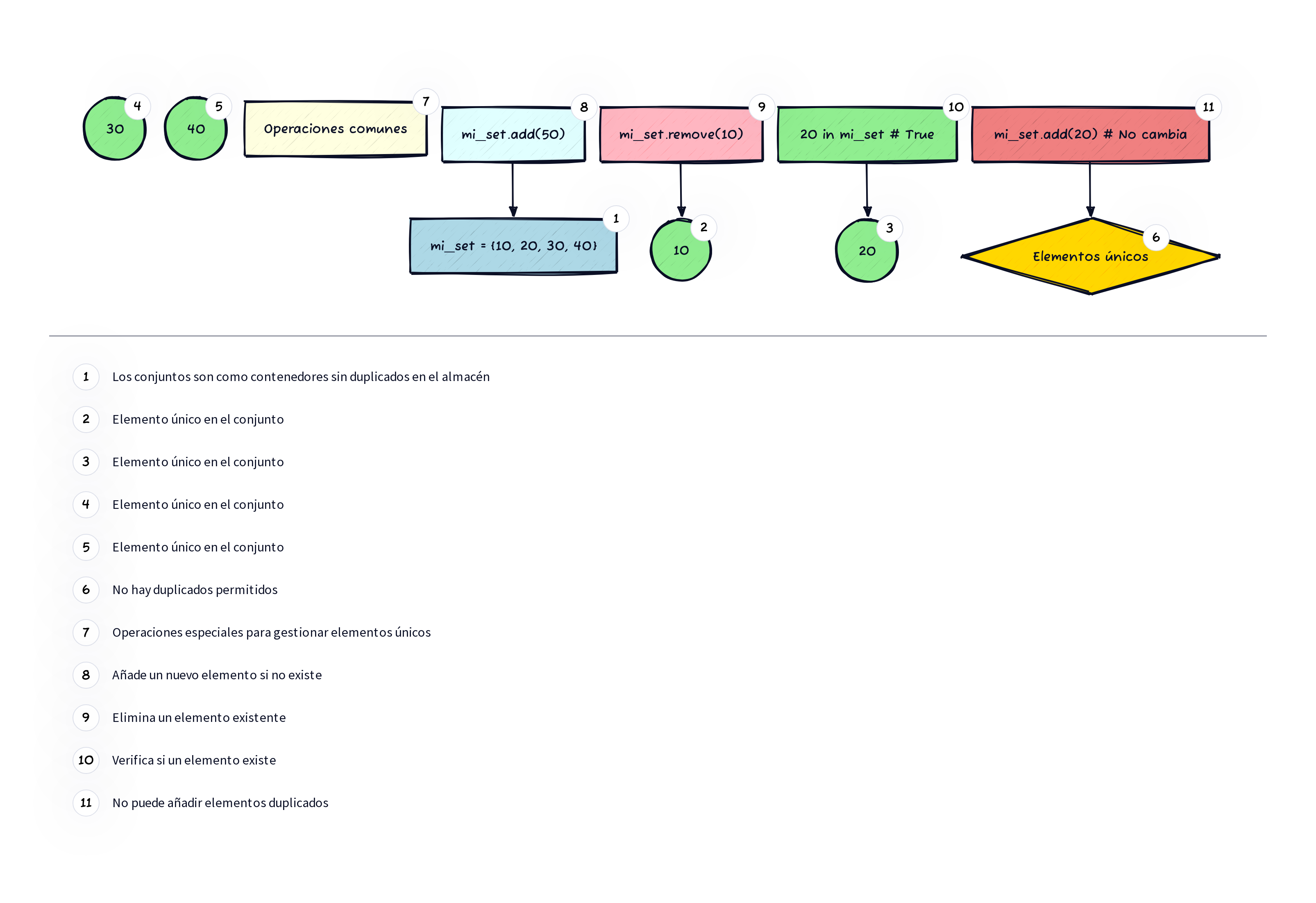
Comparación de Estructuras de Datos
Este diagrama muestra una comparación de las principales características de las estructuras de datos en Python:
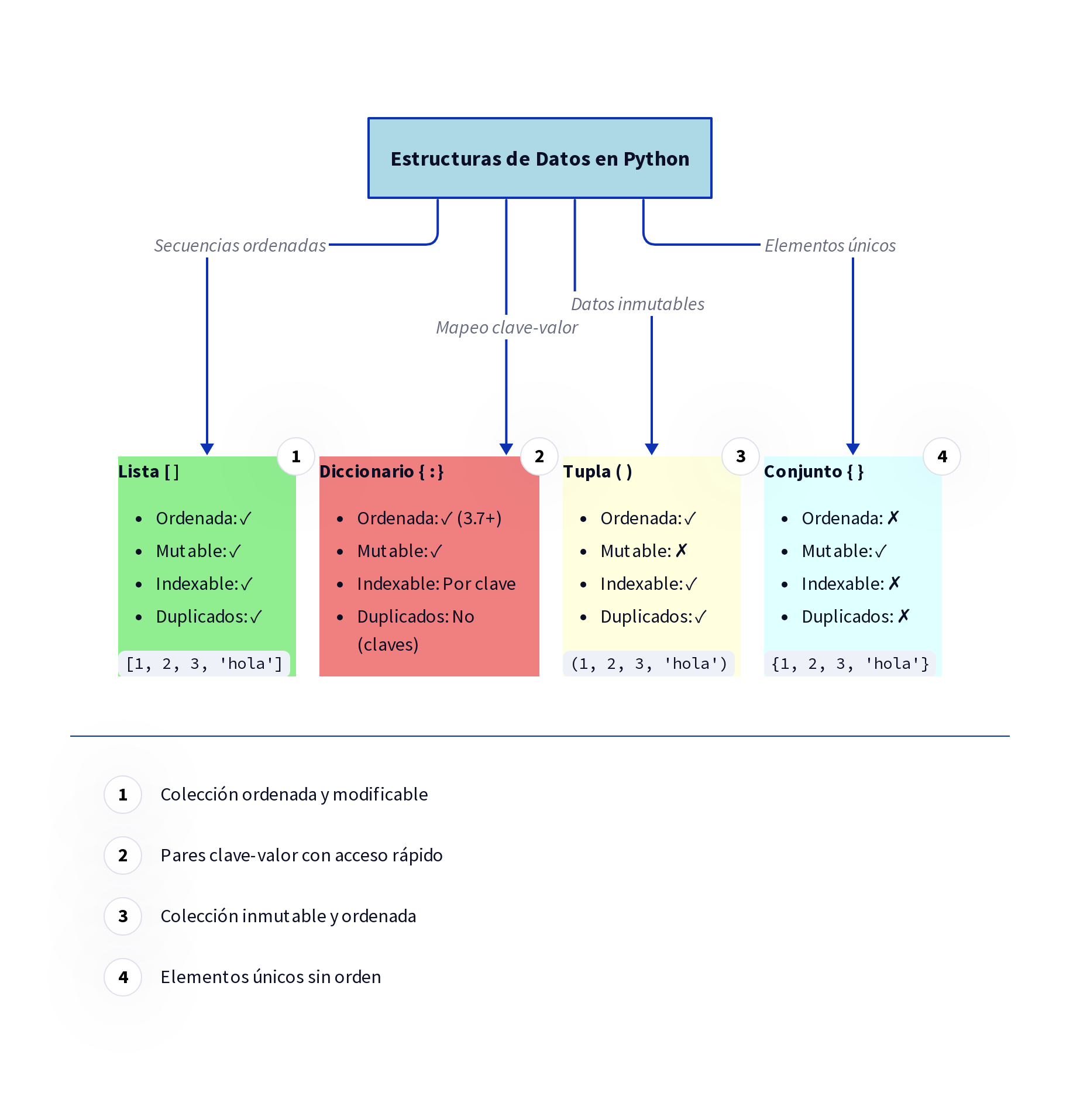
Estos diagramas te ayudarán a visualizar cómo se organizan las diferentes estructuras de datos en Python y cómo interactuar con ellas.
Quiz: Estructuras de Datos
🧭 Navegación:
- Anterior: Conjuntos (Sets)
- Siguiente: Funciones – Bloques de Construcción para Reutilización
- Volver al Índice de Estructuras de Datos
¡Es hora de poner a prueba tus conocimientos sobre las estructuras de datos en Python! Este quiz cubre los conceptos clave de listas, diccionarios, tuplas y conjuntos que hemos explorado en este capítulo.
Instrucciones
- Lee cada pregunta cuidadosamente
- Intenta responder antes de ver la solución
- Las soluciones están ocultas bajo cada pregunta
- Al final encontrarás una evaluación basada en tus respuestas correctas
¡Buena suerte!
Preguntas Teóricas
1. Analogías del Almacén
¿Qué estructura de datos corresponde a cada analogía del almacén?
a) Estanterías flexibles que pueden reorganizarse
b) Sistema de inventario con etiquetas
c) Paquetes sellados que no pueden modificarse
d) Estaciones de clasificación sin duplicados
Ver respuesta
Respuestas correctas:
- a) Listas: Estanterías flexibles que pueden reorganizarse
- b) Diccionarios: Sistema de inventario con etiquetas
- c) Tuplas: Paquetes sellados que no pueden modificarse
- d) Conjuntos: Estaciones de clasificación sin duplicados
Estas analogías nos ayudan a entender el propósito y comportamiento de cada estructura de datos:
- Las listas son flexibles y ordenadas, como estanterías que podemos reorganizar
- Los diccionarios permiten acceso rápido por clave, como un sistema de inventario
- Las tuplas son inmutables, como paquetes sellados
- Los conjuntos eliminan duplicados automáticamente, como estaciones de clasificación
2. Mutabilidad vs Inmutabilidad
¿Cuáles de las siguientes afirmaciones son correctas sobre la mutabilidad de las estructuras de datos?
a) Las listas son mutables y pueden contener cualquier tipo de dato
b) Los diccionarios son inmutables una vez creados
c) Las tuplas son inmutables pero pueden contener objetos mutables
d) Los conjuntos son mutables pero solo pueden contener objetos inmutables
Ver respuesta
Respuestas correctas: a), c) y d)
Explicación:
- ✅ Las listas son mutables y pueden contener cualquier tipo de dato
- ❌ Los diccionarios son mutables, no inmutables
- ✅ Las tuplas son inmutables pero pueden contener objetos mutables (como listas)
- ✅ Los conjuntos son mutables pero solo pueden contener objetos inmutables (números, strings, tuplas)
Ejemplo con tuplas conteniendo objetos mutables:
# La tupla es inmutable, pero la lista dentro de ella es mutable
t = (1, [2, 3], 4)
t[1].append(5) # Válido
print(t) # (1, [2, 3, 5], 4)
# Pero no podemos cambiar la tupla en sí
try:
t[1] = [6, 7] # Esto generará un error
except TypeError as e:
print(f"Error: {e}")
3. Eficiencia de Operaciones
Ordena las siguientes operaciones de más eficiente a menos eficiente:
a) Buscar un elemento en una lista
b) Buscar una clave en un diccionario
c) Verificar si un elemento está en un conjunto
d) Buscar un elemento en una tupla
Ver respuesta
Orden correcto (de más eficiente a menos eficiente):
- b) y c) - Buscar en diccionario y conjunto: O(1)
- a) y d) - Buscar en lista y tupla: O(n)
Explicación:
- Los diccionarios y conjuntos usan tablas hash, permitiendo búsquedas en tiempo constante O(1)
- Las listas y tuplas requieren búsqueda lineal O(n), revisando cada elemento
- Las tuplas no son más rápidas que las listas para búsquedas, aunque son más eficientes en memoria
# Ejemplo de rendimiento
import time
def medir_tiempo(operacion, n=1000000):
inicio = time.time()
operacion()
return time.time() - inicio
# Preparar estructuras
lista = list(range(n))
conjunto = set(lista)
diccionario = {x: x for x in lista}
elemento = n - 1 # Peor caso
# Medir tiempos
tiempo_lista = medir_tiempo(lambda: elemento in lista)
tiempo_conjunto = medir_tiempo(lambda: elemento in conjunto)
tiempo_dict = medir_tiempo(lambda: elemento in diccionario)
print(f"Tiempo lista: {tiempo_lista:.6f}s")
print(f"Tiempo conjunto: {tiempo_conjunto:.6f}s")
print(f"Tiempo diccionario: {tiempo_dict:.6f}s")
Preguntas Prácticas
4. Manipulación de Listas
¿Qué imprimirá el siguiente código?
lista = [1, 2, 3, 4, 5]
lista[1:4] = [10]
print(lista)
Ver respuesta
Respuesta: [1, 10, 5]
Explicación:
- La lista original es
[1, 2, 3, 4, 5] - El slice
[1:4]selecciona los elementos en los índices 1, 2 y 3 - Estos tres elementos son reemplazados por un solo elemento
[10] - El resultado es
[1, 10, 5]
Este ejemplo demuestra que:
- Los slices pueden ser reemplazados por un número diferente de elementos
- La lista se ajusta automáticamente al nuevo tamaño
- Los elementos fuera del slice permanecen sin cambios
5. Diccionarios Anidados
Dado el siguiente diccionario:
almacen = {
'electrónicos': {
'computadoras': {'stock': 10, 'precio': 1200},
'tablets': {'stock': 15, 'precio': 300}
},
'muebles': {
'sillas': {'stock': 20, 'precio': 50},
'mesas': {'stock': 8, 'precio': 150}
}
}
Escribe una función que calcule el valor total del inventario.
Ver respuesta
Solución:
def valor_total_inventario(inventario):
total = 0
for categoria in inventario.values():
for producto in categoria.values():
total += producto['stock'] * producto['precio']
return total
# Calcular el valor total
total = valor_total_inventario(almacen)
print(f"Valor total del inventario: ${total:,}") # $19,200
Explicación:
- La función recorre cada categoría del almacén
- Para cada categoría, recorre cada producto
- Multiplica el stock por el precio de cada producto
- Suma todos los valores para obtener el total
Alternativa usando comprensión de diccionarios:
def valor_total_inventario_comprension(inventario):
return sum(
producto['stock'] * producto['precio']
for categoria in inventario.values()
for producto in categoria.values()
)
6. Tuplas y Desempaquetado
¿Qué valores tendrán las variables después de ejecutar este código?
datos = [(1, 'a'), (2, 'b'), (3, 'c')]
numeros, letras = zip(*datos)
print(numeros)
print(letras)
Ver respuesta
Respuesta:
numeros = (1, 2, 3)
letras = ('a', 'b', 'c')
Explicación:
zip(*datos)desempaqueta la lista de tuplas- El operador
*desempaquetadatosen argumentos individuales zip()crea un nuevo iterador que agrupa los elementos por posición- El resultado se asigna a
numerosyletrasmediante desempaquetado
Este patrón es útil para:
- Transponer matrices
- Separar datos en columnas
- Procesar datos estructurados
Ejemplo adicional:
# Crear una lista de tuplas desde columnas separadas
nums = [1, 2, 3]
lets = ['a', 'b', 'c']
combinados = list(zip(nums, lets))
print(combinados) # [(1, 'a'), (2, 'b'), (3, 'c')]
# Volver a separar
n, l = zip(*combinados)
print(n) # (1, 2, 3)
print(l) # ('a', 'b', 'c')
7. Operaciones con Conjuntos
Dado el siguiente código:
empleados_python = {'Ana', 'Carlos', 'Diana', 'Eduardo'}
empleados_java = {'Bruno', 'Carlos', 'Diana', 'Fernando'}
empleados_javascript = {'Carlos', 'Gabriel', 'Diana', 'Helena'}
Escribe expresiones para encontrar:
a) Empleados que conocen los tres lenguajes
b) Empleados que solo conocen Python
c) Empleados que conocen al menos dos lenguajes
Ver respuesta
Solución:
# a) Empleados que conocen los tres lenguajes
todos_lenguajes = empleados_python & empleados_java & empleados_javascript
print(f"Conocen los tres lenguajes: {todos_lenguajes}") # {'Carlos', 'Diana'}
# b) Empleados que solo conocen Python
solo_python = empleados_python - (empleados_java | empleados_javascript)
print(f"Solo conocen Python: {solo_python}") # {'Ana'}
# c) Empleados que conocen al menos dos lenguajes
python_java = empleados_python & empleados_java
python_js = empleados_python & empleados_javascript
java_js = empleados_java & empleados_javascript
al_menos_dos = python_java | python_js | java_js
print(f"Conocen al menos dos lenguajes: {al_menos_dos}") # {'Carlos', 'Diana'}
Explicación de operadores:
&: intersección (elementos comunes)|: unión (todos los elementos)-: diferencia (elementos en el primer conjunto pero no en el segundo)
Alternativa usando métodos:
# Los mismos resultados usando métodos
todos_lenguajes = empleados_python.intersection(empleados_java, empleados_javascript)
solo_python = empleados_python.difference(empleados_java.union(empleados_javascript))
al_menos_dos = (empleados_python.intersection(empleados_java)
.union(empleados_python.intersection(empleados_javascript))
.union(empleados_java.intersection(empleados_javascript)))
8. Proyecto Práctico: Sistema de Inventario
Implementa un sistema simple de inventario que permita:
- Añadir productos con cantidad y precio
- Actualizar el stock
- Calcular el valor total del inventario
- Listar productos con bajo stock (menos de 5 unidades)
Ver respuesta
Solución:
class Inventario:
def __init__(self):
self.productos = {}
def agregar_producto(self, codigo, nombre, cantidad, precio):
"""Añade un nuevo producto o actualiza uno existente."""
self.productos[codigo] = {
'nombre': nombre,
'cantidad': cantidad,
'precio': precio
}
def actualizar_stock(self, codigo, cantidad):
"""Actualiza la cantidad de un producto."""
if codigo in self.productos:
self.productos[codigo]['cantidad'] += cantidad
return True
return False
def valor_total(self):
"""Calcula el valor total del inventario."""
return sum(
prod['cantidad'] * prod['precio']
for prod in self.productos.values()
)
def productos_bajo_stock(self, limite=5):
"""Lista productos con stock menor al límite."""
return {
codigo: datos
for codigo, datos in self.productos.items()
if datos['cantidad'] < limite
}
def mostrar_inventario(self):
"""Muestra el inventario completo."""
print("\nInventario Actual:")
print("-" * 50)
print(f"{'Código':<10} {'Nombre':<20} {'Cantidad':<10} {'Precio':>8}")
print("-" * 50)
for codigo, datos in self.productos.items():
print(f"{codigo:<10} {datos['nombre']:<20} {datos['cantidad']:<10} ${datos['precio']:>7.2f}")
print("-" * 50)
print(f"Valor total del inventario: ${self.valor_total():,.2f}")
# Ejemplo de uso
inventario = Inventario()
# Agregar productos
inventario.agregar_producto('LAP001', 'Laptop Dell', 10, 1200)
inventario.agregar_producto('MON001', 'Monitor 24"', 15, 200)
inventario.agregar_producto('TEC001', 'Teclado Mecánico', 3, 80)
inventario.agregar_producto('MOU001', 'Mouse Inalámbrico', 20, 30)
# Mostrar inventario inicial
inventario.mostrar_inventario()
# Actualizar stock
inventario.actualizar_stock('LAP001', -2) # Venta de 2 laptops
inventario.actualizar_stock('MON001', 5) # Recepción de 5 monitores
# Mostrar productos con bajo stock
print("\nProductos con bajo stock:")
for codigo, datos in inventario.productos_bajo_stock().items():
print(f"{datos['nombre']}: {datos['cantidad']} unidades")
# Mostrar inventario actualizado
inventario.mostrar_inventario()
Este ejemplo demuestra:
- Uso de diccionarios anidados para almacenar datos
- Métodos para manipular el inventario
- Comprensiones de diccionarios para filtrar datos
- Formateo de strings para presentación
Características adicionales que podrías implementar:
- Validación de datos (cantidades no negativas, precios válidos)
- Historial de transacciones usando tuplas
- Categorización de productos usando conjuntos
- Búsqueda de productos por nombre o código
9. Desafío: Análisis de Datos
Dado un conjunto de datos de ventas, escribe funciones para:
- Encontrar los productos más vendidos
- Calcular las ventas por día
- Identificar patrones de compra (productos que se compran juntos)
ventas = [
('2023-07-01', ['laptop', 'mouse', 'teclado']),
('2023-07-01', ['monitor', 'teclado']),
('2023-07-02', ['laptop', 'monitor']),
('2023-07-02', ['mouse', 'teclado', 'auriculares']),
('2023-07-03', ['laptop', 'mouse'])
]
Ver respuesta
Solución:
from collections import Counter
from itertools import combinations
def productos_mas_vendidos(ventas):
"""Encuentra los productos más vendidos y su cantidad."""
contador = Counter()
for _, productos in ventas:
contador.update(productos)
return contador.most_common()
def ventas_por_dia(ventas):
"""Calcula el número de ventas por día."""
ventas_dia = {}
for fecha, productos in ventas:
ventas_dia[fecha] = ventas_dia.get(fecha, 0) + 1
return dict(sorted(ventas_dia.items()))
def productos_relacionados(ventas, min_frecuencia=2):
"""Identifica productos que se compran juntos frecuentemente."""
pares = Counter()
for _, productos in ventas:
# Generar todos los pares posibles de productos
for par in combinations(sorted(productos), 2):
pares[par] += 1
# Filtrar pares que aparecen al menos min_frecuencia veces
return {par: freq for par, freq in pares.items()
if freq >= min_frecuencia}
# Análisis de ventas
print("Productos más vendidos:")
for producto, cantidad in productos_mas_vendidos(ventas):
print(f"{producto}: {cantidad} ventas")
print("\nVentas por día:")
for fecha, cantidad in ventas_por_dia(ventas).items():
print(f"{fecha}: {cantidad} ventas")
print("\nProductos frecuentemente comprados juntos:")
for (prod1, prod2), freq in productos_relacionados(ventas).items():
print(f"{prod1} + {prod2}: {freq} veces")
Este ejemplo demuestra:
- Uso de
Counterpara contar ocurrencias - Diccionarios para agrupar datos por fecha
- Combinaciones para analizar patrones
- Comprensiones de diccionarios para filtrar resultados
Mejoras posibles:
- Añadir análisis de tendencias temporales
- Calcular correlaciones entre productos
- Visualizar datos con gráficos
- Generar recomendaciones basadas en patrones
10. Desafío Final: Optimización de Código
Optimiza el siguiente código que procesa datos de ventas:
def procesar_ventas(ventas):
productos_vendidos = []
ventas_por_producto = {}
clientes_por_producto = {}
for venta in ventas:
producto = venta['producto']
cantidad = venta['cantidad']
cliente = venta['cliente']
productos_vendidos.append(producto)
if producto in ventas_por_producto:
ventas_por_producto[producto] += cantidad
else:
ventas_por_producto[producto] = cantidad
if producto not in clientes_por_producto:
clientes_por_producto[producto] = []
if cliente not in clientes_por_producto[producto]:
clientes_por_producto[producto].append(cliente)
return (list(set(productos_vendidos)),
ventas_por_producto,
clientes_por_producto)
Ver respuesta
Solución optimizada:
from collections import defaultdict
def procesar_ventas_optimizado(ventas):
"""
Procesa datos de ventas de manera eficiente.
Args:
ventas: Lista de diccionarios con datos de ventas
Returns:
Tupla con (productos únicos, ventas por producto, clientes por producto)
"""
productos_vendidos = set() # Usar set desde el inicio
ventas_por_producto = defaultdict(int) # Valor default 0
clientes_por_producto = defaultdict(set) # Valor default set()
for venta in ventas:
producto = venta['producto']
productos_vendidos.add(producto)
ventas_por_producto[producto] += venta['cantidad']
clientes_por_producto[producto].add(venta['cliente'])
return (list(productos_vendidos),
dict(ventas_por_producto),
{k: list(v) for k, v in clientes_por_producto.items()})
# Comparación de rendimiento
import time
# Datos de prueba
datos_prueba = [
{'producto': 'laptop', 'cantidad': 1, 'cliente': 'Ana'},
{'producto': 'monitor', 'cantidad': 2, 'cliente': 'Bruno'},
{'producto': 'laptop', 'cantidad': 1, 'cliente': 'Carlos'},
{'producto': 'teclado', 'cantidad': 3, 'cliente': 'Ana'},
{'producto': 'monitor', 'cantidad': 1, 'cliente': 'Diana'}
]
# Medir tiempo de la versión original
inicio = time.time()
resultado_original = procesar_ventas(datos_prueba)
tiempo_original = time.time() - inicio
# Medir tiempo de la versión optimizada
inicio = time.time()
resultado_optimizado = procesar_ventas_optimizado(datos_prueba)
tiempo_optimizado = time.time() - inicio
print(f"Tiempo versión original: {tiempo_original:.6f}s")
print(f"Tiempo versión optimizada: {tiempo_optimizado:.6f}s")
print(f"Mejora: {(tiempo_original/tiempo_optimizado):.2f}x más rápido")
Mejoras realizadas:
- Uso de
set()desde el inicio para productos únicos - Uso de
defaultdictpara evitar verificaciones de existencia - Uso de
set()para clientes por producto, eliminando duplicados automáticamente - Conversión final a los tipos de datos requeridos
Ventajas:
- Código más conciso y legible
- Mejor rendimiento
- Menos propenso a errores
- Más eficiente en memoria
La versión optimizada es especialmente más eficiente con conjuntos de datos grandes debido a:
- Menos operaciones de verificación
- Uso de estructuras de datos optimizadas
- Mejor manejo de memoria
Evaluación
Cuenta tus respuestas correctas:
- 9-10 correctas: ¡Excelente! Dominas las estructuras de datos en Python.
- 7-8 correctas: ¡Muy bien! Tienes una comprensión sólida.
- 5-6 correctas: Bien. Entiendes los conceptos básicos pero necesitas más práctica.
- 3-4 correctas: Regular. Repasa los conceptos clave.
- 0-2 correctas: Necesitas revisar el capítulo nuevamente.
Próximos Pasos
- Revisa los conceptos en los que tuviste dificultades
- Practica con los ejercicios adicionales de cada sección
- Intenta resolver problemas reales usando estas estructuras
- Avanza al siguiente capítulo: Funciones – Bloques de Construcción para Reutilización
🧭 Navegación:
- Anterior: Conjuntos (Sets)
- Siguiente: Funciones – Bloques de Construcción para Reutilización
- Volver al Índice de Estructuras de Datos
Funciones – Bloques de Construcción para Reutilización
🧭 Navegación:
- Anterior: Estructuras de Datos
- Siguiente: Módulos y la Biblioteca Estándar
¡Bienvenido al departamento de herramientas especializadas de nuestro almacén! Las funciones son como las máquinas y herramientas que nos permiten automatizar tareas repetitivas y organizar nuestro código de manera inteligente.
🏗️ ¿Qué son las funciones?
Las funciones son bloques de código reutilizable que realizan una tarea específica. Son como máquinas especializadas en nuestro almacén que:
- Reciben materias primas (parámetros de entrada)
- Procesan la información (ejecutan el código interno)
- Entregan un producto terminado (devuelven un resultado)
- Se pueden usar múltiples veces sin tener que reconstruir la máquina
# Una función simple en acción
def saludar_cliente(nombre):
"""Máquina saludadora personalizada"""
saludo = f"¡Bienvenido a nuestro almacén, {nombre}!"
return saludo
# Usar la máquina múltiples veces
mensaje1 = saludar_cliente("Ana")
mensaje2 = saludar_cliente("Carlos")
print(mensaje1) # ¡Bienvenido a nuestro almacén, Ana!
print(mensaje2) # ¡Bienvenido a nuestro almacén, Carlos!
Mi perspectiva personal: Siempre pienso en las funciones como pequeñas fábricas especializadas. Cada función tiene un trabajo específico que hace muy bien, y puedes usar esa fábrica tantas veces como necesites. Esta forma de pensar me ayuda a escribir código más organizado y a identificar qué partes de mi programa podrían convertirse en funciones útiles.
¿Por qué necesitamos funciones?
Las funciones son fundamentales para escribir código de calidad porque:
- Eliminan repetición - No escribes el mismo código una y otra vez
- Organizan el código - Dividen problemas grandes en piezas manejables
- Facilitan el mantenimiento - Los cambios se hacen en un solo lugar
- Permiten reutilización - El mismo código puede usarse en diferentes contextos
- Hacen el código más legible - Los nombres de funciones explican qué hace el código
Analogía del almacén: La fábrica de herramientas
Imagina que nuestro almacén tiene una fábrica de herramientas donde:
- Las funciones son máquinas especializadas (calculadora de precios, empaquetadora, etiquetadora)
- Los parámetros son los materiales que introducimos en la máquina
- El código interno es el proceso de manufactura de la máquina
- El valor de retorno es el producto final que sale de la máquina
Contenido de este capítulo
En este capítulo aprenderás sobre:
-
Crear funciones con def - Cómo construir tus propias máquinas especializadas
- Sintaxis básica de funciones
- Nombrar funciones apropiadamente
- Documentar funciones con docstrings
-
Parámetros y argumentos - Cómo alimentar tus máquinas con datos
- Parámetros posicionales y por nombre
- Valores por defecto
- *args y **kwargs
-
Retorno de valores - Cómo obtener resultados de tus máquinas
- La declaración return
- Retornar múltiples valores
- Funciones que no retornan nada
-
Diagramas de Funciones - Visualización del flujo de funciones
- Representación gráfica de funciones
- Flujo de datos y control
- Ejemplos visuales
Mapa conceptual
FUNCIONES (Máquinas especializadas)
|
|-- Definición (def)
| |-- Nombre descriptivo
| |-- Parámetros de entrada
| |-- Código de procesamiento
| |-- Valor de retorno
|
|-- Llamada a función
| |-- Pasar argumentos
| |-- Ejecutar código
| |-- Recibir resultado
|
|-- Beneficios
|-- Reutilización de código
|-- Organización
|-- Mantenimiento fácil
|-- Legibilidad mejorada
¡Comencemos a construir tus propias herramientas especializadas!
🧭 Navegación:
- Anterior: Estructuras de Datos
- Siguiente: Módulos y la Biblioteca Estándar
Capítulos de esta sección:
- Introducción a Funciones (página actual)
- Crear funciones con def
- Parámetros y argumentos
- Retorno de valores
- Diagramas de Funciones
Crear funciones con def
🧭 Navegación:
- Anterior: Funciones – Bloques de Construcción para Reutilización
- Siguiente: Parámetros y argumentos
¡Bienvenido al taller de creación de herramientas de nuestro almacén! Las funciones son como máquinas especializadas que podemos diseñar y construir para automatizar tareas específicas. Una vez que aprendas a crearlas, tu eficiencia como “gerente del almacén” se multiplicará exponencialmente.
🏭 ¿Qué es una función?
Imagina que en tu almacén tienes que calcular el precio final de productos con descuentos e impuestos todo el tiempo. En lugar de hacer estos cálculos manualmente cada vez, puedes construir una máquina calculadora de precios que:
- Reciba el precio original como entrada
- Procese los cálculos internamente
- Entregue el precio final como resultado
Esa máquina es una función en programación.
# Antes: Cálculos repetitivos y propensos a errores
precio_laptop = 1500
precio_laptop_con_descuento = precio_laptop * 0.90 # 10% descuento
precio_laptop_final = precio_laptop_con_descuento * 1.16 # 16% impuesto
precio_mouse = 35
precio_mouse_con_descuento = precio_mouse * 0.90
precio_mouse_final = precio_mouse_con_descuento * 1.16
precio_teclado = 120
precio_teclado_con_descuento = precio_teclado * 0.90
precio_teclado_final = precio_teclado_con_descuento * 1.16
# Después: Una función reutilizable
def calcular_precio_final(precio_original):
"""Máquina calculadora de precios del almacén"""
precio_con_descuento = precio_original * 0.90
precio_final = precio_con_descuento * 1.16
return precio_final
# Uso simple y confiable
precio_laptop_final = calcular_precio_final(1500)
precio_mouse_final = calcular_precio_final(35)
precio_teclado_final = calcular_precio_final(120)
🔧 Anatomía de una función
La palabra clave def
Como en nuestro almacén necesitamos definir las especificaciones de cada máquina antes de construirla, en Python usamos def para definir una función:
def nombre_de_la_funcion():
"""Documentación de lo que hace la máquina"""
# Código que ejecuta la máquina
pass
Partes esenciales de una función
def procesar_pedido(codigo_producto, cantidad):
"""
Procesa un pedido en el almacén.
Args:
codigo_producto (str): Código único del producto
cantidad (int): Cantidad solicitada
Returns:
dict: Información del pedido procesado
"""
# 1. Validar que el producto existe
if not codigo_producto.startswith("PROD"):
return {"error": "Código de producto inválido"}
# 2. Verificar stock disponible
stock_actual = consultar_stock(codigo_producto)
if stock_actual < cantidad:
return {"error": "Stock insuficiente"}
# 3. Procesar el pedido
precio_unitario = obtener_precio(codigo_producto)
total = precio_unitario * cantidad
# 4. Retornar el resultado
return {
"codigo": codigo_producto,
"cantidad": cantidad,
"total": total,
"status": "procesado"
}
Análisis de las partes:
def- Palabra clave para definir la funciónprocesar_pedido- Nombre descriptivo de la función(codigo_producto, cantidad)- Parámetros de entrada"""docstring"""- Documentación de la función- Cuerpo de la función - El código que se ejecuta
return- Valor que devuelve la función
🏗️ Creando tu primera función
Función básica sin parámetros
def saludar_empleados():
"""Función que saluda a los empleados del almacén"""
print("¡Buenos días, equipo del almacén!")
print("¡Listos para un día productivo!")
# Llamar (usar) la función
saludar_empleados()
Salida:
¡Buenos días, equipo del almacén!
¡Listos para un día productivo!
Función con un parámetro
def calcular_area_zona(longitud):
"""Calcula el área de una zona cuadrada del almacén"""
area = longitud ** 2
print(f"El área de la zona es: {area} metros cuadrados")
# Usar la función
calcular_area_zona(10) # Área de 100 m²
calcular_area_zona(25) # Área de 625 m²
Función con múltiples parámetros
def generar_etiqueta_producto(nombre, precio, categoria, en_oferta=False):
"""Genera una etiqueta de precio para un producto"""
etiqueta = f"🏷️ {nombre}\n"
etiqueta += f"💰 Precio: ${precio:.2f}\n"
etiqueta += f"📂 Categoría: {categoria}\n"
if en_oferta:
etiqueta += "🔥 ¡EN OFERTA!"
print(etiqueta)
# Ejemplos de uso
generar_etiqueta_producto("Laptop Gaming", 1500.00, "Electrónicos")
generar_etiqueta_producto("Mouse Inalámbrico", 35.99, "Accesorios", True)
📊 Funciones que retornan valores
Diferencia entre print y return
# Función que IMPRIME (no retorna)
def mostrar_descuento(precio, porcentaje):
"""Muestra el descuento pero no retorna nada útil"""
descuento = precio * (porcentaje / 100)
print(f"Descuento: ${descuento:.2f}")
# No tiene return, por lo que retorna None implícitamente
# Función que RETORNA (más útil)
def calcular_descuento(precio, porcentaje):
"""Calcula y retorna el valor del descuento"""
descuento = precio * (porcentaje / 100)
return descuento
# Comparación de uso
mostrar_descuento(100, 15) # Imprime: Descuento: $15.00
resultado = mostrar_descuento(100, 15) # resultado = None (no útil)
descuento = calcular_descuento(100, 15) # descuento = 15.0 (útil!)
precio_final = 100 - descuento # Podemos usar el resultado
print(f"Precio final: ${precio_final:.2f}")
Función calculadora completa del almacén
def calcular_metricas_venta(precio_base, cantidad, descuento_porcentaje=0, impuesto_porcentaje=16):
"""
Calculadora completa de métricas de venta del almacén.
Args:
precio_base (float): Precio unitario del producto
cantidad (int): Cantidad de productos vendidos
descuento_porcentaje (float): Porcentaje de descuento (0-100)
impuesto_porcentaje (float): Porcentaje de impuesto (0-100)
Returns:
dict: Diccionario con todas las métricas calculadas
"""
# Cálculos paso a paso
subtotal = precio_base * cantidad
descuento = subtotal * (descuento_porcentaje / 100)
subtotal_con_descuento = subtotal - descuento
impuesto = subtotal_con_descuento * (impuesto_porcentaje / 100)
total_final = subtotal_con_descuento + impuesto
# Retornar todas las métricas
return {
"subtotal": subtotal,
"descuento": descuento,
"subtotal_con_descuento": subtotal_con_descuento,
"impuesto": impuesto,
"total_final": total_final,
"ahorro_cliente": descuento
}
# Ejemplo de uso
venta = calcular_metricas_venta(precio_base=50, cantidad=3, descuento_porcentaje=10)
print(f"📊 RESUMEN DE VENTA")
print(f"Subtotal: ${venta['subtotal']:.2f}")
print(f"Descuento: ${venta['descuento']:.2f}")
print(f"Impuesto: ${venta['impuesto']:.2f}")
print(f"Total: ${venta['total_final']:.2f}")
print(f"Ahorro del cliente: ${venta['ahorro_cliente']:.2f}")
🎨 Mejores prácticas para crear funciones
1. Nombres descriptivos y claros
# ❌ Nombres poco descriptivos
def calc(x, y):
return x * y * 0.16
def proc(data):
# ¿Qué procesa? ¿Cómo?
pass
# ✅ Nombres descriptivos
def calcular_impuesto_venta(precio_base, cantidad):
"""Calcula el impuesto de una venta basado en precio y cantidad"""
return precio_base * cantidad * 0.16
def procesar_devolucion_producto(producto_info):
"""Procesa la devolución de un producto al inventario"""
pass
2. Funciones pequeñas con una responsabilidad
# ❌ Función que hace demasiadas cosas
def procesar_pedido_completo(codigo, cantidad, cliente):
# Validar producto
# Verificar stock
# Calcular precios
# Procesar pago
# Actualizar inventario
# Enviar email
# Generar factura
# Actualizar estadísticas
pass # ¡Demasiadas responsabilidades!
# ✅ Funciones especializadas
def validar_producto(codigo):
"""Se enfoca solo en validar si un producto es válido"""
return codigo.startswith("PROD") and len(codigo) == 8
def verificar_stock_disponible(codigo, cantidad_solicitada):
"""Se enfoca solo en verificar stock"""
stock_actual = obtener_stock(codigo)
return stock_actual >= cantidad_solicitada
def calcular_precio_total(codigo, cantidad):
"""Se enfoca solo en calcular precios"""
precio_unitario = obtener_precio(codigo)
return precio_unitario * cantidad
3. Documentación clara con docstrings
def gestionar_inventario_automatico(productos, umbral_minimo=10):
"""
Gestiona automáticamente el inventario basado en umbrales mínimos.
Esta función revisa todos los productos en el inventario y genera
órdenes de recompra automáticas para aquellos productos cuyo stock
está por debajo del umbral especificado.
Args:
productos (list): Lista de diccionarios con información de productos.
Cada producto debe tener las claves: 'codigo', 'nombre', 'stock'
umbral_minimo (int, opcional): Stock mínimo antes de generar reorden.
Por defecto es 10.
Returns:
dict: Resultado del procesamiento con las siguientes claves:
- 'productos_procesados': Número total de productos revisados
- 'reordenes_generadas': Número de órdenes de recompra creadas
- 'productos_criticos': Lista de productos con stock crítico
Raises:
ValueError: Si la lista de productos está vacía o mal formateada
TypeError: Si umbral_minimo no es un número entero
Example:
>>> productos = [
... {'codigo': 'PROD001', 'nombre': 'Laptop', 'stock': 5},
... {'codigo': 'PROD002', 'nombre': 'Mouse', 'stock': 15}
... ]
>>> resultado = gestionar_inventario_automatico(productos, 8)
>>> print(resultado['reordenes_generadas'])
1
"""
# Implementación de la función...
pass
🔄 Funciones recursivas: Máquinas que se llaman a sí mismas
Algunas máquinas en nuestro almacén necesitan usar versiones más pequeñas de sí mismas. Por ejemplo, una máquina que cuenta todos los elementos en cajas que pueden contener otras cajas:
def contar_elementos_totales(contenedor):
"""
Cuenta todos los elementos en un contenedor que puede tener sub-contenedores.
Args:
contenedor (list): Lista que puede contener números o otras listas
Returns:
int: Número total de elementos contados
"""
total = 0
for elemento in contenedor:
if isinstance(elemento, list): # Si es una sub-caja
# La máquina se llama a sí misma para contar la sub-caja
total += contar_elementos_totales(elemento)
else: # Si es un elemento individual
total += 1
return total
# Ejemplo de almacén con estructura anidada
almacen_principal = [
"producto1",
"producto2",
["sub_caja1", "sub_caja2", ["caja_pequena1", "caja_pequena2"]],
"producto3",
["otra_subcaja"]
]
total_productos = contar_elementos_totales(almacen_principal)
print(f"Total de productos en el almacén: {total_productos}")
# Resultado: 7 productos
🚀 Funciones lambda: Máquinas portátiles
Para tareas muy simples, Python permite crear mini-máquinas portátiles llamadas funciones lambda:
# Función tradicional
def aplicar_descuento_standard(precio):
return precio * 0.90
# Función lambda equivalente (para casos simples)
aplicar_descuento = lambda precio: precio * 0.90
# Uso práctico con listas de productos
precios = [100, 250, 75, 400, 150]
# Aplicar descuento a todos los precios
precios_con_descuento = list(map(lambda precio: precio * 0.90, precios))
print(f"Precios originales: {precios}")
print(f"Precios con descuento: {precios_con_descuento}")
# Filtrar productos caros (más de $200)
productos_premium = list(filter(lambda precio: precio > 200, precios))
print(f"Productos premium: {productos_premium}")
🏭 Proyecto práctico: Sistema de gestión de productos
Vamos a crear un sistema completo con múltiples funciones especializadas:
# Base de datos simulada de productos
productos_almacen = [
{"codigo": "LAP001", "nombre": "Laptop Gaming", "precio": 1500, "stock": 5, "categoria": "Electronica"},
{"codigo": "MOU001", "nombre": "Mouse Inalámbrico", "precio": 35, "stock": 20, "categoria": "Accesorios"},
{"codigo": "TEC001", "nombre": "Teclado Mecánico", "precio": 120, "stock": 8, "categoria": "Accesorios"},
{"codigo": "MON001", "nombre": "Monitor 4K", "precio": 350, "stock": 3, "categoria": "Electronica"}
]
def buscar_producto_por_codigo(codigo):
"""Busca un producto específico por su código"""
for producto in productos_almacen:
if producto["codigo"] == codigo:
return producto
return None
def calcular_valor_total_categoria(categoria):
"""Calcula el valor total de inventario de una categoría"""
valor_total = 0
for producto in productos_almacen:
if producto["categoria"] == categoria:
valor_total += producto["precio"] * producto["stock"]
return valor_total
def generar_reporte_stock_bajo(umbral=10):
"""Genera reporte de productos con stock bajo"""
productos_criticos = []
for producto in productos_almacen:
if producto["stock"] <= umbral:
productos_criticos.append({
"codigo": producto["codigo"],
"nombre": producto["nombre"],
"stock_actual": producto["stock"],
"urgencia": "CRÍTICO" if producto["stock"] <= 5 else "BAJO"
})
return productos_criticos
def procesar_venta(codigo_producto, cantidad):
"""Procesa una venta y actualiza el inventario"""
producto = buscar_producto_por_codigo(codigo_producto)
if not producto:
return {"error": "Producto no encontrado"}
if producto["stock"] < cantidad:
return {"error": f"Stock insuficiente. Disponible: {producto['stock']}"}
# Actualizar stock
producto["stock"] -= cantidad
total_venta = producto["precio"] * cantidad
return {
"venta_exitosa": True,
"producto": producto["nombre"],
"cantidad_vendida": cantidad,
"total": total_venta,
"stock_restante": producto["stock"]
}
# Ejemplo de uso del sistema
print("=== SISTEMA DE GESTIÓN DE ALMACÉN ===")
# Buscar un producto
laptop = buscar_producto_por_codigo("LAP001")
print(f"Producto encontrado: {laptop['nombre']} - ${laptop['precio']}")
# Calcular valor por categoría
valor_electronica = calcular_valor_total_categoria("Electronica")
print(f"Valor total en Electrónica: ${valor_electronica}")
# Generar reporte de stock
productos_criticos = generar_reporte_stock_bajo(umbral=8)
print(f"Productos con stock crítico:")
for producto in productos_criticos:
print(f" - {producto['nombre']}: {producto['stock_actual']} unidades ({producto['urgencia']})")
# Procesar una venta
resultado_venta = procesar_venta("LAP001", 2)
if resultado_venta.get("venta_exitosa"):
print(f"Venta procesada: {resultado_venta['cantidad_vendida']} x {resultado_venta['producto']}")
print(f"Total: ${resultado_venta['total']}")
print(f"Stock restante: {resultado_venta['stock_restante']}")
🎯 Comprueba tu comprensión
Ejercicio 1: Función básica
Crea una función llamada calcular_capacidad_estante que reciba la altura, ancho y profundidad de un estante y retorne su volumen en metros cúbicos.
def calcular_capacidad_estante(altura, ancho, profundidad):
# Tu código aquí
pass
# Prueba tu función
volumen = calcular_capacidad_estante(2.5, 1.2, 0.8)
print(f"Capacidad del estante: {volumen} m³")
Ejercicio 2: Función con validación
Crea una función llamada validar_codigo_producto que reciba un código de producto y verifique que:
- Tenga exactamente 6 caracteres
- Los primeros 3 sean letras mayúsculas
- Los últimos 3 sean números
def validar_codigo_producto(codigo):
# Tu código aquí
pass
# Pruebas
print(validar_codigo_producto("LAP001")) # Debería ser True
print(validar_codigo_producto("lap001")) # Debería ser False
print(validar_codigo_producto("LAPTOP1")) # Debería ser False
Ejercicio 3: Función de procesamiento
Crea una función llamada procesar_lista_precios que reciba una lista de precios y un porcentaje de descuento, y retorne una nueva lista con los precios con descuento aplicado.
def procesar_lista_precios(precios, descuento_porcentaje):
# Tu código aquí
pass
# Prueba
precios_originales = [100, 250, 75, 400]
precios_rebajados = procesar_lista_precios(precios_originales, 15)
print(f"Precios rebajados: {precios_rebajados}")
💡 Consejos para el éxito
- Piensa en funciones como herramientas: Cada función debe tener un propósito específico y claro
- Reutilización es clave: Si escribes el mismo código más de 2 veces, crea una función
- Nombres descriptivos: El nombre debe explicar qué hace la función sin necesidad de leer el código
- Documenta siempre: Usa docstrings para explicar propósito, parámetros y valor de retorno
- Funciones pequeñas: Es mejor tener muchas funciones pequeñas que pocas funciones grandes
- Prueba tu código: Siempre verifica que tus funciones funcionen con diferentes valores de entrada
🎉 ¡Felicitaciones!
Has aprendido a crear máquinas especializadas (funciones) para tu almacén digital. Estas herramientas te permitirán:
- ✅ Automatizar tareas repetitivas
- ✅ Organizar mejor tu código
- ✅ Reducir errores y bugs
- ✅ Hacer tu código más legible y mantenible
- ✅ Crear soluciones escalables
En la siguiente sección aprenderemos sobre parámetros y argumentos: cómo hacer que nuestras máquinas sean más flexibles y potentes.
🧭 Navegación:
- Anterior: Funciones – Bloques de Construcción para Reutilización
- Siguiente: Parámetros y argumentos
Parámetros y argumentos
🧭 Navegación:
- Anterior: Crear funciones con def
- Siguiente: Retorno de valores
¡Bienvenido al departamento de configuración de máquinas de nuestro almacén! Hasta ahora has aprendido a crear funciones básicas, pero ahora vamos a convertirlas en máquinas súper flexibles que pueden adaptarse a diferentes situaciones. Los parámetros y argumentos son como los controles y configuraciones que hacen que una máquina sea versátil.
🔧 ¿Qué son los parámetros y argumentos?
Imagina que tienes una máquina etiquetadora en tu almacén. Esta máquina puede crear etiquetas, pero necesita que le digas:
- ¿Qué texto poner?
- ¿De qué color debe ser?
- ¿Qué tamaño usar?
Estos “ajustes” que le das a la máquina son los argumentos, y los “controles” que tiene la máquina para recibir esos ajustes son los parámetros.
# Los parámetros son los "controles" de la máquina
def crear_etiqueta(texto, color, tamaño):
"""Máquina etiquetadora del almacén"""
etiqueta = f"[{color.upper()}] {texto} (Tamaño: {tamaño})"
return etiqueta
# Los argumentos son los "valores" que pasamos a esos controles
etiqueta1 = crear_etiqueta("FRÁGIL", "rojo", "grande")
etiqueta2 = crear_etiqueta("Electrónicos", "azul", "mediano")
📋 Tipos de parámetros
1. Parámetros obligatorios (posicionales)
Son como los controles esenciales de la máquina que SIEMPRE necesitas configurar:
def calcular_precio_envio(peso, distancia, tipo_envio):
"""
Calcula el precio de envío de un producto.
TODOS los parámetros son obligatorios - la máquina no funciona sin ellos.
"""
precio_base = peso * 2.5 # $2.5 por kg
precio_distancia = distancia * 0.1 # $0.1 por km
multiplicador = {
"express": 2.0,
"normal": 1.0,
"economico": 0.7
}
precio_final = (precio_base + precio_distancia) * multiplicador[tipo_envio]
return precio_final
# TODOS los argumentos son obligatorios
precio = calcular_precio_envio(5.2, 150, "express")
print(f"Precio de envío: ${precio:.2f}")
# ❌ Esto dará error - faltan argumentos
# precio = calcular_precio_envio(5.2) # Error: faltan distancia y tipo_envio
2. Parámetros opcionales (con valores por defecto)
Son como los controles con configuración automática - si no los ajustas, usan un valor por defecto:
def procesar_pedido(codigo_producto, cantidad, descuento=0, urgente=False, notas=""):
"""
Procesa un pedido con configuraciones opcionales.
Parámetros obligatorios: codigo_producto, cantidad
Parámetros opcionales: descuento, urgente, notas
"""
precio_base = obtener_precio(codigo_producto) * cantidad
precio_con_descuento = precio_base * (1 - descuento/100)
costo_urgente = 50 if urgente else 0
precio_final = precio_con_descuento + costo_urgente
pedido = {
"codigo": codigo_producto,
"cantidad": cantidad,
"precio_final": precio_final,
"urgente": urgente,
"notas": notas if notas else "Sin notas especiales"
}
return pedido
# Usando solo parámetros obligatorios
pedido1 = procesar_pedido("LAP001", 2)
# Usando algunos parámetros opcionales
pedido2 = procesar_pedido("MOU001", 1, descuento=10)
# Usando todos los parámetros
pedido3 = procesar_pedido("TEC001", 1, descuento=15, urgente=True, notas="Cliente VIP")
3. Parámetros con palabras clave
Puedes especificar exactamente qué control quieres ajustar usando el nombre del parámetro:
def generar_reporte_inventario(categoria, incluir_agotados=True, ordenar_por="nombre", formato="texto"):
"""Genera un reporte personalizado del inventario"""
print(f"Generando reporte de {categoria}")
print(f"Incluir agotados: {incluir_agotados}")
print(f"Ordenar por: {ordenar_por}")
print(f"Formato: {formato}")
# Argumentos posicionales (en orden)
generar_reporte_inventario("Electrónicos", False, "precio", "PDF")
# Argumentos con palabras clave (cualquier orden)
generar_reporte_inventario(
categoria="Electrónicos",
formato="PDF",
ordenar_por="precio",
incluir_agotados=False
)
# Mezclando posicionales y por palabra clave
generar_reporte_inventario("Electrónicos", ordenar_por="stock", formato="Excel")
🌟 Parámetros avanzados: *args y **kwargs
*args: Para listas variables de argumentos
Como una máquina que puede procesar cualquier cantidad de elementos:
def calcular_total_productos(*precios):
"""
Calcula el total de productos sin importar cuántos sean.
*precios recoge TODOS los argumentos posicionales en una tupla.
"""
total = 0
print(f"Procesando {len(precios)} productos:")
for i, precio in enumerate(precios, 1):
print(f" Producto {i}: ${precio:.2f}")
total += precio
return total
# Puedes pasar cualquier cantidad de precios
total1 = calcular_total_productos(25.99)
total2 = calcular_total_productos(25.99, 89.50, 12.75)
total3 = calcular_total_productos(100, 200, 300, 400, 500)
print(f"Totales: ${total1:.2f}, ${total2:.2f}, ${total3:.2f}")
**kwargs: Para parámetros con nombre variables
Como una máquina súper configurable que acepta cualquier configuración que le envíes:
def crear_producto_personalizado(nombre, precio, **caracteristicas):
"""
Crea un producto con características personalizables.
**caracteristicas recoge TODOS los argumentos con nombre en un diccionario.
"""
producto = {
"nombre": nombre,
"precio": precio
}
# Agregar todas las características adicionales
producto.update(caracteristicas)
print(f"📦 Producto: {nombre}")
print(f"💰 Precio: ${precio:.2f}")
print("🔧 Características adicionales:")
for caracteristica, valor in caracteristicas.items():
print(f" {caracteristica}: {valor}")
return producto
# Cada producto puede tener características diferentes
laptop = crear_producto_personalizado(
"Laptop Gaming",
1500.00,
procesador="Intel i7",
ram="16GB",
almacenamiento="1TB SSD",
tarjeta_grafica="RTX 4060",
garantia="2 años"
)
mouse = crear_producto_personalizado(
"Mouse Inalámbrico",
35.99,
conectividad="Bluetooth",
bateria="6 meses",
color="Negro"
)
Combinando *args y **kwargs
La máquina más flexible del almacén que acepta cualquier configuración:
def procesar_venta_flexible(vendedor, *productos, **opciones_venta):
"""
Procesa una venta súper flexible.
vendedor: Parámetro obligatorio
*productos: Cualquier cantidad de productos
**opciones_venta: Cualquier opción adicional
"""
print(f"👨💼 Vendedor: {vendedor}")
print(f"📦 Productos ({len(productos)}):")
total = 0
for i, producto in enumerate(productos, 1):
print(f" {i}. {producto['nombre']} - ${producto['precio']:.2f}")
total += producto['precio']
print(f"💰 Subtotal: ${total:.2f}")
# Procesar opciones adicionales
if opciones_venta:
print("⚙️ Opciones especiales:")
for opcion, valor in opciones_venta.items():
print(f" {opcion}: {valor}")
# Aplicar descuentos si existen
if 'descuento' in opciones_venta:
descuento = total * (opciones_venta['descuento'] / 100)
total -= descuento
print(f"🎉 Descuento aplicado: -${descuento:.2f}")
print(f"💳 Total final: ${total:.2f}")
return total
# Ejemplo de uso súper flexible
venta = procesar_venta_flexible(
"Ana García", # vendedor (obligatorio)
{"nombre": "Laptop", "precio": 1500}, # *productos
{"nombre": "Mouse", "precio": 35},
{"nombre": "Teclado", "precio": 120},
descuento=10, # **opciones_venta
metodo_pago="tarjeta",
cliente_vip=True,
envio_express=True
)
🎯 Orden de los parámetros
En Python hay un orden específico que debes seguir al definir parámetros:
def funcion_completa(
obligatorio1, # 1. Parámetros posicionales obligatorios
obligatorio2,
opcional1="valor1", # 2. Parámetros opcionales (con default)
opcional2="valor2",
*args, # 3. *args (argumentos posicionales variables)
clave_solo1, # 4. Keyword-only arguments
clave_solo2="default",
**kwargs # 5. **kwargs (argumentos con clave variables)
):
"""Función que muestra el orden correcto de parámetros"""
print(f"Obligatorios: {obligatorio1}, {obligatorio2}")
print(f"Opcionales: {opcional1}, {opcional2}")
print(f"Args adicionales: {args}")
print(f"Clave solo: {clave_solo1}, {clave_solo2}")
print(f"Kwargs: {kwargs}")
# Ejemplo de uso
funcion_completa(
"req1", "req2", # obligatorios
"opt1", # opcional1
"extra1", "extra2", # *args
clave_solo1="valor", # keyword-only
parametro_extra="valor" # **kwargs
)
🏭 Ejemplos prácticos del almacén
1. Sistema de descuentos flexible
def aplicar_descuentos(precio_base, *descuentos_porcentaje, cantidad=1, cliente_vip=False, **promociones):
"""
Sistema flexible de descuentos del almacén.
Args:
precio_base: Precio original del producto
*descuentos_porcentaje: Múltiples descuentos que se aplican secuencialmente
cantidad: Cantidad de productos (con descuento por volumen)
cliente_vip: Si es cliente VIP (descuento especial)
**promociones: Promociones adicionales
"""
precio_actual = precio_base
print(f"💰 Precio base: ${precio_base:.2f}")
# Aplicar descuentos secuenciales
for i, descuento in enumerate(descuentos_porcentaje, 1):
descuento_valor = precio_actual * (descuento / 100)
precio_actual -= descuento_valor
print(f"🎯 Descuento {i} ({descuento}%): -${descuento_valor:.2f} = ${precio_actual:.2f}")
# Descuento por cantidad
precio_total = precio_actual * cantidad
if cantidad >= 5:
descuento_volumen = precio_total * 0.05 # 5% por volumen
precio_total -= descuento_volumen
print(f"📦 Descuento por volumen (5%): -${descuento_volumen:.2f}")
# Descuento VIP
if cliente_vip:
descuento_vip = precio_total * 0.10 # 10% VIP
precio_total -= descuento_vip
print(f"⭐ Descuento VIP (10%): -${descuento_vip:.2f}")
# Promociones especiales
for promo, valor in promociones.items():
if promo == "codigo_promocional" and valor == "VERANO2024":
descuento_promo = precio_total * 0.15
precio_total -= descuento_promo
print(f"🌞 Código promocional: -${descuento_promo:.2f}")
elif promo == "descuento_adicional":
precio_total -= valor
print(f"💸 Descuento adicional: -${valor:.2f}")
print(f"💳 PRECIO FINAL: ${precio_total:.2f}")
return precio_total
# Ejemplo: múltiples descuentos en una venta compleja
precio_final = aplicar_descuentos(
200.00, # precio_base
10, 5, # descuentos del 10% y 5%
cantidad=6, # 6 productos (activa descuento por volumen)
cliente_vip=True, # cliente VIP
codigo_promocional="VERANO2024", # promoción especial
descuento_adicional=20.00 # descuento extra
)
2. Generador de reportes configurables
def generar_reporte(titulo, *datos, formato="texto", incluir_fecha=True,
separador="-", **metadatos):
"""
Generador flexible de reportes del almacén.
"""
from datetime import datetime
# Encabezado del reporte
linea_separador = separador * 50
print(linea_separador)
print(f"📊 {titulo.upper()}")
if incluir_fecha:
fecha_actual = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"📅 Generado: {fecha_actual}")
# Metadatos adicionales
if metadatos:
print("ℹ️ Información adicional:")
for clave, valor in metadatos.items():
print(f" {clave.replace('_', ' ').title()}: {valor}")
print(linea_separador)
# Datos del reporte
if formato == "texto":
for i, dato in enumerate(datos, 1):
print(f"{i}. {dato}")
elif formato == "lista":
for dato in datos:
print(f"• {dato}")
elif formato == "numerado":
for i, dato in enumerate(datos, 1):
print(f"[{i:03d}] {dato}")
print(linea_separador)
print(f"📈 Total de elementos: {len(datos)}")
return len(datos)
# Ejemplos de uso
reporte1 = generar_reporte(
"Productos más vendidos",
"Laptop Gaming - 45 unidades",
"Mouse Inalámbrico - 32 unidades",
"Teclado Mecánico - 28 unidades",
formato="numerado",
generado_por="Sistema automático",
categoria="Electrónicos",
periodo="Último mes"
)
reporte2 = generar_reporte(
"Inventario crítico",
"Monitor 4K - Stock: 2",
"Webcam HD - Stock: 1",
"Parlantes - Stock: 3",
formato="lista",
separador="=",
incluir_fecha=True,
urgencia="Alta",
accion_requerida="Reposición inmediata"
)
🔍 Introspección de funciones
Python te permite inspeccionar las máquinas que has creado:
def maquina_compleja(param1, param2="default", *args, param_clave, **kwargs):
"""Una máquina compleja para demostrar introspección"""
pass
# Inspeccionar los parámetros de la función
import inspect
print("🔍 Análisis de la máquina:")
signature = inspect.signature(maquina_compleja)
for name, param in signature.parameters.items():
print(f"⚙️ {name}:")
print(f" Tipo: {param.kind}")
print(f" Default: {param.default if param.default != param.empty else 'Sin default'}")
# Información adicional
print(f"\n📋 Documentación: {maquina_compleja.__doc__}")
print(f"🏷️ Nombre: {maquina_compleja.__name__}")
🎯 Comprueba tu comprensión
Ejercicio 1: Calculadora de envíos
Crea una función que calcule el costo de envío con múltiples opciones:
def calcular_envio(peso, distancia, tipo="normal", urgente=False, seguro=False, **extras):
"""
Calcula el costo de envío con múltiples opciones.
Args:
peso: Peso en kg (obligatorio)
distancia: Distancia en km (obligatorio)
tipo: "normal", "express", "economico" (default: "normal")
urgente: Si requiere entrega urgente (default: False)
seguro: Si incluye seguro (default: False)
**extras: Servicios adicionales
"""
# Tu código aquí
pass
# Pruebas
costo1 = calcular_envio(2.5, 100)
costo2 = calcular_envio(5.0, 200, tipo="express", urgente=True)
costo3 = calcular_envio(1.2, 50, seguro=True, embalaje_especial=25, manejo_fragil=15)
Ejercicio 2: Procesador de productos
Crea una función que procese una lista variable de productos:
def procesar_productos(*productos, descuento_global=0, **configuraciones):
"""
Procesa múltiples productos con configuraciones flexibles.
Args:
*productos: Lista variable de diccionarios de productos
descuento_global: Descuento aplicado a todos los productos
**configuraciones: Configuraciones adicionales del procesamiento
"""
# Tu código aquí
pass
# Prueba
productos = [
{"nombre": "Laptop", "precio": 1000, "categoria": "Electronica"},
{"nombre": "Mouse", "precio": 30, "categoria": "Accesorios"}
]
resultado = procesar_productos(
*productos,
descuento_global=10,
aplicar_impuesto=True,
moneda="USD",
incluir_garantia=True
)
Ejercicio 3: Validador flexible
Crea una función que valide datos con reglas variables:
def validar_datos(datos, *reglas_obligatorias, permitir_extras=False, **reglas_opcionales):
"""
Valida un diccionario de datos contra reglas flexibles.
Args:
datos: Diccionario con datos a validar
*reglas_obligatorias: Campos que deben existir
permitir_extras: Si permite campos no especificados
**reglas_opcionales: Validaciones opcionales por campo
"""
# Tu código aquí
pass
# Prueba
datos_usuario = {
"nombre": "Ana García",
"email": "ana@email.com",
"edad": 25,
"telefono": "555-0123"
}
es_valido = validar_datos(
datos_usuario,
"nombre", "email", # campos obligatorios
permitir_extras=True,
edad_minima=18,
email_formato=r".*@.*\..*"
)
💡 Mejores prácticas
- Orden consistente: Siempre sigue el orden estándar de parámetros
- Nombres descriptivos: Los parámetros deben explicar qué representan
- Valores por defecto sensatos: Usa defaults que tengan sentido en el contexto
- Documentación clara: Explica todos los parámetros en el docstring
- **No abuses de *args y kwargs: Úsalos cuando realmente aporten flexibilidad
- Validación de entrada: Verifica que los argumentos tengan sentido
🎉 ¡Felicitaciones!
Has aprendido a crear máquinas súper configurables para tu almacén digital. Ahora puedes:
- ✅ Crear funciones flexibles con parámetros opcionales
- ✅ Usar argumentos por palabra clave para mayor claridad
- ✅ Implementar funciones que acepten cantidad variable de argumentos
- ✅ Combinar diferentes tipos de parámetros eficientemente
- ✅ Hacer tu código más reutilizable y mantenible
En la siguiente sección aprenderemos sobre valores de retorno: cómo hacer que nuestras máquinas nos entreguen exactamente lo que necesitamos.
🧭 Navegación:
- Anterior: Crear funciones con def
- Siguiente: Retorno de valores
Retorno de valores
🧭 Navegación:
- Anterior: Parámetros y argumentos
- Siguiente: Módulos y la Biblioteca Estándar
¡Bienvenido al departamento de productos terminados de nuestro almacén! Has aprendido a crear máquinas (funciones) y configurarlas (parámetros), pero ahora necesitas que te entreguen exactamente lo que necesitas. El return es como el área de entrega de tus máquinas, donde recogen el producto final de su trabajo.
📦 ¿Qué es el valor de retorno?
Imagina que tienes una máquina empaquetadora en tu almacén. Puedes darle productos para empaquetar, pero lo que realmente te interesa es recibir de vuelta el paquete terminado para poder usarlo. El return es exactamente eso: la forma en que tu función te entrega el resultado de su trabajo.
# Máquina SIN retorno (solo hace ruido, no entrega nada útil)
def procesar_venta_inutil(producto, precio):
"""Esta máquina solo hace ruido pero no entrega nada"""
total = precio * 1.16 # Calcula con impuesto
print(f"Procesando {producto}: ${total:.2f}")
# ¡No hay return! El cálculo se pierde
# Máquina CON retorno (entrega el producto terminado)
def procesar_venta_util(producto, precio):
"""Esta máquina calcula Y entrega el resultado"""
total = precio * 1.16 # Calcula con impuesto
return total # ¡ENTREGA el resultado!
# Comparación de uso
procesar_venta_inutil("Laptop", 1000) # Solo imprime, no puedo usar el resultado
total_venta = procesar_venta_util("Laptop", 1000) # ¡Ahora puedo usar el resultado!
print(f"Puedo usar este total para más cálculos: ${total_venta:.2f}")
🔄 Tipos de retorno
1. Funciones sin retorno explícito (None)
Son como máquinas de servicio que realizan una acción pero no entregan un producto físico:
def mostrar_inventario(productos):
"""Máquina que muestra información pero no retorna nada útil"""
print("=== INVENTARIO ACTUAL ===")
for producto in productos:
print(f"- {producto['nombre']}: {producto['stock']} unidades")
print("=== FIN DEL INVENTARIO ===")
# No hay return explícito, por lo que retorna None
def registrar_venta(producto, cantidad):
"""Máquina que registra pero no entrega confirmación"""
timestamp = datetime.now()
print(f"[{timestamp}] Venta registrada: {cantidad} x {producto}")
# Tampoco hay return, retorna None implícitamente
# Estas funciones retornan None
resultado1 = mostrar_inventario([{"nombre": "Laptop", "stock": 5}])
resultado2 = registrar_venta("Mouse", 3)
print(f"resultado1: {resultado1}") # None
print(f"resultado2: {resultado2}") # None
2. Funciones con retorno de un solo valor
Son como máquinas especializadas que entregan exactamente un producto:
def calcular_descuento(precio, porcentaje):
"""Máquina calculadora que entrega UN resultado"""
descuento = precio * (porcentaje / 100)
return descuento
def obtener_precio_final(precio_base, descuento, impuesto=0.16):
"""Máquina que entrega el precio procesado"""
precio_con_descuento = precio_base - descuento
precio_final = precio_con_descuento * (1 + impuesto)
return precio_final
def validar_codigo_producto(codigo):
"""Máquina validadora que entrega True o False"""
es_valido = len(codigo) == 6 and codigo[:3].isupper() and codigo[3:].isdigit()
return es_valido
# Usando las máquinas
descuento_calculado = calcular_descuento(1000, 15) # Retorna 150.0
precio_final = obtener_precio_final(1000, descuento_calculado) # Retorna 986.0
es_codigo_valido = validar_codigo_producto("LAP001") # Retorna True
print(f"Descuento: ${descuento_calculado}")
print(f"Precio final: ${precio_final:.2f}")
print(f"Código válido: {es_codigo_valido}")
3. Funciones con múltiples valores de retorno
Son como máquinas de línea de producción que entregan varios productos a la vez:
def analizar_venta(precio, cantidad):
"""Máquina que entrega múltiples métricas de una vez"""
subtotal = precio * cantidad
impuesto = subtotal * 0.16
total = subtotal + impuesto
# Retornamos múltiples valores como una tupla
return subtotal, impuesto, total
def obtener_estadisticas_producto(ventas_producto):
"""Máquina que entrega estadísticas completas"""
total_vendido = sum(ventas_producto)
promedio = total_vendido / len(ventas_producto) if ventas_producto else 0
maximo = max(ventas_producto) if ventas_producto else 0
minimo = min(ventas_producto) if ventas_producto else 0
return total_vendido, promedio, maximo, minimo
# Recibiendo múltiples valores
subtotal, impuesto, total = analizar_venta(100, 5)
print(f"Subtotal: ${subtotal}, Impuesto: ${impuesto:.2f}, Total: ${total:.2f}")
# También puedes recibirlos como una sola tupla
resultado_analisis = analizar_venta(200, 3)
print(f"Resultado completo: {resultado_analisis}")
# Desempaquetar estadísticas
ventas = [120, 85, 200, 150, 95, 180]
total, promedio, max_venta, min_venta = obtener_estadisticas_producto(ventas)
print(f"Total: {total}, Promedio: {promedio:.1f}, Max: {max_venta}, Min: {min_venta}")
4. Funciones que retornan estructuras de datos complejas
Son como máquinas ensambladoras que entregan productos complejos y organizados:
def crear_reporte_producto(codigo, nombre, ventas_mes):
"""Máquina que ensambla un reporte completo"""
reporte = {
"codigo": codigo,
"nombre": nombre,
"ventas": {
"total_unidades": sum(ventas_mes),
"promedio_diario": sum(ventas_mes) / len(ventas_mes),
"mejor_dia": max(ventas_mes),
"peor_dia": min(ventas_mes)
},
"estado": "ACTIVO" if sum(ventas_mes) > 0 else "INACTIVO",
"recomendacion": "Reabastecer" if sum(ventas_mes) > 100 else "Mantener stock"
}
return reporte
def procesar_pedido_completo(productos_pedido):
"""Máquina que entrega un pedido completamente procesado"""
productos_procesados = []
total_pedido = 0
for producto in productos_pedido:
producto_procesado = {
"codigo": producto["codigo"],
"nombre": producto["nombre"],
"cantidad": producto["cantidad"],
"precio_unitario": producto["precio"],
"subtotal": producto["precio"] * producto["cantidad"]
}
productos_procesados.append(producto_procesado)
total_pedido += producto_procesado["subtotal"]
pedido_final = {
"productos": productos_procesados,
"resumen": {
"total_productos": len(productos_procesados),
"total_unidades": sum(p["cantidad"] for p in productos_procesados),
"subtotal": total_pedido,
"impuesto": total_pedido * 0.16,
"total_final": total_pedido * 1.16
},
"metadata": {
"fecha_procesamiento": datetime.now().isoformat(),
"status": "PROCESADO"
}
}
return pedido_final
# Usando máquinas complejas
ventas_laptop = [12, 8, 15, 10, 20, 18, 14]
reporte = crear_reporte_producto("LAP001", "Laptop Gaming", ventas_laptop)
print("📊 REPORTE DE PRODUCTO:")
print(f"Producto: {reporte['nombre']} ({reporte['codigo']})")
print(f"Total vendido: {reporte['ventas']['total_unidades']} unidades")
print(f"Promedio diario: {reporte['ventas']['promedio_diario']:.1f}")
print(f"Estado: {reporte['estado']}")
print(f"Recomendación: {reporte['recomendacion']}")
# Procesando un pedido complejo
productos_para_pedido = [
{"codigo": "LAP001", "nombre": "Laptop", "cantidad": 2, "precio": 1500},
{"codigo": "MOU001", "nombre": "Mouse", "cantidad": 2, "precio": 35},
{"codigo": "TEC001", "nombre": "Teclado", "cantidad": 1, "precio": 120}
]
pedido_procesado = procesar_pedido_completo(productos_para_pedido)
print(f"\n💰 TOTAL DEL PEDIDO: ${pedido_procesado['resumen']['total_final']:.2f}")
🎯 Patrones de retorno avanzados
1. Retorno condicional
Las máquinas pueden entregar diferentes tipos de productos según las condiciones:
def buscar_producto(codigo, inventario):
"""
Máquina buscadora que retorna diferentes cosas según lo que encuentre
"""
for producto in inventario:
if producto["codigo"] == codigo:
# Si lo encuentra, retorna el producto completo
return producto
# Si no lo encuentra, retorna None
return None
def procesar_compra(total, dinero_recibido):
"""Máquina que retorna diferentes resultados según el escenario"""
if dinero_recibido < total:
# Retorna diccionario con error
return {
"exitoso": False,
"error": "Dinero insuficiente",
"faltante": total - dinero_recibido
}
elif dinero_recibido == total:
# Retorna confirmación sin cambio
return {
"exitoso": True,
"cambio": 0,
"mensaje": "Pago exacto recibido"
}
else:
# Retorna confirmación con cambio
return {
"exitoso": True,
"cambio": dinero_recibido - total,
"mensaje": "Compra procesada exitosamente"
}
# Ejemplos de uso
inventario = [
{"codigo": "LAP001", "nombre": "Laptop", "precio": 1500},
{"codigo": "MOU001", "nombre": "Mouse", "precio": 35}
]
# Búsqueda exitosa
producto_encontrado = buscar_producto("LAP001", inventario)
if producto_encontrado:
print(f"Producto encontrado: {producto_encontrado['nombre']}")
else:
print("Producto no encontrado")
# Búsqueda fallida
producto_no_existe = buscar_producto("XYZ999", inventario)
if producto_no_existe is None:
print("Este producto no existe en el inventario")
# Diferentes escenarios de compra
resultado1 = procesar_compra(100, 80) # Dinero insuficiente
resultado2 = procesar_compra(100, 100) # Pago exacto
resultado3 = procesar_compra(100, 120) # Con cambio
for resultado in [resultado1, resultado2, resultado3]:
print(f"Compra exitosa: {resultado['exitoso']}")
if not resultado['exitoso']:
print(f"Error: {resultado['error']}")
else:
print(f"Cambio: ${resultado['cambio']}")
2. Retorno anticipado (Early Return)
Como máquinas con controles de calidad que se detienen temprano si detectan problemas:
def validar_y_procesar_pedido(pedido):
"""
Máquina con múltiples puntos de salida para diferentes validaciones
"""
# Validación 1: ¿Existe el pedido?
if not pedido:
return {"error": "Pedido vacío", "codigo": "E001"}
# Validación 2: ¿Tiene productos?
if not pedido.get("productos"):
return {"error": "Pedido sin productos", "codigo": "E002"}
# Validación 3: ¿Todos los productos tienen precio?
for producto in pedido["productos"]:
if "precio" not in producto or producto["precio"] <= 0:
return {"error": f"Precio inválido para {producto.get('nombre', 'producto desconocido')}", "codigo": "E003"}
# Validación 4: ¿El cliente existe?
if not pedido.get("cliente"):
return {"error": "Cliente no especificado", "codigo": "E004"}
# Si pasó todas las validaciones, procesar normalmente
total = sum(p["precio"] * p["cantidad"] for p in pedido["productos"])
return {
"exitoso": True,
"total": total,
"productos_procesados": len(pedido["productos"]),
"cliente": pedido["cliente"]
}
# Pruebas con diferentes pedidos
pedidos_prueba = [
None, # Pedido vacío
{"cliente": "Ana"}, # Sin productos
{"productos": [{"nombre": "Laptop", "precio": 0}], "cliente": "Juan"}, # Precio inválido
{"productos": [{"nombre": "Mouse", "precio": 35, "cantidad": 2}]}, # Sin cliente
{"productos": [{"nombre": "Laptop", "precio": 1500, "cantidad": 1}], "cliente": "María"} # Válido
]
for i, pedido in enumerate(pedidos_prueba, 1):
resultado = validar_y_procesar_pedido(pedido)
print(f"\nPedido {i}:")
if resultado.get("exitoso"):
print(f"✅ Procesado exitosamente - Total: ${resultado['total']}")
else:
print(f"❌ Error: {resultado['error']} (Código: {resultado['codigo']})")
3. Funciones generadoras (yield)
Como máquinas de producción continua que van entregando productos uno por uno:
def generar_reportes_mensuales(ventas_anuales):
"""
Máquina generadora que produce reportes mes por mes
"""
meses = ["Enero", "Febrero", "Marzo", "Abril", "Mayo", "Junio",
"Julio", "Agosto", "Septiembre", "Octubre", "Noviembre", "Diciembre"]
for i, ventas_mes in enumerate(ventas_anuales):
reporte = {
"mes": meses[i],
"numero_mes": i + 1,
"ventas": ventas_mes,
"promedio_diario": ventas_mes / 30,
"estado": "Excelente" if ventas_mes > 10000 else "Bueno" if ventas_mes > 5000 else "Bajo"
}
yield reporte # Entrega un reporte y pausa hasta la siguiente solicitud
def procesar_inventario_grande(productos):
"""
Máquina que procesa inventarios grandes de forma eficiente
"""
for producto in productos:
# Procesamiento complejo del producto
producto_procesado = {
"codigo": producto["codigo"],
"nombre": producto["nombre"],
"valor_total": producto["precio"] * producto["stock"],
"categoria_valor": "Alto" if producto["precio"] > 500 else "Medio" if producto["precio"] > 100 else "Bajo",
"necesita_reposicion": producto["stock"] < 10
}
yield producto_procesado # Entrega procesado de a uno
# Usando generadores
ventas_por_mes = [8500, 9200, 12000, 11500, 13000, 14500,
15000, 13500, 12800, 11200, 10500, 16000]
print("📅 REPORTES MENSUALES:")
for reporte in generar_reportes_mensuales(ventas_por_mes):
print(f"{reporte['mes']}: ${reporte['ventas']:,} ({reporte['estado']})")
if reporte['numero_mes'] == 6: # Solo mostrar primeros 6 meses
break
# Procesando inventario grande
inventario_grande = [
{"codigo": "LAP001", "nombre": "Laptop Gaming", "precio": 1500, "stock": 8},
{"codigo": "LAP002", "nombre": "Laptop Office", "precio": 800, "stock": 5},
{"codigo": "MOU001", "nombre": "Mouse", "precio": 35, "stock": 25},
{"codigo": "TEC001", "nombre": "Teclado", "precio": 120, "stock": 12}
]
print("\n📦 INVENTARIO PROCESADO:")
for producto_procesado in procesar_inventario_grande(inventario_grande):
print(f"{producto_procesado['nombre']}: ${producto_procesado['valor_total']} (Categoría: {producto_procesado['categoria_valor']})")
if producto_procesado['necesita_reposicion']:
print(f" ⚠️ Requiere reposición")
🛠️ Mejores prácticas para retornos
1. Consistencia en el tipo de retorno
# ❌ Mal: Retorna diferentes tipos según el caso
def buscar_precio_mal(codigo):
if codigo == "LAP001":
return 1500.00 # Retorna float
elif codigo == "MOU001":
return "35 pesos" # Retorna string
else:
return None # Retorna None
# ✅ Bien: Siempre retorna el mismo tipo o estructura
def buscar_precio_bien(codigo):
precios = {"LAP001": 1500.00, "MOU001": 35.00}
if codigo in precios:
return {"encontrado": True, "precio": precios[codigo]}
else:
return {"encontrado": False, "precio": None}
2. Documentación clara del retorno
def calcular_metricas_venta(ventas_diarias):
"""
Calcula métricas completas de ventas.
Args:
ventas_diarias (list): Lista de ventas por día
Returns:
dict: Diccionario con las siguientes claves:
- total (float): Suma total de ventas
- promedio (float): Promedio diario de ventas
- maximo (float): Día de mayor venta
- minimo (float): Día de menor venta
- dias_objetivo (int): Días que superaron objetivo de $1000
- tendencia (str): "CRECIENTE", "DECRECIENTE", o "ESTABLE"
Raises:
ValueError: Si la lista de ventas está vacía
"""
if not ventas_diarias:
raise ValueError("La lista de ventas no puede estar vacía")
total = sum(ventas_diarias)
promedio = total / len(ventas_diarias)
maximo = max(ventas_diarias)
minimo = min(ventas_diarias)
dias_objetivo = sum(1 for venta in ventas_diarias if venta > 1000)
# Calcular tendencia comparando primera y segunda mitad
mitad = len(ventas_diarias) // 2
primera_mitad = sum(ventas_diarias[:mitad]) / mitad
segunda_mitad = sum(ventas_diarias[mitad:]) / (len(ventas_diarias) - mitad)
if segunda_mitad > primera_mitad * 1.1:
tendencia = "CRECIENTE"
elif segunda_mitad < primera_mitad * 0.9:
tendencia = "DECRECIENTE"
else:
tendencia = "ESTABLE"
return {
"total": total,
"promedio": promedio,
"maximo": maximo,
"minimo": minimo,
"dias_objetivo": dias_objetivo,
"tendencia": tendencia
}
3. Manejo de casos especiales
def dividir_seguro(dividendo, divisor):
"""
División segura que maneja casos especiales.
Returns:
tuple: (exito: bool, resultado: float o str)
"""
if divisor == 0:
return False, "Error: División por cero"
if not isinstance(dividendo, (int, float)) or not isinstance(divisor, (int, float)):
return False, "Error: Los argumentos deben ser números"
try:
resultado = dividendo / divisor
return True, resultado
except Exception as e:
return False, f"Error inesperado: {str(e)}"
# Uso seguro
exito, resultado = dividir_seguro(10, 3)
if exito:
print(f"Resultado: {resultado:.2f}")
else:
print(f"Error en la operación: {resultado}")
🎯 Comprueba tu comprensión
Ejercicio 1: Analizador de ventas
Crea una función que analice las ventas de un producto y retorne información completa:
def analizar_producto_ventas(nombre_producto, ventas_diarias, precio_unitario):
"""
Analiza las ventas de un producto y retorna métricas completas.
Args:
nombre_producto: Nombre del producto
ventas_diarias: Lista con cantidad vendida cada día
precio_unitario: Precio por unidad
Returns:
dict: Información completa del análisis
"""
# Tu código aquí
pass
# Prueba
ventas = [12, 8, 15, 10, 20, 5, 18]
resultado = analizar_producto_ventas("Laptop Gaming", ventas, 1500)
print(resultado)
Ejercicio 2: Validador con múltiples retornos
Crea una función que valide un pedido y retorne diferentes resultados:
def validar_pedido_completo(pedido_data):
"""
Valida un pedido completo y retorna el resultado de la validación.
Debe validar:
- Que existan productos
- Que todos tengan precio válido
- Que las cantidades sean positivas
- Que el total no exceda $10,000
Returns:
dict: Resultado de validación con estado y detalles
"""
# Tu código aquí
pass
# Pruebas
pedido1 = {
"productos": [
{"nombre": "Laptop", "precio": 1500, "cantidad": 2},
{"nombre": "Mouse", "precio": 35, "cantidad": 1}
]
}
resultado = validar_pedido_completo(pedido1)
print(resultado)
Ejercicio 3: Generador de reportes
Crea una función generadora que produzca reportes de inventario:
def generar_reportes_inventario(productos):
"""
Generador que produce reportes de productos uno por uno.
Para cada producto debe calcular:
- Valor total en inventario
- Estado del stock (Crítico/Bajo/Normal/Alto)
- Recomendación de acción
Yields:
dict: Reporte individual de cada producto
"""
# Tu código aquí
pass
# Prueba
inventario = [
{"codigo": "LAP001", "nombre": "Laptop", "precio": 1500, "stock": 3},
{"codigo": "MOU001", "nombre": "Mouse", "precio": 35, "stock": 25},
{"codigo": "TEC001", "nombre": "Teclado", "precio": 120, "stock": 8}
]
for reporte in generar_reportes_inventario(inventario):
print(reporte)
💡 Consejos para el éxito
- Siempre documenta qué retorna tu función: Especifica tipo y estructura en el docstring
- Sé consistente: Si una función puede retornar múltiples tipos, usa una estructura consistente
- Maneja casos especiales: Considera qué pasa con entradas vacías, nulas o inválidas
- Usa nombres descriptivos: El retorno debe ser claro por el nombre de la función
- Retorna temprano: Usa early returns para validaciones y casos especiales
- Prefire retornar estructuras: Los diccionarios y tuplas nombradas son más claros que múltiples valores sueltos
🎉 ¡Felicitaciones!
Has dominado el área de entrega de tus máquinas digitales. Ahora puedes:
- ✅ Diseñar funciones que entreguen exactamente lo que necesitas
- ✅ Manejar múltiples valores de retorno eficientemente
- ✅ Crear funciones que se adapten a diferentes escenarios
- ✅ Implementar validaciones con retornos informativos
- ✅ Usar generadores para procesar grandes cantidades de datos
En la siguiente sección aprenderemos sobre módulos estándar: cómo usar las herramientas prefabricadas que Python te ofrece para hacer tu trabajo más eficiente.
🧭 Navegación:
- Anterior: Parámetros y argumentos
- Siguiente: Módulos y la Biblioteca Estándar
Diagramas de Funciones y Módulos
En esta sección visualizaremos cómo funcionan las funciones y módulos en Python para ayudar a comprender su estructura y comportamiento.
Anatomía de una Función
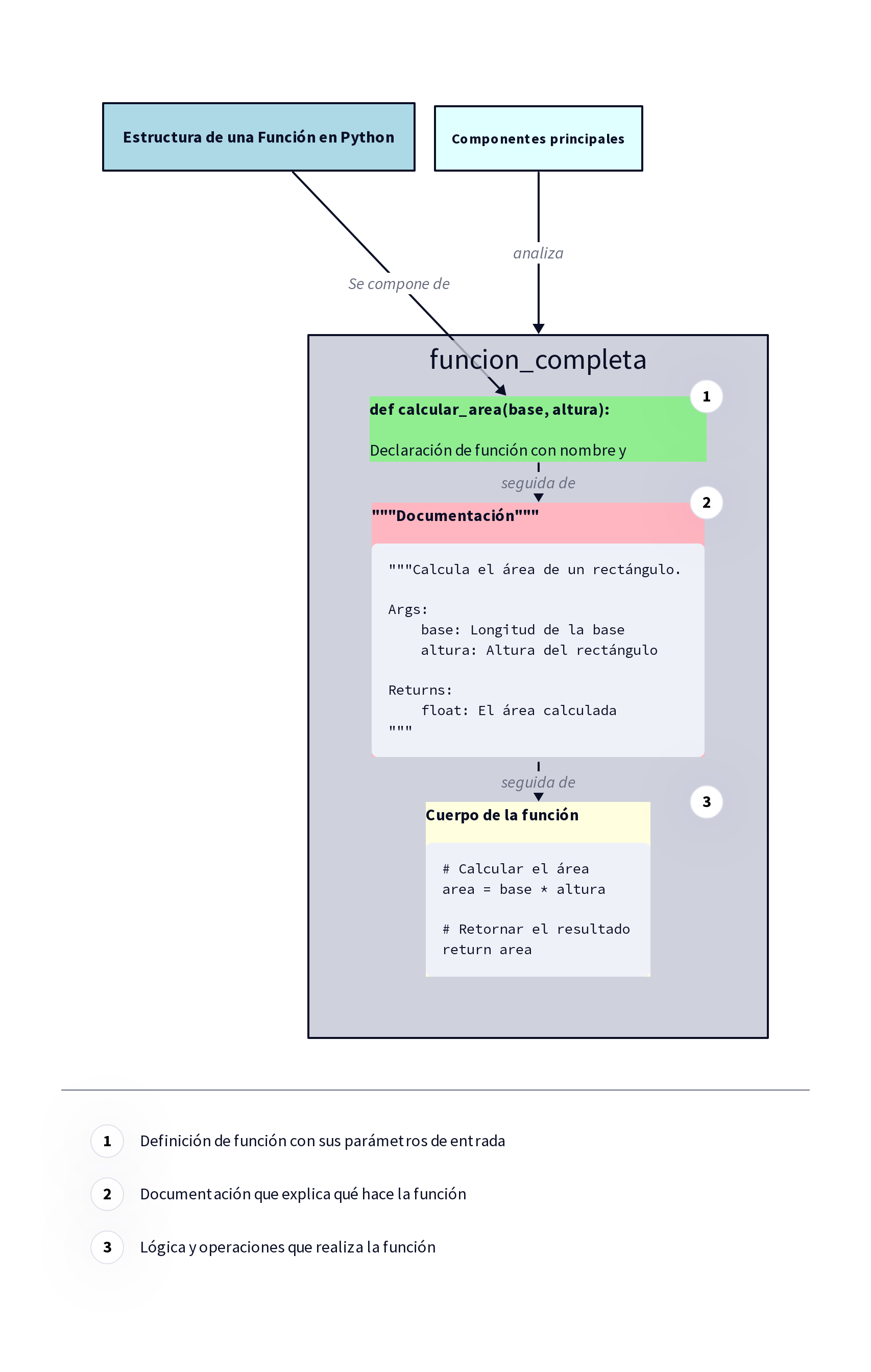
Flujo de Ejecución de una Función (Diagrama de Secuencia)
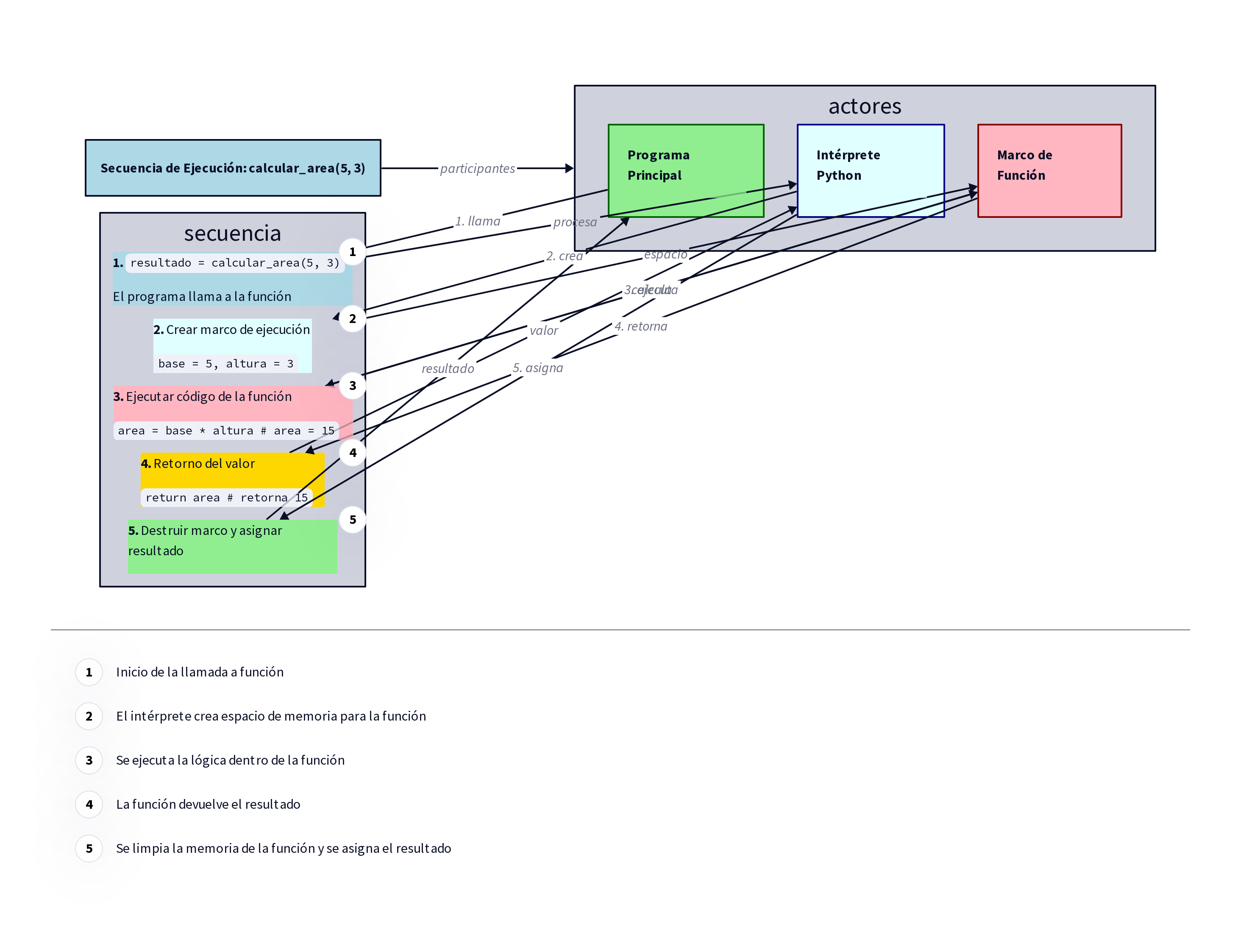
Estructura de Módulos y Paquetes (Diagrama de Árbol)
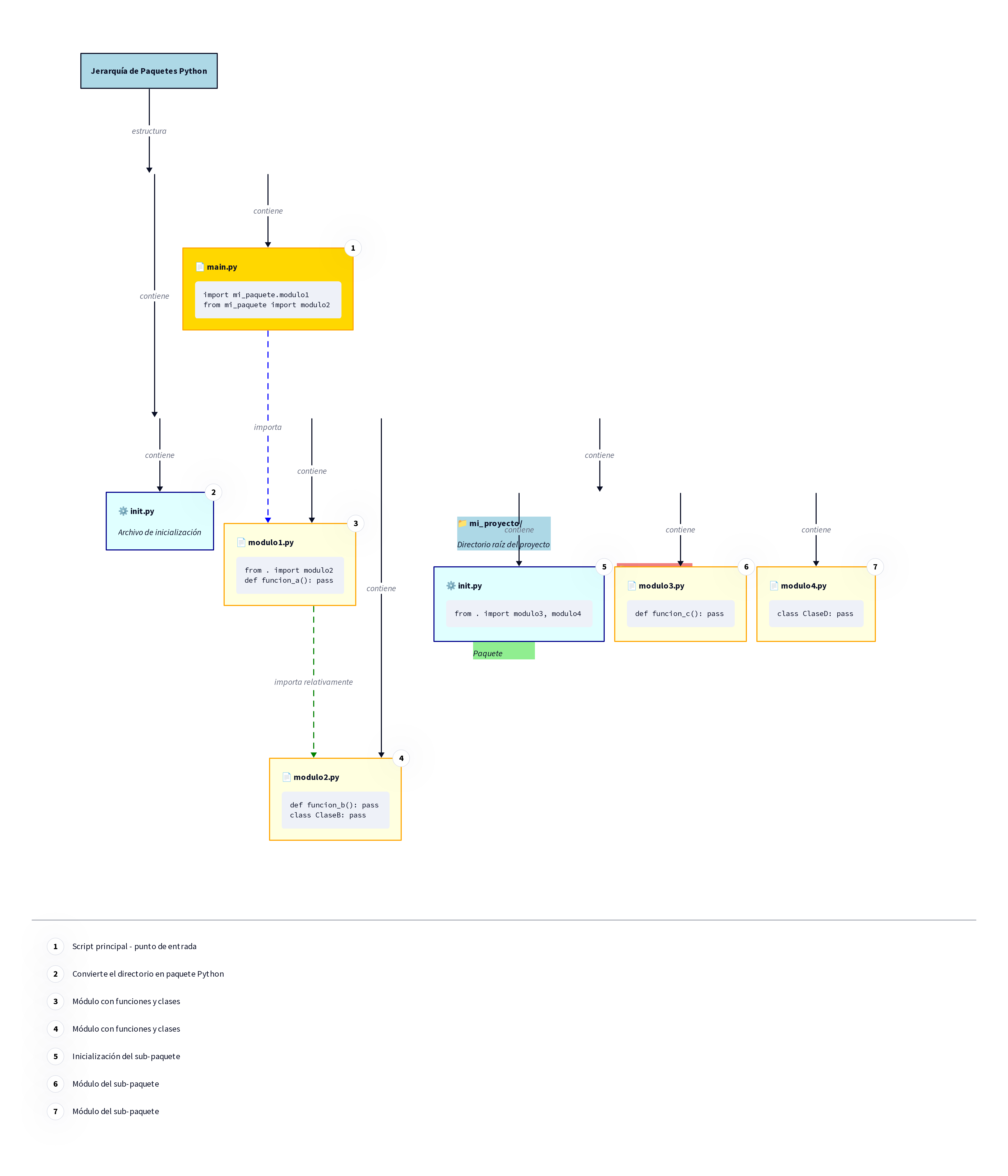
Ciclo de Vida de un Módulo
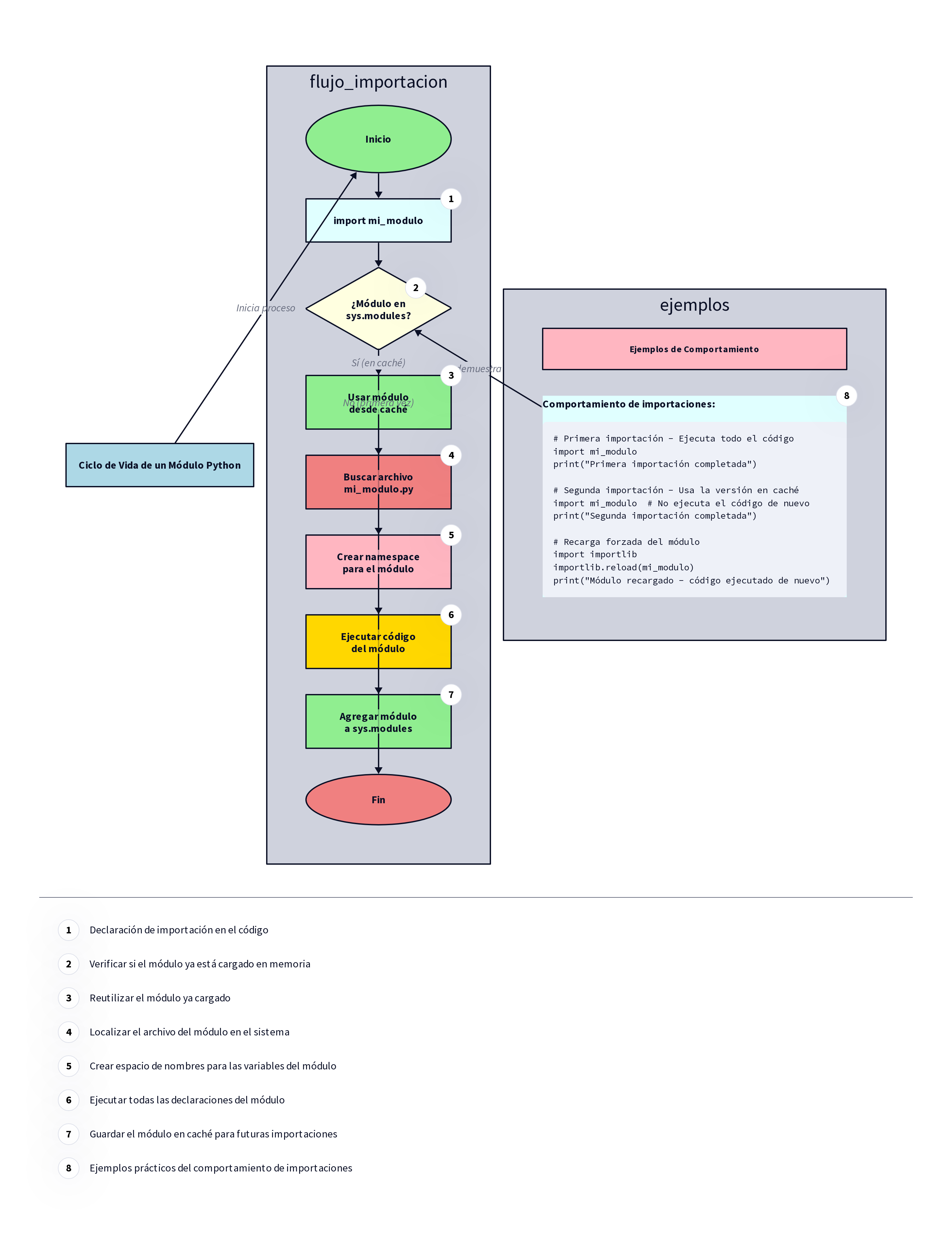
Comportamiento de importaciones:
# Primera importación - Ejecuta todo el código
import mi_modulo
print("Primera importación completada")
# Segunda importación - Usa la versión en caché
import mi_modulo # No ejecuta el código de nuevo
print("Segunda importación completada")
# Recarga forzada del módulo
import importlib
importlib.reload(mi_modulo)
print("Módulo recargado - código ejecutado de nuevo")
Estos diagramas te ayudarán a visualizar cómo funcionan las funciones y módulos en Python, facilitando su comprensión y uso efectivo en tus programas.
Módulos y la Biblioteca Estándar
🧭 Navegación:
- Anterior: Funciones – Bloques de Construcción para Reutilización
- Siguiente: Mini Proyecto – Integrando Todo
¡Bienvenido al almacén central de herramientas de Python! Has aprendido a crear tus propias máquinas (funciones), pero Python viene con un almacén gigantesco de herramientas prefabricadas llamado Standard Library. Es como tener acceso a una ferretería industrial completa sin tener que fabricar cada herramienta desde cero.
¿Qué es la Standard Library?
La Standard Library (Biblioteca Estándar) es una colección enorme de módulos que vienen incluidos con Python. Cada módulo es como un departamento especializado con herramientas específicas para diferentes tipos de trabajo:
- Departamento Matemático:
math- Calculadoras avanzadas y fórmulas - Departamento de Tiempo:
datetime- Relojes, calendarios y cronómetros - Departamento de Azar:
random- Generadores de números aleatorios - Departamento del Sistema:
os- Herramientas para el sistema operativo - Departamento de Archivos:
pathlib- Navegadores de carpetas y archivos
# Importar herramientas de diferentes departamentos
import math # Departamento matemático
import datetime # Departamento de tiempo
import random # Departamento de azar
# Usar las herramientas especializadas
precio_base = 127.89
precio_redondeado = math.ceil(precio_base) # Redondear hacia arriba
print(f"Precio redondeado: ${precio_redondeado}")
fecha_hoy = datetime.date.today() # Obtener fecha actual
print(f"Procesando pedido del: {fecha_hoy}")
numero_factura = random.randint(1000, 9999) # Generar número aleatorio
print(f"Número de factura: {numero_factura}")
¿Por qué usar módulos?
Los módulos de la Standard Library son increíblemente útiles porque:
- Ahorran tiempo - No tienes que reinventar la rueda
- Son confiables - Han sido probados por millones de programadores
- Están optimizados - Funcionan de manera eficiente
- Son gratuitos - Vienen incluidos con Python
- Están documentados - Tienen excelente documentación
Mi perspectiva personal: La Standard Library es como tener un equipo de expertos trabajando para ti. Cuando necesito hacer algo con fechas, no invento mi propio sistema de calendario - uso
datetime. Cuando necesito números aleatorios, usorandom. Es importante aprender qué herramientas existen para no perder tiempo creando algo que ya existe y funciona perfectamente.
Analogía del almacén: El centro de distribución
Imagina que Python tiene un centro de distribución gigante donde:
- Cada módulo es un departamento especializado
- Las funciones del módulo son herramientas específicas en ese departamento
- Importar es como solicitar herramientas de un departamento específico
- Usar las funciones es como operar las herramientas que pediste
Contenido de este capítulo
En este capítulo aprenderás sobre:
- Módulos estándar - El almacén de herramientas de Python
- Qué son los módulos estándar
- Cómo importar y usar módulos
- Módulos más importantes para principiantes
Mapa conceptual
MÓDULOS Y STANDARD LIBRARY
|
|-- Standard Library
| |-- Colección de módulos incluidos
| |-- Probados y optimizados
| |-- Documentación completa
|
|-- Importar módulos
| |-- import modulo
| |-- from modulo import funcion
| |-- import modulo as alias
|
|-- Módulos populares
|-- math (matemáticas)
|-- datetime (fechas y tiempo)
|-- random (números aleatorios)
|-- os (sistema operativo)
|-- pathlib (rutas y archivos)
¡Comencemos a explorar el almacén de herramientas de Python!
🧭 Navegación:
- Anterior: Funciones – Bloques de Construcción para Reutilización
- Siguiente: Mini Proyecto – Integrando Todo
Contenido de este capítulo:
- Introducción a Módulos (página actual)
- Módulos estándar
Módulos estándar
🧭 Navegación:
- Anterior: Módulos y la Biblioteca Estándar
- Siguiente: Mini Proyecto – Integrando Todo
¡Bienvenido al almacén central de herramientas de Python! Has aprendido a crear tus propias máquinas (funciones), pero Python viene con un almacén gigantesco de herramientas prefabricadas llamadas módulos estándar. Es como tener acceso a una ferretería industrial completa sin tener que fabricar cada herramienta desde cero.
🏪 ¿Qué son los módulos estándar?
Los módulos estándar son como departamentos especializados dentro del almacén central de Python. Cada departamento contiene herramientas específicas para diferentes tipos de trabajo:
- Departamento Matemático:
math- Calculadoras avanzadas y fórmulas - Departamento de Tiempo:
datetime- Relojes, calendarios y cronómetros - Departamento de Azar:
random- Generadores de números aleatorios - Departamento del Sistema:
os- Herramientas para el sistema operativo - Departamento de Archivos:
pathlib- Navegadores de carpetas y archivos - Departamento de Internet:
urllib- Herramientas para descargar de internet
# Importar herramientas de diferentes departamentos
import math # Departamento matemático
import datetime # Departamento de tiempo
import random # Departamento de azar
import os # Departamento del sistema
# Usar las herramientas especializadas
precio_base = 127.89
precio_redondeado = math.ceil(precio_base) # Redondear hacia arriba
print(f"Precio redondeado: ${precio_redondeado}")
fecha_hoy = datetime.date.today() # Obtener fecha actual
print(f"Procesando pedido del: {fecha_hoy}")
numero_factura = random.randint(1000, 9999) # Generar número aleatorio
print(f"Número de factura: {numero_factura}")
📚 Formas de importar módulos
1. Importación completa del departamento
import math
# Necesitas especificar el departamento cada vez
area_circulo = math.pi * (5 ** 2)
raiz_cuadrada = math.sqrt(25)
seno_45 = math.sin(math.radians(45))
print(f"Área del círculo: {area_circulo:.2f}")
print(f"Raíz de 25: {raiz_cuadrada}")
print(f"Seno de 45°: {seno_45:.2f}")
2. Importación con alias (apodo)
import datetime as dt # Le ponemos un apodo más corto
# Ahora usamos el apodo
ahora = dt.datetime.now()
mañana = ahora + dt.timedelta(days=1)
fecha_entrega = mañana.strftime("%Y-%m-%d")
print(f"Pedido procesado: {ahora.strftime('%H:%M:%S')}")
print(f"Fecha de entrega: {fecha_entrega}")
3. Importación específica de herramientas
from random import randint, choice, shuffle
from os import getcwd, listdir
from math import pi, sqrt, ceil
# Usamos las herramientas directamente (sin especificar departamento)
numero_aleatorio = randint(1, 100)
producto_aleatorio = choice(["Laptop", "Mouse", "Teclado", "Monitor"])
area_circulo = pi * (10 ** 2)
directorio_actual = getcwd()
print(f"Número: {numero_aleatorio}")
print(f"Producto seleccionado: {producto_aleatorio}")
print(f"Área: {area_circulo:.2f}")
print(f"Trabajando en: {directorio_actual}")
4. Importación de todo (usar con cuidado)
# ⚠️ Usar solo con módulos que conoces bien
from math import *
# Ahora todas las herramientas matemáticas están disponibles directamente
resultado = sqrt(sin(pi/2) + cos(0) + tan(pi/4))
print(f"Resultado complejo: {resultado:.2f}")
🧮 Departamento Matemático (math)
El módulo math es como tener una calculadora científica avanzada en tu almacén:
import math
def calcular_metricas_almacen():
"""Usa herramientas matemáticas para métricas del almacén"""
# Área de zonas circulares del almacén
radio_zona_carga = 15 # metros
area_zona_carga = math.pi * (radio_zona_carga ** 2)
# Volumen de contenedores cilíndricos
altura_contenedor = 3 # metros
volumen_contenedor = area_zona_carga * altura_contenedor
# Distancia entre dos puntos del almacén (usando teorema de Pitágoras)
def distancia_puntos(x1, y1, x2, y2):
return math.sqrt((x2 - x1)**2 + (y2 - y1)**2)
# Coordenadas de estaciones en el almacén
estacion_recepcion = (0, 0)
estacion_empaque = (50, 30)
distancia = distancia_puntos(*estacion_recepcion, *estacion_empaque)
# Redondeo inteligente de precios
precios_originales = [127.89, 45.23, 199.67, 89.12]
precios_redondeados = {
"hacia_arriba": [math.ceil(precio) for precio in precios_originales],
"hacia_abajo": [math.floor(precio) for precio in precios_originales],
"normal": [round(precio, 2) for precio in precios_originales]
}
# Estadísticas con logaritmos (para crecimiento exponencial)
ventas_mensuales = [1000, 1200, 1440, 1728, 2074] # Crecimiento del 20%
tasa_crecimiento = math.log(ventas_mensuales[-1] / ventas_mensuales[0]) / len(ventas_mensuales)
return {
"area_zona_carga": round(area_zona_carga, 2),
"volumen_contenedor": round(volumen_contenedor, 2),
"distancia_estaciones": round(distancia, 2),
"precios_redondeados": precios_redondeados,
"tasa_crecimiento_mensual": round(tasa_crecimiento * 100, 2)
}
# Ejemplo de uso
metricas = calcular_metricas_almacen()
print("📊 MÉTRICAS DEL ALMACÉN:")
print(f"Área de zona de carga: {metricas['area_zona_carga']} m²")
print(f"Volumen de contenedor: {metricas['volumen_contenedor']} m³")
print(f"Distancia entre estaciones: {metricas['distancia_estaciones']} m")
print(f"Tasa de crecimiento: {metricas['tasa_crecimiento_mensual']}% mensual")
# Herramientas matemáticas más utilizadas
print("\n🧮 HERRAMIENTAS MATEMÁTICAS DISPONIBLES:")
print(f"π (pi): {math.pi:.4f}")
print(f"e (euler): {math.e:.4f}")
print(f"Raíz cuadrada de 144: {math.sqrt(144)}")
print(f"2 elevado a la 8: {math.pow(2, 8)}")
print(f"Logaritmo natural de 100: {math.log(100):.2f}")
print(f"Logaritmo base 10 de 1000: {math.log10(1000)}")
📅 Departamento de Tiempo (datetime)
El módulo datetime es como tener relojes, calendarios y cronómetros profesionales:
import datetime as dt
def sistema_gestion_tiempo():
"""Sistema completo de gestión de tiempo para el almacén"""
# Obtener información actual
ahora = dt.datetime.now()
hoy = dt.date.today()
# Crear fechas específicas
apertura_almacen = dt.date(2020, 1, 15)
horario_apertura = dt.time(8, 0, 0) # 8:00 AM
horario_cierre = dt.time(18, 0, 0) # 6:00 PM
# Calcular tiempo en operación
dias_en_operacion = (hoy - apertura_almacen).days
años_en_operacion = dias_en_operacion / 365.25
# Programar entregas futuras
entregas_proximas = []
for i in range(1, 8): # Próximos 7 días
fecha_entrega = hoy + dt.timedelta(days=i)
# Solo días laborales (lunes a viernes)
if fecha_entrega.weekday() < 5:
entregas_proximas.append({
"fecha": fecha_entrega.strftime("%Y-%m-%d"),
"dia_semana": fecha_entrega.strftime("%A"),
"es_laborable": True
})
# Verificar si estamos abiertos ahora
hora_actual = ahora.time()
esta_abierto = horario_apertura <= hora_actual <= horario_cierre
# Calcular tiempo hasta cierre/apertura
if esta_abierto:
tiempo_hasta_cierre = dt.datetime.combine(hoy, horario_cierre) - ahora
mensaje_estado = f"Abierto - Cierra en {tiempo_hasta_cierre}"
else:
mañana = hoy + dt.timedelta(days=1)
tiempo_hasta_apertura = dt.datetime.combine(mañana, horario_apertura) - ahora
mensaje_estado = f"Cerrado - Abre en {tiempo_hasta_apertura}"
# Análisis por trimestres
trimestre_actual = (ahora.month - 1) // 3 + 1
inicio_trimestre = dt.date(ahora.year, (trimestre_actual - 1) * 3 + 1, 1)
dias_transcurridos_trimestre = (hoy - inicio_trimestre).days
return {
"fecha_hora_actual": ahora.strftime("%Y-%m-%d %H:%M:%S"),
"dias_en_operacion": dias_en_operacion,
"años_en_operacion": round(años_en_operacion, 1),
"estado_almacen": mensaje_estado,
"entregas_proximas": entregas_proximas,
"trimestre": {
"numero": trimestre_actual,
"dias_transcurridos": dias_transcurridos_trimestre
}
}
# Sistema de registro de actividades
def registrar_actividad(actividad, timestamp=None):
"""Registra actividades con timestamp automático"""
if timestamp is None:
timestamp = dt.datetime.now()
registro = {
"actividad": actividad,
"timestamp": timestamp.isoformat(),
"fecha_legible": timestamp.strftime("%d/%m/%Y %H:%M:%S"),
"dia_semana": timestamp.strftime("%A"),
"es_fin_semana": timestamp.weekday() >= 5
}
return registro
# Ejemplos de uso
info_tiempo = sistema_gestion_tiempo()
print("⏰ SISTEMA DE GESTIÓN DE TIEMPO:")
print(f"Fecha y hora: {info_tiempo['fecha_hora_actual']}")
print(f"Días en operación: {info_tiempo['dias_en_operacion']}")
print(f"Estado: {info_tiempo['estado_almacen']}")
print(f"Trimestre {info_tiempo['trimestre']['numero']}: día {info_tiempo['trimestre']['dias_transcurridos']}")
print("\n📦 ENTREGAS PROGRAMADAS:")
for entrega in info_tiempo['entregas_proximas'][:3]:
print(f" {entrega['fecha']} ({entrega['dia_semana']})")
# Registrar algunas actividades
actividades = [
"Recepción de mercancía",
"Inventario de productos",
"Procesamiento de pedidos"
]
print("\n📝 REGISTRO DE ACTIVIDADES:")
for actividad in actividades:
registro = registrar_actividad(actividad)
print(f" {registro['fecha_legible']}: {registro['actividad']}")
🎲 Departamento de Azar (random)
El módulo random es como tener dados, ruletas y máquinas de sorteo profesionales:
import random
def sistema_aleatorio_almacen():
"""Sistema de decisiones y selecciones aleatorias para el almacén"""
# Base de datos simulada
productos = [
{"codigo": "LAP001", "nombre": "Laptop Gaming", "stock": 15},
{"codigo": "MOU001", "nombre": "Mouse Inalámbrico", "stock": 50},
{"codigo": "TEC001", "nombre": "Teclado Mecánico", "stock": 25},
{"codigo": "MON001", "nombre": "Monitor 4K", "stock": 8},
{"codigo": "AUD001", "nombre": "Audífonos", "stock": 30}
]
empleados = ["Ana García", "Carlos López", "María Rodríguez", "José Martínez", "Elena Fernández"]
colores_etiqueta = ["rojo", "azul", "verde", "amarillo", "naranja", "morado"]
# 1. Selección aleatoria simple
producto_destacado = random.choice(productos)
empleado_del_mes = random.choice(empleados)
color_promocional = random.choice(colores_etiqueta)
# 2. Números aleatorios para códigos y referencias
numero_factura = random.randint(10000, 99999)
descuento_sorpresa = round(random.uniform(5.0, 25.0), 1) # Entre 5% y 25%
# 3. Muestreo de productos para inventario sorpresa
productos_a_revisar = random.sample(productos, 3) # Seleccionar 3 sin repetición
# 4. Distribución normal para simulación de demanda
# La mayoría de pedidos están cerca del promedio, pocos muy altos o bajos
demanda_simulada = [round(random.normalvariate(100, 20)) for _ in range(7)] # 7 días
demanda_simulada = [max(0, d) for d in demanda_simulada] # No negativos
# 5. Barajado de prioridades de envío
ordenes_envio = [f"Orden-{i:03d}" for i in range(1, 11)]
random.shuffle(ordenes_envio) # Barajar las órdenes
# 6. Simulación de fallos/éxitos
def simular_entrega():
return random.random() < 0.95 # 95% de éxito
resultados_entregas = [simular_entrega() for _ in range(10)]
tasa_exito = sum(resultados_entregas) / len(resultados_entregas) * 100
# 7. Selección ponderada (algunos productos tienen más probabilidad)
pesos_productos = [p["stock"] for p in productos] # Más stock = más probable
producto_tendencia = random.choices(productos, weights=pesos_productos, k=1)[0]
return {
"selecciones": {
"producto_destacado": producto_destacado["nombre"],
"empleado_del_mes": empleado_del_mes,
"color_promocional": color_promocional
},
"numeros_aleatorios": {
"numero_factura": numero_factura,
"descuento_sorpresa": f"{descuento_sorpresa}%"
},
"inventario_sorpresa": [p["nombre"] for p in productos_a_revisar],
"demanda_semanal": demanda_simulada,
"ordenes_priorizadas": ordenes_envio[:5], # Primeras 5
"simulacion_entregas": {
"total_entregas": len(resultados_entregas),
"entregas_exitosas": sum(resultados_entregas),
"tasa_exito": round(tasa_exito, 1)
},
"producto_tendencia": producto_tendencia["nombre"]
}
# Generador de datos de prueba
def generar_datos_prueba(cantidad=100):
"""Genera datos aleatorios para pruebas del sistema"""
nombres = ["Ana", "Carlos", "María", "José", "Elena", "Luis", "Carmen", "Antonio"]
apellidos = ["García", "López", "Rodríguez", "Martínez", "Fernández", "González"]
ciudades = ["Madrid", "Barcelona", "Valencia", "Sevilla", "Bilbao", "Málaga"]
clientes_prueba = []
for i in range(cantidad):
cliente = {
"id": f"CLI{i+1:03d}",
"nombre": random.choice(nombres),
"apellido": random.choice(apellidos),
"ciudad": random.choice(ciudades),
"edad": random.randint(18, 70),
"gasto_promedio": round(random.expovariate(1/200), 2), # Distribución exponencial
"es_vip": random.random() < 0.1 # 10% son VIP
}
clientes_prueba.append(cliente)
return clientes_prueba
# Establecer semilla para resultados reproducibles
random.seed(42) # Mismos resultados en cada ejecución
# Ejemplos de uso
print("🎲 SISTEMA ALEATORIO DEL ALMACÉN:")
datos_aleatorios = sistema_aleatorio_almacen()
print(f"🌟 Producto destacado: {datos_aleatorios['selecciones']['producto_destacado']}")
print(f"👤 Empleado del mes: {datos_aleatorios['selecciones']['empleado_del_mes']}")
print(f"🏷️ Color promocional: {datos_aleatorios['selecciones']['color_promocional']}")
print(f"📄 Número de factura: {datos_aleatorios['numeros_aleatorios']['numero_factura']}")
print(f"💰 Descuento sorpresa: {datos_aleatorios['numeros_aleatorios']['descuento_sorpresa']}")
print(f"\n📊 Demanda simulada (7 días): {datos_aleatorios['demanda_semanal']}")
print(f"📈 Tasa de éxito en entregas: {datos_aleatorios['simulacion_entregas']['tasa_exito']}%")
# Generar algunos clientes de prueba
print("\n👥 CLIENTES DE PRUEBA GENERADOS:")
clientes_muestra = generar_datos_prueba(5)
for cliente in clientes_muestra:
vip = " (VIP)" if cliente["es_vip"] else ""
print(f" {cliente['nombre']} {cliente['apellido']} - {cliente['ciudad']} - ${cliente['gasto_promedio']:.2f}{vip}")
💻 Departamento del Sistema (os)
El módulo os es como tener herramientas para interactuar con el sistema operativo:
import os
from pathlib import Path
def sistema_gestion_archivos():
"""Sistema de gestión de archivos y directorios del almacén"""
# Información del sistema actual
info_sistema = {
"directorio_actual": os.getcwd(),
"usuario": os.getenv("USER", os.getenv("USERNAME", "usuario_desconocido")),
"sistema_operativo": os.name,
"separador_rutas": os.sep,
"variables_entorno": len(os.environ)
}
# Crear estructura de directorios para el almacén
estructura_almacen = [
"datos_almacen",
"datos_almacen/inventario",
"datos_almacen/ventas",
"datos_almacen/reportes",
"datos_almacen/backups",
"datos_almacen/logs"
]
# Crear directorios si no existen
directorios_creados = []
for directorio in estructura_almacen:
try:
os.makedirs(directorio, exist_ok=True)
directorios_creados.append(directorio)
except PermissionError:
print(f"⚠️ Sin permisos para crear: {directorio}")
# Listar contenido del directorio actual
contenido_actual = []
try:
for item in os.listdir("."):
ruta_completa = os.path.join(".", item)
es_directorio = os.path.isdir(ruta_completa)
tamaño = os.path.getsize(ruta_completa) if not es_directorio else 0
contenido_actual.append({
"nombre": item,
"tipo": "Directorio" if es_directorio else "Archivo",
"tamaño": tamaño,
"ruta_completa": os.path.abspath(ruta_completa)
})
except PermissionError:
contenido_actual = [{"error": "Sin permisos para listar directorio"}]
# Trabajar con rutas usando pathlib (más moderno)
directorio_datos = Path("datos_almacen")
archivos_ejemplo = {
"inventario": directorio_datos / "inventario" / "productos.json",
"ventas": directorio_datos / "ventas" / "ventas_2024.csv",
"log": directorio_datos / "logs" / "sistema.log"
}
# Crear archivos de ejemplo
archivos_creados = []
for tipo, archivo in archivos_ejemplo.items():
try:
archivo.parent.mkdir(parents=True, exist_ok=True)
if not archivo.exists():
archivo.write_text(f"# Archivo de {tipo} del almacén\n# Creado automáticamente\n")
archivos_creados.append(str(archivo))
except Exception as e:
print(f"⚠️ Error creando {archivo}: {e}")
return {
"info_sistema": info_sistema,
"directorios_creados": directorios_creados,
"archivos_creados": archivos_creados,
"contenido_directorio": contenido_actual[:5] # Primeros 5 elementos
}
# Utilidades para el sistema de archivos
def crear_respaldo_configuracion():
"""Crea respaldo de archivos de configuración"""
import datetime as dt
timestamp = dt.datetime.now().strftime("%Y%m%d_%H%M%S")
directorio_backup = Path(f"backup_{timestamp}")
try:
directorio_backup.mkdir(exist_ok=True)
# Archivos importantes del sistema a respaldar
archivos_importantes = [
"datos_almacen/inventario/productos.json",
"datos_almacen/ventas/ventas_2024.csv"
]
archivos_respaldados = []
for archivo in archivos_importantes:
ruta_origen = Path(archivo)
if ruta_origen.exists():
nombre_backup = f"{ruta_origen.stem}_backup_{timestamp}{ruta_origen.suffix}"
ruta_destino = directorio_backup / nombre_backup
# Copiar contenido
contenido = ruta_origen.read_text()
ruta_destino.write_text(contenido)
archivos_respaldados.append(str(ruta_destino))
return {
"directorio_backup": str(directorio_backup),
"archivos_respaldados": archivos_respaldados,
"timestamp": timestamp
}
except Exception as e:
return {"error": f"Error creando respaldo: {e}"}
# Ejemplos de uso
print("💻 SISTEMA DE GESTIÓN DE ARCHIVOS:")
gestion = sistema_gestion_archivos()
print(f"📁 Directorio actual: {gestion['info_sistema']['directorio_actual']}")
print(f"👤 Usuario: {gestion['info_sistema']['usuario']}")
print(f"🖥️ Sistema: {gestion['info_sistema']['sistema_operativo']}")
print(f"\n📂 Directorios creados: {len(gestion['directorios_creados'])}")
for directorio in gestion['directorios_creados']:
print(f" ✅ {directorio}")
print(f"\n📄 Archivos creados: {len(gestion['archivos_creados'])}")
for archivo in gestion['archivos_creados']:
print(f" ✅ {archivo}")
# Crear respaldo
print("\n💾 CREANDO RESPALDO:")
respaldo = crear_respaldo_configuracion()
if "error" not in respaldo:
print(f"✅ Respaldo creado en: {respaldo['directorio_backup']}")
print(f"📦 Archivos respaldados: {len(respaldo['archivos_respaldados'])}")
else:
print(f"❌ {respaldo['error']}")
🌐 Departamento de Internet (urllib)
Para conectar tu almacén con el mundo exterior:
from urllib.parse import urlparse, parse_qs
from urllib.request import urlopen
import json
def sistema_consulta_precios():
"""Sistema para consultar precios externos y APIs"""
# Simulación de URLs de APIs (en un caso real serían APIs reales)
urls_ejemplo = {
"api_precios": "https://api.ejemplo.com/precios?producto=laptop",
"api_inventario": "https://proveedor.com/api/stock?codigo=LAP001",
"api_cambio": "https://api.cambio.com/rates?from=USD&to=EUR"
}
# Análisis de URLs
analisis_urls = {}
for nombre, url in urls_ejemplo.items():
parsed = urlparse(url)
parametros = parse_qs(parsed.query)
analisis_urls[nombre] = {
"dominio": parsed.netloc,
"ruta": parsed.path,
"parametros": parametros,
"esquema": parsed.scheme,
"url_completa": url
}
return analisis_urls
# Ejemplo de construcción de URLs para APIs
def construir_url_api(base_url, endpoint, **parametros):
"""Construye URLs para APIs con parámetros"""
from urllib.parse import urlencode
url_completa = f"{base_url.rstrip('/')}/{endpoint.lstrip('/')}"
if parametros:
query_string = urlencode(parametros)
url_completa += f"?{query_string}"
return url_completa
# Ejemplos de uso
print("🌐 SISTEMA DE CONSULTA EXTERNA:")
analisis = sistema_consulta_precios()
for nombre, info in analisis.items():
print(f"\n📡 {nombre.upper()}:")
print(f" Dominio: {info['dominio']}")
print(f" Ruta: {info['ruta']}")
print(f" Parámetros: {info['parametros']}")
# Construcción de URLs
print("\n🔗 CONSTRUCCIÓN DE URLs:")
base_api = "https://api.almacen.com"
urls_construidas = [
construir_url_api(base_api, "productos", categoria="electronicos", limite=10),
construir_url_api(base_api, "ventas", desde="2024-01-01", hasta="2024-12-31"),
construir_url_api(base_api, "inventario", codigo="LAP001", incluir_stock=True)
]
for url in urls_construidas:
print(f" ✅ {url}")
🎯 Comprueba tu comprensión
Ejercicio 1: Calculadora de almacén
Usa el módulo math para crear una calculadora de espacios del almacén:
import math
def calcular_espacios_almacen(largo, ancho, alto, forma="rectangular"):
"""
Calcula diferentes métricas de espacio del almacén.
Args:
largo, ancho, alto: Dimensiones en metros
forma: "rectangular" o "circular"
Returns:
dict: Métricas calculadas
"""
# Tu código aquí
pass
# Prueba
metricas = calcular_espacios_almacen(50, 30, 8)
print(metricas)
Ejercicio 2: Sistema de fechas de vencimiento
Usa datetime para gestionar fechas de vencimiento:
import datetime as dt
def gestionar_vencimientos(productos):
"""
Analiza productos próximos a vencer.
Args:
productos: Lista de productos con fecha de vencimiento
Returns:
dict: Análisis de vencimientos
"""
# Tu código aquí
pass
# Prueba
productos_test = [
{"nombre": "Producto A", "vencimiento": "2024-12-31"},
{"nombre": "Producto B", "vencimiento": "2024-11-15"},
{"nombre": "Producto C", "vencimiento": "2025-06-01"}
]
analisis = gestionar_vencimientos(productos_test)
print(analisis)
Ejercicio 3: Generador de códigos aleatorios
Usa random para generar códigos únicos:
import random
import string
def generar_sistema_codigos(cantidad, tipo="producto"):
"""
Genera códigos únicos para productos, empleados, etc.
Args:
cantidad: Número de códigos a generar
tipo: "producto", "empleado", "factura"
Returns:
list: Lista de códigos únicos
"""
# Tu código aquí
pass
# Prueba
codigos_productos = generar_sistema_codigos(10, "producto")
print(codigos_productos)
💡 Mejores prácticas
- Importa solo lo que necesitas: No importes módulos completos si solo usas una función
- Usa alias descriptivos:
import datetime as dtes más claro queimport datetime as d - Documenta las dependencias: Siempre especifica qué módulos necesita tu código
- Maneja errores de importación: No todos los módulos están disponibles en todos los sistemas
- Explora la documentación: Cada módulo tiene muchas funciones útiles
🎉 ¡Felicitaciones!
Has aprendido a usar el almacén central de herramientas de Python. Ahora puedes:
- ✅ Importar y usar módulos estándar eficientemente
- ✅ Realizar cálculos matemáticos avanzados con
math - ✅ Gestionar fechas y tiempo con
datetime - ✅ Generar datos aleatorios con
random - ✅ Interactuar con el sistema operativo usando
os - ✅ Trabajar con URLs e internet usando
urllib
Estos módulos son la base para crear aplicaciones más potentes y profesionales. En la siguiente sección veremos diagramas que te ayudarán a visualizar cómo funcionan las funciones y módulos.
🧭 Navegación:
- Anterior: Módulos y la Biblioteca Estándar
- Siguiente: Mini Proyecto – Integrando Todo
Capítulo 12: Mini Proyecto Integrador
¡Llegó el momento más emocionante! Es hora de construir tu obra maestra de Python combinando todas las herramientas que has dominado. Imagina que eres el encargado de un almacén moderno donde cada concepto aprendido se convierte en una pieza fundamental de un sistema completo y funcional.
🏗️ El Proyecto: Sistema de Gestión de Almacén
Vamos a crear un Sistema de Gestión de Almacén que use TODOS los conceptos que has aprendido hasta ahora:
¿Qué hará nuestro sistema?
- Gestionar inventario con diccionarios y listas
- Procesar ventas con funciones y control de flujo
- Generar reportes guardándolos en archivos CSV
- Validar datos con manejo de errores
- Automatizar tareas como respaldos y alertas
🧰 Conceptos que integraremos
- Variables y tipos de datos → Información de productos
- Operadores → Cálculos de precios y totales
- Estructuras de control → Lógica de negocio
- Listas y diccionarios → Base de datos en memoria
- Funciones → Operaciones reutilizables
- Manejo de archivos → Persistencia de datos
- Manejo de errores → Sistema robusto
Desarrollo del Proyecto
Paso 1: Estructura de Datos del Almacén
Primero, definamos cómo representaremos nuestro almacén usando las estructuras de datos que conocemos:
# Base de datos del almacén (usando diccionarios y listas)
inventario = {
"PROD001": {
"nombre": "Laptop HP",
"precio": 15000.00,
"stock": 5,
"categoria": "Electrónicos",
"proveedor": "TechCorp"
},
"PROD002": {
"nombre": "Mouse Inalámbrico",
"precio": 350.00,
"stock": 20,
"categoria": "Accesorios",
"proveedor": "GadgetCo"
},
"PROD003": {
"nombre": "Monitor 24 pulgadas",
"precio": 4500.00,
"stock": 8,
"categoria": "Electrónicos",
"proveedor": "ScreenTech"
}
}
# Registro de ventas (lista de diccionarios)
ventas = []
# Configuración del sistema
configuracion = {
"iva": 0.16,
"descuento_mayoreo": 0.10,
"stock_minimo": 5,
"archivo_ventas": "ventas_almacen.csv",
"archivo_inventario": "inventario_respaldo.json"
}
Paso 2: Funciones de Operación
Creemos las funciones principales que harán funcionar nuestro almacén:
import json
import csv
from datetime import datetime
def mostrar_inventario():
"""Muestra todo el inventario actual del almacén"""
print("\n" + "="*50)
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#662113" d="M4 11v12.375c0 2.042 1.093 2.484 1.093 2.484l11.574 9.099C18.489 36.39 18 33.375 18 33.375V22L4 11z"/><path fill="#C1694F" d="M32 11v12.375c0 2.042-1.063 2.484-1.063 2.484s-9.767 7.667-11.588 9.099C17.526 36.39 18 33.375 18 33.375V22l14-11z"/><path fill="#D99E82" d="M19.289.5c-.753-.61-1.988-.61-2.742 0L4.565 10.029c-.754.61-.754 1.607 0 2.216l12.023 9.646c.754.609 1.989.609 2.743 0l12.104-9.73c.754-.609.754-1.606 0-2.216L19.289.5z"/><path fill="#D99E82" d="M18 35.75c-.552 0-1-.482-1-1.078V21.745c0-.596.448-1.078 1-1.078.553 0 1 .482 1 1.078v12.927c0 .596-.447 1.078-1 1.078z"/><path fill="#99AAB5" d="M28 18.836c0 1.104.104 1.646-1 2.442l-2.469 1.878c-1.104.797-1.531.113-1.531-.992v-2.961c0-.193-.026-.4-.278-.608C20.144 16.47 10.134 8.519 8.31 7.051l4.625-3.678c1.266.926 10.753 8.252 14.722 11.377.197.156.343.328.343.516v3.57z"/><path fill="#CCD6DD" d="M27.656 14.75C23.688 11.625 14.201 4.299 12.935 3.373l-1.721 1.368-2.904 2.31c1.825 1.468 11.834 9.419 14.412 11.544.151.125.217.25.248.371L27.903 15c-.06-.087-.146-.171-.247-.25z"/><path fill="#CCD6DD" d="M28 18.836v-3.57c0-.188-.146-.359-.344-.516-3.968-3.125-13.455-10.451-14.721-11.377l-2.073 1.649c3.393 2.669 12.481 9.681 14.86 11.573.256.204.278.415.278.608v4.836l1-.761c1.104-.797 1-1.338 1-2.442z"/><path fill="#E1E8ED" d="M27.656 14.75C23.688 11.625 14.201 4.299 12.935 3.373l-2.073 1.649c3.393 2.669 12.481 9.681 14.86 11.573.037.029.06.059.087.088L27.903 15c-.06-.087-.146-.171-.247-.25z"/></svg> INVENTARIO DEL ALMACÉN")
print("="*50)
for codigo, producto in inventario.items():
print(f"\nCódigo: {codigo}")
print(f" Nombre: {producto['nombre']}")
print(f" Precio: ${producto['precio']:,.2f}")
print(f" Stock: {producto['stock']} unidades")
print(f" Categoría: {producto['categoria']}")
# Alerta de stock bajo usando condicionales
if producto['stock'] <= configuracion['stock_minimo']:
print(f" <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M34.16 28.812L31.244 2.678C31.074 1.153 29.785 0 28.251 0H7.664C6.119 0 4.825 1.168 4.667 2.704l-2.67 26.108H34.16z"/><circle fill="#BE1931" cx="18.069" cy="14" r="9.366"/><path fill="#99AAB5" d="M35.521 29.18H.479L0 34c0 2 2 2 2 2h32s2 0 2-2l-.479-4.82z"/><path fill="#CCD6DD" d="M35.594 29.912l-.073-.732C35.38 28.442 34.751 28 34 28H2c-.751 0-1.38.442-1.521 1.18l-.073.732h35.188z"/><path fill="#EC9DAD" d="M29.647 13.63l-7.668-1.248 4.539-6.308c.107-.148.091-.354-.039-.484-.131-.129-.336-.146-.484-.039l-6.309 4.538-1.247-7.667c-.029-.181-.187-.314-.37-.314s-.341.133-.37.314l-1.248 7.667-6.308-4.538c-.149-.107-.353-.09-.484.039-.13.131-.146.335-.039.484l4.538 6.308L6.49 13.63c-.181.029-.314.186-.314.37s.133.341.314.37l7.668 1.248-4.538 6.308c-.107.149-.091.354.039.484.131.129.335.146.484.039l6.308-4.538 1.248 7.667c.029.182.187.314.37.314s.341-.134.37-.314l1.247-7.667 6.308 4.538c.148.106.354.09.484-.039.13-.131.146-.335.039-.484l-4.538-6.308 7.668-1.248c.182-.029.314-.187.314-.37s-.132-.341-.314-.37z"/></svg> ALERTA: Stock bajo!")
def buscar_producto(codigo):
"""Busca un producto por código"""
if codigo in inventario:
return inventario[codigo]
else:
return None
def calcular_precio_venta(codigo, cantidad):
"""Calcula el precio final de una venta con IVA y descuentos"""
producto = buscar_producto(codigo)
if not producto:
return None, "Producto no encontrado"
if cantidad > producto['stock']:
return None, f"Stock insuficiente. Disponible: {producto['stock']}"
# Cálculo del precio base
precio_base = producto['precio'] * cantidad
# Aplicar descuento por mayoreo (si compra 10 o más)
if cantidad >= 10:
descuento = precio_base * configuracion['descuento_mayoreo']
precio_con_descuento = precio_base - descuento
print(f"<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#FDD888" d="M31.898 23.938C31.3 17.32 28 14 28 14l-6-8h-8l-6 8s-1.419 1.433-2.567 4.275C3.444 18.935 2 20.789 2 23c0 1.448.625 2.742 1.609 3.655C3.233 27.357 3 28.147 3 29c0 1.958 1.136 3.636 2.775 4.456C7.058 35.378 8.772 36 10 36h16c1.379 0 3.373-.779 4.678-3.31C32.609 31.999 34 30.17 34 28c0-1.678-.834-3.154-2.102-4.062zM18 6c.55 0 1.058-.158 1.5-.416.443.258.951.416 1.5.416 1.657 0 4-2.344 4-4 0 0 0-2-2-2-.788 0-1 1-2 1s-1-1-3-1-2 1-3 1-1.211-1-2-1c-2 0-2 2-2 2 0 1.656 2.344 4 4 4 .549 0 1.057-.158 1.5-.416.443.258.951.416 1.5.416z"/><path fill="#BF6952" d="M24 6c0 .552-.447 1-1 1H13c-.552 0-1-.448-1-1s.448-1 1-1h10c.553 0 1 .448 1 1z"/><path fill="#67757F" d="M23.901 24.542c0-4.477-8.581-4.185-8.581-6.886 0-1.308 1.301-1.947 2.811-1.947 2.538 0 2.99 1.569 4.139 1.569.813 0 1.205-.493 1.205-1.046 0-1.284-2.024-2.256-3.965-2.592V12.4c0-.773-.65-1.4-1.454-1.4-.805 0-1.456.627-1.456 1.4v1.283c-2.116.463-3.937 1.875-3.937 4.176 0 4.299 8.579 4.125 8.579 7.145 0 1.047-1.178 2.093-3.111 2.093-2.901 0-3.867-1.889-5.045-1.889-.574 0-1.087.464-1.087 1.164 0 1.113 1.938 2.451 4.603 2.824l-.001.01v1.398c0 .772.652 1.4 1.456 1.4.804 0 1.455-.628 1.455-1.4v-1.398c0-.017-.008-.03-.009-.045 2.398-.43 4.398-1.932 4.398-4.619z"/></svg> Descuento por mayoreo aplicado: ${descuento:,.2f}")
else:
precio_con_descuento = precio_base
descuento = 0
# Calcular IVA
iva = precio_con_descuento * configuracion['iva']
precio_final = precio_con_descuento + iva
return {
'precio_base': precio_base,
'descuento': descuento,
'iva': iva,
'precio_final': precio_final
}, "OK"
def registrar_venta(codigo, cantidad, cliente="Cliente general"):
"""Registra una venta en el sistema"""
try:
# Calcular precios
calculo, mensaje = calcular_precio_venta(codigo, cantidad)
if calculo is None:
print(f"<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> Error: {mensaje}")
return False
# Crear registro de venta
venta = {
'fecha': datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
'codigo_producto': codigo,
'nombre_producto': inventario[codigo]['nombre'],
'cantidad': cantidad,
'precio_unitario': inventario[codigo]['precio'],
'precio_base': calculo['precio_base'],
'descuento': calculo['descuento'],
'iva': calculo['iva'],
'precio_final': calculo['precio_final'],
'cliente': cliente
}
# Agregar a lista de ventas
ventas.append(venta)
# Actualizar stock
inventario[codigo]['stock'] -= cantidad
print(f"\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#77B255" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V4c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v28z"/><path fill="#FFF" d="M29.28 6.362c-1.156-.751-2.704-.422-3.458.736L14.936 23.877l-5.029-4.65c-1.014-.938-2.596-.875-3.533.138-.937 1.014-.875 2.596.139 3.533l7.209 6.666c.48.445 1.09.665 1.696.665.673 0 1.534-.282 2.099-1.139.332-.506 12.5-19.27 12.5-19.27.751-1.159.421-2.707-.737-3.458z"/></svg> Venta registrada exitosamente")
print(f"Cliente: {cliente}")
print(f"Producto: {venta['nombre_producto']}")
print(f"Cantidad: {cantidad}")
print(f"Total: ${calculo['precio_final']:,.2f}")
return True
except Exception as e:
print(f"<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> Error al registrar venta: {e}")
return False
def generar_reporte_ventas():
"""Genera un reporte completo de ventas"""
if not ventas:
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#CCD6DD" d="M31 2H5C3.343 2 2 3.343 2 5v26c0 1.657 1.343 3 3 3h26c1.657 0 3-1.343 3-3V5c0-1.657-1.343-3-3-3z"/><path fill="#E1E8ED" d="M31 1H5C2.791 1 1 2.791 1 5v26c0 2.209 1.791 4 4 4h26c2.209 0 4-1.791 4-4V5c0-2.209-1.791-4-4-4zm0 2c1.103 0 2 .897 2 2v4h-6V3h4zm-4 16h6v6h-6v-6zm0-2v-6h6v6h-6zM25 3v6h-6V3h6zm-6 8h6v6h-6v-6zm0 8h6v6h-6v-6zM17 3v6h-6V3h6zm-6 8h6v6h-6v-6zm0 8h6v6h-6v-6zM3 5c0-1.103.897-2 2-2h4v6H3V5zm0 6h6v6H3v-6zm0 8h6v6H3v-6zm2 14c-1.103 0-2-.897-2-2v-4h6v6H5zm6 0v-6h6v6h-6zm8 0v-6h6v6h-6zm12 0h-4v-6h6v4c0 1.103-.897 2-2 2z"/><path fill="#5C913B" d="M13 33H7V16c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v17z"/><path fill="#3B94D9" d="M29 33h-6V9c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v24z"/><path fill="#DD2E44" d="M21 33h-6V23c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v10z"/></svg> No hay ventas registradas")
return
print("\n" + "="*60)
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#CCD6DD" d="M31 2H5C3.343 2 2 3.343 2 5v26c0 1.657 1.343 3 3 3h26c1.657 0 3-1.343 3-3V5c0-1.657-1.343-3-3-3z"/><path fill="#E1E8ED" d="M31 1H5C2.791 1 1 2.791 1 5v26c0 2.209 1.791 4 4 4h26c2.209 0 4-1.791 4-4V5c0-2.209-1.791-4-4-4zm0 2c1.103 0 2 .897 2 2v4h-6V3h4zm-4 16h6v6h-6v-6zm0-2v-6h6v6h-6zM25 3v6h-6V3h6zm-6 8h6v6h-6v-6zm0 8h6v6h-6v-6zM17 3v6h-6V3h6zm-6 8h6v6h-6v-6zm0 8h6v6h-6v-6zM3 5c0-1.103.897-2 2-2h4v6H3V5zm0 6h6v6H3v-6zm0 8h6v6H3v-6zm2 14c-1.103 0-2-.897-2-2v-4h6v6H5zm6 0v-6h6v6h-6zm8 0v-6h6v6h-6zm12 0h-4v-6h6v4c0 1.103-.897 2-2 2z"/><path fill="#5C913B" d="M13 33H7V16c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v17z"/><path fill="#3B94D9" d="M29 33h-6V9c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v24z"/><path fill="#DD2E44" d="M21 33h-6V23c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v10z"/></svg> REPORTE DE VENTAS")
print("="*60)
total_ventas = 0
total_iva = 0
productos_vendidos = {}
# Procesar cada venta usando bucles
for venta in ventas:
total_ventas += venta['precio_final']
total_iva += venta['iva']
# Contabilizar productos vendidos
codigo = venta['codigo_producto']
if codigo in productos_vendidos:
productos_vendidos[codigo] += venta['cantidad']
else:
productos_vendidos[codigo] = venta['cantidad']
print(f"Total de ventas: {len(ventas)}")
print(f"Ingresos totales: ${total_ventas:,.2f}")
print(f"IVA recaudado: ${total_iva:,.2f}")
print("\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#CCD6DD" d="M31 2H5C3.343 2 2 3.343 2 5v26c0 1.657 1.343 3 3 3h26c1.657 0 3-1.343 3-3V5c0-1.657-1.343-3-3-3z"/><path fill="#E1E8ED" d="M31 1H5C2.791 1 1 2.791 1 5v26c0 2.209 1.791 4 4 4h26c2.209 0 4-1.791 4-4V5c0-2.209-1.791-4-4-4zm0 2c1.103 0 2 .897 2 2v4h-6V3h4zm-4 16h6v6h-6v-6zm0-2v-6h6v6h-6zM25 3v6h-6V3h6zm-6 8h6v6h-6v-6zm0 8h6v6h-6v-6zM17 3v6h-6V3h6zm-6 8h6v6h-6v-6zm0 8h6v6h-6v-6zM3 5c0-1.103.897-2 2-2h4v6H3V5zm0 6h6v6H3v-6zm0 8h6v6H3v-6zm2 14c-1.103 0-2-.897-2-2v-4h6v6H5zm6 0v-6h6v6h-6zm8 0v-6h6v6h-6zm12 0h-4v-6h6v4c0 1.103-.897 2-2 2z"/><path fill="#DD2E44" d="M4.998 33c-.32 0-.645-.076-.946-.239-.973-.523-1.336-1.736-.813-2.709l7-13c.299-.557.845-.939 1.47-1.031.626-.092 1.258.118 1.705.565l6.076 6.076 9.738-18.59c.512-.978 1.721-1.357 2.699-.843.979.512 1.356 1.721.844 2.7l-11 21c-.295.564-.841.953-1.47 1.05-.627.091-1.266-.113-1.716-.563l-6.1-6.099-5.724 10.631C6.4 32.619 5.71 33 4.998 33z"/></svg> Productos más vendidos:")
# Ordenar productos por cantidad vendida
productos_ordenados = sorted(productos_vendidos.items(),
key=lambda x: x[1], reverse=True)
for codigo, cantidad in productos_ordenados:
nombre = inventario[codigo]['nombre']
print(f" • {nombre}: {cantidad} unidades")
def exportar_ventas_csv():
"""Exporta las ventas a un archivo CSV"""
try:
with open(configuracion['archivo_ventas'], 'w', newline='', encoding='utf-8') as archivo:
campos = ['fecha', 'codigo_producto', 'nombre_producto', 'cantidad',
'precio_unitario', 'precio_base', 'descuento', 'iva',
'precio_final', 'cliente']
escritor = csv.DictWriter(archivo, fieldnames=campos)
escritor.writeheader()
for venta in ventas:
escritor.writerow(venta)
print(f"<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#77B255" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V4c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v28z"/><path fill="#FFF" d="M29.28 6.362c-1.156-.751-2.704-.422-3.458.736L14.936 23.877l-5.029-4.65c-1.014-.938-2.596-.875-3.533.138-.937 1.014-.875 2.596.139 3.533l7.209 6.666c.48.445 1.09.665 1.696.665.673 0 1.534-.282 2.099-1.139.332-.506 12.5-19.27 12.5-19.27.751-1.159.421-2.707-.737-3.458z"/></svg> Ventas exportadas a {configuracion['archivo_ventas']}")
except Exception as e:
print(f"<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> Error al exportar ventas: {e}")
def respaldar_inventario():
"""Crea un respaldo del inventario en JSON"""
try:
respaldo = {
'fecha_respaldo': datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
'inventario': inventario,
'configuracion': configuracion
}
with open(configuracion['archivo_inventario'], 'w', encoding='utf-8') as archivo:
json.dump(respaldo, archivo, indent=2, ensure_ascii=False)
print(f"<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#77B255" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V4c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v28z"/><path fill="#FFF" d="M29.28 6.362c-1.156-.751-2.704-.422-3.458.736L14.936 23.877l-5.029-4.65c-1.014-.938-2.596-.875-3.533.138-.937 1.014-.875 2.596.139 3.533l7.209 6.666c.48.445 1.09.665 1.696.665.673 0 1.534-.282 2.099-1.139.332-.506 12.5-19.27 12.5-19.27.751-1.159.421-2.707-.737-3.458z"/></svg> Inventario respaldado en {configuracion['archivo_inventario']}")
except Exception as e:
print(f"<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> Error al respaldar inventario: {e}")
def cargar_respaldo():
"""Carga un respaldo del inventario"""
try:
with open(configuracion['archivo_inventario'], 'r', encoding='utf-8') as archivo:
respaldo = json.load(archivo)
global inventario
inventario = respaldo['inventario']
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#77B255" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V4c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v28z"/><path fill="#FFF" d="M29.28 6.362c-1.156-.751-2.704-.422-3.458.736L14.936 23.877l-5.029-4.65c-1.014-.938-2.596-.875-3.533.138-.937 1.014-.875 2.596.139 3.533l7.209 6.666c.48.445 1.09.665 1.696.665.673 0 1.534-.282 2.099-1.139.332-.506 12.5-19.27 12.5-19.27.751-1.159.421-2.707-.737-3.458z"/></svg> Respaldo cargado exitosamente")
print(f"Fecha del respaldo: {respaldo['fecha_respaldo']}")
except FileNotFoundError:
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> No se encontró archivo de respaldo")
except Exception as e:
print(f"<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> Error al cargar respaldo: {e}")
Paso 3: Sistema de Menús Interactivo
Ahora creemos la interfaz principal que permite al usuario interactuar con todas las funciones:
def mostrar_menu():
"""Muestra el menú principal del sistema"""
print("\n" + "="*50)
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#AAB8C2" d="M17 34c0 1.104.896 2 2 2h14c1.104 0 2-.896 2-2V18c0-1.104-.896-2-2-2H19c-1.104 0-2 .896-2 2v16z"/><path fill="#292F33" d="M33 16H23v2h12c0-1.104-.896-2-2-2z"/><path fill="#3B88C3" d="M3 30h30v4H3z"/><path fill="#CCD6DD" d="M3 16c-1.104 0-2 .896-2 2v16c0 1.104.896 2 2 2h20V16H3z"/><path fill="#66757F" d="M3 16c-1.104 0-2 .896-2 2h22v-2H3z"/><path fill="#55ACEE" d="M3 20h4v4H3zm14 0h4v4h-4zm-7 0h4v4h-4z"/><path fill="#3B88C3" d="M29 20h4v4h-4zm-6 0h4v4h-4z"/><path fill="#55ACEE" d="M3 30h18v6H3z"/><path fill="#3B88C3" d="M7 30h10v6H7z"/><path fill="#DD2E44" d="M1 26h22v4H1z"/><path fill="#F4ABBA" d="M7 27h10v2H7z"/><path fill="#FFF" d="M9 27h6v2H9z"/><path fill="#A0041E" d="M23 26h12v4H23z"/><path fill="#292F33" d="M5 14h2v2H5zm12 0h2v2h-2z"/><path fill="#DD2E44" d="M21 12c0 1.104-.896 2-2 2H5c-1.104 0-2-.896-2-2V2c0-1.104.896-2 2-2h14c1.104 0 2 .896 2 2v10z"/><path d="M10.561 10.151c.616 0 1.093.28 1.093.925 0 .644-.477.924-1.009.924H5.967c-.617 0-1.093-.28-1.093-.924 0-.294.182-.546.322-.714C6.359 8.975 7.62 7.714 8.685 6.173c.252-.364.49-.798.49-1.303 0-.574-.434-1.079-1.009-1.079-1.611 0-.84 2.269-2.185 2.269-.672 0-1.022-.476-1.022-1.022 0-1.765 1.569-3.18 3.292-3.18 1.723 0 3.109 1.135 3.109 2.914 0 1.947-2.171 3.88-3.362 5.379h2.563zm2.363-.35c-.687 0-.981-.462-.981-.826 0-.309.112-.477.196-.617l3.138-5.687c.308-.56.7-.813 1.429-.813.812 0 1.611.519 1.611 1.793v4.3h.238c.546 0 .98.364.98.925 0 .56-.434.924-.98.924h-.238v1.19c0 .743-.295 1.093-1.009 1.093s-1.008-.35-1.008-1.093V9.8h-3.376zM16.3 4.044h-.028l-1.891 3.908H16.3V4.044z" fill="#FFF"/></svg> SISTEMA DE GESTIÓN DE ALMACÉN")
print("="*50)
print("1. <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#662113" d="M4 11v12.375c0 2.042 1.093 2.484 1.093 2.484l11.574 9.099C18.489 36.39 18 33.375 18 33.375V22L4 11z"/><path fill="#C1694F" d="M32 11v12.375c0 2.042-1.063 2.484-1.063 2.484s-9.767 7.667-11.588 9.099C17.526 36.39 18 33.375 18 33.375V22l14-11z"/><path fill="#D99E82" d="M19.289.5c-.753-.61-1.988-.61-2.742 0L4.565 10.029c-.754.61-.754 1.607 0 2.216l12.023 9.646c.754.609 1.989.609 2.743 0l12.104-9.73c.754-.609.754-1.606 0-2.216L19.289.5z"/><path fill="#D99E82" d="M18 35.75c-.552 0-1-.482-1-1.078V21.745c0-.596.448-1.078 1-1.078.553 0 1 .482 1 1.078v12.927c0 .596-.447 1.078-1 1.078z"/><path fill="#99AAB5" d="M28 18.836c0 1.104.104 1.646-1 2.442l-2.469 1.878c-1.104.797-1.531.113-1.531-.992v-2.961c0-.193-.026-.4-.278-.608C20.144 16.47 10.134 8.519 8.31 7.051l4.625-3.678c1.266.926 10.753 8.252 14.722 11.377.197.156.343.328.343.516v3.57z"/><path fill="#CCD6DD" d="M27.656 14.75C23.688 11.625 14.201 4.299 12.935 3.373l-1.721 1.368-2.904 2.31c1.825 1.468 11.834 9.419 14.412 11.544.151.125.217.25.248.371L27.903 15c-.06-.087-.146-.171-.247-.25z"/><path fill="#CCD6DD" d="M28 18.836v-3.57c0-.188-.146-.359-.344-.516-3.968-3.125-13.455-10.451-14.721-11.377l-2.073 1.649c3.393 2.669 12.481 9.681 14.86 11.573.256.204.278.415.278.608v4.836l1-.761c1.104-.797 1-1.338 1-2.442z"/><path fill="#E1E8ED" d="M27.656 14.75C23.688 11.625 14.201 4.299 12.935 3.373l-2.073 1.649c3.393 2.669 12.481 9.681 14.86 11.573.037.029.06.059.087.088L27.903 15c-.06-.087-.146-.171-.247-.25z"/></svg> Ver inventario")
print("2. <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#9AAAB4" d="M27.388 24.642L24.56 27.47l-4.95-4.95 2.828-2.828z"/><path fill="#66757F" d="M34.683 29.11l-5.879-5.879c-.781-.781-2.047-.781-2.828 0l-2.828 2.828c-.781.781-.781 2.047 0 2.828l5.879 5.879c1.562 1.563 4.096 1.563 5.658 0 1.56-1.561 1.559-4.094-.002-5.656z"/><circle fill="#8899A6" cx="13.586" cy="13.669" r="13.5"/><circle fill="#BBDDF5" cx="13.586" cy="13.669" r="9.5"/></svg> Buscar producto")
print("3. <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#FDD888" d="M31.898 23.938C31.3 17.32 28 14 28 14l-6-8h-8l-6 8s-1.419 1.433-2.567 4.275C3.444 18.935 2 20.789 2 23c0 1.448.625 2.742 1.609 3.655C3.233 27.357 3 28.147 3 29c0 1.958 1.136 3.636 2.775 4.456C7.058 35.378 8.772 36 10 36h16c1.379 0 3.373-.779 4.678-3.31C32.609 31.999 34 30.17 34 28c0-1.678-.834-3.154-2.102-4.062zM18 6c.55 0 1.058-.158 1.5-.416.443.258.951.416 1.5.416 1.657 0 4-2.344 4-4 0 0 0-2-2-2-.788 0-1 1-2 1s-1-1-3-1-2 1-3 1-1.211-1-2-1c-2 0-2 2-2 2 0 1.656 2.344 4 4 4 .549 0 1.057-.158 1.5-.416.443.258.951.416 1.5.416z"/><path fill="#BF6952" d="M24 6c0 .552-.447 1-1 1H13c-.552 0-1-.448-1-1s.448-1 1-1h10c.553 0 1 .448 1 1z"/><path fill="#67757F" d="M23.901 24.542c0-4.477-8.581-4.185-8.581-6.886 0-1.308 1.301-1.947 2.811-1.947 2.538 0 2.99 1.569 4.139 1.569.813 0 1.205-.493 1.205-1.046 0-1.284-2.024-2.256-3.965-2.592V12.4c0-.773-.65-1.4-1.454-1.4-.805 0-1.456.627-1.456 1.4v1.283c-2.116.463-3.937 1.875-3.937 4.176 0 4.299 8.579 4.125 8.579 7.145 0 1.047-1.178 2.093-3.111 2.093-2.901 0-3.867-1.889-5.045-1.889-.574 0-1.087.464-1.087 1.164 0 1.113 1.938 2.451 4.603 2.824l-.001.01v1.398c0 .772.652 1.4 1.456 1.4.804 0 1.455-.628 1.455-1.4v-1.398c0-.017-.008-.03-.009-.045 2.398-.43 4.398-1.932 4.398-4.619z"/></svg> Registrar venta")
print("4. <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#CCD6DD" d="M31 2H5C3.343 2 2 3.343 2 5v26c0 1.657 1.343 3 3 3h26c1.657 0 3-1.343 3-3V5c0-1.657-1.343-3-3-3z"/><path fill="#E1E8ED" d="M31 1H5C2.791 1 1 2.791 1 5v26c0 2.209 1.791 4 4 4h26c2.209 0 4-1.791 4-4V5c0-2.209-1.791-4-4-4zm0 2c1.103 0 2 .897 2 2v4h-6V3h4zm-4 16h6v6h-6v-6zm0-2v-6h6v6h-6zM25 3v6h-6V3h6zm-6 8h6v6h-6v-6zm0 8h6v6h-6v-6zM17 3v6h-6V3h6zm-6 8h6v6h-6v-6zm0 8h6v6h-6v-6zM3 5c0-1.103.897-2 2-2h4v6H3V5zm0 6h6v6H3v-6zm0 8h6v6H3v-6zm2 14c-1.103 0-2-.897-2-2v-4h6v6H5zm6 0v-6h6v6h-6zm8 0v-6h6v6h-6zm12 0h-4v-6h6v4c0 1.103-.897 2-2 2z"/><path fill="#5C913B" d="M13 33H7V16c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v17z"/><path fill="#3B94D9" d="M29 33h-6V9c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v24z"/><path fill="#DD2E44" d="M21 33h-6V23c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v10z"/></svg> Reporte de ventas")
print("5. <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#269" d="M0 29c0 2.209 1.791 4 4 4h24c2.209 0 4-1.791 4-4V12c0-2.209-1.791-4-4-4h-9c-3.562 0-3-5-8.438-5H4C1.791 3 0 4.791 0 7v22z"/><path fill="#55ACEE" d="M30 10h-6.562C18 10 18.562 15 15 15H6c-2.209 0-4 1.791-4 4v10c0 .553-.448 1-1 1s-1-.447-1-1c0 2.209 1.791 4 4 4h26c2.209 0 4-1.791 4-4V14c0-2.209-1.791-4-4-4z"/></svg> Exportar ventas a CSV")
print("6. <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#31373D" d="M4 36s-4 0-4-4V4s0-4 4-4h26c1 0 2 1 2 1l3 3s1 1 1 2v26s0 4-4 4H4z"/><path fill="#55ACEE" d="M5 19v-1s0-2 2-2h21c2 0 2 2 2 2v1H5z"/><path fill="#E1E8ED" d="M5 32.021V19h25v13s0 2-2 2H7c-2 0-2-1.979-2-1.979zM10 3s0-1 1-1h18c1.048 0 1 1 1 1v10s0 1-1 1H11s-1 0-1-1V3zm12 10h5V3h-5v10z"/></svg> Respaldar inventario")
print("7. <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#269" d="M0 29c0 2.209 1.791 4 4 4h24c2.209 0 4-1.791 4-4V12c0-2.209-1.791-4-4-4h-9c-3.562 0-3-5-8.438-5H4C1.791 3 0 4.791 0 7v22z"/><path fill="#55ACEE" d="M32.336 12h-6.562c-5.438 0-5.383 5-8.945 5h-9c-2.209 0-4.182 1.791-4.406 4l-.493 3.874L2.406 29l-.02-.002c-.116.607-.672.999-1.3.999-.643 0-1.106-.507-1.074-1.144C.01 28.903 0 28.95 0 29c0 2.004 1.478 3.648 3.4 3.939.177.038.371.061.6.061h26c2.209 0 4.182-1.791 4.406-4l1.523-13c.225-2.209-1.384-4-3.593-4z"/></svg> Cargar respaldo")
print("8. <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#31373D" d="M31 15H21V5c0-1.657-1.343-3-3-3s-3 1.343-3 3v10H5c-1.657 0-3 1.343-3 3s1.343 3 3 3h10v10c0 1.657 1.343 3 3 3s3-1.343 3-3V21h10c1.657 0 3-1.343 3-3s-1.343-3-3-3z"/></svg> Agregar producto")
print("9. <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#BF6952" d="M29 34c0 1.105-.895 2-2 2H9c-1.105 0-2-.895-2-2V2c0-1.105.895-2 2-2h18c1.105 0 2 .895 2 2v32z"/><circle fill="#FFAC33" cx="11" cy="18" r="1.5"/><path fill="#AC5640" d="M25 3c-.552 0-1 .448-1 1v9H11c-.552 0-1 .448-1 1s.448 1 1 1h14c.552 0 1-.448 1-1V4c0-.552-.448-1-1-1zm0 25c.552 0 1 .448 1 1v3c0 .552-.448 1-1 1H11c-.552 0-1-.448-1-1s.448-1 1-1h13v-2c0-.552.448-1 1-1z"/><path fill="#854836" d="M11 33c-.552 0-1-.448-1-1v-3c0-.552.448-1 1-1h14c.552 0 1 .448 1 1s-.448 1-1 1H12v2c0 .552-.448 1-1 1z"/><path fill="#AC5640" d="M25 21c.552 0 1 .448 1 1v3c0 .552-.448 1-1 1H11c-.552 0-1-.448-1-1s.448-1 1-1h13v-2c0-.552.448-1 1-1z"/><path fill="#854836" d="M11 26c-.552 0-1-.448-1-1v-3c0-.552.448-1 1-1h14c.552 0 1 .448 1 1s-.448 1-1 1H12v2c0 .552-.448 1-1 1zm0-11c-.552 0-1-.448-1-1V4c0-.552.448-1 1-1h14c.552 0 1 .448 1 1s-.448 1-1 1H12v9c0 .552-.448 1-1 1z"/></svg> Salir")
print("-" * 50)
def agregar_producto():
"""Permite agregar un nuevo producto al inventario"""
try:
print("\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#31373D" d="M31 15H21V5c0-1.657-1.343-3-3-3s-3 1.343-3 3v10H5c-1.657 0-3 1.343-3 3s1.343 3 3 3h10v10c0 1.657 1.343 3 3 3s3-1.343 3-3V21h10c1.657 0 3-1.343 3-3s-1.343-3-3-3z"/></svg> AGREGAR NUEVO PRODUCTO")
print("-" * 30)
codigo = input("Código del producto: ").upper()
# Validar que el código no exista
if codigo in inventario:
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> Error: El código ya existe")
return
nombre = input("Nombre del producto: ")
precio = float(input("Precio: $"))
stock = int(input("Stock inicial: "))
categoria = input("Categoría: ")
proveedor = input("Proveedor: ")
# Validaciones básicas
if precio <= 0:
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> Error: El precio debe ser mayor a 0")
return
if stock < 0:
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> Error: El stock no puede ser negativo")
return
# Agregar al inventario
inventario[codigo] = {
"nombre": nombre,
"precio": precio,
"stock": stock,
"categoria": categoria,
"proveedor": proveedor
}
print(f"<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#77B255" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V4c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v28z"/><path fill="#FFF" d="M29.28 6.362c-1.156-.751-2.704-.422-3.458.736L14.936 23.877l-5.029-4.65c-1.014-.938-2.596-.875-3.533.138-.937 1.014-.875 2.596.139 3.533l7.209 6.666c.48.445 1.09.665 1.696.665.673 0 1.534-.282 2.099-1.139.332-.506 12.5-19.27 12.5-19.27.751-1.159.421-2.707-.737-3.458z"/></svg> Producto {nombre} agregado exitosamente")
except ValueError:
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> Error: Ingresa valores numéricos válidos")
except Exception as e:
print(f"<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> Error inesperado: {e}")
def ejecutar_sistema():
"""Función principal que ejecuta el sistema completo"""
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M11.626 7.488c-.112.112-.197.247-.268.395l-.008-.008L.134 33.141l.011.011c-.208.403.14 1.223.853 1.937.713.713 1.533 1.061 1.936.853l.01.01L28.21 24.735l-.008-.009c.147-.07.282-.155.395-.269 1.562-1.562-.971-6.627-5.656-11.313-4.687-4.686-9.752-7.218-11.315-5.656z"/><path fill="#EA596E" d="M13 12L.416 32.506l-.282.635.011.011c-.208.403.14 1.223.853 1.937.232.232.473.408.709.557L17 17l-4-5z"/><path fill="#A0041E" d="M23.012 13.066c4.67 4.672 7.263 9.652 5.789 11.124-1.473 1.474-6.453-1.118-11.126-5.788-4.671-4.672-7.263-9.654-5.79-11.127 1.474-1.473 6.454 1.119 11.127 5.791z"/><path fill="#AA8DD8" d="M18.59 13.609c-.199.161-.459.245-.734.215-.868-.094-1.598-.396-2.109-.873-.541-.505-.808-1.183-.735-1.862.128-1.192 1.324-2.286 3.363-2.066.793.085 1.147-.17 1.159-.292.014-.121-.277-.446-1.07-.532-.868-.094-1.598-.396-2.11-.873-.541-.505-.809-1.183-.735-1.862.13-1.192 1.325-2.286 3.362-2.065.578.062.883-.057 1.012-.134.103-.063.144-.123.148-.158.012-.121-.275-.446-1.07-.532-.549-.06-.947-.552-.886-1.102.059-.549.55-.946 1.101-.886 2.037.219 2.973 1.542 2.844 2.735-.13 1.194-1.325 2.286-3.364 2.067-.578-.063-.88.057-1.01.134-.103.062-.145.123-.149.157-.013.122.276.446 1.071.532 2.037.22 2.973 1.542 2.844 2.735-.129 1.192-1.324 2.286-3.362 2.065-.578-.062-.882.058-1.012.134-.104.064-.144.124-.148.158-.013.121.276.446 1.07.532.548.06.947.553.886 1.102-.028.274-.167.511-.366.671z"/><path fill="#77B255" d="M30.661 22.857c1.973-.557 3.334.323 3.658 1.478.324 1.154-.378 2.615-2.35 3.17-.77.216-1.001.584-.97.701.034.118.425.312 1.193.095 1.972-.555 3.333.325 3.657 1.479.326 1.155-.378 2.614-2.351 3.17-.769.216-1.001.585-.967.702.033.117.423.311 1.192.095.53-.149 1.084.16 1.233.691.148.532-.161 1.084-.693 1.234-1.971.555-3.333-.323-3.659-1.479-.324-1.154.379-2.613 2.353-3.169.77-.217 1.001-.584.967-.702-.032-.117-.422-.312-1.19-.096-1.974.556-3.334-.322-3.659-1.479-.325-1.154.378-2.613 2.351-3.17.768-.215.999-.585.967-.701-.034-.118-.423-.312-1.192-.096-.532.15-1.083-.16-1.233-.691-.149-.53.161-1.082.693-1.232z"/><path fill="#AA8DD8" d="M23.001 20.16c-.294 0-.584-.129-.782-.375-.345-.432-.274-1.061.156-1.406.218-.175 5.418-4.259 12.767-3.208.547.078.927.584.849 1.131-.078.546-.58.93-1.132.848-6.493-.922-11.187 2.754-11.233 2.791-.186.148-.406.219-.625.219z"/><path fill="#77B255" d="M5.754 16c-.095 0-.192-.014-.288-.042-.529-.159-.829-.716-.67-1.245 1.133-3.773 2.16-9.794.898-11.364-.141-.178-.354-.353-.842-.316-.938.072-.849 2.051-.848 2.071.042.551-.372 1.031-.922 1.072-.559.034-1.031-.372-1.072-.923-.103-1.379.326-4.035 2.692-4.214 1.056-.08 1.933.287 2.552 1.057 2.371 2.951-.036 11.506-.542 13.192-.13.433-.528.712-.958.712z"/><circle fill="#5C913B" cx="25.5" cy="9.5" r="1.5"/><circle fill="#9266CC" cx="2" cy="18" r="2"/><circle fill="#5C913B" cx="32.5" cy="19.5" r="1.5"/><circle fill="#5C913B" cx="23.5" cy="31.5" r="1.5"/><circle fill="#FFCC4D" cx="28" cy="4" r="2"/><circle fill="#FFCC4D" cx="32.5" cy="8.5" r="1.5"/><circle fill="#FFCC4D" cx="29.5" cy="12.5" r="1.5"/><circle fill="#FFCC4D" cx="7.5" cy="23.5" r="1.5"/></svg> ¡Bienvenido al Sistema de Gestión de Almacén!")
print("Este sistema integra todos los conceptos de Python que has aprendido.")
while True:
mostrar_menu()
try:
opcion = input("\nSelecciona una opción (1-9): ")
if opcion == "1":
mostrar_inventario()
elif opcion == "2":
codigo = input("Ingresa el código del producto: ").upper()
producto = buscar_producto(codigo)
if producto:
print(f"\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><circle fill="#DD2E44" cx="18" cy="18" r="18"/><circle fill="#FFF" cx="18" cy="18" r="13.5"/><circle fill="#DD2E44" cx="18" cy="18" r="10"/><circle fill="#FFF" cx="18" cy="18" r="6"/><circle fill="#DD2E44" cx="18" cy="18" r="3"/><path opacity=".2" d="M18.24 18.282l13.144 11.754s-2.647 3.376-7.89 5.109L17.579 18.42l.661-.138z"/><path fill="#FFAC33" d="M18.294 19c-.255 0-.509-.097-.704-.292-.389-.389-.389-1.018 0-1.407l.563-.563c.389-.389 1.018-.389 1.408 0 .388.389.388 1.018 0 1.407l-.564.563c-.194.195-.448.292-.703.292z"/><path fill="#55ACEE" d="M24.016 6.981c-.403 2.079 0 4.691 0 4.691l7.054-7.388c.291-1.454-.528-3.932-1.718-4.238-1.19-.306-4.079.803-5.336 6.935zm5.003 5.003c-2.079.403-4.691 0-4.691 0l7.388-7.054c1.454-.291 3.932.528 4.238 1.718.306 1.19-.803 4.079-6.935 5.336z"/><path fill="#3A87C2" d="M32.798 4.485L21.176 17.587c-.362.362-1.673.882-2.51.046-.836-.836-.419-2.08-.057-2.443L31.815 3.501s.676-.635 1.159-.152-.176 1.136-.176 1.136z"/></svg> Producto encontrado:")
print(f"Nombre: {producto['nombre']}")
print(f"Precio: ${producto['precio']:,.2f}")
print(f"Stock: {producto['stock']}")
print(f"Categoría: {producto['categoria']}")
else:
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> Producto no encontrado")
elif opcion == "3":
codigo = input("Código del producto: ").upper()
cantidad = int(input("Cantidad: "))
cliente = input("Nombre del cliente (opcional): ") or "Cliente general"
registrar_venta(codigo, cantidad, cliente)
elif opcion == "4":
generar_reporte_ventas()
elif opcion == "5":
exportar_ventas_csv()
elif opcion == "6":
respaldar_inventario()
elif opcion == "7":
cargar_respaldo()
elif opcion == "8":
agregar_producto()
elif opcion == "9":
print("\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#EF9645" d="M4.861 9.147c.94-.657 2.357-.531 3.201.166l-.968-1.407c-.779-1.111-.5-2.313.612-3.093 1.112-.777 4.263 1.312 4.263 1.312-.786-1.122-.639-2.544.483-3.331 1.122-.784 2.67-.513 3.456.611l10.42 14.72L25 31l-11.083-4.042L4.25 12.625c-.793-1.129-.519-2.686.611-3.478z"/><path fill="#FFDC5D" d="M2.695 17.336s-1.132-1.65.519-2.781c1.649-1.131 2.78.518 2.78.518l5.251 7.658c.181-.302.379-.6.6-.894L4.557 11.21s-1.131-1.649.519-2.78c1.649-1.131 2.78.518 2.78.518l6.855 9.997c.255-.208.516-.417.785-.622L7.549 6.732s-1.131-1.649.519-2.78c1.649-1.131 2.78.518 2.78.518l7.947 11.589c.292-.179.581-.334.871-.498L12.238 4.729s-1.131-1.649.518-2.78c1.649-1.131 2.78.518 2.78.518l7.854 11.454 1.194 1.742c-4.948 3.394-5.419 9.779-2.592 13.902.565.825 1.39.26 1.39.26-3.393-4.949-2.357-10.51 2.592-13.903L24.515 8.62s-.545-1.924 1.378-2.47c1.924-.545 2.47 1.379 2.47 1.379l1.685 5.004c.668 1.984 1.379 3.961 2.32 5.831 2.657 5.28 1.07 11.842-3.94 15.279-5.465 3.747-12.936 2.354-16.684-3.11L2.695 17.336z"/><g fill="#5DADEC"><path d="M12 32.042C8 32.042 3.958 28 3.958 24c0-.553-.405-1-.958-1s-1.042.447-1.042 1C1.958 30 6 34.042 12 34.042c.553 0 1-.489 1-1.042s-.447-.958-1-.958z"/><path d="M7 34c-3 0-5-2-5-5 0-.553-.447-1-1-1s-1 .447-1 1c0 4 3 7 7 7 .553 0 1-.447 1-1s-.447-1-1-1zM24 2c-.552 0-1 .448-1 1s.448 1 1 1c4 0 8 3.589 8 8 0 .552.448 1 1 1s1-.448 1-1c0-5.514-4-10-10-10z"/><path d="M29 .042c-.552 0-1 .406-1 .958s.448 1.042 1 1.042c3 0 4.958 2.225 4.958 4.958 0 .552.489 1 1.042 1s.958-.448.958-1C35.958 3.163 33 .042 29 .042z"/></g></svg> ¡Gracias por usar el Sistema de Gestión de Almacén!")
print("¡Has completado exitosamente tu proyecto integrador!")
break
else:
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> Opción inválida. Selecciona del 1 al 9.")
except ValueError:
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> Error: Ingresa un número válido")
except KeyboardInterrupt:
print("\n\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#EF9645" d="M4.861 9.147c.94-.657 2.357-.531 3.201.166l-.968-1.407c-.779-1.111-.5-2.313.612-3.093 1.112-.777 4.263 1.312 4.263 1.312-.786-1.122-.639-2.544.483-3.331 1.122-.784 2.67-.513 3.456.611l10.42 14.72L25 31l-11.083-4.042L4.25 12.625c-.793-1.129-.519-2.686.611-3.478z"/><path fill="#FFDC5D" d="M2.695 17.336s-1.132-1.65.519-2.781c1.649-1.131 2.78.518 2.78.518l5.251 7.658c.181-.302.379-.6.6-.894L4.557 11.21s-1.131-1.649.519-2.78c1.649-1.131 2.78.518 2.78.518l6.855 9.997c.255-.208.516-.417.785-.622L7.549 6.732s-1.131-1.649.519-2.78c1.649-1.131 2.78.518 2.78.518l7.947 11.589c.292-.179.581-.334.871-.498L12.238 4.729s-1.131-1.649.518-2.78c1.649-1.131 2.78.518 2.78.518l7.854 11.454 1.194 1.742c-4.948 3.394-5.419 9.779-2.592 13.902.565.825 1.39.26 1.39.26-3.393-4.949-2.357-10.51 2.592-13.903L24.515 8.62s-.545-1.924 1.378-2.47c1.924-.545 2.47 1.379 2.47 1.379l1.685 5.004c.668 1.984 1.379 3.961 2.32 5.831 2.657 5.28 1.07 11.842-3.94 15.279-5.465 3.747-12.936 2.354-16.684-3.11L2.695 17.336z"/><g fill="#5DADEC"><path d="M12 32.042C8 32.042 3.958 28 3.958 24c0-.553-.405-1-.958-1s-1.042.447-1.042 1C1.958 30 6 34.042 12 34.042c.553 0 1-.489 1-1.042s-.447-.958-1-.958z"/><path d="M7 34c-3 0-5-2-5-5 0-.553-.447-1-1-1s-1 .447-1 1c0 4 3 7 7 7 .553 0 1-.447 1-1s-.447-1-1-1zM24 2c-.552 0-1 .448-1 1s.448 1 1 1c4 0 8 3.589 8 8 0 .552.448 1 1 1s1-.448 1-1c0-5.514-4-10-10-10z"/><path d="M29 .042c-.552 0-1 .406-1 .958s.448 1.042 1 1.042c3 0 4.958 2.225 4.958 4.958 0 .552.489 1 1.042 1s.958-.448.958-1C35.958 3.163 33 .042 29 .042z"/></g></svg> Sistema cerrado por el usuario")
break
except Exception as e:
print(f"<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#DD2E44" d="M21.533 18.002L33.768 5.768c.976-.976.976-2.559 0-3.535-.977-.977-2.559-.977-3.535 0L17.998 14.467 5.764 2.233c-.976-.977-2.56-.977-3.535 0-.977.976-.977 2.559 0 3.535l12.234 12.234L2.201 30.265c-.977.977-.977 2.559 0 3.535.488.488 1.128.732 1.768.732s1.28-.244 1.768-.732l12.262-12.263 12.234 12.234c.488.488 1.128.732 1.768.732.64 0 1.279-.244 1.768-.732.976-.977.976-2.559 0-3.535L21.533 18.002z"/></svg> Error inesperado: {e}")
print("El sistema continuará funcionando...")
# Pausa para que el usuario pueda leer los resultados
input("\nPresiona Enter para continuar...")
# ¡Ejecutar el sistema!
if __name__ == "__main__":
ejecutar_sistema()
Análisis del Proyecto: ¿Qué has logrado?
Conceptos Integrados Exitosamente:
1. Variables y Tipos de Datos
- Diccionarios para productos, configuración
- Listas para ventas
- Strings, floats, integers, booleans
2. Operadores
- Aritméticos: cálculos de precios, IVA, descuentos
- Comparación: validaciones de stock, precios
- Lógicos: condiciones complejas
3. Estructuras de Control
- if/elif/else: validaciones, alertas, descuentos
- for: procesar ventas, mostrar inventario
- while: menú principal interactivo
4. Estructuras de Datos
- Diccionarios: inventario, productos, configuración
- Listas: registro de ventas
- Operaciones: búsqueda, ordenamiento, filtrado
5. Funciones
- Modularización del código
- Parámetros y valores de retorno
- Manejo de errores localizado
6. Manejo de Archivos
- CSV: exportación de ventas
- JSON: respaldos del inventario
- Encoding UTF-8: soporte para caracteres especiales
7. Manejo de Errores
- try/except: captura de errores
- Validaciones: datos de entrada
- Mensajes informativos: experiencia de usuario
8. Automatización
- Respaldos automáticos
- Cálculos automáticos de precios
- Generación automática de reportes
¡Felicitaciones!
Has creado un sistema completo y funcional que demuestra el dominio de todos los conceptos fundamentales de Python. Este proyecto:
- Es realista: Simula un caso de uso del mundo real
- Es completo: Integra todos los conceptos aprendidos
- Es escalable: Puedes agregar más funcionalidades
- Es educativo: Refuerza el aprendizaje práctico
Ideas para Expandir el Proyecto:
- Agregar más validaciones de datos de entrada
- Crear categorías dinámicas de productos
- Implementar alertas automáticas por email
- Agregar gráficos con matplotlib
- Crear una interfaz web con Flask
Reflexión Final
Con este proyecto has demostrado que puedes:
- 🧠 Pensar como programador: Dividir problemas complejos en funciones simples
- Usar las herramientas correctas: Elegir la estructura de datos apropiada
- 🛡️ Crear código robusto: Manejar errores y validar datos
- Diseñar experiencias: Crear interfaces amigables
- Resolver problemas reales: Automatizar tareas del mundo real
¡Ya no eres un principiante, eres un programador Python!
¿Listo para los siguientes desafíos? El mundo de la programación está lleno de oportunidades esperándote…
Planificación del Proyecto: Arquitectura Empresarial
La planificación es el ADN del éxito en cualquier proyecto de software. Como un arquitecto que diseña un rascacielos, nosotros diseñaremos un sistema empresarial robusto, escalable y mantenible. Esta fase es donde transformamos ideas en planos ejecutables.
🎯 Análisis de Requisitos: Definiendo el Éxito
📋 Requisitos Funcionales (¿Qué debe hacer?)
RF-001: Gestión Completa de Productos
# Operaciones CRUD empresariales
OPERACIONES_PRODUCTO = {
"crear": "Agregar nuevos productos al catálogo",
"leer": "Consultar información de productos existentes",
"actualizar": "Modificar datos de productos (precio, stock, etc.)",
"eliminar": "Remover productos del catálogo"
}
# Validaciones de negocio
REGLAS_PRODUCTO = {
"codigo_unico": "Cada producto debe tener código único",
"precio_positivo": "Precio debe ser mayor a cero",
"stock_no_negativo": "Stock no puede ser negativo",
"categoria_valida": "Debe pertenecer a categoría existente"
}
RF-002: Control Inteligente de Inventario
# Funcionalidades de inventario
CONTROL_INVENTARIO = {
"seguimiento_stock": "Monitoreo en tiempo real de existencias",
"alertas_automaticas": "Notificaciones de stock bajo",
"reposicion_sugerida": "Cálculo automático de cantidades a reponer",
"historial_movimientos": "Registro de entradas y salidas"
}
# Parámetros configurables
PARAMETROS_INVENTARIO = {
"stock_minimo_default": 5,
"stock_critico": 2,
"margen_reposicion": 1.5, # Factor multiplicador para sugerencias
"dias_proyeccion": 30 # Días para cálculo de demanda
}
RF-003: Procesamiento de Ventas
# Flujo de ventas
PROCESO_VENTA = {
"validacion_producto": "Verificar existencia y disponibilidad",
"validacion_stock": "Confirmar cantidad suficiente",
"calculo_total": "Precio × cantidad + impuestos - descuentos",
"actualizacion_inventario": "Descontar stock automáticamente",
"registro_transaccion": "Guardar historial de venta"
}
# Reglas de negocio para ventas
REGLAS_VENTA = {
"cantidad_minima": 1,
"cantidad_maxima": "No puede exceder stock disponible",
"descuento_maximo": 0.50, # 50% máximo de descuento
"impuesto_default": 0.16 # 16% IVA
}
RF-004: Sistema de Reportes Inteligentes
# Tipos de reportes
REPORTES_DISPONIBLES = {
"inventario_actual": "Estado completo del inventario",
"productos_stock_bajo": "Alertas de reposición",
"ventas_periodo": "Análisis de ventas por período",
"productos_mas_vendidos": "Top de productos por demanda",
"analisis_rentabilidad": "Productos más rentables",
"proyeccion_demanda": "Predicción de necesidades futuras"
}
# Formatos de exportación
FORMATOS_REPORTE = ["consola", "json", "csv", "html"]
🔧 Requisitos No Funcionales (¿Cómo debe funcionar?)
RNF-001: Rendimiento
METRICAS_RENDIMIENTO = {
"tiempo_respuesta_crud": "< 0.5 segundos",
"tiempo_carga_inventario": "< 2 segundos para 10,000 productos",
"tiempo_generacion_reporte": "< 3 segundos",
"memoria_maxima": "< 100MB para operación normal"
}
RNF-002: Confiabilidad
REQUISITOS_CONFIABILIDAD = {
"disponibilidad": "99.9% uptime",
"respaldo_automatico": "Cada operación crítica",
"recuperacion_errores": "Rollback automático en fallos",
"validacion_datos": "100% de entradas validadas"
}
RNF-003: Usabilidad
CRITERIOS_USABILIDAD = {
"interfaz_intuitiva": "Menús claros y navegación simple",
"mensajes_informativos": "Feedback claro en cada operación",
"manejo_errores": "Mensajes de error comprensibles",
"ayuda_contextual": "Instrucciones disponibles en cada pantalla"
}
🏗️ Arquitectura del Sistema: Planos Maestros
📐 Patrón de Arquitectura: MVC Empresarial
# Modelo (Model) - Lógica de negocio y datos
CAPA_MODELO = {
"entidades": ["Producto", "Venta", "Usuario", "Categoria"],
"gestores": ["GestorInventario", "GestorVentas", "GestorReportes"],
"validadores": ["ValidadorProducto", "ValidadorVenta"],
"persistencia": ["GestorArchivos", "GestorRespaldos"]
}
# Vista (View) - Interfaz de usuario
CAPA_VISTA = {
"menus": ["MenuPrincipal", "MenuProductos", "MenuVentas", "MenuReportes"],
"formularios": ["FormularioProducto", "FormularioVenta"],
"reportes": ["VistaReporte", "VistaEstadisticas"],
"utilidades": ["FormateadorPantalla", "GestorMensajes"]
}
# Controlador (Controller) - Coordinación
CAPA_CONTROLADOR = {
"coordinadores": ["ControladorPrincipal", "ControladorProductos"],
"procesadores": ["ProcesadorComandos", "ProcesadorEventos"],
"validadores": ["ValidadorEntradas", "ValidadorPermisos"]
}
🏢 Estructura Modular Empresarial
# Organización por responsabilidades
ESTRUCTURA_PROYECTO = {
"nucleo/": {
"main.py": "Punto de entrada del sistema",
"config.py": "Configuración global",
"app.py": "Aplicación principal"
},
"modelos/": {
"producto.py": "Entidad Producto y lógica asociada",
"venta.py": "Entidad Venta y procesamiento",
"usuario.py": "Gestión de usuarios y permisos",
"base.py": "Clase base para todas las entidades"
},
"gestores/": {
"inventario.py": "Gestor principal de inventario",
"ventas.py": "Procesador de transacciones",
"reportes.py": "Generador de análisis",
"archivos.py": "Persistencia de datos"
},
"interfaces/": {
"menu.py": "Sistema de menús interactivos",
"formularios.py": "Captura de datos del usuario",
"reportes_vista.py": "Presentación de reportes"
},
"utilidades/": {
"validadores.py": "Validaciones de negocio",
"formateadores.py": "Formateo de datos",
"helpers.py": "Funciones auxiliares"
},
"datos/": {
"productos.json": "Base de datos de productos",
"ventas.json": "Historial de transacciones",
"configuracion.json": "Parámetros del sistema"
},
"respaldos/": {
"automaticos/": "Respaldos programados",
"manuales/": "Respaldos bajo demanda"
}
}
🎨 Diseño de Clases: Ingeniería de Software
🏭 Jerarquía de Clases Empresariales
# Clase base para todas las entidades
class EntidadBase:
"""Clase base con funcionalidades comunes"""
def __init__(self):
self.id = self._generar_id()
self.fecha_creacion = datetime.now()
self.fecha_actualizacion = datetime.now()
self.activo = True
def _generar_id(self) -> str:
"""Genera ID único para la entidad"""
pass
def to_dict(self) -> Dict:
"""Serialización a diccionario"""
pass
def from_dict(self, datos: Dict):
"""Deserialización desde diccionario"""
pass
def validar(self) -> Tuple[bool, List[str]]:
"""Validación de reglas de negocio"""
pass
# Especialización para productos
class Producto(EntidadBase):
"""Entidad de negocio: Producto del inventario"""
def __init__(self, codigo: str, nombre: str, precio: float, stock: int):
super().__init__()
self.codigo = codigo.upper()
self.nombre = nombre
self.precio = precio
self.stock = stock
self.categoria = "General"
self.stock_minimo = 5
self.proveedor = None
self.ubicacion = None
def calcular_valor_inventario(self) -> float:
"""Calcula valor total del producto en inventario"""
return self.precio * self.stock
def necesita_reposicion(self) -> bool:
"""Determina si el producto necesita reposición"""
return self.stock <= self.stock_minimo
def aplicar_descuento(self, porcentaje: float) -> float:
"""Aplica descuento y retorna nuevo precio"""
if 0 <= porcentaje <= 0.50: # Máximo 50% descuento
return self.precio * (1 - porcentaje)
raise ValueError("Descuento debe estar entre 0% y 50%")
🎯 Patrones de Diseño Aplicados
Patrón Singleton: Configuración Global
class ConfiguracionSistema:
"""Configuración única del sistema (Singleton)"""
_instancia = None
def __new__(cls):
if cls._instancia is None:
cls._instancia = super().__new__(cls)
cls._instancia._inicializado = False
return cls._instancia
def __init__(self):
if not self._inicializado:
self.cargar_configuracion()
self._inicializado = True
def cargar_configuracion(self):
"""Carga configuración desde archivo"""
self.stock_minimo_default = 5
self.impuesto_default = 0.16
self.descuento_maximo = 0.50
Patrón Factory: Creación de Reportes
class FabricaReportes:
"""Factory para crear diferentes tipos de reportes"""
@staticmethod
def crear_reporte(tipo: str, datos: Dict) -> 'ReporteBase':
"""Crea reporte según el tipo especificado"""
if tipo == "inventario":
return ReporteInventario(datos)
elif tipo == "ventas":
return ReporteVentas(datos)
elif tipo == "estadisticas":
return ReporteEstadisticas(datos)
else:
raise ValueError(f"Tipo de reporte no soportado: {tipo}")
Patrón Observer: Sistema de Alertas
class SistemaAlertas:
"""Observer para alertas del sistema"""
def __init__(self):
self.observadores = []
def agregar_observador(self, observador):
"""Registra un observador de alertas"""
self.observadores.append(observador)
def notificar_stock_bajo(self, producto: Producto):
"""Notifica a todos los observadores sobre stock bajo"""
for observador in self.observadores:
observador.alerta_stock_bajo(producto)
📊 Flujo de Datos: Arquitectura de Información
🔄 Ciclo de Vida de los Datos
# Flujo completo de una operación
FLUJO_OPERACION = {
"1_entrada": {
"fuente": "Usuario/Sistema",
"validacion": "Sintáctica y semántica",
"sanitizacion": "Limpieza y normalización"
},
"2_procesamiento": {
"validacion_negocio": "Reglas empresariales",
"transformacion": "Conversión a formato interno",
"calculo": "Operaciones matemáticas/lógicas"
},
"3_persistencia": {
"respaldo_previo": "Backup antes de cambios",
"transaccion": "Operación atómica",
"verificacion": "Confirmación de escritura"
},
"4_respuesta": {
"formateo": "Preparación para presentación",
"logging": "Registro de la operación",
"notificacion": "Feedback al usuario"
}
}
🗄️ Modelo de Datos
# Estructura de datos empresarial
MODELO_DATOS = {
"productos": {
"estructura": {
"codigo": "str (PK, unique, 3-10 chars)",
"nombre": "str (required, 1-100 chars)",
"precio": "float (required, > 0)",
"stock": "int (required, >= 0)",
"categoria": "str (FK to categorias)",
"stock_minimo": "int (default: 5)",
"proveedor": "str (optional)",
"fecha_creacion": "datetime (auto)",
"fecha_actualizacion": "datetime (auto)"
},
"indices": ["codigo", "categoria", "nombre"],
"validaciones": ["codigo_unico", "precio_positivo", "stock_no_negativo"]
},
"ventas": {
"estructura": {
"id": "str (PK, UUID)",
"codigo_producto": "str (FK to productos)",
"cantidad": "int (required, > 0)",
"precio_unitario": "float (snapshot del precio)",
"descuento": "float (0-0.5)",
"impuesto": "float (default: 0.16)",
"total": "float (calculated)",
"fecha_venta": "datetime (auto)",
"usuario": "str (optional)"
},
"indices": ["fecha_venta", "codigo_producto"],
"validaciones": ["cantidad_positiva", "descuento_valido"]
}
}
🚀 Plan de Implementación: Roadmap Ejecutivo
📅 Cronograma de Desarrollo
Sprint 1: Fundamentos (Días 1-2)
SPRINT_1 = {
"objetivos": [
"Configurar estructura del proyecto",
"Implementar utilidades básicas",
"Crear sistema de configuración",
"Establecer manejo de archivos"
],
"entregables": [
"Estructura de directorios completa",
"Módulo de utilidades funcional",
"Sistema de logging operativo",
"Configuración centralizada"
],
"criterios_aceptacion": [
"Proyecto se ejecuta sin errores",
"Archivos JSON se crean/leen correctamente",
"Logs se generan apropiadamente"
]
}
Sprint 2: Entidades Core (Días 3-4)
SPRINT_2 = {
"objetivos": [
"Implementar clase Producto completa",
"Crear GestorInventario básico",
"Desarrollar validaciones de negocio",
"Establecer persistencia de datos"
],
"entregables": [
"Clase Producto con todos sus métodos",
"CRUD básico de productos",
"Validaciones robustas",
"Persistencia JSON funcional"
]
}
Sprint 3: Lógica de Negocio (Días 5-6)
SPRINT_3 = {
"objetivos": [
"Implementar procesamiento de ventas",
"Crear sistema de alertas",
"Desarrollar búsquedas y filtros",
"Establecer cálculos empresariales"
]
}
Sprint 4: Reportes y Análisis (Días 7-8)
SPRINT_4 = {
"objetivos": [
"Crear generador de reportes",
"Implementar estadísticas",
"Desarrollar exportación de datos",
"Crear dashboards básicos"
]
}
Sprint 5: Interfaz de Usuario (Días 9-10)
SPRINT_5 = {
"objetivos": [
"Crear sistema de menús",
"Implementar formularios interactivos",
"Desarrollar navegación fluida",
"Establecer manejo de errores UX"
]
}
🎯 Métricas de Éxito
METRICAS_PROYECTO = {
"cobertura_funcional": "100% de requisitos implementados",
"calidad_codigo": "0 errores críticos, < 5 warnings",
"rendimiento": "Todas las operaciones < 2 segundos",
"usabilidad": "Usuario puede completar tareas sin ayuda",
"mantenibilidad": "Código documentado y modular"
}
🔍 Consideraciones de Diseño: Principios de Ingeniería
🏗️ Principios SOLID Aplicados
S - Single Responsibility Principle
# ❌ MAL: Clase con múltiples responsabilidades
class ProductoTodoEnUno:
def __init__(self):
pass
def validar_producto(self):
pass
def guardar_en_archivo(self):
pass
def generar_reporte(self):
pass
def enviar_email(self):
pass
# ✅ BIEN: Responsabilidades separadas
class Producto:
"""Solo maneja datos del producto"""
pass
class ValidadorProducto:
"""Solo valida productos"""
pass
class GestorArchivos:
"""Solo maneja persistencia"""
pass
O - Open/Closed Principle
# Extensible sin modificar código existente
class ReporteBase:
"""Clase base para reportes"""
def generar(self):
raise NotImplementedError
class ReporteInventario(ReporteBase):
"""Reporte específico de inventario"""
def generar(self):
# Implementación específica
pass
# Agregar nuevos reportes sin modificar código existente
class ReporteVentas(ReporteBase):
def generar(self):
# Nueva funcionalidad
pass
🛡️ Manejo de Errores Empresarial
# Jerarquía de excepciones del negocio
class ErrorSistemaInventario(Exception):
"""Excepción base del sistema"""
pass
class ErrorProductoNoEncontrado(ErrorSistemaInventario):
"""Producto no existe en el inventario"""
pass
class ErrorStockInsuficiente(ErrorSistemaInventario):
"""No hay suficiente stock para la operación"""
pass
class ErrorValidacionNegocio(ErrorSistemaInventario):
"""Violación de reglas de negocio"""
pass
🎯 Próximos Pasos
Con esta planificación sólida, estamos listos para la implementación paso a paso. En la siguiente sección comenzaremos a construir nuestro sistema empresarial, transformando estos planos en código funcional.
✅ Lo que hemos definido:
- Requisitos claros y medibles
- Arquitectura robusta y escalable
- Diseño modular y mantenible
- Plan de implementación estructurado
- Métricas de éxito específicas
Próximo paso: Desarrollo paso a paso del sistema completo, comenzando por los cimientos y construyendo hacia arriba.
Desarrollo Paso a Paso: Construyendo el Sistema Empresarial
¡Es hora de construir nuestra obra maestra! 🏗️ En esta sección transformaremos todos los planos y diseños en código funcional. Será como dirigir la construcción de un rascacielos: cada línea de código es un ladrillo que colocamos con precisión para crear algo extraordinario.
🚀 Metodología de Construcción: De Cimientos a Cúspide
🏗️ Fase 1: Cimientos Sólidos (Configuración y Utilidades)
Comenzamos construyendo los cimientos de nuestro sistema empresarial. Como en cualquier construcción, los cimientos determinan la solidez de toda la estructura.
Paso 1.1: Configuración Central del Sistema
# archivo: config.py
"""
Configuración centralizada del Sistema de Gestión Empresarial
Todos los parámetros del sistema en un solo lugar
"""
import os
from pathlib import Path
from datetime import datetime
import json
class ConfiguracionSistema:
"""Configuración única y centralizada del sistema (Patrón Singleton)"""
_instancia = None
_inicializado = False
def __new__(cls):
if cls._instancia is None:
cls._instancia = super().__new__(cls)
return cls._instancia
def __init__(self):
if not ConfiguracionSistema._inicializado:
self._inicializar_configuracion()
ConfiguracionSistema._inicializado = True
def _inicializar_configuracion(self):
"""Inicializa toda la configuración del sistema"""
# 📁 RUTAS DEL SISTEMA
self.BASE_DIR = Path(__file__).parent
self.DATOS_DIR = self.BASE_DIR / "datos"
self.RESPALDOS_DIR = self.BASE_DIR / "respaldos"
self.LOGS_DIR = self.BASE_DIR / "logs"
self.REPORTES_DIR = self.BASE_DIR / "reportes"
self.TEMPLATES_DIR = self.BASE_DIR / "templates"
# 💾 ARCHIVOS DE BASE DE DATOS
self.DB_PRODUCTOS = self.DATOS_DIR / "productos.json"
self.DB_VENTAS = self.DATOS_DIR / "ventas.json"
self.DB_USUARIOS = self.DATOS_DIR / "usuarios.json"
self.DB_CONFIGURACION = self.DATOS_DIR / "configuracion.json"
self.DB_CATEGORIAS = self.DATOS_DIR / "categorias.json"
# 🏢 PARÁMETROS DE NEGOCIO
self.STOCK_MINIMO_DEFAULT = 5
self.STOCK_CRITICO = 2
self.DESCUENTO_MAXIMO = 0.50 # 50% máximo
self.IMPUESTO_DEFAULT = 0.16 # 16% IVA
self.MARGEN_REPOSICION = 2.0 # Factor para sugerencias de reposición
# 💰 CONFIGURACIÓN FINANCIERA
self.MONEDA_SIMBOLO = "$"
self.MONEDA_CODIGO = "MXN"
self.PRECISION_DECIMAL = 2
self.PRECIO_MINIMO = 0.01
self.PRECIO_MAXIMO = 999999.99
# 🔔 CONFIGURACIÓN DE ALERTAS
self.ALERTAS_HABILITADAS = True
self.ALERTA_STOCK_BAJO = True
self.ALERTA_PRECIO_ALTO = True
self.ALERTA_VENTA_GRANDE = True
self.UMBRAL_VENTA_GRANDE = 10000.0
# 📊 CONFIGURACIÓN DE REPORTES
self.REPORTES_AUTOMATICOS = True
self.FORMATO_FECHA_REPORTE = "%d/%m/%Y %H:%M:%S"
self.PRODUCTOS_POR_PAGINA = 20
self.DIAS_HISTORIAL_DEFAULT = 30
# 🔐 CONFIGURACIÓN DE SEGURIDAD
self.RESPALDO_AUTOMATICO = True
self.RESPALDOS_MAXIMOS = 10
self.VALIDACION_ESTRICTA = True
self.LOG_OPERACIONES = True
# 🎨 CONFIGURACIÓN DE INTERFAZ
self.LIMPIAR_PANTALLA = True
self.MOSTRAR_LOGO = True
self.COLOR_EXITO = "verde"
self.COLOR_ERROR = "rojo"
self.COLOR_ADVERTENCIA = "amarillo"
# Crear directorios necesarios
self._crear_directorios()
# Cargar configuración personalizada si existe
self._cargar_configuracion_personalizada()
def _crear_directorios(self):
"""Crea todos los directorios necesarios"""
directorios = [
self.DATOS_DIR,
self.RESPALDOS_DIR,
self.LOGS_DIR,
self.REPORTES_DIR,
self.TEMPLATES_DIR
]
for directorio in directorios:
directorio.mkdir(parents=True, exist_ok=True)
def _cargar_configuracion_personalizada(self):
"""Carga configuración personalizada desde archivo"""
if self.DB_CONFIGURACION.exists():
try:
with open(self.DB_CONFIGURACION, 'r', encoding='utf-8') as f:
config_personalizada = json.load(f)
# Aplicar configuración personalizada
for clave, valor in config_personalizada.items():
if hasattr(self, clave):
setattr(self, clave, valor)
except Exception as e:
print(f"⚠️ Error cargando configuración personalizada: {e}")
def guardar_configuracion(self):
"""Guarda la configuración actual"""
config_data = {
attr: getattr(self, attr)
for attr in dir(self)
if not attr.startswith('_') and not callable(getattr(self, attr))
}
try:
with open(self.DB_CONFIGURACION, 'w', encoding='utf-8') as f:
json.dump(config_data, f, indent=2, ensure_ascii=False, default=str)
return True
except Exception as e:
print(f"❌ Error guardando configuración: {e}")
return False
def obtener_info_sistema(self):
"""Retorna información del sistema"""
return {
"version": "1.0.0",
"nombre": "Sistema de Gestión Empresarial",
"autor": "Tu Nombre",
"fecha_creacion": datetime.now().isoformat(),
"python_version": f"{os.sys.version_info.major}.{os.sys.version_info.minor}",
"directorio_base": str(self.BASE_DIR)
}
# Instancia global de configuración
config = ConfiguracionSistema()
Paso 1.2: Sistema de Logging Empresarial
# archivo: logger.py
"""
Sistema de logging empresarial para auditoría y debugging
"""
import logging
import logging.handlers
from datetime import datetime
from pathlib import Path
from config import config
class LoggerEmpresarial:
"""Sistema de logging centralizado para el sistema empresarial"""
def __init__(self):
self.logger = None
self._configurar_logger()
def _configurar_logger(self):
"""Configura el sistema de logging"""
# Crear logger principal
self.logger = logging.getLogger('SistemaEmpresarial')
self.logger.setLevel(logging.DEBUG)
# Evitar duplicación de logs
if self.logger.handlers:
return
# Formato de logs
formato = logging.Formatter(
'%(asctime)s | %(levelname)-8s | %(name)s | %(funcName)s:%(lineno)d | %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
)
# Handler para archivo principal
archivo_log = config.LOGS_DIR / "sistema.log"
handler_archivo = logging.handlers.RotatingFileHandler(
archivo_log,
maxBytes=5*1024*1024, # 5MB
backupCount=5,
encoding='utf-8'
)
handler_archivo.setLevel(logging.INFO)
handler_archivo.setFormatter(formato)
# Handler para errores críticos
archivo_errores = config.LOGS_DIR / "errores.log"
handler_errores = logging.handlers.RotatingFileHandler(
archivo_errores,
maxBytes=2*1024*1024, # 2MB
backupCount=3,
encoding='utf-8'
)
handler_errores.setLevel(logging.ERROR)
handler_errores.setFormatter(formato)
# Handler para consola (solo en desarrollo)
handler_consola = logging.StreamHandler()
handler_consola.setLevel(logging.WARNING)
handler_consola.setFormatter(logging.Formatter(
'%(levelname)s: %(message)s'
))
# Agregar handlers
self.logger.addHandler(handler_archivo)
self.logger.addHandler(handler_errores)
self.logger.addHandler(handler_consola)
def info(self, mensaje, **kwargs):
"""Log de información"""
self.logger.info(mensaje, extra=kwargs)
def warning(self, mensaje, **kwargs):
"""Log de advertencia"""
self.logger.warning(mensaje, extra=kwargs)
def error(self, mensaje, **kwargs):
"""Log de error"""
self.logger.error(mensaje, extra=kwargs)
def critical(self, mensaje, **kwargs):
"""Log crítico"""
self.logger.critical(mensaje, extra=kwargs)
def debug(self, mensaje, **kwargs):
"""Log de debug"""
self.logger.debug(mensaje, extra=kwargs)
def operacion(self, operacion, usuario="sistema", detalles=None):
"""Log específico para operaciones de negocio"""
mensaje = f"OPERACION: {operacion} | Usuario: {usuario}"
if detalles:
mensaje += f" | Detalles: {detalles}"
self.info(mensaje)
def venta(self, codigo_producto, cantidad, total, usuario="sistema"):
"""Log específico para ventas"""
self.operacion(
"VENTA",
usuario,
f"Producto: {codigo_producto}, Cantidad: {cantidad}, Total: ${total:.2f}"
)
def inventario(self, operacion, codigo_producto, detalles=""):
"""Log específico para operaciones de inventario"""
self.operacion(
f"INVENTARIO_{operacion}",
"sistema",
f"Producto: {codigo_producto} | {detalles}"
)
# Instancia global del logger
logger = LoggerEmpresarial()
Paso 1.3: Caja de Herramientas Empresarial (Utilidades)
# archivo: utilidades.py
"""
Caja de herramientas empresarial - Utilidades fundamentales
Todas las herramientas auxiliares que necesita nuestro sistema
"""
import json
import os
import csv
import hashlib
from datetime import datetime, timedelta
from typing import Dict, List, Any, Optional, Tuple, Union
from pathlib import Path
import re
from config import config
from logger import logger
class ValidadorEmpresarial:
"""Validador de reglas de negocio empresarial"""
@staticmethod
def codigo_producto(codigo: str) -> Tuple[bool, str]:
"""Valida código de producto según estándares empresariales"""
if not codigo:
return False, "Código no puede estar vacío"
codigo = codigo.strip().upper()
if len(codigo) < 3:
return False, "Código debe tener mínimo 3 caracteres"
if len(codigo) > 10:
return False, "Código debe tener máximo 10 caracteres"
if not re.match(r'^[A-Z0-9]+$', codigo):
return False, "Código solo puede contener letras y números (sin espacios ni símbolos)"
# Verificar que no sea solo números
if codigo.isdigit():
return False, "Código debe contener al menos una letra"
return True, "Código válido"
@staticmethod
def precio_producto(precio: Union[int, float]) -> Tuple[bool, str]:
"""Valida precio según políticas empresariales"""
try:
precio = float(precio)
except (ValueError, TypeError):
return False, "Precio debe ser numérico"
if precio <= 0:
return False, "Precio debe ser positivo"
if precio < config.PRECIO_MINIMO:
return False, f"Precio mínimo permitido: ${config.PRECIO_MINIMO}"
if precio > config.PRECIO_MAXIMO:
return False, f"Precio máximo permitido: ${config.PRECIO_MAXIMO:,.2f}"
# Verificar precisión decimal
if round(precio, config.PRECISION_DECIMAL) != precio:
return False, f"Precio debe tener máximo {config.PRECISION_DECIMAL} decimales"
return True, "Precio válido"
@staticmethod
def stock_producto(stock: Union[int, str]) -> Tuple[bool, str]:
"""Valida stock según reglas empresariales"""
try:
stock = int(stock)
except (ValueError, TypeError):
return False, "Stock debe ser un número entero"
if stock < 0:
return False, "Stock no puede ser negativo"
if stock > 999999:
return False, "Stock máximo permitido: 999,999 unidades"
return True, "Stock válido"
@staticmethod
def nombre_producto(nombre: str) -> Tuple[bool, str]:
"""Valida nombre de producto"""
if not nombre or not nombre.strip():
return False, "Nombre no puede estar vacío"
nombre = nombre.strip()
if len(nombre) < 2:
return False, "Nombre debe tener mínimo 2 caracteres"
if len(nombre) > 100:
return False, "Nombre debe tener máximo 100 caracteres"
# Verificar caracteres válidos
if not re.match(r'^[a-zA-Z0-9\s\-_.,()]+$', nombre):
return False, "Nombre contiene caracteres no permitidos"
return True, "Nombre válido"
@staticmethod
def categoria_producto(categoria: str) -> Tuple[bool, str]:
"""Valida categoría de producto"""
if not categoria or not categoria.strip():
return True, "Categoría válida (se usará 'General')"
categoria = categoria.strip()
if len(categoria) > 50:
return False, "Categoría debe tener máximo 50 caracteres"
if not re.match(r'^[a-zA-Z0-9\s\-_]+$', categoria):
return False, "Categoría contiene caracteres no permitidos"
return True, "Categoría válida"
@staticmethod
def cantidad_venta(cantidad: Union[int, str]) -> Tuple[bool, str]:
"""Valida cantidad para venta"""
try:
cantidad = int(cantidad)
except (ValueError, TypeError):
return False, "Cantidad debe ser un número entero"
if cantidad <= 0:
return False, "Cantidad debe ser mayor a cero"
if cantidad > 1000:
return False, "Cantidad máxima por venta: 1,000 unidades"
return True, "Cantidad válida"
@staticmethod
def descuento(descuento: Union[int, float]) -> Tuple[bool, str]:
"""Valida descuento aplicado"""
try:
descuento = float(descuento)
except (ValueError, TypeError):
return False, "Descuento debe ser numérico"
if descuento < 0:
return False, "Descuento no puede ser negativo"
if descuento > config.DESCUENTO_MAXIMO:
return False, f"Descuento máximo permitido: {config.DESCUENTO_MAXIMO * 100}%"
return True, "Descuento válido"
class FormateadorEmpresarial:
"""Formateador de datos para presentación empresarial"""
@staticmethod
def moneda(cantidad: float, incluir_simbolo: bool = True) -> str:
"""Formatea cantidad como moneda"""
if incluir_simbolo:
return f"{config.MONEDA_SIMBOLO}{cantidad:,.{config.PRECISION_DECIMAL}f}"
else:
return f"{cantidad:,.{config.PRECISION_DECIMAL}f}"
@staticmethod
def fecha_empresarial(fecha: datetime) -> str:
"""Formatea fecha para reportes empresariales"""
return fecha.strftime(config.FORMATO_FECHA_REPORTE)
@staticmethod
def fecha_corta(fecha: datetime) -> str:
"""Formatea fecha en formato corto"""
return fecha.strftime("%d/%m/%Y")
@staticmethod
def porcentaje(decimal: float, decimales: int = 1) -> str:
"""Convierte decimal a porcentaje"""
return f"{decimal * 100:.{decimales}f}%"
@staticmethod
def numero_entero(numero: int) -> str:
"""Formatea número entero con separadores de miles"""
return f"{numero:,}"
@staticmethod
def codigo_producto(codigo: str) -> str:
"""Formatea código de producto"""
return codigo.upper().strip()
@staticmethod
def nombre_propio(texto: str) -> str:
"""Convierte texto a formato de nombre propio"""
return texto.strip().title()
@staticmethod
def texto_tabla(texto: str, ancho: int, alineacion: str = "izquierda") -> str:
"""Formatea texto para tablas con ancho fijo"""
texto = str(texto)[:ancho] # Truncar si es muy largo
if alineacion == "derecha":
return texto.rjust(ancho)
elif alineacion == "centro":
return texto.center(ancho)
else: # izquierda
return texto.ljust(ancho)
class GestorArchivos:
"""Gestor de persistencia empresarial con respaldos automáticos"""
@staticmethod
def cargar_json(archivo: Path, crear_si_no_existe: bool = True) -> Dict[str, Any]:
"""Carga datos desde archivo JSON con manejo robusto de errores"""
try:
if archivo.exists():
with open(archivo, 'r', encoding='utf-8') as f:
datos = json.load(f)
logger.debug(f"Datos cargados desde {archivo}")
return datos
else:
if crear_si_no_existe:
logger.info(f"Archivo {archivo} no existe, creando archivo vacío")
GestorArchivos.guardar_json({}, archivo)
return {}
else:
logger.warning(f"Archivo {archivo} no existe")
return {}
except json.JSONDecodeError as e:
logger.error(f"Error JSON en {archivo}: {e}")
# Intentar recuperar desde respaldo
return GestorArchivos._recuperar_desde_respaldo(archivo)
except Exception as e:
logger.error(f"Error cargando {archivo}: {e}")
return {}
@staticmethod
def guardar_json(datos: Dict[str, Any], archivo: Path, crear_respaldo: bool = True) -> bool:
"""Guarda datos en archivo JSON con respaldo automático"""
try:
# Crear respaldo si el archivo existe y está configurado
if crear_respaldo and archivo.exists() and config.RESPALDO_AUTOMATICO:
GestorArchivos._crear_respaldo(archivo)
# Crear directorio si no existe
archivo.parent.mkdir(parents=True, exist_ok=True)
# Guardar datos con formato bonito
with open(archivo, 'w', encoding='utf-8') as f:
json.dump(
datos,
f,
indent=2,
ensure_ascii=False,
default=str,
sort_keys=True
)
logger.debug(f"Datos guardados en {archivo}")
return True
except Exception as e:
logger.error(f"Error guardando {archivo}: {e}")
return False
@staticmethod
def _crear_respaldo(archivo: Path):
"""Crea respaldo de un archivo"""
try:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
nombre_respaldo = f"{archivo.stem}_backup_{timestamp}{archivo.suffix}"
archivo_respaldo = config.RESPALDOS_DIR / nombre_respaldo
# Copiar archivo
import shutil
shutil.copy2(archivo, archivo_respaldo)
logger.info(f"Respaldo creado: {archivo_respaldo}")
# Limpiar respaldos antiguos
GestorArchivos._limpiar_respaldos_antiguos(archivo.stem)
except Exception as e:
logger.error(f"Error creando respaldo de {archivo}: {e}")
@staticmethod
def _limpiar_respaldos_antiguos(prefijo: str):
"""Limpia respaldos antiguos manteniendo solo los más recientes"""
try:
patron = f"{prefijo}_backup_*"
respaldos = list(config.RESPALDOS_DIR.glob(patron))
if len(respaldos) > config.RESPALDOS_MAXIMOS:
# Ordenar por fecha de modificación (más reciente primero)
respaldos.sort(key=lambda x: x.stat().st_mtime, reverse=True)
# Eliminar los más antiguos
for respaldo in respaldos[config.RESPALDOS_MAXIMOS:]:
respaldo.unlink()
logger.debug(f"Respaldo antiguo eliminado: {respaldo}")
except Exception as e:
logger.error(f"Error limpiando respaldos antiguos: {e}")
@staticmethod
def _recuperar_desde_respaldo(archivo: Path) -> Dict[str, Any]:
"""Intenta recuperar datos desde el respaldo más reciente"""
try:
patron = f"{archivo.stem}_backup_*{archivo.suffix}"
respaldos = list(config.RESPALDOS_DIR.glob(patron))
if respaldos:
# Obtener el respaldo más reciente
respaldo_reciente = max(respaldos, key=lambda x: x.stat().st_mtime)
with open(respaldo_reciente, 'r', encoding='utf-8') as f:
datos = json.load(f)
logger.warning(f"Datos recuperados desde respaldo: {respaldo_reciente}")
return datos
else:
logger.error(f"No hay respaldos disponibles para {archivo}")
return {}
except Exception as e:
logger.error(f"Error recuperando desde respaldo: {e}")
return {}
@staticmethod
def exportar_csv(datos: List[Dict], archivo: Path, encabezados: List[str] = None) -> bool:
"""Exporta datos a archivo CSV"""
try:
if not datos:
logger.warning("No hay datos para exportar")
return False
# Crear directorio si no existe
archivo.parent.mkdir(parents=True, exist_ok=True)
# Determinar encabezados si no se proporcionan
if not encabezados:
encabezados = list(datos[0].keys())
with open(archivo, 'w', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=encabezados)
writer.writeheader()
writer.writerows(datos)
logger.info(f"Datos exportados a CSV: {archivo}")
return True
except Exception as e:
logger.error(f"Error exportando CSV {archivo}: {e}")
return False
class InterfazUsuario:
"""Utilidades para interfaz de usuario empresarial"""
@staticmethod
def limpiar_pantalla():
"""Limpia la pantalla de la consola"""
if config.LIMPIAR_PANTALLA:
os.system('cls' if os.name == 'nt' else 'clear')
@staticmethod
def pausar(mensaje: str = "Presiona Enter para continuar..."):
"""Pausa la ejecución hasta que el usuario presione Enter"""
try:
input(f"\n{mensaje}")
except KeyboardInterrupt:
print("\n👋 Operación cancelada por el usuario")
@staticmethod
def mostrar_titulo(titulo: str, caracter: str = "=", ancho: int = 60):
"""Muestra un título formateado empresarial"""
print(f"\n{caracter * ancho}")
print(f"{titulo.center(ancho)}")
print(f"{caracter * ancho}")
@staticmethod
def mostrar_subtitulo(subtitulo: str, caracter: str = "-", ancho: int = 50):
"""Muestra un subtítulo formateado"""
print(f"\n{caracter * ancho}")
print(f"{subtitulo.center(ancho)}")
print(f"{caracter * ancho}")
@staticmethod
def mostrar_mensaje_exito(mensaje: str):
"""Muestra mensaje de éxito"""
print(f"✅ {mensaje}")
@staticmethod
def mostrar_mensaje_error(mensaje: str):
"""Muestra mensaje de error"""
print(f"❌ {mensaje}")
@staticmethod
def mostrar_mensaje_advertencia(mensaje: str):
"""Muestra mensaje de advertencia"""
print(f"⚠️ {mensaje}")
@staticmethod
def mostrar_mensaje_info(mensaje: str):
"""Muestra mensaje informativo"""
print(f"ℹ️ {mensaje}")
@staticmethod
def confirmar_accion(mensaje: str, default: bool = False) -> bool:
"""Pide confirmación al usuario"""
opciones = "(s/N)" if not default else "(S/n)"
respuesta = input(f"{mensaje} {opciones}: ").strip().lower()
if not respuesta:
return default
return respuesta in ['s', 'si', 'sí', 'y', 'yes', '1']
@staticmethod
def obtener_entrada_usuario(
mensaje: str,
tipo: type = str,
validador=None,
obligatorio: bool = True,
valor_default=None
):
"""Obtiene entrada del usuario con validación robusta"""
while True:
try:
# Mostrar mensaje con valor default si existe
prompt = mensaje
if valor_default is not None:
prompt += f" [{valor_default}]"
prompt += ": "
entrada = input(prompt).strip()
# Usar valor default si no se ingresa nada
if not entrada and valor_default is not None:
entrada = str(valor_default)
# Verificar si es obligatorio
if not entrada and obligatorio:
InterfazUsuario.mostrar_mensaje_error("Este campo es obligatorio")
continue
# Si no es obligatorio y está vacío, retornar None
if not entrada and not obligatorio:
return None
# Convertir al tipo deseado
if tipo == int:
valor = int(entrada)
elif tipo == float:
valor = float(entrada)
elif tipo == bool:
valor = entrada.lower() in ['true', '1', 's', 'si', 'sí', 'yes']
else:
valor = entrada
# Aplicar validador si existe
if validador:
if callable(validador):
# Validador es una función
if hasattr(validador, '__call__'):
resultado = validador(valor)
if isinstance(resultado, tuple):
es_valido, mensaje_error = resultado
if not es_valido:
InterfazUsuario.mostrar_mensaje_error(mensaje_error)
continue
elif not resultado:
InterfazUsuario.mostrar_mensaje_error("Valor inválido")
continue
else:
# Validador es un valor/lista de valores válidos
if valor not in validador:
InterfazUsuario.mostrar_mensaje_error(f"Valor debe ser uno de: {validador}")
continue
return valor
except ValueError as e:
InterfazUsuario.mostrar_mensaje_error(f"Debe ingresar un {tipo.__name__} válido")
except KeyboardInterrupt:
print("\n👋 Operación cancelada por el usuario")
return None
except Exception as e:
InterfazUsuario.mostrar_mensaje_error(f"Error inesperado: {e}")
@staticmethod
def mostrar_menu(opciones: List[str], titulo: str = "MENÚ", mostrar_salir: bool = True) -> int:
"""Muestra un menú empresarial y devuelve la opción seleccionada"""
InterfazUsuario.mostrar_titulo(titulo)
# Mostrar opciones
for i, opcion in enumerate(opciones, 1):
print(f" {i}. {opcion}")
if mostrar_salir:
print(f" 0. Salir")
print() # Línea en blanco
# Obtener selección
while True:
try:
max_opcion = len(opciones)
min_opcion = 0 if mostrar_salir else 1
seleccion = int(input(f"Selecciona una opción ({min_opcion}-{max_opcion}): "))
if min_opcion <= seleccion <= max_opcion:
return seleccion
else:
InterfazUsuario.mostrar_mensaje_error(
f"Opción debe estar entre {min_opcion} y {max_opcion}"
)
except ValueError:
InterfazUsuario.mostrar_mensaje_error("Debe ingresar un número válido")
except KeyboardInterrupt:
print("\n👋 Saliendo del menú...")
return 0
@staticmethod
def mostrar_tabla(
datos: List[Dict],
encabezados: List[str] = None,
titulo: str = None,
max_filas: int = None
):
"""Muestra datos en formato de tabla empresarial"""
if not datos:
InterfazUsuario.mostrar_mensaje_info("No hay datos para mostrar")
return
# Determinar encabezados si no se proporcionan
if not encabezados:
encabezados = list(datos[0].keys())
# Mostrar título si se proporciona
if titulo:
InterfazUsuario.mostrar_subtitulo(titulo)
# Calcular anchos de columna
anchos = {}
for encabezado in encabezados:
ancho_encabezado = len(str(encabezado))
ancho_datos = max(len(str(fila.get(encabezado, ""))) for fila in datos)
anchos[encabezado] = max(ancho_encabezado, ancho_datos, 10) # Mínimo 10
# Mostrar encabezados
linea_separadora = "+" + "+".join("-" * (anchos[enc] + 2) for enc in encabezados) + "+"
print(linea_separadora)
encabezados_formateados = "|".join(
f" {enc.center(anchos[enc])} " for enc in encabezados
)
print(f"|{encabezados_formateados}|")
print(linea_separadora)
# Mostrar datos (limitados si se especifica max_filas)
datos_mostrar = datos[:max_filas] if max_filas else datos
for fila in datos_mostrar:
fila_formateada = "|".join(
f" {str(fila.get(enc, '')).ljust(anchos[enc])} " for enc in encabezados
)
print(f"|{fila_formateada}|")
print(linea_separadora)
# Mostrar información adicional si hay más filas
if max_filas and len(datos) > max_filas:
print(f"... y {len(datos) - max_filas} filas más")
print(f"Total de registros: {len(datos)}")
# Instancias globales para fácil acceso
validador = ValidadorEmpresarial()
formateador = FormateadorEmpresarial()
gestor_archivos = GestorArchivos()
interfaz = InterfazUsuario()
🏗️ Fase 2: Estructura Principal (Entidades de Negocio)
Con los cimientos sólidos, ahora construimos las entidades principales de nuestro sistema empresarial.
# archivo: reportes.py
"""
Módulo de generación de reportes para el sistema de inventario.
"""
from datetime import datetime
from typing import List, Dict
from inventario import GestorInventario, Producto
from utilidades import *
class GeneradorReportes:
"""Clase para generar diferentes tipos de reportes"""
def __init__(self, gestor: GestorInventario):
self.gestor = gestor
def reporte_inventario_completo(self):
"""Genera reporte completo del inventario"""
mostrar_titulo("REPORTE COMPLETO DE INVENTARIO", "=")
productos = self.gestor.listar_productos()
if not productos:
print("📦 No hay productos en el inventario")
return
# Estadísticas generales
stats = self.gestor.obtener_estadisticas()
print(f"📊 ESTADÍSTICAS GENERALES:")
print(f" Total de productos: {stats['total_productos']}")
print(f" Total de unidades: {stats['total_stock']}")
print(f" Valor total: {formatear_precio(stats['valor_total'])}")
print(f" Productos con stock bajo: {stats['productos_stock_bajo']}")
print(f" Categorías: {stats['categorias']}")
# Lista de productos
print(f"\n📦 PRODUCTOS:")
for producto in productos:
print(f" {producto}")
def reporte_stock_bajo(self):
"""Genera reporte de productos con stock bajo"""
mostrar_titulo("REPORTE DE STOCK BAJO", "⚠")
productos_bajo = self.gestor.obtener_productos_stock_bajo()
if not productos_bajo:
print("✅ Todos los productos tienen stock suficiente")
return
print(f"⚠️ {len(productos_bajo)} productos con stock bajo:")
for producto in productos_bajo:
print(f" {producto.codigo}: {producto.nombre}")
print(f" Stock actual: {producto.stock}")
print(f" Stock mínimo: {producto.stock_minimo}")
print(f" Sugerido reponer: {producto.stock_minimo * 2}")
print()
def reporte_por_categoria(self):
"""Genera reporte agrupado por categorías"""
mostrar_titulo("REPORTE POR CATEGORÍAS", "📂")
categorias = self.gestor.obtener_categorias()
for categoria in categorias:
productos = self.gestor.listar_productos(categoria)
valor_categoria = sum(p.precio * p.stock for p in productos)
print(f"\n📂 {categoria.upper()}:")
print(f" Productos: {len(productos)}")
print(f" Valor total: {formatear_precio(valor_categoria)}")
for producto in productos:
print(f" {producto}")
Programa principal
# archivo: main.py
"""
Sistema de Gestión de Inventario Inteligente
Programa principal con interfaz de usuario
"""
from inventario import GestorInventario
from reportes import GeneradorReportes
from utilidades import *
class SistemaInventario:
"""Clase principal del sistema"""
def __init__(self):
self.gestor = GestorInventario()
self.reportes = GeneradorReportes(self.gestor)
self.ejecutando = True
def mostrar_menu_principal(self):
"""Muestra el menú principal"""
opciones = [
"Gestión de Productos",
"Procesar Venta",
"Reportes",
"Buscar Productos",
"Alertas de Stock"
]
return mostrar_menu(opciones, "SISTEMA DE INVENTARIO")
def menu_gestion_productos(self):
"""Menú de gestión de productos"""
while True:
opciones = [
"Agregar Producto",
"Listar Productos",
"Actualizar Producto",
"Eliminar Producto"
]
opcion = mostrar_menu(opciones, "GESTIÓN DE PRODUCTOS")
if opcion == 0:
break
elif opcion == 1:
self.agregar_producto()
elif opcion == 2:
self.listar_productos()
elif opcion == 3:
self.actualizar_producto()
elif opcion == 4:
self.eliminar_producto()
def agregar_producto(self):
"""Interfaz para agregar producto"""
mostrar_titulo("AGREGAR PRODUCTO")
try:
codigo = obtener_entrada_usuario("Código del producto", str, validar_codigo_producto)
if not codigo:
return
nombre = obtener_entrada_usuario("Nombre del producto")
if not nombre:
return
precio = obtener_entrada_usuario("Precio", float, validar_precio)
if precio is None:
return
stock = obtener_entrada_usuario("Stock inicial", int, validar_stock)
if stock is None:
return
categoria = obtener_entrada_usuario("Categoría (opcional)", str) or "General"
stock_minimo = obtener_entrada_usuario("Stock mínimo (opcional)", int, validar_stock) or 5
exito, mensaje = self.gestor.agregar_producto(codigo, nombre, precio, stock, categoria, stock_minimo)
if exito:
print(f"✅ {mensaje}")
else:
print(f"❌ {mensaje}")
except KeyboardInterrupt:
print("\n👋 Operación cancelada")
pausar()
def procesar_venta(self):
"""Interfaz para procesar ventas"""
mostrar_titulo("PROCESAR VENTA")
try:
codigo = obtener_entrada_usuario("Código del producto")
if not codigo:
return
producto = self.gestor.obtener_producto(codigo)
if not producto:
print(f"❌ Producto {codigo} no encontrado")
pausar()
return
print(f"📦 Producto: {producto.nombre}")
print(f"💰 Precio: {formatear_precio(producto.precio)}")
print(f"📊 Stock disponible: {producto.stock}")
cantidad = obtener_entrada_usuario("Cantidad a vender", int, lambda x: x > 0)
if cantidad is None:
return
total = producto.precio * cantidad
print(f"\n💰 Total de la venta: {formatear_precio(total)}")
if confirmar_accion("¿Confirmar venta?"):
exito, mensaje, total_real = self.gestor.procesar_venta(codigo, cantidad)
if exito:
print(f"✅ {mensaje}")
print(f"💰 Total: {formatear_precio(total_real)}")
else:
print(f"❌ {mensaje}")
else:
print("👋 Venta cancelada")
except KeyboardInterrupt:
print("\n👋 Operación cancelada")
pausar()
def menu_reportes(self):
"""Menú de reportes"""
while True:
opciones = [
"Reporte Completo",
"Productos con Stock Bajo",
"Reporte por Categorías",
"Estadísticas Generales"
]
opcion = mostrar_menu(opciones, "REPORTES")
if opcion == 0:
break
elif opcion == 1:
self.reportes.reporte_inventario_completo()
pausar()
elif opcion == 2:
self.reportes.reporte_stock_bajo()
pausar()
elif opcion == 3:
self.reportes.reporte_por_categoria()
pausar()
elif opcion == 4:
self.mostrar_estadisticas()
pausar()
def ejecutar(self):
"""Ejecuta el sistema principal"""
print("🏪 Bienvenido al Sistema de Gestión de Inventario")
while self.ejecutando:
try:
opcion = self.mostrar_menu_principal()
if opcion == 0:
self.ejecutando = False
elif opcion == 1:
self.menu_gestion_productos()
elif opcion == 2:
self.procesar_venta()
elif opcion == 3:
self.menu_reportes()
elif opcion == 4:
self.buscar_productos()
elif opcion == 5:
self.mostrar_alertas()
except KeyboardInterrupt:
print("\n👋 Saliendo del sistema...")
self.ejecutando = False
print("¡Gracias por usar el Sistema de Inventario! 👋")
def main():
"""Función principal"""
sistema = SistemaInventario()
sistema.ejecutar()
if __name__ == "__main__":
main()
Pruebas del sistema
# archivo: test_sistema.py
"""
Pruebas básicas del sistema de inventario
"""
from inventario import GestorInventario, Producto
def test_crear_producto():
"""Prueba la creación de productos"""
producto = Producto("TEST01", "Producto de Prueba", 100.0, 10)
assert producto.codigo == "TEST01"
assert producto.nombre == "Producto de Prueba"
assert producto.precio == 100.0
assert producto.stock == 10
print("✅ Test crear producto: PASÓ")
def test_gestor_inventario():
"""Prueba el gestor de inventario"""
gestor = GestorInventario("test_productos.json")
# Agregar producto
exito, mensaje = gestor.agregar_producto("TEST02", "Producto Test", 50.0, 20)
assert exito, f"Error al agregar producto: {mensaje}"
# Obtener producto
producto = gestor.obtener_producto("TEST02")
assert producto is not None, "Producto no encontrado"
assert producto.nombre == "Producto Test"
# Procesar venta
exito, mensaje, total = gestor.procesar_venta("TEST02", 5)
assert exito, f"Error al procesar venta: {mensaje}"
assert total == 250.0, f"Total incorrecto: {total}"
# Verificar stock actualizado
producto = gestor.obtener_producto("TEST02")
assert producto.stock == 15, f"Stock incorrecto: {producto.stock}"
print("✅ Test gestor inventario: PASÓ")
if __name__ == "__main__":
test_crear_producto()
test_gestor_inventario()
print("🎉 Todas las pruebas pasaron!")
Mejoras y Desafíos: Evolución Empresarial
¡Felicidades! 🎉 Has construido un sistema empresarial completo y funcional. Pero como todo gran arquitecto sabe, la construcción nunca termina realmente. Siempre hay nuevos pisos que agregar, tecnologías que integrar y funcionalidades que perfeccionar.
Esta sección es tu hoja de ruta hacia la excelencia, donde transformarás tu buen sistema en un sistema extraordinario. Cada mejora que implementes te acercará más al nivel de un desarrollador profesional.
🚀 Niveles de Evolución: Tu Camino al Dominio
🥉 Nivel Bronce: Mejoras Fundamentales
“Perfeccionando los cimientos”
Mejora 1: Base de Datos Profesional (SQLite)
Evoluciona de archivos JSON a una base de datos real:
# archivo: database.py
"""
Sistema de base de datos profesional con SQLite
Reemplaza el almacenamiento JSON con una base de datos real
"""
import sqlite3
import json
from datetime import datetime
from typing import List, Dict, Optional, Tuple
from pathlib import Path
from config import config
from logger import logger
class GestorBaseDatos:
"""Gestor de base de datos SQLite para el sistema empresarial"""
def __init__(self, db_path: Path = None):
self.db_path = db_path or config.DATOS_DIR / "inventario.db"
self.init_database()
def init_database(self):
"""Inicializa la base de datos con todas las tablas necesarias"""
try:
conn = self.get_connection()
cursor = conn.cursor()
# Tabla de productos
cursor.execute('''
CREATE TABLE IF NOT EXISTS productos (
codigo TEXT PRIMARY KEY,
nombre TEXT NOT NULL,
precio REAL NOT NULL CHECK(precio > 0),
stock INTEGER NOT NULL CHECK(stock >= 0),
categoria TEXT DEFAULT 'General',
stock_minimo INTEGER DEFAULT 5 CHECK(stock_minimo >= 0),
proveedor TEXT,
ubicacion TEXT,
descripcion TEXT,
activo BOOLEAN DEFAULT 1,
fecha_creacion TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
fecha_actualizacion TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
''')
# Tabla de ventas
cursor.execute('''
CREATE TABLE IF NOT EXISTS ventas (
id INTEGER PRIMARY KEY AUTOINCREMENT,
codigo_producto TEXT NOT NULL,
cantidad INTEGER NOT NULL CHECK(cantidad > 0),
precio_unitario REAL NOT NULL CHECK(precio_unitario > 0),
descuento REAL DEFAULT 0 CHECK(descuento >= 0 AND descuento <= 1),
impuesto REAL DEFAULT 0.16,
total REAL NOT NULL,
usuario TEXT DEFAULT 'sistema',
fecha_venta TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (codigo_producto) REFERENCES productos (codigo)
)
''')
# Tabla de categorías
cursor.execute('''
CREATE TABLE IF NOT EXISTS categorias (
id INTEGER PRIMARY KEY AUTOINCREMENT,
nombre TEXT UNIQUE NOT NULL,
descripcion TEXT,
activa BOOLEAN DEFAULT 1,
fecha_creacion TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
''')
# Tabla de usuarios
cursor.execute('''
CREATE TABLE IF NOT EXISTS usuarios (
id INTEGER PRIMARY KEY AUTOINCREMENT,
username TEXT UNIQUE NOT NULL,
nombre_completo TEXT NOT NULL,
email TEXT UNIQUE,
rol TEXT DEFAULT 'operador',
activo BOOLEAN DEFAULT 1,
fecha_creacion TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
ultimo_acceso TIMESTAMP
)
''')
# Tabla de configuración
cursor.execute('''
CREATE TABLE IF NOT EXISTS configuracion (
clave TEXT PRIMARY KEY,
valor TEXT NOT NULL,
descripcion TEXT,
fecha_actualizacion TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
''')
# Índices para mejorar rendimiento
cursor.execute('CREATE INDEX IF NOT EXISTS idx_productos_categoria ON productos(categoria)')
cursor.execute('CREATE INDEX IF NOT EXISTS idx_productos_activo ON productos(activo)')
cursor.execute('CREATE INDEX IF NOT EXISTS idx_ventas_fecha ON ventas(fecha_venta)')
cursor.execute('CREATE INDEX IF NOT EXISTS idx_ventas_producto ON ventas(codigo_producto)')
conn.commit()
logger.info("Base de datos inicializada correctamente")
except Exception as e:
logger.error(f"Error inicializando base de datos: {e}")
raise
finally:
conn.close()
def get_connection(self) -> sqlite3.Connection:
"""Obtiene conexión a la base de datos"""
conn = sqlite3.connect(self.db_path)
conn.row_factory = sqlite3.Row # Para acceso por nombre de columna
return conn
def migrar_desde_json(self, archivo_productos: Path):
"""Migra datos existentes desde JSON a SQLite"""
try:
if not archivo_productos.exists():
logger.info("No hay archivo JSON para migrar")
return
with open(archivo_productos, 'r', encoding='utf-8') as f:
productos_json = json.load(f)
conn = self.get_connection()
cursor = conn.cursor()
productos_migrados = 0
for codigo, datos in productos_json.items():
try:
cursor.execute('''
INSERT OR REPLACE INTO productos
(codigo, nombre, precio, stock, categoria, stock_minimo, fecha_creacion)
VALUES (?, ?, ?, ?, ?, ?, ?)
''', (
codigo,
datos['nombre'],
datos['precio'],
datos['stock'],
datos.get('categoria', 'General'),
datos.get('stock_minimo', 5),
datos.get('fecha_creacion', datetime.now().isoformat())
))
productos_migrados += 1
except Exception as e:
logger.error(f"Error migrando producto {codigo}: {e}")
conn.commit()
logger.info(f"Migración completada: {productos_migrados} productos")
except Exception as e:
logger.error(f"Error en migración: {e}")
finally:
conn.close()
def ejecutar_consulta(self, query: str, params: tuple = ()) -> List[sqlite3.Row]:
"""Ejecuta una consulta SELECT y retorna los resultados"""
try:
conn = self.get_connection()
cursor = conn.cursor()
cursor.execute(query, params)
resultados = cursor.fetchall()
return resultados
except Exception as e:
logger.error(f"Error ejecutando consulta: {e}")
return []
finally:
conn.close()
def ejecutar_comando(self, query: str, params: tuple = ()) -> bool:
"""Ejecuta un comando INSERT/UPDATE/DELETE"""
try:
conn = self.get_connection()
cursor = conn.cursor()
cursor.execute(query, params)
conn.commit()
return True
except Exception as e:
logger.error(f"Error ejecutando comando: {e}")
return False
finally:
conn.close()
# Ejemplo de uso del nuevo sistema de base de datos
class ProductoConDB:
"""Versión mejorada de la clase Producto que usa SQLite"""
def __init__(self, db_manager: GestorBaseDatos):
self.db = db_manager
def crear_producto(self, codigo: str, nombre: str, precio: float,
stock: int, categoria: str = "General") -> Tuple[bool, str]:
"""Crea un nuevo producto en la base de datos"""
query = '''
INSERT INTO productos (codigo, nombre, precio, stock, categoria)
VALUES (?, ?, ?, ?, ?)
'''
if self.db.ejecutar_comando(query, (codigo, nombre, precio, stock, categoria)):
logger.operacion("CREAR_PRODUCTO", detalles=f"Código: {codigo}")
return True, f"Producto {codigo} creado exitosamente"
else:
return False, "Error al crear el producto"
def obtener_producto(self, codigo: str) -> Optional[Dict]:
"""Obtiene un producto por su código"""
query = "SELECT * FROM productos WHERE codigo = ? AND activo = 1"
resultados = self.db.ejecutar_consulta(query, (codigo,))
if resultados:
return dict(resultados[0])
return None
def listar_productos(self, categoria: str = None, activos_solo: bool = True) -> List[Dict]:
"""Lista productos con filtros opcionales"""
query = "SELECT * FROM productos"
params = []
condiciones = []
if activos_solo:
condiciones.append("activo = 1")
if categoria:
condiciones.append("categoria = ?")
params.append(categoria)
if condiciones:
query += " WHERE " + " AND ".join(condiciones)
query += " ORDER BY nombre"
resultados = self.db.ejecutar_consulta(query, tuple(params))
return [dict(row) for row in resultados]
def actualizar_stock(self, codigo: str, nuevo_stock: int) -> Tuple[bool, str]:
"""Actualiza el stock de un producto"""
query = '''
UPDATE productos
SET stock = ?, fecha_actualizacion = CURRENT_TIMESTAMP
WHERE codigo = ? AND activo = 1
'''
if self.db.ejecutar_comando(query, (nuevo_stock, codigo)):
logger.operacion("ACTUALIZAR_STOCK", detalles=f"Código: {codigo}, Nuevo stock: {nuevo_stock}")
return True, f"Stock actualizado para {codigo}"
else:
return False, "Error al actualizar stock"
def productos_stock_bajo(self) -> List[Dict]:
"""Obtiene productos con stock bajo"""
query = '''
SELECT * FROM productos
WHERE stock <= stock_minimo AND activo = 1
ORDER BY (stock - stock_minimo), nombre
'''
resultados = self.db.ejecutar_consulta(query)
return [dict(row) for row in resultados]
Mejora 2: Sistema de Autenticación y Usuarios
# archivo: autenticacion.py
"""
Sistema de autenticación y gestión de usuarios
"""
import hashlib
import secrets
from datetime import datetime, timedelta
from typing import Optional, Dict, List, Tuple
class GestorUsuarios:
"""Gestor de usuarios y autenticación"""
def __init__(self, db_manager):
self.db = db_manager
self.usuario_actual = None
self.sesion_activa = False
def hash_password(self, password: str, salt: str = None) -> Tuple[str, str]:
"""Genera hash seguro de contraseña"""
if not salt:
salt = secrets.token_hex(16)
# Usar PBKDF2 para mayor seguridad
password_hash = hashlib.pbkdf2_hmac(
'sha256',
password.encode('utf-8'),
salt.encode('utf-8'),
100000 # 100,000 iteraciones
)
return password_hash.hex(), salt
def crear_usuario(self, username: str, password: str, nombre_completo: str,
email: str = None, rol: str = "operador") -> Tuple[bool, str]:
"""Crea un nuevo usuario"""
# Verificar si el usuario ya existe
if self.obtener_usuario(username):
return False, "El usuario ya existe"
# Generar hash de contraseña
password_hash, salt = self.hash_password(password)
# Insertar usuario
query = '''
INSERT INTO usuarios (username, password_hash, salt, nombre_completo, email, rol)
VALUES (?, ?, ?, ?, ?, ?)
'''
if self.db.ejecutar_comando(query, (username, password_hash, salt, nombre_completo, email, rol)):
logger.operacion("CREAR_USUARIO", detalles=f"Usuario: {username}, Rol: {rol}")
return True, f"Usuario {username} creado exitosamente"
else:
return False, "Error al crear usuario"
def autenticar(self, username: str, password: str) -> Tuple[bool, str]:
"""Autentica un usuario"""
usuario = self.obtener_usuario(username)
if not usuario:
return False, "Usuario no encontrado"
if not usuario['activo']:
return False, "Usuario inactivo"
# Verificar contraseña
password_hash, _ = self.hash_password(password, usuario['salt'])
if password_hash == usuario['password_hash']:
self.usuario_actual = usuario
self.sesion_activa = True
# Actualizar último acceso
self.db.ejecutar_comando(
"UPDATE usuarios SET ultimo_acceso = CURRENT_TIMESTAMP WHERE username = ?",
(username,)
)
logger.operacion("LOGIN", usuario=username)
return True, f"Bienvenido, {usuario['nombre_completo']}"
else:
logger.operacion("LOGIN_FALLIDO", usuario=username)
return False, "Contraseña incorrecta"
def cerrar_sesion(self):
"""Cierra la sesión actual"""
if self.usuario_actual:
logger.operacion("LOGOUT", usuario=self.usuario_actual['username'])
self.usuario_actual = None
self.sesion_activa = False
def tiene_permiso(self, operacion: str) -> bool:
"""Verifica si el usuario actual tiene permiso para una operación"""
if not self.sesion_activa or not self.usuario_actual:
return False
rol = self.usuario_actual['rol']
# Definir permisos por rol
permisos = {
'admin': ['*'], # Todos los permisos
'gerente': ['ver_productos', 'crear_producto', 'actualizar_producto',
'procesar_venta', 'ver_reportes', 'gestionar_usuarios'],
'vendedor': ['ver_productos', 'procesar_venta', 'ver_reportes_basicos'],
'operador': ['ver_productos', 'actualizar_stock']
}
permisos_rol = permisos.get(rol, [])
return '*' in permisos_rol or operacion in permisos_rol
Mejora 3: Sistema de Reportes Avanzados
# archivo: reportes_avanzados.py
"""
Sistema de reportes empresariales avanzados con gráficos y análisis
"""
import matplotlib.pyplot as plt
import pandas as pd
from datetime import datetime, timedelta
import seaborn as sns
from typing import Dict, List, Optional
class GeneradorReportesAvanzados:
"""Generador de reportes empresariales con visualizaciones"""
def __init__(self, db_manager):
self.db = db_manager
# Configurar estilo de gráficos
plt.style.use('seaborn-v0_8')
sns.set_palette("husl")
def reporte_ventas_temporales(self, dias: int = 30) -> Dict:
"""Genera reporte de ventas por período con gráfico"""
fecha_inicio = datetime.now() - timedelta(days=dias)
query = '''
SELECT DATE(fecha_venta) as fecha,
COUNT(*) as num_ventas,
SUM(total) as total_ventas,
AVG(total) as promedio_venta
FROM ventas
WHERE fecha_venta >= ?
GROUP BY DATE(fecha_venta)
ORDER BY fecha
'''
resultados = self.db.ejecutar_consulta(query, (fecha_inicio.isoformat(),))
if not resultados:
return {"mensaje": "No hay datos de ventas para el período"}
# Convertir a DataFrame para análisis
df = pd.DataFrame([dict(row) for row in resultados])
df['fecha'] = pd.to_datetime(df['fecha'])
# Crear gráfico
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 10))
# Gráfico de ventas diarias
ax1.plot(df['fecha'], df['total_ventas'], marker='o', linewidth=2, markersize=6)
ax1.set_title(f'Ventas Diarias - Últimos {dias} días', fontsize=14, fontweight='bold')
ax1.set_ylabel('Total Ventas ($)')
ax1.grid(True, alpha=0.3)
ax1.tick_params(axis='x', rotation=45)
# Gráfico de número de transacciones
ax2.bar(df['fecha'], df['num_ventas'], alpha=0.7, color='skyblue')
ax2.set_title('Número de Transacciones Diarias', fontsize=14, fontweight='bold')
ax2.set_ylabel('Número de Ventas')
ax2.set_xlabel('Fecha')
ax2.grid(True, alpha=0.3)
ax2.tick_params(axis='x', rotation=45)
plt.tight_layout()
# Guardar gráfico
archivo_grafico = config.REPORTES_DIR / f"ventas_temporales_{datetime.now().strftime('%Y%m%d')}.png"
plt.savefig(archivo_grafico, dpi=300, bbox_inches='tight')
plt.show()
# Estadísticas resumidas
estadisticas = {
"periodo": f"{fecha_inicio.strftime('%d/%m/%Y')} - {datetime.now().strftime('%d/%m/%Y')}",
"total_ventas": float(df['total_ventas'].sum()),
"promedio_diario": float(df['total_ventas'].mean()),
"mejor_dia": {
"fecha": df.loc[df['total_ventas'].idxmax(), 'fecha'].strftime('%d/%m/%Y'),
"ventas": float(df['total_ventas'].max())
},
"total_transacciones": int(df['num_ventas'].sum()),
"promedio_transacciones": float(df['num_ventas'].mean()),
"archivo_grafico": str(archivo_grafico)
}
return estadisticas
def analisis_productos_abc(self) -> Dict:
"""Análisis ABC de productos (80/20 rule)"""
query = '''
SELECT p.codigo, p.nombre, p.categoria,
COALESCE(SUM(v.cantidad * v.precio_unitario), 0) as ingresos_totales,
COALESCE(SUM(v.cantidad), 0) as unidades_vendidas,
p.stock, p.precio
FROM productos p
LEFT JOIN ventas v ON p.codigo = v.codigo_producto
WHERE p.activo = 1
GROUP BY p.codigo, p.nombre, p.categoria, p.stock, p.precio
ORDER BY ingresos_totales DESC
'''
resultados = self.db.ejecutar_consulta(query)
if not resultados:
return {"mensaje": "No hay datos suficientes para análisis ABC"}
df = pd.DataFrame([dict(row) for row in resultados])
# Calcular porcentajes acumulados
df['porcentaje_ingresos'] = (df['ingresos_totales'] / df['ingresos_totales'].sum()) * 100
df['porcentaje_acumulado'] = df['porcentaje_ingresos'].cumsum()
# Clasificar productos ABC
def clasificar_abc(porcentaje_acum):
if porcentaje_acum <= 80:
return 'A'
elif porcentaje_acum <= 95:
return 'B'
else:
return 'C'
df['clasificacion'] = df['porcentaje_acumulado'].apply(clasificar_abc)
# Crear gráfico de Pareto
fig, ax1 = plt.subplots(figsize=(14, 8))
# Barras de ingresos
bars = ax1.bar(range(len(df)), df['ingresos_totales'], alpha=0.7, color='steelblue')
ax1.set_xlabel('Productos (ordenados por ingresos)')
ax1.set_ylabel('Ingresos Totales ($)', color='steelblue')
ax1.tick_params(axis='y', labelcolor='steelblue')
# Línea de porcentaje acumulado
ax2 = ax1.twinx()
ax2.plot(range(len(df)), df['porcentaje_acumulado'], color='red', marker='o', linewidth=2)
ax2.set_ylabel('Porcentaje Acumulado (%)', color='red')
ax2.tick_params(axis='y', labelcolor='red')
ax2.set_ylim(0, 100)
# Líneas de referencia ABC
ax2.axhline(y=80, color='orange', linestyle='--', alpha=0.7, label='80% (A-B)')
ax2.axhline(y=95, color='green', linestyle='--', alpha=0.7, label='95% (B-C)')
plt.title('Análisis ABC de Productos (Principio de Pareto)', fontsize=16, fontweight='bold')
plt.legend()
plt.tight_layout()
# Guardar gráfico
archivo_grafico = config.REPORTES_DIR / f"analisis_abc_{datetime.now().strftime('%Y%m%d')}.png"
plt.savefig(archivo_grafico, dpi=300, bbox_inches='tight')
plt.show()
# Estadísticas por clasificación
resumen_abc = df.groupby('clasificacion').agg({
'codigo': 'count',
'ingresos_totales': 'sum',
'unidades_vendidas': 'sum'
}).round(2)
return {
"productos_a": int(resumen_abc.loc['A', 'codigo']) if 'A' in resumen_abc.index else 0,
"productos_b": int(resumen_abc.loc['B', 'codigo']) if 'B' in resumen_abc.index else 0,
"productos_c": int(resumen_abc.loc['C', 'codigo']) if 'C' in resumen_abc.index else 0,
"ingresos_a": float(resumen_abc.loc['A', 'ingresos_totales']) if 'A' in resumen_abc.index else 0,
"archivo_grafico": str(archivo_grafico),
"productos_detalle": df.to_dict('records')
}
self.crear_interfaz()
def crear_interfaz(self):
"""Crea la interfaz gráfica"""
# Frame principal
main_frame = ttk.Frame(self.root, padding="10")
main_frame.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
# Botones principales
ttk.Button(main_frame, text="Agregar Producto",
command=self.ventana_agregar_producto).grid(row=0, column=0, padx=5)
ttk.Button(main_frame, text="Listar Productos",
command=self.mostrar_productos).grid(row=0, column=1, padx=5)
command=self.listar_productos).grid(row=0, column=1, padx=5)
# Tabla de productos
self.tree = ttk.Treeview(main_frame, columns=("Código", "Nombre", "Precio", "Stock"))
self.tree.grid(row=1, column=0, columnspan=3, pady=10)
3. API REST
Crear una API con Flask:
from flask import Flask, jsonify, request
from inventario import GestorInventario
app = Flask(__name__)
gestor = GestorInventario()
@app.route("/api/productos", methods=["GET"])
def obtener_productos():
productos = gestor.listar_productos()
return jsonify([p.to_dict() for p in productos])
@app.route('/api/productos', methods=['POST'])
def agregar_producto():
datos = request.json
exito, mensaje = gestor.agregar_producto(
datos['codigo'], datos['nombre'],
datos['precio'], datos['stock']
)
return jsonify({'exito': exito, 'mensaje': mensaje})
if __name__ == '__main__':
app.run(debug=True)
app.run(debug=True)
Funcionalidades adicionales
1. Sistema de usuarios
class Usuario:
def __init__(self, username, password, rol="empleado"):
self.username = username
self.password = password # En producción, usar hash
self.rol = rol
self.fecha_creacion = datetime.now()
class GestorUsuarios:
def __init__(self):
self.usuarios = {}
self.usuario_actual = None
def autenticar(self, username, password):
"""Autentica un usuario"""
usuario = self.usuarios.get(username)
if usuario and usuario.password == password:
self.usuario_actual = usuario
return True
return False
2. Historial de movimientos
class MovimientoInventario:
def __init__(self, tipo, producto_codigo, cantidad, usuario, motivo=""):
self.tipo = tipo # "entrada", "salida", "ajuste"
self.producto_codigo = producto_codigo
self.cantidad = cantidad
self.usuario = usuario
self.motivo = motivo
self.fecha = datetime.now()
class GestorMovimientos:
def __init__(self):
self.movimientos = []
def registrar_movimiento(self, tipo, producto_codigo, cantidad, usuario, motivo=""):
"""Registra un movimiento de inventario"""
movimiento = MovimientoInventario(tipo, producto_codigo, cantidad, usuario, motivo)
self.movimientos.append(movimiento)
3. Códigos de barras
import barcode
from barcode.writer import ImageWriter
def generar_codigo_barras(codigo_producto):
"""Genera código de barras para un producto"""
code128 = barcode.get_barcode_class('code128')
codigo = code128(codigo_producto, writer=ImageWriter())
filename = f"codigos_barras/{codigo_producto}.png"
codigo.save(filename)
return filename
Desafíos de programación
Desafío 1: Predicción de demanda
Implementa un algoritmo simple para predecir cuándo se agotará un producto:
def predecir_agotamiento(producto, historial_ventas):
"""Predice cuándo se agotará un producto"""
if not historial_ventas:
return None
# Calcular promedio de ventas diarias
ventas_diarias = sum(historial_ventas) / len(historial_ventas)
if ventas_diarias <= 0:
return None
# Días hasta agotamiento
dias_restantes = producto.stock / ventas_diarias
fecha_agotamiento = datetime.now() + timedelta(days=dias_restantes)
return fecha_agotamiento
Desafío 2: Optimización de inventario
Calcula el punto de reorden óptimo:
def calcular_punto_reorden(demanda_promedio, tiempo_reposicion, stock_seguridad):
"""Calcula el punto de reorden óptimo"""
return (demanda_promedio * tiempo_reposicion) + stock_seguridad
def sugerir_cantidad_pedido(producto, costo_pedido, costo_almacenamiento, demanda_anual):
"""Sugiere cantidad óptima de pedido usando EOQ"""
import math
# Fórmula EOQ (Economic Order Quantity)
eoq = math.sqrt((2 * demanda_anual * costo_pedido) / costo_almacenamiento)
return round(eoq)
Desafío 3: Dashboard en tiempo real
Crea un dashboard que se actualice automáticamente:
import threading
import time
class DashboardTiempoReal:
def __init__(self, gestor):
self.gestor = gestor
self.ejecutando = False
def iniciar_monitoreo(self):
"""Inicia el monitoreo en tiempo real"""
self.ejecutando = True
thread = threading.Thread(target=self._monitorear)
thread.daemon = True
thread.start()
def _monitorear(self):
"""Monitorea el inventario continuamente"""
while self.ejecutando:
self._actualizar_dashboard()
time.sleep(30) # Actualizar cada 30 segundos
def _actualizar_dashboard(self):
"""Actualiza la información del dashboard"""
stats = self.gestor.obtener_estadisticas()
productos_bajo = self.gestor.obtener_productos_stock_bajo()
# Aquí actualizarías la interfaz gráfica
print(f"Dashboard actualizado: {len(productos_bajo)} productos con stock bajo")
Mejores prácticas implementadas
1. Logging
import logging
# Configurar logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('inventario.log'),
logging.StreamHandler()
]
)
logger = logging.getLogger(__name__)
class GestorInventario:
def agregar_producto(self, codigo, nombre, precio, stock):
logger.info(f"Agregando producto: {codigo} - {nombre}")
# ... resto del código
2. Configuración externa
# archivo: config.py
import json
class Configuracion:
def __init__(self, archivo_config="config.json"):
self.config = self.cargar_configuracion(archivo_config)
def cargar_configuracion(self, archivo):
"""Carga configuración desde archivo JSON"""
try:
with open(archivo, 'r') as f:
return json.load(f)
except FileNotFoundError:
return self.configuracion_por_defecto()
def configuracion_por_defecto(self):
"""Configuración por defecto"""
return {
"stock_minimo_global": 5,
"moneda": "USD",
"idioma": "es",
"backup_automatico": True,
"intervalo_backup": 3600 # segundos
}
3. Tests automatizados
import unittest
from inventario import GestorInventario, Producto
class TestInventario(unittest.TestCase):
def setUp(self):
"""Configuración antes de cada test"""
self.gestor = GestorInventario("test_db.json")
def test_agregar_producto(self):
"""Test agregar producto"""
exito, mensaje = self.gestor.agregar_producto("TEST01", "Test", 100, 10)
self.assertTrue(exito)
self.assertIn("TEST01", self.gestor.productos)
def test_procesar_venta(self):
"""Test procesar venta"""
self.gestor.agregar_producto("TEST02", "Test", 50, 20)
exito, mensaje, total = self.gestor.procesar_venta("TEST02", 5)
self.assertTrue(exito)
self.assertEqual(total, 250.0)
def tearDown(self):
"""Limpieza después de cada test"""
import os
if os.path.exists("test_db.json"):
os.remove("test_db.json")
if __name__ == '__main__':
unittest.main()
Próximos pasos
- Implementa una mejora: Elige una de las sugerencias y desarróllala
- Optimiza el rendimiento: Identifica cuellos de botella
- Añade más validaciones: Mejora la robustez del sistema
- Crea documentación: Escribe manuales de usuario
- Despliega el sistema: Ponlo en producción
¡El proyecto está listo para crecer y evolucionar según tus necesidades!
Conclusión: Tu Viaje de Construcción Empresarial
🧭 Navegación:
- Anterior: Mejoras y Desafíos
- Siguiente: Siguientes Pasos
🏆 ¡Lo has logrado!
¡Felicidades, constructor maestro! 🎉 Has completado un viaje extraordinario desde la concepción hasta la implementación de un sistema empresarial completo. Este no es un logro menor: has aplicado prácticamente todos los conceptos de Python que hemos explorado a lo largo del libro para crear algo funcional, útil y profesional.
📊 Evaluación del Proyecto: Lo que has construido
Tomemos un momento para apreciar la magnitud de lo que has logrado:
🏗️ Arquitectura Completa
- Diseñaste una estructura modular con separación clara de responsabilidades
- Implementaste patrones de diseño como Singleton, Factory y Repository
- Creaste un sistema con capas bien definidas (datos, lógica de negocio, interfaz)
💾 Gestión de Datos Robusta
- Desarrollaste un sistema de persistencia con archivos JSON
- Implementaste validación de datos para mantener la integridad
- Creaste mecanismos de respaldo para prevenir pérdida de información
🧠 Lógica de Negocio Sofisticada
- Programaste reglas de negocio complejas para inventario y ventas
- Implementaste cálculos automáticos para precios, impuestos y ganancias
- Creaste alertas inteligentes basadas en umbrales configurables
👤 Interfaz de Usuario Funcional
- Diseñaste un menú interactivo intuitivo y fácil de navegar
- Implementaste formularios de entrada con validación en tiempo real
- Creaste reportes formativos que presentan información de manera clara
🔄 Integración de Conceptos: Tu Caja de Herramientas Completa
Este proyecto ha sido el escenario perfecto para aplicar todo lo que has aprendido:
📚 Fundamentos de Python
- Variables y tipos de datos: Para almacenar y manipular información empresarial
- Operadores y expresiones: Para cálculos de precios, impuestos y descuentos
- Estructuras de control: Para implementar la lógica de decisión del negocio
🧰 Estructuras de Datos
- Listas: Para colecciones de productos, transacciones y usuarios
- Diccionarios: Para representar entidades con atributos (productos, clientes)
- Tuplas: Para datos inmutables como códigos y registros históricos
- Conjuntos: Para operaciones de filtrado y eliminación de duplicados
🛠️ Organización de Código
- Funciones: Para encapsular operaciones específicas y promover la reutilización
- Módulos: Para organizar el código en unidades lógicas y manejables
- Clases y objetos: Para modelar entidades del mundo real con comportamiento
- Manejo de errores: Para crear un sistema robusto que anticipa problemas
📂 Operaciones con Archivos
- Lectura/escritura de archivos: Para persistencia de datos
- Formato JSON: Para almacenamiento estructurado
- Logging: Para registro de actividades y depuración
🚀 De Proyecto a Producto: Próximos Pasos
Tu sistema tiene el potencial de convertirse en un producto real. Aquí hay algunas direcciones que podrías tomar:
💼 Uso Profesional
- Personalízalo para un negocio específico (tienda, restaurante, almacén)
- Expande las funcionalidades según las necesidades específicas
- Documenta exhaustivamente para facilitar su uso y mantenimiento
🌐 Evolución Tecnológica
- Migra a una base de datos como SQLite o PostgreSQL
- Desarrolla una interfaz web con Flask o Django
- Implementa una API REST para integración con otros sistemas
- Añade autenticación y autorización para múltiples usuarios con diferentes roles
📱 Expansión de Plataformas
- Crea una versión móvil para gestión en movimiento
- Implementa sincronización en la nube para acceso desde múltiples dispositivos
- Desarrolla un panel de administración para configuración avanzada
🧠 Reflexión: Más Allá del Código
Este proyecto no solo te ha enseñado a programar; te ha introducido a:
🏢 Pensamiento Empresarial
- Comprender cómo el software puede modelar procesos de negocio
- Identificar necesidades y traducirlas en soluciones técnicas
- Balancear funcionalidad, usabilidad y mantenibilidad
🧩 Arquitectura de Software
- Diseñar sistemas modulares y escalables
- Separar responsabilidades en componentes especializados
- Planificar para el cambio y la evolución
👥 Perspectiva de Usuario
- Considerar la experiencia del usuario final
- Diseñar interfaces intuitivas y eficientes
- Anticipar necesidades y puntos de fricción
🌟 Tu Legado de Código
Este proyecto representa tu transición de estudiante a creador. Es la prueba tangible de que puedes:
- Analizar un problema complejo y dividirlo en partes manejables
- Diseñar una solución estructurada y coherente
- Implementar esa solución con código limpio y funcional
- Probar y refinar hasta lograr un resultado profesional
🔮 El Futuro: Tu Camino Como Desarrollador
Con las habilidades que has demostrado en este proyecto, estás preparado para:
- Contribuir a proyectos de código abierto
- Desarrollar aplicaciones personales para resolver problemas específicos
- Explorar roles profesionales en desarrollo de software
- Especializarte en áreas como desarrollo web, ciencia de datos o automatización
🎓 Certificado de Logro
+---------------------------------------------------------------+
| |
| CERTIFICADO DE FINALIZACIÓN |
| |
| Este documento certifica que has completado exitosamente |
| el proyecto integrador "Sistema de Gestión Empresarial" |
| demostrando dominio de los conceptos fundamentales de |
| Python y habilidades de desarrollo de software. |
| |
| Habilidades demostradas: |
| - Diseño e implementación de sistemas modulares |
| - Programación orientada a objetos |
| - Gestión de datos y persistencia |
| - Desarrollo de interfaces de usuario |
| - Implementación de lógica de negocio |
| |
+---------------------------------------------------------------+
🔍 Comprueba tu comprensión final
- ¿Qué patrones de diseño implementaste en este proyecto y por qué son útiles?
- ¿Cómo manejarías la migración de datos si quisieras pasar de archivos JSON a una base de datos SQL?
- ¿Qué consideraciones de seguridad deberías tener en cuenta si este sistema se usara en un entorno de producción?
- ¿Cómo podrías adaptar este sistema para manejar múltiples tiendas o sucursales?
- Si tuvieras que elegir una característica para implementar a continuación, ¿cuál sería y por qué?
En el próximo capítulo, exploraremos los Siguientes Pasos en tu viaje como programador Python, donde descubrirás cómo continuar tu aprendizaje y qué caminos puedes tomar para especializarte.
Siguientes Pasos
🧭 Navegación:
- Anterior: Mini Proyecto – Integrando Todo
- Siguiente: Apéndices
¡Felicitaciones! Has completado tu viaje inicial por el mundo de la programación en Python. Has transformado tu almacén mental de conceptos vacíos en una operación completa y funcional, llena de herramientas poderosas y conocimientos prácticos.
Lo que has logrado
A lo largo de este libro, has dominado los fundamentos esenciales de la programación en Python:
Fundamentos sólidos construidos
- Variables y tipos de datos - Tus cajas organizadas para almacenar información
- Operadores y expresiones - Tus herramientas para procesar y comparar datos
- Control de flujo - Tu gerente inteligente que toma decisiones y automatiza tareas
- Estructuras de datos - Tus sistemas de organización avanzados
- Funciones - Tus máquinas especializadas reutilizables
- Módulos estándar - Tu acceso al almacén gigante de herramientas de Python
Habilidades desarrolladas
- Puedes leer y escribir código Python básico con confianza
- Sabes resolver problemas dividiéndolos en pasos lógicos
- Puedes crear programas que automatizan tareas simples
- Entiendes cómo pensar como programador
- Tienes las bases para continuar aprendiendo conceptos más avanzados
Cómo continuar practicando
Ejercicios recomendados
Para reforzar lo aprendido, te sugiero practicar con estos tipos de ejercicios:
-
Calculadoras especializadas
- Calculadora de propinas
- Convertidor de unidades (temperatura, distancia, peso)
- Calculadora de interés compuesto
-
Juegos simples de texto
- Adivina el número
- Piedra, papel o tijeras
- Quiz de preguntas y respuestas
-
Herramientas de texto
- Contador de palabras
- Generador de contraseñas simples
- Analizador de texto básico
-
Simuladores básicos
- Simulador de dados
- Generador de listas de compras
- Organizador de tareas simple
Recursos para seguir aprendiendo
-
Documentación oficial de Python
- docs.python.org - La fuente más confiable
- Especialmente útil: Tutorial oficial y referencia de la biblioteca estándar
-
Sitios de práctica interactiva
- Ejercicios de programación básica
- Desafíos de lógica
- Proyectos guiados paso a paso
-
Comunidades de programadores
- Foros y grupos de principiantes en Python
- Comunidades locales de programación
- Grupos de estudio virtuales
Un vistazo a tu futuro como programador
Tu progresión natural
Como programador principiante que domina los fundamentos, tu camino natural de crecimiento incluirá:
-
Próximo nivel (Libro 2 de esta serie)
- Manejo de archivos - Leer, escribir y procesar archivos de datos
- Manejo de errores - Crear programas robustos que no se rompen
- Programación orientada a objetos - Crear tus propios tipos de datos
- Trabajo con APIs - Conectar tus programas con servicios web
- Bases de datos - Almacenar y consultar información de manera persistente
-
Nivel intermedio (Libro 3 de esta serie)
- Automatización avanzada - Scripts que pueden ejecutarse automáticamente
- Desarrollo web básico - Crear aplicaciones web simples
- Análisis de datos - Procesar y visualizar información
- Testing y calidad - Escribir pruebas para tu código
- Optimización - Hacer que tus programas corran más rápido
-
Especialización futura
- Desarrollo web - Sitios y aplicaciones web
- Ciencia de datos - Análisis y machine learning
- Automatización - Scripts para empresas y procesos
- Desarrollo de juegos - Entretenimiento interactivo
- Inteligencia artificial - Programas que aprenden
🛣️ Diferentes caminos profesionales
Python te abre las puertas a múltiples campos:
- Automatización de procesos - Hacer que las computadoras hagan trabajo repetitivo
- Análisis de datos - Encontrar patrones e insights en información
- Desarrollo web - Crear sitios y aplicaciones en internet
- Ciencia de datos - Resolver problemas con datos y estadísticas
- DevOps - Administrar sistemas y despliegues automatizados
- Testing de software - Asegurar que los programas funcionen correctamente
Mi perspectiva personal sobre tu futuro
Reflexión del instructor: Has dado el paso más difícil - comenzar. La programación es como aprender un idioma: al principio todo parece extraño, pero una vez que dominas los fundamentos, el resto es construir sobre esa base sólida. Lo que has aprendido en este libro no son solo conceptos de Python, son formas de pensar que te servirán en cualquier lenguaje de programación que decidas aprender después.
Lo más importante que has desarrollado no es solo conocimiento técnico, sino confianza. Ahora sabes que puedes:
- Dividir problemas complejos en pasos simples
- Buscar soluciones cuando no sabes algo
- Experimentar y aprender de los errores
- Construir sobre lo que ya sabes para aprender cosas nuevas
Desafíos para mantener el impulso
Desafío de 30 días
Programa algo pequeño cada día durante 30 días. Puede ser:
- Modificar un ejemplo del libro
- Resolver un problema simple
- Crear una pequeña herramienta útil para ti
Proyecto personal
Identifica una tarea repetitiva en tu vida diaria y trata de automatizarla con Python:
- Organizar archivos en tu computadora
- Calcular gastos mensuales
- Generar reportes simples
- Crear recordatorios automáticos
Comparte tu conocimiento
Enseñar es la mejor forma de aprender:
- Explícale Python a un amigo o familiar
- Escribe sobre lo que aprendiste
- Ayuda a otros principiantes en línea
- Crea tus propios ejemplos y ejercicios
El mensaje final
Has completado un viaje increíble. Comenzaste sin saber nada sobre programación y ahora tienes las herramientas fundamentales para crear programas útiles. Python es solo el comienzo - es tu llave de entrada al mundo infinito de posibilidades que ofrece la programación.
Recuerda siempre:
- La programación es una habilidad práctica - Se mejora haciendo, no solo leyendo
- Los errores son parte del aprendizaje - Cada error te enseña algo nuevo
- La comunidad de programadores es generosa - No tengas miedo de pedir ayuda
- Siempre hay más que aprender - Y eso es lo emocionante de este campo
Tu certificado mental
Declaro que [tu nombre] ha completado exitosamente los fundamentos de programación en Python y está listo para continuar construyendo habilidades increíbles que pueden cambiar su futuro profesional y personal.
¡El mundo de la programación te espera!
Recursos finales
Enlaces útiles
- Documentación oficial de Python: docs.python.org
- Tutorial interactivo: Busca “Python tutorial interactivo” en tu navegador
- Editor recomendado: Visual Studio Code con extensión de Python
- Comunidad Python en español: Busca grupos locales de Python
Próximos libros de esta serie
- Libro 2: “Python Intermedio: Automatización y Proyectos Reales”
- Libro 3: “Python Avanzado: Desarrollo Web y Análisis de Datos”
¡Hasta la próxima aventura de programación!
🧭 Navegación:
- Anterior: Mini Proyecto – Integrando Todo
- Siguiente: Apéndices
Apéndice A: Glosario de Términos
🧭 Navegación:
- Anterior: Siguientes Pasos
- Siguiente: Recursos Adicionales
Este glosario contiene definiciones de los términos técnicos utilizados a lo largo del libro. Está organizado alfabéticamente para facilitar su consulta.
A
Algoritmo
Conjunto de instrucciones o reglas definidas y ordenadas que permite realizar una actividad mediante pasos sucesivos que no generen dudas a quien deba realizar dicha actividad.
Ejemplo: Un algoritmo para calcular el promedio de una lista de números incluiría los pasos para sumar todos los números y dividir por la cantidad de elementos.
API (Application Programming Interface)
Conjunto de reglas y especificaciones que las aplicaciones pueden seguir para comunicarse entre ellas, sirviendo de interfaz entre programas diferentes.
Ejemplo: La API de Twitter permite a los desarrolladores acceder a datos de Twitter desde sus propias aplicaciones.
Argumento
Valor que se pasa a una función cuando es llamada.
Ejemplo: En print("Hola"), "Hola" es un argumento pasado a la función print().
B
Biblioteca (Library)
Conjunto de implementaciones funcionales, codificadas en un lenguaje de programación, que ofrece una interfaz bien definida para la funcionalidad que se invoca.
Ejemplo: La biblioteca estándar de Python incluye módulos como math, os y datetime.
Booleano
Tipo de dato que puede tener dos valores: True (verdadero) o False (falso).
Ejemplo: es_mayor_de_edad = edad >= 18 asigna un valor booleano a la variable.
Bucle (Loop)
Estructura de control que permite ejecutar un bloque de código repetidamente mientras se cumpla una condición.
Ejemplo: Un bucle for que recorre una lista de nombres para saludar a cada persona.
C
Clase
Plantilla para la creación de objetos que define sus propiedades y comportamientos.
Ejemplo: Una clase Coche podría definir propiedades como color y modelo, y métodos como arrancar() y frenar().
Comentario
Texto en el código fuente que es ignorado por el intérprete y sirve para documentar el código.
Ejemplo: # Este es un comentario en Python o """Este es un comentario de múltiples líneas""".
Compilador
Programa que traduce código escrito en un lenguaje de programación a otro lenguaje, generalmente código máquina.
Ejemplo: El compilador de C++ traduce el código fuente a código máquina ejecutable.
Condicional
Estructura de control que permite ejecutar diferentes bloques de código según se cumpla o no una condición.
Ejemplo: Una estructura if-else que muestra diferentes mensajes según la edad del usuario.
D
Depuración (Debugging)
Proceso de identificar y corregir errores en el código.
Ejemplo: Usar print() para mostrar valores de variables en diferentes puntos del código para encontrar dónde ocurre un error.
Diccionario
Estructura de datos que almacena pares clave-valor, donde cada clave es única.
Ejemplo: persona = {"nombre": "Ana", "edad": 25, "ciudad": "Madrid"}.
E
Encapsulamiento
Principio de la programación orientada a objetos que consiste en ocultar los detalles de implementación de un objeto y exponer solo lo necesario.
Ejemplo: Usar métodos getter y setter para acceder a atributos privados de una clase.
Excepción
Evento que ocurre durante la ejecución de un programa que interrumpe el flujo normal de instrucciones.
Ejemplo: Una ZeroDivisionError ocurre cuando se intenta dividir por cero.
Expresión
Combinación de valores, variables y operadores que se evalúa para producir un resultado.
Ejemplo: 2 * (3 + 4) es una expresión que se evalúa a 14.
F
Función
Bloque de código reutilizable que realiza una tarea específica.
Ejemplo: Una función calcular_area_circulo(radio) que devuelve el área de un círculo dado su radio.
H
Herencia
Mecanismo de la programación orientada a objetos que permite que una clase adquiera propiedades y métodos de otra clase.
Ejemplo: Una clase Coche que hereda de una clase Vehiculo.
I
IDE (Integrated Development Environment)
Aplicación que proporciona facilidades integrales para el desarrollo de software, como editor de código, depurador y compilador.
Ejemplo: Visual Studio Code, PyCharm y Jupyter Notebook son IDEs populares para Python.
Indentación
Espacios o tabulaciones al principio de una línea de código que indican la estructura y jerarquía del código.
Ejemplo: En Python, la indentación se usa para definir bloques de código dentro de funciones, bucles y condicionales.
Intérprete
Programa que ejecuta instrucciones escritas en un lenguaje de programación sin necesidad de compilarlas previamente.
Ejemplo: Python utiliza un intérprete para ejecutar código línea por línea.
Iteración
Proceso de repetir un bloque de código múltiples veces.
Ejemplo: Recorrer una lista con un bucle for es un proceso de iteración.
L
Lista
Estructura de datos que almacena una colección ordenada de elementos.
Ejemplo: numeros = [1, 2, 3, 4, 5].
M
Método
Función que está asociada a un objeto o clase.
Ejemplo: El método append() de una lista añade un elemento al final de la lista.
Módulo
Archivo que contiene definiciones y declaraciones de Python que pueden ser importadas para su uso en otros programas.
Ejemplo: El módulo math contiene funciones matemáticas como sqrt() y sin().
O
Objeto
Instancia de una clase que encapsula datos y comportamientos.
Ejemplo: Si Coche es una clase, mi_coche = Coche("rojo", "Toyota") crea un objeto de esa clase.
Operador
Símbolo que realiza operaciones sobre variables y valores.
Ejemplo: +, -, *, /, ==, and, or son operadores en Python.
P
Parámetro
Variable utilizada en la definición de una función para recibir valores cuando la función es llamada.
Ejemplo: En def saludar(nombre):, nombre es un parámetro.
Paquete
Directorio que contiene módulos de Python y un archivo especial __init__.py.
Ejemplo: NumPy y Pandas son paquetes populares de Python para análisis de datos.
PEP 8
Guía de estilo para el código Python que proporciona convenciones para escribir código legible.
Ejemplo: Según PEP 8, las líneas de código no deberían exceder los 79 caracteres.
Polimorfismo
Capacidad de diferentes clases de responder al mismo método de diferentes maneras.
Ejemplo: Diferentes clases que implementan un método hablar() pero producen sonidos diferentes.
R
Recursión
Técnica de programación donde una función se llama a sí misma.
Ejemplo: Una función factorial que se llama a sí misma con valores decrecientes.
Refactorización
Proceso de reestructurar el código existente sin cambiar su comportamiento externo.
Ejemplo: Extraer código repetido a una función para mejorar la mantenibilidad.
S
Script
Programa escrito en un lenguaje interpretado como Python, generalmente contenido en un solo archivo.
Ejemplo: Un archivo automatizar_backup.py que realiza copias de seguridad automáticas.
String (Cadena de texto)
Secuencia de caracteres.
Ejemplo: "Hola, mundo!" es una cadena de texto.
T
Tupla
Estructura de datos similar a una lista pero inmutable (no se puede modificar después de su creación).
Ejemplo: coordenadas = (10, 20).
Tipo de dato
Clasificación que determina qué valores puede tener una variable y qué operaciones se pueden realizar con ella.
Ejemplo: Enteros, flotantes, cadenas, booleanos, listas, diccionarios son tipos de datos en Python.
V
Variable
Nombre que se refiere a un valor almacenado en la memoria del ordenador.
Ejemplo: edad = 25 asigna el valor 25 a la variable edad.
Virtual Environment (Entorno Virtual)
Herramienta que ayuda a mantener las dependencias requeridas por diferentes proyectos en entornos aislados.
Ejemplo: Crear un entorno virtual con venv para instalar paquetes específicos para un proyecto sin afectar a otros proyectos.
Apéndice B: Recursos Adicionales
¡Felicidades por llegar hasta aquí! Has dado los primeros pasos sólidos en tu viaje como programador Python. Ahora es momento de expandir tus horizontes y descubrir el vasto ecosistema que te espera.
Documentación Oficial y Fundamental
Python.org - La fuente oficial
- URL: https://www.python.org/
- ¿Qué encontrarás?: Documentación oficial, tutoriales, y noticias sobre Python
- Por qué es importante: Es la referencia autoritativa para todo lo relacionado con Python
- Consejo: Marca la sección “Python Tutorial” como favorita
Python Documentation
- URL: https://docs.python.org/3/
- ¿Qué encontrarás?: Documentación completa de la biblioteca estándar
- Por qué es importante: Cuando necesites detalles específicos sobre funciones y módulos
- Consejo: Usa la función de búsqueda para encontrar rápidamente lo que necesitas
PEP 8 - Style Guide for Python Code
- URL: https://pep8.org/
- ¿Qué encontrarás?: Las convenciones oficiales de estilo para escribir código Python
- Por qué es importante: Te ayudará a escribir código que otros programadores puedan leer fácilmente
- Consejo: No necesitas memorizarlo todo, pero consulta cuando tengas dudas sobre formato
Plataformas de Aprendizaje Interactivo
Codecademy Python Course
- URL: https://www.codecademy.com/learn/learn-python-3
- Tipo: Curso interactivo gratuito/premium
- Nivel: Principiante a intermedio
- Fortaleza: Ejercicios prácticos paso a paso
- Ideal para: Reforzar conceptos con práctica dirigida
Python Challenge
- URL: http://www.pythonchallenge.com/
- Tipo: Acertijos de programación
- Nivel: Intermedio a avanzado
- Fortaleza: Problemas creativos que te hacen pensar fuera de la caja
- Ideal para: Cuando quieras desafiarte con puzzles divertidos
LeetCode
- URL: https://leetcode.com/
- Tipo: Plataforma de práctica de algoritmos
- Nivel: Todos los niveles
- Fortaleza: Preparación para entrevistas técnicas
- Ideal para: Mejorar habilidades de resolución de problemas
HackerRank
- URL: https://www.hackerrank.com/domains/python
- Tipo: Desafíos de programación
- Nivel: Principiante a experto
- Fortaleza: Categorías específicas de Python con certificaciones
- Ideal para: Practicar temas específicos y obtener reconocimientos
Canales de YouTube en Español
Canales Recomendados para Python
MoureDev by Brais Moure
- URL: https://www.youtube.com/@mouredev
- Especialidad: Programación general y Python
- Estilo: Tutoriales claros y proyectos prácticos
- Ideal para: Seguir aprendiendo con proyectos reales
Dot CSV
- URL: https://www.youtube.com/@DotCSV
- Especialidad: Machine Learning y Data Science con Python
- Estilo: Explicaciones accesibles de temas complejos
- Ideal para: Cuando quieras explorar inteligencia artificial
Fazt
- URL: https://www.youtube.com/@FaztTech
- Especialidad: Desarrollo web y programación en general
- Estilo: Tutoriales step-by-step
- Ideal para: Aprender desarrollo web con Python
Libros Recomendados
Para Consolidar Fundamentos
“Python Crash Course” - Eric Matthes
- Nivel: Principiante
- Fortaleza: Excelente para solidificar conceptos básicos
- Incluye: Proyectos prácticos como juegos y aplicaciones web
- Disponible en: Inglés (con traducciones parciales)
“Automate the Boring Stuff with Python” - Al Sweigart
- Nivel: Principiante
- Fortaleza: Enfocado en automatización práctica
- Incluye: Scripts útiles para tareas del día a día
- Disponible: Gratis en línea en https://automatetheboringstuff.com/
Para Nivel Intermedio
“Effective Python” - Brett Slatkin
- Nivel: Intermedio
- Fortaleza: 90 mejores prácticas para escribir mejor código Python
- Ideal para: Cuando ya domines lo básico y quieras profesionalizarte
“Python Tricks” - Dan Bader
- Nivel: Intermedio
- Fortaleza: Consejos y trucos para escribir código más elegante
- Ideal para: Aprender patrones avanzados de Python
Frameworks y Librerías Esenciales
Desarrollo Web
Django
- URL: https://www.djangoproject.com/
- Qué es: Framework web completo para aplicaciones robustas
- Ideal para: Proyectos web grandes y complejos
- Aprende si: Quieres crear sitios web profesionales
Flask
- URL: https://flask.palletsprojects.com/
- Qué es: Microframework web ligero y flexible
- Ideal para: Proyectos web pequeños y APIs
- Aprende si: Prefieres simplicidad y control total
FastAPI
- URL: https://fastapi.tiangolo.com/
- Qué es: Framework moderno para crear APIs rápidas
- Ideal para: APIs modernas con documentación automática
- Aprende si: Quieres crear servicios web de última generación
Data Science y Análisis
Pandas
- URL: https://pandas.pydata.org/
- Qué es: Biblioteca para manipulación y análisis de datos
- Ideal para: Trabajar con tablas y datasets
- Aprende si: Te interesa el análisis de datos
NumPy
- URL: https://numpy.org/
- Qué es: Biblioteca para cómputo numérico
- Ideal para: Operaciones matemáticas complejas
- Aprende si: Quieres trabajar con matrices y arrays
Matplotlib / Seaborn
- URLs: https://matplotlib.org/ | https://seaborn.pydata.org/
- Qué son: Bibliotecas para crear gráficos y visualizaciones
- Ideal para: Crear gráficos y dashboards
- Aprende si: Quieres visualizar datos de manera profesional
🤖 Machine Learning e IA
Scikit-learn
- URL: https://scikit-learn.org/
- Qué es: Biblioteca de machine learning
- Ideal para: Algoritmos de ML tradicionales
- Aprende si: Quieres iniciarte en inteligencia artificial
TensorFlow / PyTorch
- URLs: https://www.tensorflow.org/ | https://pytorch.org/
- Qué son: Frameworks para deep learning
- Ideal para: Redes neuronales y AI avanzada
- Aprende si: Quieres especializarte en deep learning
🛠️ Herramientas de Desarrollo
Editores y IDEs Recomendados
Visual Studio Code
- URL: https://code.visualstudio.com/
- Tipo: Editor gratuito
- Fortalezas: Extensiones, debugging, Git integrado
- Extensiones clave: Python, Pylance, Python Docstring Generator
PyCharm
- URL: https://www.jetbrains.com/pycharm/
- Tipo: IDE especializado (versión gratuita disponible)
- Fortalezas: Refactoring avanzado, debugging potente
- Ideal para: Proyectos grandes y desarrollo profesional
Jupyter Notebook
- URL: https://jupyter.org/
- Tipo: Entorno interactivo
- Fortalezas: Ideal para experimentación y data science
- Ideal para: Análisis de datos y prototipado rápido
Control de Versiones
Git y GitHub
- URLs: https://git-scm.com/ | https://github.com/
- Qué son: Sistema de control de versiones y plataforma de código
- Por qué son esenciales: Todo programador profesional debe conocerlos
- Aprende: Comandos básicos de Git y cómo usar GitHub
Comunidades y Foros
Comunidades en Español
Python España
- URL: https://www.python-spain.es/
- Qué es: Asociación oficial de Python en España
- Incluye: Eventos, meetups, conferencias
- Ideal para: Conectar con la comunidad local
Discord de programación en español
- Busca servidores como “Programadores”, “Python en Español”
- Ideal para: Chat en tiempo real y ayuda rápida
Comunidades Internacionales
Stack Overflow
- URL: https://stackoverflow.com/questions/tagged/python
- Qué es: Plataforma de preguntas y respuestas
- Cómo usar: Busca antes de preguntar, se específico en tus dudas
- Consejos: Lee las guías para hacer buenas preguntas
Reddit - r/Python
- URL: https://www.reddit.com/r/Python/
- Qué es: Comunidad activa de desarrolladores Python
- Incluye: Noticias, proyectos, discusiones
- Ideal para: Mantenerte al día con tendencias
Real Python
- URL: https://realpython.com/
- Qué es: Plataforma de tutoriales y artículos
- Fortaleza: Contenido de alta calidad para todos los niveles
- Ideal para: Aprendizaje estructurado y proyectos prácticos
Recursos Gratuitos Especiales
Cursos Universitarios Gratuitos
MIT OpenCourseWare
- URL: https://ocw.mit.edu/
- Buscar: “Introduction to Computer Science and Programming in Python”
- Nivel: Universitario
- Incluye: Videos, ejercicios, exámenes
Harvard CS50
- URL: https://cs50.harvard.edu/python/
- Qué es: Curso introductorio de Harvard
- Fortaleza: Producción profesional y ejercicios desafiantes
- Disponible: Completamente gratis en línea
Bibliotecas de Código
GitHub Awesome Python
- URL: https://github.com/vinta/awesome-python
- Qué es: Lista curada de librerías y recursos Python
- Ideal para: Descubrir nuevas herramientas y librerías
Python Package Index (PyPI)
- URL: https://pypi.org/
- Qué es: Repositorio oficial de paquetes Python
- Cómo usar:
pip install nombre_paquete - Consejos: Lee la documentación antes de instalar
Plan de Continuación Sugerido
Primeras 4 Semanas
- Semana 1-2: Refuerza conceptos con ejercicios de HackerRank
- Semana 3: Comienza un proyecto personal pequeño
- Semana 4: Aprende Git y sube tu proyecto a GitHub
Siguientes 2 Meses
- Mes 1: Elige una especialización (web, data science, automatización)
- Mes 2: Aprende un framework relacionado (Django/Flask, Pandas, etc.)
A Largo Plazo (6 meses+)
- Contribuye a proyectos open source
- Participa en comunidades locales
- Considera certificaciones profesionales
- Busca oportunidades de prácticas o trabajo
Oportunidades Profesionales
Roles que puedes aspirar con Python
- Desarrollador Backend: Crear APIs y servicios web
- Data Analyst/Scientist: Análisis de datos e insights de negocio
- DevOps Engineer: Automatización de infraestructura
- QA Automation Engineer: Automatización de pruebas
- Machine Learning Engineer: Implementar modelos de IA
- Full-Stack Developer: Desarrollo web completo
Sectores con alta demanda
- Fintech: Tecnología financiera
- HealthTech: Tecnología médica
- E-commerce: Comercio electrónico
- EdTech: Tecnología educativa
- Consulting: Consultoría tecnológica
Mensaje Final
¡Felicidades por completar este viaje! Has adquirido las bases sólidas para convertirte en un programador Python competente.
🛤️ Recuerda: La programación es una habilidad que se desarrolla con la práctica constante. No te desanimes si algunos conceptos toman tiempo en asentarse – es completamente normal.
Tu próximo paso: Elige UN recurso de esta lista y comienza mañana. La consistencia es más importante que la intensidad.
¡Éxito en tu carrera como programador!
Consejo del autor: No intentes aprender todo a la vez. Elige una especialización, masónala, y luego expande. La profundidad es más valiosa que la amplitud cuando estás comenzando.
Apéndice C: Soluciones a Ejercicios
Este apéndice contiene las soluciones completas y comentadas a los ejercicios presentados a lo largo del libro. Cada solución incluye no solo el código, sino también explicaciones detalladas del razonamiento detrás de cada decisión.
Consejo importante: Intenta resolver los ejercicios por tu cuenta antes de consultar estas soluciones. El aprendizaje real ocurre cuando luchas con los problemas y encuentras tus propias soluciones.
Capítulo 4: Variables y Tipos de Datos
Ejercicio 1: Creando tu almacén personal
Solución completa:
# ================================
# MI ALMACÉN PERSONAL - SOLUCIÓN COMPLETA
# ================================
# Información básica
nombre = "María González"
edad = 28
altura = 1.68 # metros
te_gusta_programar = True
# Variables adicionales (ejemplos creativos)
ciudad_origen = "Guadalajara"
color_favorito = "azul"
num_hermanos = 2
tiene_mascota = True
nombre_mascota = "Luna"
salario_deseado = 45000.0
# Mostrar información usando f-strings
print("=== MI INFORMACIÓN PERSONAL ===")
print(f"Nombre: {nombre}")
print(f"Edad: {edad} años")
print(f"Altura: {altura} metros")
print(f"¿Me gusta programar?: {'Sí' if te_gusta_programar else 'No'}")
print(f"Ciudad de origen: {ciudad_origen}")
print(f"Color favorito: {color_favorito}")
print(f"Número de hermanos: {num_hermanos}")
print(f"¿Tengo mascota?: {'Sí' if tiene_mascota else 'No'}")
if tiene_mascota:
print(f"Nombre de mi mascota: {nombre_mascota}")
print(f"Salario deseado: ${salario_deseado:,.2f}")
# Realizar cálculos
print("\n=== CÁLCULOS ===")
# Cálculo 1: Edad en meses
edad_en_meses = edad * 12
print(f"Mi edad en meses: {edad_en_meses} meses")
# Cálculo 2: Altura en centímetros
altura_en_cm = altura * 100
print(f"Mi altura en centímetros: {altura_en_cm:.1f} cm")
# Cálculo 3: Años hasta jubilación (asumiendo jubilación a los 65)
edad_jubilacion = 65
anos_hasta_jubilacion = edad_jubilacion - edad
print(f"Años hasta jubilación: {anos_hasta_jubilacion} años")
# Cálculo 4: Salario anual vs mensual
salario_mensual = salario_deseado / 12
print(f"Salario mensual deseado: ${salario_mensual:.2f}")
# Mostrar tipos de variables
print("\n=== TIPOS DE VARIABLES ===")
print(f'Variable "nombre" es de tipo: {type(nombre).__name__}')
print(f'Variable "edad" es de tipo: {type(edad).__name__}')
print(f'Variable "altura" es de tipo: {type(altura).__name__}')
print(f'Variable "te_gusta_programar" es de tipo: {type(te_gusta_programar).__name__}')
print(f'Variable "ciudad_origen" es de tipo: {type(ciudad_origen).__name__}')
print(f'Variable "num_hermanos" es de tipo: {type(num_hermanos).__name__}')
print(f'Variable "salario_deseado" es de tipo: {type(salario_deseado).__name__}')
Explicación de la solución:
- Variables diversas: Incluí variables de diferentes tipos para demostrar la versatilidad
- F-strings avanzados: Uso condicionales dentro de f-strings para mostrar texto dinámico
- Cálculos variados: Incluyo operaciones que son útiles en la vida real
- Formateo de números: Uso
:,.2fpara formatear el salario con comas y 2 decimales - Uso de
__name__: Para mostrar nombres de tipo más limpios
Ejercicio 2: Calculadora de IMC
Solución completa:
# ================================
# CALCULADORA DE IMC - SOLUCIÓN COMPLETA
# ================================
# Datos de la persona
nombre = "Carlos Mendoza"
peso = 75.5 # en kilogramos
altura = 1.78 # en metros
# Cálculo del IMC
imc = peso / (altura ** 2)
# Determinación de la categoría con lógica detallada
if imc < 18.5:
categoria = "Bajo peso"
recomendacion = "Considera consultar a un nutricionista para un plan de alimentación saludable."
emoji = "🟡"
elif imc < 25:
categoria = "Peso normal"
recomendacion = "¡Excelente! Mantén tus hábitos saludables de alimentación y ejercicio."
emoji = "🟢"
elif imc < 30:
categoria = "Sobrepeso"
recomendacion = "Considera incorporar más ejercicio y revisar tu alimentación."
emoji = "🟠"
else:
categoria = "Obesidad"
recomendacion = "Te recomendamos consultar con un profesional de la salud."
emoji = "<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><circle fill="#DD2E44" cx="18" cy="18" r="18"/></svg>"
# Cálculos adicionales
peso_ideal_min = 18.5 * (altura ** 2)
peso_ideal_max = 24.9 * (altura ** 2)
# Mostrar informe completo
print("=== INFORME COMPLETO DE IMC ===")
print(f"Nombre: {nombre}")
print(f"Peso: {peso} kg")
print(f"Altura: {altura} m")
print(f"IMC calculado: {imc:.2f}")
print(f"Categoría: {emoji} {categoria}")
print(f"\nRango de peso ideal para tu altura:")
print(f" Mínimo: {peso_ideal_min:.1f} kg")
print(f" Máximo: {peso_ideal_max:.1f} kg")
# Análisis personalizado
if peso < peso_ideal_min:
diferencia = peso_ideal_min - peso
print(f"\nPara alcanzar el peso mínimo ideal, necesitarías ganar {diferencia:.1f} kg")
elif peso > peso_ideal_max:
diferencia = peso - peso_ideal_max
print(f"\nPara alcanzar el peso máximo ideal, necesitarías perder {diferencia:.1f} kg")
else:
print(f"\n¡Tu peso está dentro del rango ideal!")
print(f"\nRecomendación: {recomendacion}")
# Información educativa adicional
print("\n=== INFORMACIÓN EDUCATIVA ===")
print("Rangos de IMC:")
print(" < 18.5: Bajo peso")
print(" 18.5 - 24.9: Peso normal")
print(" 25.0 - 29.9: Sobrepeso")
print(" ≥ 30.0: Obesidad")
print("\nNota: El IMC es una herramienta de orientación. Consulta siempre")
print("con profesionales de la salud para evaluaciones completas.")
Explicación de la solución:
- Lógica extendida: Además de calcular el IMC, incluyo recomendaciones personalizadas
- Cálculos adicionales: Determino el rango de peso ideal para la altura
- Feedback personalizado: El programa da consejos específicos según el resultado
- Emojis para claridad: Uso colores emoji para visualizar rápidamente el estado
- Información educativa: Incluyo los rangos para que el usuario aprenda
Ejercicio 3: Conversor de unidades
Solución completa:
# ================================
# CONVERSOR DE UNIDADES - SOLUCIÓN COMPLETA
# ================================
# Distancia en kilómetros
distancia_km = 42.195 # Distancia de un maratón
# Factores de conversión (constantes)
KM_A_METROS = 1000
KM_A_CM = 100000
KM_A_MILLAS = 0.621371
KM_A_PIES = 3280.84
KM_A_YARDAS = 1093.61
KM_A_PULGADAS = 39370.1
# Realizar todas las conversiones
metros = distancia_km * KM_A_METROS
centimetros = distancia_km * KM_A_CM
millas = distancia_km * KM_A_MILLAS
pies = distancia_km * KM_A_PIES
yardas = distancia_km * KM_A_YARDAS
pulgadas = distancia_km * KM_A_PULGADAS
# Mostrar resultados con formato elegante
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#FFDC5D" d="M15.087 24.856l-1.728-3.593c-.428.233-2.257 1.253-3.35 2.237-.635.572-.549 1.002-.36 1.944l.017.085c.189.952 2.205 7.351 2.47 8.187l1.345-.334c.011-.446-.04-2.803-.272-4.27-.073-.463-.147-1.025-.214-1.522-.071-.543-.263-1.087-.309-1.323-.064-.334.13-.493.433-.64.862-.417 1.715-.66 1.968-.771zm8.793 1.905c-.546-.067-1.107-.08-1.346-.095-.339-.021-.577-.253-.643-.584-.188-.939-.225-1.767-.268-2.039l-3.912.767c.118.473.644 2.5 1.322 3.806.393.757.831.782 1.79.838l.087.005c.975.057 7.669-.284 8.545-.329l.015-1.385c-.43-.124-2.59-.664-4.069-.808-.464-.045-1.025-.115-1.521-.176z"/><path fill="#8899A6" d="M27.805 29.682l-.178-.328c-.022-.053.004-.113.058-.132.171-.059.518-.217.639-.281-.105.24-.225.624-.359.74-.052.043-.134.063-.16.001z"/><path fill="#DD551F" d="M30.398 27.138c-.139-.111-.457-.166-.657-.185-.138-.013-.498-.024-.799-.008-.136.008-.291.024-.355.043-.198.057-.285.141-.332.198-.057.069-.062.144-.049.181.052.153.304.418.414.67.037.084.058.166.05.243-.027.276-.379.678-.643.976-.158.179-.285.32-.29.375-.006.059.011.109.037.158v.002c.072.132.229.269.337.629.069.232.395 1.291.395 1.291.078.27.182.336.226.481.091.297.251 1.094.331 1.346.08.252.271.36.418.381s.232-.014.232-.014.345-.155.574-1.449c.165-.935.019-1.079-.105-2.483s.216-2.835.216-2.835z"/><path fill="#FA743E" d="M30.109 29.226c-.235-.096-.771-.45-.922-.831-.136-.344-.229-1.273-.246-1.449.288-.026.731-.007.873.007.188.018.404.033.534.143l.05.043c0-.001-.229 1.473-.289 2.087z"/><path fill="#CCD6DD" d="M28.048 30.27c-.073 0-.142-.041-.175-.111-.046-.097-.005-.213.092-.258l.342-.162c.097-.046.212-.005.259.092.046.097.005.213-.092.258l-.342.162c-.028.013-.056.019-.084.019zm.218.625c-.082 0-.158-.053-.185-.135-.032-.102.024-.211.126-.244l.38-.121c.097-.033.21.023.243.126.032.102-.024.211-.126.244l-.38.121c-.018.007-.038.009-.058.009zm.184.637c-.091 0-.171-.063-.19-.155-.021-.105.046-.207.152-.229l.356-.072c.111-.023.207.047.229.152.021.105-.046.207-.152.229l-.356.072-.039.003zm2.776-4.13c-.006-.028-.027-.137-.101-.27-.025-.045-.082-.059-.14-.066-.072-.009-.6-.085-.61.022 0 0-.003.159-.077.268-.075.109-.127.377-.146.577-.019.199-.105.951-.085 1.478.02.528.183 1.482.19 1.8.008.318 0 .814-.068 1.18s-.14.692-.196.893c-.072.259-.168.471-.279.619 0 0 .417-.028.736-.645.252-.487.393-.955.446-1.411.004-.035.113-1.252.165-1.86.038-.445.102-1.155.102-1.155.081-.841.1-1.269.063-1.43z"/><path fill="#8899A6" d="M11.211 32.283l.269-.259c.045-.036.11-.027.143.021.102.149.348.441.441.541-.26-.037-.661-.051-.809-.149-.056-.038-.096-.112-.044-.154z"/><path fill="#DD551F" d="M14.355 34.104c.07-.163.038-.485.003-.683-.024-.136-.109-.486-.206-.772-.043-.129-.101-.274-.136-.33-.108-.176-.212-.237-.28-.267-.082-.036-.155-.022-.188.001-.134.091-.322.405-.535.578-.071.058-.144.1-.22.113-.273.048-.755-.184-1.112-.359-.214-.105-.385-.189-.438-.18-.059.01-.102.039-.143.078l-.002.001h.001c-.108.104-.199.293-.516.492-.206.128-1.14.724-1.14.724-.24.147-.275.265-.403.346-.262.167-.987.534-1.209.678-.222.144-.275.357-.255.505.02.148.076.22.076.22s.242.291 1.549.166c.945-.09 1.045-.269 2.365-.763 1.32-.493 2.789-.548 2.789-.548z"/><path fill="#FA743E" d="M12.266 34.382c.03-.252.228-.863.555-1.11.295-.222 1.166-.56 1.331-.624.102.271.202.703.226.843.033.186.076.398.004.553l-.028.059c.001.001-1.481.173-2.088.279z"/><path fill="#CCD6DD" d="M11.144 33.103c-.054 0-.109-.023-.147-.067l-.247-.287c-.07-.081-.061-.204.02-.274.081-.07.205-.061.274.02l.247.287c.07.081.061.204-.02.274-.038.032-.083.047-.127.047zm-.575.425c-.063 0-.125-.031-.163-.088l-.218-.334c-.058-.09-.033-.21.057-.269.09-.058.209-.034.269.056l.218.334c.058.09.033.21-.057.269-.033.022-.069.032-.106.032zm-.617.337c-.07 0-.138-.039-.173-.106l-.165-.324c-.048-.095-.01-.212.085-.261.095-.049.211-.011.261.085l.165.324c.048.096.01.212-.085.261-.028.015-.059.021-.088.021zm4.369 1.108c.026-.014.125-.062.234-.17.036-.036.035-.095.026-.153-.01-.072-.078-.601-.184-.582 0 0-.154.04-.279-.003-.125-.043-.398-.021-.595.013-.197.035-.944.152-1.447.312-.503.16-1.379.571-1.684.664-.305.092-.784.217-1.156.249-.371.032-.705.05-.913.049-.269 0-.498-.036-.671-.103 0 0 .138.394.818.537.537.113 1.025.124 1.479.053.034-.005 1.237-.225 1.836-.337.439-.082 1.14-.21 1.14-.21.833-.146 1.25-.241 1.396-.319z"/><path fill="#C63900" d="M12.654 21.244c.751-.398 3.235-1.653 4.947-1.804.156-.014.298.088.352.235l1.328 3.635c.068.186-.027.391-.216.451-.781.25-2.74.915-4.22 1.719-.157.085-.347.041-.448-.106-.456-.664-1.642-2.477-1.923-3.76-.032-.15.045-.298.18-.37z"/><path fill="#DD551F" d="M17.514 25.488c-.196-.827-.785-3.547-.501-5.242.026-.155.16-.266.316-.281l3.853-.37c.198-.019.371.125.382.323.046.818.196 2.882.601 4.517.043.173-.048.346-.216.407-.758.274-2.811.965-4.123.914-.153-.007-.276-.118-.312-.268z"/><path fill="#FFDC5D" d="M15.015 10.618c-.085.612.05 1.546 1.466 1.787 1.416.241 2.812.059 3.411-.108.599-.167.569.884.747 1.872.179.992.301 1.768.252 1.973-.082.347-.809 1.011-.517 1.612s.757 1.179 1.332.962c.575-.217 1.05-.475 1.203-.797s-.525-1.295-.552-1.574c-.027-.278.227-3.888.194-4.298-.04-.501-.078-1.187-.896-1.47-.818-.284-4.094-.92-4.915-1.079-.942-.185-1.612.309-1.725 1.12zM13.826.971C11.981.781 9.725 2.34 9.867 4.376c.198 2.841 2.368 4.687 4.011 4.031 1.723-.688 2.703-1.387 2.911-3.417.21-2.03-1.117-3.829-2.963-4.019z"/><path fill="#FFDC5D" d="M16.449 5.593c1.625-3.518-4.125-1.612-4.125-1.612-1.092.348.181 1.974-.058 3.122-.162.794 1.439.743 1.439.743s.685-.202.955.622l.002.008c.068.21.116.469.111.834-.027 1.808 2.503 2.205 2.528.394.01-.717-.229-1.278-.478-1.788l-.022-.045c-.372-.76-.753-1.408-.352-2.278z"/><path fill="#FFAC33" d="M16.079.962c-1.13-.88-4.156-1.091-5.51.802-1.269.129-1.411 1.408-1.123 2.041.23.506 1.567.279 2.173 1.192.156-.315.072-.847-.054-1.109.525.283.637 1.379 2.455 1.608 1.757.221 1.867 1.688 1.867 1.688s.719-.623 1.109-1.451c.745-1.582.329-3.8-.917-4.771z"/><path fill="#FA743E" d="M19.459 10.057c-.77-1.644-2.017-2.56-3.384-1.957-1.809.799-2.443 2.756-2.332 4.652.122 2.065 1.556 3.924 1.551 7.601 0 0 3.109.449 6.316.36 0 0-.298-6.699-2.151-10.656z"/><path fill="#FFDC5D" d="M16.94 10.268c-.577-.345-1.462-.572-2.304.745s-1.187 2.756-1.447 3.433c-.243.632-1.127.196-2.194-.045-1.07-.242-2.429-.654-2.614-.79-.313-.229-.199-.874-.925-.837s-1.083-.047-1.11.622c-.026.669-.035 1.339.222 1.629.258.29 1.127.04 1.516.177.287.101 3.803 1.876 4.228 2.017.519.172 1.223.425 1.854-.275s2.658-3.714 3.167-4.47c.584-.867.373-1.748-.393-2.206z"/></svg> ========================================")
print(" CONVERSOR DE DISTANCIAS")
print(" (Distancia de un Maratón)")
print("========================================")
print(f"Distancia original: {distancia_km} kilómetros")
print("\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#FFCC4D" d="M30.021 34.264c-1.563 1.563-4.095 1.562-5.656 0L1.736 11.636c-1.562-1.562-1.563-4.094 0-5.657l4.243-4.242c1.562-1.562 4.095-1.562 5.657 0l22.626 22.628c1.562 1.562 1.562 4.096.001 5.656l-4.242 4.243z"/><path fill="#292F33" d="M9.515 6.687c-.391.39-1.023.39-1.414 0-.39-.391-.39-1.024 0-1.415l3.536-3.536 1.414 1.415-3.536 3.536zm5.656 1.414c-.39.391-1.024.391-1.414 0-.391-.391-.391-1.024 0-1.414l1.415-1.415 1.414 1.415-1.415 1.414zm1.415 5.656c-.391.391-1.024.391-1.414 0-.39-.391-.39-1.024 0-1.414l3.536-3.536c.486.486.929.928 1.414 1.415l-3.536 3.535zm5.656 1.414c-.39.391-1.023.391-1.413 0-.392-.391-.391-1.024 0-1.414l1.414-1.415c.485.487.928.928 1.414 1.415l-1.415 1.414zm1.415 5.657c-.391.391-1.023.392-1.414 0-.391-.391-.391-1.023-.001-1.414l3.536-3.535 1.414 1.414-3.535 3.535zm7.071 7.071c-.39.391-1.023.391-1.413 0-.392-.391-.392-1.023-.001-1.414l3.536-3.535 1.414 1.414-3.536 3.535zm-1.415-5.657c-.391.391-1.022.391-1.414.001-.391-.391-.39-1.024 0-1.414l1.415-1.414 1.413 1.413-1.414 1.414z"/></svg> EQUIVALENCIAS:")
print(f" En metros: {metros:>12,.2f} m")
print(f" En centímetros: {centimetros:>12,.0f} cm")
print(f" En millas: {millas:>12,.2f} mi")
print(f" En pies: {pies:>12,.2f} ft")
print(f" En yardas: {yardas:>12,.2f} yd")
print(f" En pulgadas: {pulgadas:>12,.0f} in")
# Comparaciones interesantes
print("\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><circle fill="#DD2E44" cx="18" cy="18" r="18"/><circle fill="#FFF" cx="18" cy="18" r="13.5"/><circle fill="#DD2E44" cx="18" cy="18" r="10"/><circle fill="#FFF" cx="18" cy="18" r="6"/><circle fill="#DD2E44" cx="18" cy="18" r="3"/><path opacity=".2" d="M18.24 18.282l13.144 11.754s-2.647 3.376-7.89 5.109L17.579 18.42l.661-.138z"/><path fill="#FFAC33" d="M18.294 19c-.255 0-.509-.097-.704-.292-.389-.389-.389-1.018 0-1.407l.563-.563c.389-.389 1.018-.389 1.408 0 .388.389.388 1.018 0 1.407l-.564.563c-.194.195-.448.292-.703.292z"/><path fill="#55ACEE" d="M24.016 6.981c-.403 2.079 0 4.691 0 4.691l7.054-7.388c.291-1.454-.528-3.932-1.718-4.238-1.19-.306-4.079.803-5.336 6.935zm5.003 5.003c-2.079.403-4.691 0-4.691 0l7.388-7.054c1.454-.291 3.932.528 4.238 1.718.306 1.19-.803 4.079-6.935 5.336z"/><path fill="#3A87C2" d="M32.798 4.485L21.176 17.587c-.362.362-1.673.882-2.51.046-.836-.836-.419-2.08-.057-2.443L31.815 3.501s.676-.635 1.159-.152-.176 1.136-.176 1.136z"/></svg> COMPARACIONES INTERESANTES:")
print(f" Un maratón equivale a correr {pies/5280:.1f} millas")
print(f" O caminar aproximadamente {int(metros/0.75)} pasos (75cm por paso)")
print(f" Es como {centimetros/30.48:.0f} reglas de 30cm puestas en fila")
# Función reutilizable
def convertir_distancia(km, unidad="todas"):
"""Convierte kilómetros a diferentes unidades"""
conversiones = {
"metros": km * 1000,
"centimetros": km * 100000,
"millas": km * 0.621371,
"pies": km * 3280.84,
"yardas": km * 1093.61,
"pulgadas": km * 39370.1
}
if unidad == "todas":
return conversiones
else:
return conversiones.get(unidad, "Unidad no reconocida")
# Ejemplo de uso de la función
print("\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#8899A6" d="M27.989 19.977c-.622 0-1.225.078-1.806.213L15.811 9.818c.134-.581.212-1.184.212-1.806C16.023 3.587 12.436 0 8.012 0 7.11 0 5.91.916 6.909 1.915l2.997 2.997s.999 1.998-.999 3.995-3.996.998-3.996.998L1.915 6.909C.916 5.91 0 7.105 0 8.012c0 4.425 3.587 8.012 8.012 8.012.622 0 1.225-.078 1.806-.212l10.371 10.371c-.135.581-.213 1.184-.213 1.806 0 4.425 3.588 8.011 8.012 8.011.901 0 2.101-.916 1.102-1.915l-2.997-2.997s-.999-1.998.999-3.995 3.995-.999 3.995-.999l2.997 2.997c1 .999 1.916-.196 1.916-1.102 0-4.425-3.587-8.012-8.011-8.012z"/></svg> EJEMPLO DE FUNCIÓN REUTILIZABLE:")
distancia_test = 5.0
resultado = convertir_distancia(distancia_test, "millas")
print(f"{distancia_test} km = {resultado:.2f} millas")
Explicación de la solución:
- Constantes con nombres claros: Uso variables en mayúsculas para las constantes
- Formateo avanzado: Uso
>12,.2fpara alinear números a la derecha con comas - Contexto real: Uso la distancia de un maratón para hacer el ejemplo más interesante
- Comparaciones útiles: Añado equivalencias que ayudan a visualizar la distancia
- Función reutilizable: Creo una función que se puede usar en otros proyectos
🗗️ Capítulo 5: Operadores Matemáticos
Ejercicio 1: Calculadora de nómina
Solución completa:
# ================================
# CALCULADORA DE NÓMINA - SOLUCIÓN COMPLETA
# ================================
# Datos del empleado
nombre_empleado = "Ana Martínez"
salario_base = 15000 # pesos mensuales
horas_extra = 10 # horas trabajadas extra
pago_por_hora_extra = 150 # pesos por hora extra
bono_productividad = 2000 # pesos
bono_puntualidad = 500 # pesos adicional
# Deducciones (porcentajes)
impuesto_renta = 0.10 # 10%
seguro_social = 0.0625 # 6.25%
seguro_medico = 500 # pesos fijos
fondo_pension = 0.04 # 4%
# CÁLCULOS DE INGRESOS
# Calcular pago por horas extra
pago_extra = horas_extra * pago_por_hora_extra
# Calcular ingresos brutos
ingresos_brutos = salario_base + pago_extra + bono_productividad + bono_puntualidad
# CÁLCULOS DE DEDUCCIONES
# Deducciones porcentuales (se calculan sobre salario base + extras)
base_para_porcentajes = salario_base + pago_extra
deduccion_impuesto = base_para_porcentajes * impuesto_renta
deduccion_seguro_social = base_para_porcentajes * seguro_social
deduccion_pension = base_para_porcentajes * fondo_pension
# Total de deducciones
total_deducciones = (deduccion_impuesto + deduccion_seguro_social +
seguro_medico + deduccion_pension)
# Salario neto
salario_neto = ingresos_brutos - total_deducciones
# GENERAR RECIBO DE NÓMINA
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#FDD888" d="M31.898 23.938C31.3 17.32 28 14 28 14l-6-8h-8l-6 8s-1.419 1.433-2.567 4.275C3.444 18.935 2 20.789 2 23c0 1.448.625 2.742 1.609 3.655C3.233 27.357 3 28.147 3 29c0 1.958 1.136 3.636 2.775 4.456C7.058 35.378 8.772 36 10 36h16c1.379 0 3.373-.779 4.678-3.31C32.609 31.999 34 30.17 34 28c0-1.678-.834-3.154-2.102-4.062zM18 6c.55 0 1.058-.158 1.5-.416.443.258.951.416 1.5.416 1.657 0 4-2.344 4-4 0 0 0-2-2-2-.788 0-1 1-2 1s-1-1-3-1-2 1-3 1-1.211-1-2-1c-2 0-2 2-2 2 0 1.656 2.344 4 4 4 .549 0 1.057-.158 1.5-.416.443.258.951.416 1.5.416z"/><path fill="#BF6952" d="M24 6c0 .552-.447 1-1 1H13c-.552 0-1-.448-1-1s.448-1 1-1h10c.553 0 1 .448 1 1z"/><path fill="#67757F" d="M23.901 24.542c0-4.477-8.581-4.185-8.581-6.886 0-1.308 1.301-1.947 2.811-1.947 2.538 0 2.99 1.569 4.139 1.569.813 0 1.205-.493 1.205-1.046 0-1.284-2.024-2.256-3.965-2.592V12.4c0-.773-.65-1.4-1.454-1.4-.805 0-1.456.627-1.456 1.4v1.283c-2.116.463-3.937 1.875-3.937 4.176 0 4.299 8.579 4.125 8.579 7.145 0 1.047-1.178 2.093-3.111 2.093-2.901 0-3.867-1.889-5.045-1.889-.574 0-1.087.464-1.087 1.164 0 1.113 1.938 2.451 4.603 2.824l-.001.01v1.398c0 .772.652 1.4 1.456 1.4.804 0 1.455-.628 1.455-1.4v-1.398c0-.017-.008-.03-.009-.045 2.398-.43 4.398-1.932 4.398-4.619z"/></svg> " + "=" * 50)
print(" RECIBO DE NÓMINA")
print("=" * 52)
print(f"Empleado: {nombre_empleado}")
print(f"Fecha: {__import__('datetime').datetime.now().strftime('%d/%m/%Y')}")
print("\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#5C913B" d="M2 11c-2 0-2 2-2 2v21s0 2 2 2h32c2 0 2-2 2-2V13s0-2-2-2H2z"/><path fill="#A7D28B" d="M2 6C0 6 0 8 0 8v20s0 2 2 2h32c2 0 2-2 2-2V8s0-2-2-2H2z"/><circle fill="#77B255" cx="25" cy="18" r="6.5"/><path fill="#5C913B" d="M33 28.5H3c-.827 0-1.5-.673-1.5-1.5V9c0-.827.673-1.5 1.5-1.5h30c.827 0 1.5.673 1.5 1.5v18c0 .827-.673 1.5-1.5 1.5zM3 8.5c-.275 0-.5.224-.5.5v18c0 .275.225.5.5.5h30c.275 0 .5-.225.5-.5V9c0-.276-.225-.5-.5-.5H3z"/><path fill="#FFE8B6" d="M14 6h8v24.062h-8z"/><path fill="#FFAC33" d="M14 30h8v6h-8z"/><path fill="#5C913B" d="M11.81 20.023c0-2.979-5.493-2.785-5.493-4.584 0-.871.833-1.296 1.799-1.296 1.625 0 1.914 1.044 2.65 1.044.521 0 .772-.328.772-.696 0-.856-1.296-1.502-2.539-1.726v-.825c0-.515-.417-.932-.932-.932s-.932.418-.932.932v.853c-1.354.31-2.521 1.25-2.521 2.781 0 2.862 5.493 2.746 5.493 4.758 0 .695-.754 1.391-1.992 1.391-1.857 0-2.476-1.257-3.229-1.257-.368 0-.696.309-.696.775 0 .741 1.24 1.631 2.947 1.881l-.001.004v.934c0 .514.418.932.933.932.514-.001.931-.419.931-.932v-.934c0-.01-.005-.019-.006-.028 1.535-.287 2.816-1.286 2.816-3.075z"/></svg> INGRESOS:")
print(f" Salario base: ${salario_base:>10,.2f}")
print(f" Horas extra ({horas_extra}h): ${pago_extra:>10,.2f}")
print(f" Bono productividad: ${bono_productividad:>10,.2f}")
print(f" Bono puntualidad: ${bono_puntualidad:>10,.2f}")
print(f" {'-' * 35}")
print(f" TOTAL BRUTO: ${ingresos_brutos:>10,.2f}")
print("\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#CCD6DD" d="M31 2H5C3.343 2 2 3.343 2 5v26c0 1.657 1.343 3 3 3h26c1.657 0 3-1.343 3-3V5c0-1.657-1.343-3-3-3z"/><path fill="#E1E8ED" d="M31 1H5C2.791 1 1 2.791 1 5v26c0 2.209 1.791 4 4 4h26c2.209 0 4-1.791 4-4V5c0-2.209-1.791-4-4-4zm0 2c1.103 0 2 .897 2 2v4h-6V3h4zm-4 16h6v6h-6v-6zm0-2v-6h6v6h-6zM25 3v6h-6V3h6zm-6 8h6v6h-6v-6zm0 8h6v6h-6v-6zM17 3v6h-6V3h6zm-6 8h6v6h-6v-6zm0 8h6v6h-6v-6zM3 5c0-1.103.897-2 2-2h4v6H3V5zm0 6h6v6H3v-6zm0 8h6v6H3v-6zm2 14c-1.103 0-2-.897-2-2v-4h6v6H5zm6 0v-6h6v6h-6zm8 0v-6h6v6h-6zm12 0h-4v-6h6v4c0 1.103-.897 2-2 2z"/><path fill="#3B94D9" d="M31.002 33c-.721 0-1.416-.39-1.774-1.072l-9.738-18.59-6.076 6.076c-.446.447-1.076.66-1.705.564-.626-.092-1.171-.474-1.47-1.03l-7-13c-.524-.973-.16-2.186.813-2.709.975-.523 2.186-.16 2.709.812l5.726 10.633 6.1-6.099c.45-.45 1.089-.659 1.716-.563.629.096 1.175.485 1.47 1.049l11 21c.513.979.135 2.187-.844 2.699-.297.157-.614.23-.927.23z"/></svg> DEDUCCIONES:")
print(f" Impuesto renta (10%): ${deduccion_impuesto:>9,.2f}")
print(f" Seguro social (6.25%): ${deduccion_seguro_social:>8,.2f}")
print(f" Seguro médico: ${seguro_medico:>10,.2f}")
print(f" Fondo pensión (4%): ${deduccion_pension:>10,.2f}")
print(f" {'-' * 35}")
print(f" TOTAL DEDUCCIONES: ${total_deducciones:>10,.2f}")
print("\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#FDD888" d="M31.898 23.938C31.3 17.32 28 14 28 14l-6-8h-8l-6 8s-1.419 1.433-2.567 4.275C3.444 18.935 2 20.789 2 23c0 1.448.625 2.742 1.609 3.655C3.233 27.357 3 28.147 3 29c0 1.958 1.136 3.636 2.775 4.456C7.058 35.378 8.772 36 10 36h16c1.379 0 3.373-.779 4.678-3.31C32.609 31.999 34 30.17 34 28c0-1.678-.834-3.154-2.102-4.062zM18 6c.55 0 1.058-.158 1.5-.416.443.258.951.416 1.5.416 1.657 0 4-2.344 4-4 0 0 0-2-2-2-.788 0-1 1-2 1s-1-1-3-1-2 1-3 1-1.211-1-2-1c-2 0-2 2-2 2 0 1.656 2.344 4 4 4 .549 0 1.057-.158 1.5-.416.443.258.951.416 1.5.416z"/><path fill="#BF6952" d="M24 6c0 .552-.447 1-1 1H13c-.552 0-1-.448-1-1s.448-1 1-1h10c.553 0 1 .448 1 1z"/><path fill="#67757F" d="M23.901 24.542c0-4.477-8.581-4.185-8.581-6.886 0-1.308 1.301-1.947 2.811-1.947 2.538 0 2.99 1.569 4.139 1.569.813 0 1.205-.493 1.205-1.046 0-1.284-2.024-2.256-3.965-2.592V12.4c0-.773-.65-1.4-1.454-1.4-.805 0-1.456.627-1.456 1.4v1.283c-2.116.463-3.937 1.875-3.937 4.176 0 4.299 8.579 4.125 8.579 7.145 0 1.047-1.178 2.093-3.111 2.093-2.901 0-3.867-1.889-5.045-1.889-.574 0-1.087.464-1.087 1.164 0 1.113 1.938 2.451 4.603 2.824l-.001.01v1.398c0 .772.652 1.4 1.456 1.4.804 0 1.455-.628 1.455-1.4v-1.398c0-.017-.008-.03-.009-.045 2.398-.43 4.398-1.932 4.398-4.619z"/></svg> RESUMEN:")
print(f" SALARIO NETO: ${salario_neto:>10,.2f}")
# Análisis adicional
porcentaje_deducciones = (total_deducciones / ingresos_brutos) * 100
print(f"\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#CCD6DD" d="M31 2H5C3.343 2 2 3.343 2 5v26c0 1.657 1.343 3 3 3h26c1.657 0 3-1.343 3-3V5c0-1.657-1.343-3-3-3z"/><path fill="#E1E8ED" d="M31 1H5C2.791 1 1 2.791 1 5v26c0 2.209 1.791 4 4 4h26c2.209 0 4-1.791 4-4V5c0-2.209-1.791-4-4-4zm0 2c1.103 0 2 .897 2 2v4h-6V3h4zm-4 16h6v6h-6v-6zm0-2v-6h6v6h-6zM25 3v6h-6V3h6zm-6 8h6v6h-6v-6zm0 8h6v6h-6v-6zM17 3v6h-6V3h6zm-6 8h6v6h-6v-6zm0 8h6v6h-6v-6zM3 5c0-1.103.897-2 2-2h4v6H3V5zm0 6h6v6H3v-6zm0 8h6v6H3v-6zm2 14c-1.103 0-2-.897-2-2v-4h6v6H5zm6 0v-6h6v6h-6zm8 0v-6h6v6h-6zm12 0h-4v-6h6v4c0 1.103-.897 2-2 2z"/><path fill="#5C913B" d="M13 33H7V16c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v17z"/><path fill="#3B94D9" d="M29 33h-6V9c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v24z"/><path fill="#DD2E44" d="M21 33h-6V23c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v10z"/></svg> ANÁLISIS:")
print(f" Porcentaje deducido: {porcentaje_deducciones:>10.1f}%")
print(f" Efectivo a recibir: {100 - porcentaje_deducciones:>10.1f}%")
# Proyección anual
salario_anual_neto = salario_neto * 12
print(f"\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#E0E7EC" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V9c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v23z"/><path d="M23.657 19.12H17.87c-1.22 0-1.673-.791-1.673-1.56 0-.791.429-1.56 1.673-1.56h8.184c1.154 0 1.628 1.04 1.628 1.628 0 .452-.249.927-.52 1.492l-5.607 11.395c-.633 1.266-.882 1.717-1.899 1.717-1.244 0-1.877-.949-1.877-1.605 0-.271.068-.474.226-.791l5.652-10.716zM10.889 19h-.5c-1.085 0-1.538-.731-1.538-1.5 0-.792.565-1.5 1.538-1.5h2.015c.972 0 1.515.701 1.515 1.605V30.47c0 1.13-.558 1.763-1.53 1.763s-1.5-.633-1.5-1.763V19z" fill="#66757F"/><path fill="#DD2F45" d="M34 0h-3.277c.172.295.277.634.277 1 0 1.104-.896 2-2 2s-2-.896-2-2c0-.366.105-.705.277-1H8.723C8.895.295 9 .634 9 1c0 1.104-.896 2-2 2s-2-.896-2-2c0-.366.105-.705.277-1H2C.896 0 0 .896 0 2v11h36V2c0-1.104-.896-2-2-2z"/><path d="M13.182 4.604c0-.5.32-.78.75-.78.429 0 .749.28.749.78v5.017h1.779c.51 0 .73.38.72.72-.02.33-.28.659-.72.659h-2.498c-.49 0-.78-.319-.78-.819V4.604zm-6.91 0c0-.5.32-.78.75-.78s.75.28.75.78v3.488c0 .92.589 1.649 1.539 1.649.909 0 1.529-.769 1.529-1.649V4.604c0-.5.319-.78.749-.78s.75.28.75.78v3.568c0 1.679-1.38 2.949-3.028 2.949-1.669 0-3.039-1.25-3.039-2.949V4.604zM5.49 9.001c0 1.679-1.069 2.119-1.979 2.119-.689 0-1.839-.27-1.839-1.14 0-.269.23-.609.56-.609.4 0 .75.37 1.199.37.56 0 .56-.52.56-.84V4.604c0-.5.32-.78.749-.78.431 0 .75.28.75.78v4.397z" fill="#F5F8FA"/><path d="M32 10c0 .552.447 1 1 1s1-.448 1-1-.447-1-1-1-1 .448-1 1m0-3c0 .552.447 1 1 1s1-.448 1-1-.447-1-1-1-1 .448-1 1m-3 3c0 .552.447 1 1 1s1-.448 1-1-.447-1-1-1-1 .448-1 1m0-3c0 .552.447 1 1 1s1-.448 1-1-.447-1-1-1-1 .448-1 1m-3 3c0 .552.447 1 1 1s1-.448 1-1-.447-1-1-1-1 .448-1 1m0-3c0 .552.447 1 1 1s1-.448 1-1-.447-1-1-1-1 .448-1 1m-3 0c0 .552.447 1 1 1s1-.448 1-1-.447-1-1-1-1 .448-1 1m0 3c0 .552.447 1 1 1s1-.448 1-1-.447-1-1-1-1 .448-1 1" fill="#F4ABBA"/></svg> PROYECCIÓN ANUAL:")
print(f" Salario neto anual: ${salario_anual_neto:>11,.2f}")
print("=" * 52)
Explicación de la solución:
- Estructura profesional: El código está organizado en secciones claras
- Cálculos precisos: Distingo entre deducciones porcentuales y fijas
- Formateo profesional: El recibo se ve como uno real
- Análisis adicional: Incluyo porcentajes y proyecciones anuales
- Documentación clara: Cada sección está bien comentada
Ejercicio 2: Distribución de productos
Solución completa:
# ================================
# DISTRIBUCIÓN DE PRODUCTOS - SOLUCIÓN COMPLETA
# ================================
productos_totales = 1847
productos_por_caja = 24
peso_por_caja = 5.5 # kg
# Cálculos principales
cajas_completas = productos_totales // productos_por_caja
productos_sueltos = productos_totales % productos_por_caja
peso_total_cajas = cajas_completas * peso_por_caja
# Cálculos adicionales
productos_empacados = cajas_completas * productos_por_caja
eficiencia_empacado = (productos_empacados / productos_totales) * 100
# Si empacamos los productos sueltos en una caja adicional
cajas_totales_necesarias = cajas_completas + (1 if productos_sueltos > 0 else 0)
peso_total_con_caja_parcial = cajas_totales_necesarias * peso_por_caja
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#662113" d="M4 11v12.375c0 2.042 1.093 2.484 1.093 2.484l11.574 9.099C18.489 36.39 18 33.375 18 33.375V22L4 11z"/><path fill="#C1694F" d="M32 11v12.375c0 2.042-1.063 2.484-1.063 2.484s-9.767 7.667-11.588 9.099C17.526 36.39 18 33.375 18 33.375V22l14-11z"/><path fill="#D99E82" d="M19.289.5c-.753-.61-1.988-.61-2.742 0L4.565 10.029c-.754.61-.754 1.607 0 2.216l12.023 9.646c.754.609 1.989.609 2.743 0l12.104-9.73c.754-.609.754-1.606 0-2.216L19.289.5z"/><path fill="#D99E82" d="M18 35.75c-.552 0-1-.482-1-1.078V21.745c0-.596.448-1.078 1-1.078.553 0 1 .482 1 1.078v12.927c0 .596-.447 1.078-1 1.078z"/><path fill="#99AAB5" d="M28 18.836c0 1.104.104 1.646-1 2.442l-2.469 1.878c-1.104.797-1.531.113-1.531-.992v-2.961c0-.193-.026-.4-.278-.608C20.144 16.47 10.134 8.519 8.31 7.051l4.625-3.678c1.266.926 10.753 8.252 14.722 11.377.197.156.343.328.343.516v3.57z"/><path fill="#CCD6DD" d="M27.656 14.75C23.688 11.625 14.201 4.299 12.935 3.373l-1.721 1.368-2.904 2.31c1.825 1.468 11.834 9.419 14.412 11.544.151.125.217.25.248.371L27.903 15c-.06-.087-.146-.171-.247-.25z"/><path fill="#CCD6DD" d="M28 18.836v-3.57c0-.188-.146-.359-.344-.516-3.968-3.125-13.455-10.451-14.721-11.377l-2.073 1.649c3.393 2.669 12.481 9.681 14.86 11.573.256.204.278.415.278.608v4.836l1-.761c1.104-.797 1-1.338 1-2.442z"/><path fill="#E1E8ED" d="M27.656 14.75C23.688 11.625 14.201 4.299 12.935 3.373l-2.073 1.649c3.393 2.669 12.481 9.681 14.86 11.573.037.029.06.059.087.088L27.903 15c-.06-.087-.146-.171-.247-.25z"/></svg> " + "=" * 50)
print(" ANÁLISIS DE DISTRIBUCIÓN DE PRODUCTOS")
print("=" * 52)
print(f"Productos totales recibidos: {productos_totales:,} unidades")
print(f"Capacidad por caja: {productos_por_caja} unidades")
print(f"Peso por caja: {peso_por_caja} kg")
print("\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#CCD6DD" d="M31 2H5C3.343 2 2 3.343 2 5v26c0 1.657 1.343 3 3 3h26c1.657 0 3-1.343 3-3V5c0-1.657-1.343-3-3-3z"/><path fill="#E1E8ED" d="M31 1H5C2.791 1 1 2.791 1 5v26c0 2.209 1.791 4 4 4h26c2.209 0 4-1.791 4-4V5c0-2.209-1.791-4-4-4zm0 2c1.103 0 2 .897 2 2v4h-6V3h4zm-4 16h6v6h-6v-6zm0-2v-6h6v6h-6zM25 3v6h-6V3h6zm-6 8h6v6h-6v-6zm0 8h6v6h-6v-6zM17 3v6h-6V3h6zm-6 8h6v6h-6v-6zm0 8h6v6h-6v-6zM3 5c0-1.103.897-2 2-2h4v6H3V5zm0 6h6v6H3v-6zm0 8h6v6H3v-6zm2 14c-1.103 0-2-.897-2-2v-4h6v6H5zm6 0v-6h6v6h-6zm8 0v-6h6v6h-6zm12 0h-4v-6h6v4c0 1.103-.897 2-2 2z"/><path fill="#5C913B" d="M13 33H7V16c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v17z"/><path fill="#3B94D9" d="M29 33h-6V9c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v24z"/><path fill="#DD2E44" d="M21 33h-6V23c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v10z"/></svg> RESULTADOS DE EMPACADO:")
print(f" Cajas completas formadas: {cajas_completas:,} cajas")
print(f" Productos en cajas: {productos_empacados:,} unidades")
print(f" Productos sueltos: {productos_sueltos} unidades")
print(f" Eficiencia de empacado: {eficiencia_empacado:.1f}%")
print("\n⚖️ PESO Y LOGÍSTICA:")
print(f" Peso de cajas completas: {peso_total_cajas:.1f} kg")
print(f" Cajas necesarias total: {cajas_totales_necesarias} cajas")
print(f" Peso total estimado: {peso_total_con_caja_parcial:.1f} kg")
# Análisis de optimización
print("\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><circle fill="#DD2E44" cx="18" cy="18" r="18"/><circle fill="#FFF" cx="18" cy="18" r="13.5"/><circle fill="#DD2E44" cx="18" cy="18" r="10"/><circle fill="#FFF" cx="18" cy="18" r="6"/><circle fill="#DD2E44" cx="18" cy="18" r="3"/><path opacity=".2" d="M18.24 18.282l13.144 11.754s-2.647 3.376-7.89 5.109L17.579 18.42l.661-.138z"/><path fill="#FFAC33" d="M18.294 19c-.255 0-.509-.097-.704-.292-.389-.389-.389-1.018 0-1.407l.563-.563c.389-.389 1.018-.389 1.408 0 .388.389.388 1.018 0 1.407l-.564.563c-.194.195-.448.292-.703.292z"/><path fill="#55ACEE" d="M24.016 6.981c-.403 2.079 0 4.691 0 4.691l7.054-7.388c.291-1.454-.528-3.932-1.718-4.238-1.19-.306-4.079.803-5.336 6.935zm5.003 5.003c-2.079.403-4.691 0-4.691 0l7.388-7.054c1.454-.291 3.932.528 4.238 1.718.306 1.19-.803 4.079-6.935 5.336z"/><path fill="#3A87C2" d="M32.798 4.485L21.176 17.587c-.362.362-1.673.882-2.51.046-.836-.836-.419-2.08-.057-2.443L31.815 3.501s.676-.635 1.159-.152-.176 1.136-.176 1.136z"/></svg> ANÁLISIS DE OPTIMIZACIÓN:")
if productos_sueltos > 0:
porcentaje_sueltos = (productos_sueltos / productos_por_caja) * 100
print(f" La última caja estará {porcentaje_sueltos:.1f}% llena")
if productos_sueltos >= productos_por_caja / 2:
print(f" <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#77B255" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V4c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v28z"/><path fill="#FFF" d="M29.28 6.362c-1.156-.751-2.704-.422-3.458.736L14.936 23.877l-5.029-4.65c-1.014-.938-2.596-.875-3.533.138-.937 1.014-.875 2.596.139 3.533l7.209 6.666c.48.445 1.09.665 1.696.665.673 0 1.534-.282 2.099-1.139.332-.506 12.5-19.27 12.5-19.27.751-1.159.421-2.707-.737-3.458z"/></svg> Recomendación: Empacar en caja adicional")
else:
print(f" <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#FFCC4D" d="M2.653 35C.811 35-.001 33.662.847 32.027L16.456 1.972c.849-1.635 2.238-1.635 3.087 0l15.609 30.056c.85 1.634.037 2.972-1.805 2.972H2.653z"/><path fill="#231F20" d="M15.583 28.953c0-1.333 1.085-2.418 2.419-2.418 1.333 0 2.418 1.085 2.418 2.418 0 1.334-1.086 2.419-2.418 2.419-1.334 0-2.419-1.085-2.419-2.419zm.186-18.293c0-1.302.961-2.108 2.232-2.108 1.241 0 2.233.837 2.233 2.108v11.938c0 1.271-.992 2.108-2.233 2.108-1.271 0-2.232-.807-2.232-2.108V10.66z"/></svg>️ Considerar: Los {productos_sueltos} productos sueltos ocupan poco espacio")
else:
print(f" <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#77B255" d="M36 32c0 2.209-1.791 4-4 4H4c-2.209 0-4-1.791-4-4V4c0-2.209 1.791-4 4-4h28c2.209 0 4 1.791 4 4v28z"/><path fill="#FFF" d="M29.28 6.362c-1.156-.751-2.704-.422-3.458.736L14.936 23.877l-5.029-4.65c-1.014-.938-2.596-.875-3.533.138-.937 1.014-.875 2.596.139 3.533l7.209 6.666c.48.445 1.09.665 1.696.665.673 0 1.534-.282 2.099-1.139.332-.506 12.5-19.27 12.5-19.27.751-1.159.421-2.707-.737-3.458z"/></svg> Perfecto: No hay productos sueltos")
# Cálculos de transporte
print("\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#99AAB5" d="M31 25H11v-1c0-2.209-1.791-4-4-4H4c-2.209 0-4 1.791-4 4v3c0 2.209 1.791 4 4 4h28c2.209 0 4-1.791 4-4v-2h-5z"/><path fill="#FFCC4D" d="M10 12H7.146C4 12 3 14 3 14l-3 5.959V25h13V15c0-1.657-1.343-3-3-3z"/><path fill="#55ACEE" d="M9 20H2l2-4s1-2 3-2h2v6z"/><circle fill="#292F33" cx="6" cy="31" r="4"/><circle fill="#CCD6DD" cx="6" cy="31" r="2"/><circle fill="#292F33" cx="30" cy="31" r="4"/><circle fill="#CCD6DD" cx="30" cy="31" r="2"/><circle fill="#292F33" cx="20" cy="31" r="4"/><circle fill="#CCD6DD" cx="20" cy="31" r="2"/><path fill="#77B255" d="M32 8H19c-2.209 0-4 1.791-4 4v13h21V12c0-2.209-1.791-4-4-4z"/></svg> ESTIMACIÓN DE TRANSPORTE:")
camion_capacidad = 1000 # kg
camiones_necesarios = peso_total_con_caja_parcial / camion_capacidad
print(f" Para camión de {camion_capacidad}kg: {camiones_necesarios:.2f} camiones")
print(f" Camiones enteros necesarios: {int(camiones_necesarios) + (1 if camiones_necesarios % 1 > 0 else 0)}")
print("=" * 52)
Explicación de la solución:
- Uso correcto de operadores:
//para cajas completas,%para sobrantes - Análisis completo: No solo respondo las preguntas, sino que agrego insights útiles
- Eficiencia de empacado: Calculo qué porcentaje de productos se empaca eficientemente
- Recomendaciones prácticas: Doy consejos sobre qué hacer con productos sueltos
- Extensión logística: Incluyo cálculos de transporte que serían útiles en la realidad
Capítulo 6: Estructuras de Control
Ejercicio: Sistema de clasificación de productos
Solución completa:
# ================================
# SISTEMA DE CLASIFICACIÓN DE PRODUCTOS
# ================================
# Simulación de productos del almacén
productos = [
{"codigo": "LAP001", "nombre": "Laptop Gaming", "precio": 1299.99, "stock": 5},
{"codigo": "MOU001", "nombre": "Mouse Inalámbrico", "precio": 29.99, "stock": 50},
{"codigo": "TEC001", "nombre": "Teclado Mecánico", "precio": 89.99, "stock": 25},
{"codigo": "MON001", "nombre": "Monitor 4K", "precio": 399.99, "stock": 8},
{"codigo": "AUD001", "nombre": "Auriculares Gaming", "precio": 79.99, "stock": 15},
{"codigo": "CAM001", "nombre": "Cámara Web HD", "precio": 49.99, "stock": 3},
{"codigo": "IMP001", "nombre": "Impresora Láser", "precio": 199.99, "stock": 0},
{"codigo": "TAB001", "nombre": "Tablet 10 pulgadas", "precio": 299.99, "stock": 12}
]
# Contadores para estadísticas
total_productos = len(productos)
productos_premium = 0
productos_economicos = 0
productos_stock_bajo = 0
productos_sin_stock = 0
valor_total_inventario = 0
# Listas para categorización
lista_premium = []
lista_economicos = []
lista_stock_critico = []
lista_sin_stock = []
print("<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#AAB8C2" d="M17 34c0 1.104.896 2 2 2h14c1.104 0 2-.896 2-2V18c0-1.104-.896-2-2-2H19c-1.104 0-2 .896-2 2v16z"/><path fill="#292F33" d="M33 16H23v2h12c0-1.104-.896-2-2-2z"/><path fill="#3B88C3" d="M3 30h30v4H3z"/><path fill="#CCD6DD" d="M3 16c-1.104 0-2 .896-2 2v16c0 1.104.896 2 2 2h20V16H3z"/><path fill="#66757F" d="M3 16c-1.104 0-2 .896-2 2h22v-2H3z"/><path fill="#55ACEE" d="M3 20h4v4H3zm14 0h4v4h-4zm-7 0h4v4h-4z"/><path fill="#3B88C3" d="M29 20h4v4h-4zm-6 0h4v4h-4z"/><path fill="#55ACEE" d="M3 30h18v6H3z"/><path fill="#3B88C3" d="M7 30h10v6H7z"/><path fill="#DD2E44" d="M1 26h22v4H1z"/><path fill="#F4ABBA" d="M7 27h10v2H7z"/><path fill="#FFF" d="M9 27h6v2H9z"/><path fill="#A0041E" d="M23 26h12v4H23z"/><path fill="#292F33" d="M5 14h2v2H5zm12 0h2v2h-2z"/><path fill="#DD2E44" d="M21 12c0 1.104-.896 2-2 2H5c-1.104 0-2-.896-2-2V2c0-1.104.896-2 2-2h14c1.104 0 2 .896 2 2v10z"/><path d="M10.561 10.151c.616 0 1.093.28 1.093.925 0 .644-.477.924-1.009.924H5.967c-.617 0-1.093-.28-1.093-.924 0-.294.182-.546.322-.714C6.359 8.975 7.62 7.714 8.685 6.173c.252-.364.49-.798.49-1.303 0-.574-.434-1.079-1.009-1.079-1.611 0-.84 2.269-2.185 2.269-.672 0-1.022-.476-1.022-1.022 0-1.765 1.569-3.18 3.292-3.18 1.723 0 3.109 1.135 3.109 2.914 0 1.947-2.171 3.88-3.362 5.379h2.563zm2.363-.35c-.687 0-.981-.462-.981-.826 0-.309.112-.477.196-.617l3.138-5.687c.308-.56.7-.813 1.429-.813.812 0 1.611.519 1.611 1.793v4.3h.238c.546 0 .98.364.98.925 0 .56-.434.924-.98.924h-.238v1.19c0 .743-.295 1.093-1.009 1.093s-1.008-.35-1.008-1.093V9.8h-3.376zM16.3 4.044h-.028l-1.891 3.908H16.3V4.044z" fill="#FFF"/></svg> " + "=" * 60)
print(" SISTEMA DE CLASIFICACIÓN DE PRODUCTOS")
print("=" * 62)
# Procesar cada producto
for producto in productos:
codigo = producto["codigo"]
nombre = producto["nombre"]
precio = producto["precio"]
stock = producto["stock"]
# Calcular valor del inventario
valor_producto = precio * stock
valor_total_inventario += valor_producto
# Clasificación por precio
if precio >= 200:
categoria_precio = "Premium"
productos_premium += 1
lista_premium.append(producto)
emoji_precio = "<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#FDD888" d="M31.898 23.938C31.3 17.32 28 14 28 14l-6-8h-8l-6 8s-1.419 1.433-2.567 4.275C3.444 18.935 2 20.789 2 23c0 1.448.625 2.742 1.609 3.655C3.233 27.357 3 28.147 3 29c0 1.958 1.136 3.636 2.775 4.456C7.058 35.378 8.772 36 10 36h16c1.379 0 3.373-.779 4.678-3.31C32.609 31.999 34 30.17 34 28c0-1.678-.834-3.154-2.102-4.062zM18 6c.55 0 1.058-.158 1.5-.416.443.258.951.416 1.5.416 1.657 0 4-2.344 4-4 0 0 0-2-2-2-.788 0-1 1-2 1s-1-1-3-1-2 1-3 1-1.211-1-2-1c-2 0-2 2-2 2 0 1.656 2.344 4 4 4 .549 0 1.057-.158 1.5-.416.443.258.951.416 1.5.416z"/><path fill="#BF6952" d="M24 6c0 .552-.447 1-1 1H13c-.552 0-1-.448-1-1s.448-1 1-1h10c.553 0 1 .448 1 1z"/><path fill="#67757F" d="M23.901 24.542c0-4.477-8.581-4.185-8.581-6.886 0-1.308 1.301-1.947 2.811-1.947 2.538 0 2.99 1.569 4.139 1.569.813 0 1.205-.493 1.205-1.046 0-1.284-2.024-2.256-3.965-2.592V12.4c0-.773-.65-1.4-1.454-1.4-.805 0-1.456.627-1.456 1.4v1.283c-2.116.463-3.937 1.875-3.937 4.176 0 4.299 8.579 4.125 8.579 7.145 0 1.047-1.178 2.093-3.111 2.093-2.901 0-3.867-1.889-5.045-1.889-.574 0-1.087.464-1.087 1.164 0 1.113 1.938 2.451 4.603 2.824l-.001.01v1.398c0 .772.652 1.4 1.456 1.4.804 0 1.455-.628 1.455-1.4v-1.398c0-.017-.008-.03-.009-.045 2.398-.43 4.398-1.932 4.398-4.619z"/></svg>"
elif precio >= 50:
categoria_precio = "Medio"
emoji_precio = "🟡"
else:
categoria_precio = "Económico"
productos_economicos += 1
lista_economicos.append(producto)
emoji_precio = "🟢"
# Clasificación por stock
if stock == 0:
categoria_stock = "Sin stock"
productos_sin_stock += 1
lista_sin_stock.append(producto)
emoji_stock = "<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><circle fill="#DD2E44" cx="18" cy="18" r="18"/></svg>"
elif stock <= 5:
categoria_stock = "Stock crítico"
productos_stock_bajo += 1
lista_stock_critico.append(producto)
emoji_stock = "🟠"
elif stock <= 15:
categoria_stock = "Stock bajo"
emoji_stock = "🟡"
else:
categoria_stock = "Stock normal"
emoji_stock = "🟢"
# Mostrar información del producto
print(f"{codigo} | {nombre:<20} | ${precio:>7.2f} | {stock:>3} und")
print(f" {emoji_precio} {categoria_precio:<10} | {emoji_stock} {categoria_stock}")
print(f" Valor inventario: ${valor_producto:,.2f}")
print("-" * 62)
# Mostrar estadísticas generales
print("\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#CCD6DD" d="M31 2H5C3.343 2 2 3.343 2 5v26c0 1.657 1.343 3 3 3h26c1.657 0 3-1.343 3-3V5c0-1.657-1.343-3-3-3z"/><path fill="#E1E8ED" d="M31 1H5C2.791 1 1 2.791 1 5v26c0 2.209 1.791 4 4 4h26c2.209 0 4-1.791 4-4V5c0-2.209-1.791-4-4-4zm0 2c1.103 0 2 .897 2 2v4h-6V3h4zm-4 16h6v6h-6v-6zm0-2v-6h6v6h-6zM25 3v6h-6V3h6zm-6 8h6v6h-6v-6zm0 8h6v6h-6v-6zM17 3v6h-6V3h6zm-6 8h6v6h-6v-6zm0 8h6v6h-6v-6zM3 5c0-1.103.897-2 2-2h4v6H3V5zm0 6h6v6H3v-6zm0 8h6v6H3v-6zm2 14c-1.103 0-2-.897-2-2v-4h6v6H5zm6 0v-6h6v6h-6zm8 0v-6h6v6h-6zm12 0h-4v-6h6v4c0 1.103-.897 2-2 2z"/><path fill="#5C913B" d="M13 33H7V16c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v17z"/><path fill="#3B94D9" d="M29 33h-6V9c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v24z"/><path fill="#DD2E44" d="M21 33h-6V23c0-1.104.896-2 2-2h2c1.104 0 2 .896 2 2v10z"/></svg> ESTADÍSTICAS GENERALES:")
print(f" Total de productos: {total_productos}")
print(f" Productos premium: {productos_premium} ({productos_premium/total_productos*100:.1f}%)")
print(f" Productos económicos: {productos_economicos} ({productos_economicos/total_productos*100:.1f}%)")
print(f" Con stock crítico: {productos_stock_bajo} ({productos_stock_bajo/total_productos*100:.1f}%)")
print(f" Sin stock: {productos_sin_stock} ({productos_sin_stock/total_productos*100:.1f}%)")
print(f" Valor total inventario: ${valor_total_inventario:,.2f}")
# Alertas importantes
print("\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#FFCC4D" d="M2.653 35C.811 35-.001 33.662.847 32.027L16.456 1.972c.849-1.635 2.238-1.635 3.087 0l15.609 30.056c.85 1.634.037 2.972-1.805 2.972H2.653z"/><path fill="#231F20" d="M15.583 28.953c0-1.333 1.085-2.418 2.419-2.418 1.333 0 2.418 1.085 2.418 2.418 0 1.334-1.086 2.419-2.418 2.419-1.334 0-2.419-1.085-2.419-2.419zm.186-18.293c0-1.302.961-2.108 2.232-2.108 1.241 0 2.233.837 2.233 2.108v11.938c0 1.271-.992 2.108-2.233 2.108-1.271 0-2.232-.807-2.232-2.108V10.66z"/></svg>️ ALERTAS IMPORTANTES:")
if productos_sin_stock > 0:
print(f" <svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><circle fill="#DD2E44" cx="18" cy="18" r="18"/></svg> {productos_sin_stock} productos SIN STOCK:")
for prod in lista_sin_stock:
print(f" - {prod['nombre']} ({prod['codigo']})")
if productos_stock_bajo > 0:
print(f" 🟠 {productos_stock_bajo} productos con STOCK CRÍTICO:")
for prod in lista_stock_critico:
print(f" - {prod['nombre']} ({prod['codigo']}): {prod['stock']} unidades")
# Recomendaciones
print("\n<svg class="emoji-svg" style="display: inline-block; width: 1.2em; height: 1.2em; vertical-align: -0.1em;" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 36 36"><path fill="#FFD983" d="M29 11.06c0 6.439-5 7.439-5 13.44 0 3.098-3.123 3.359-5.5 3.359-2.053 0-6.586-.779-6.586-3.361C11.914 18.5 7 17.5 7 11.06 7 5.029 12.285.14 18.083.14 23.883.14 29 5.029 29 11.06z"/><path fill="#CCD6DD" d="M22.167 32.5c0 .828-2.234 2.5-4.167 2.5-1.933 0-4.167-1.672-4.167-2.5 0-.828 2.233-.5 4.167-.5 1.933 0 4.167-.328 4.167.5z"/><path fill="#FFCC4D" d="M22.707 10.293c-.391-.391-1.023-.391-1.414 0L18 13.586l-3.293-3.293c-.391-.391-1.023-.391-1.414 0s-.391 1.023 0 1.414L17 15.414V26c0 .553.448 1 1 1s1-.447 1-1V15.414l3.707-3.707c.391-.391.391-1.023 0-1.414z"/><path fill="#99AAB5" d="M24 31c0 1.104-.896 2-2 2h-8c-1.104 0-2-.896-2-2v-6h12v6z"/><path fill="#CCD6DD" d="M11.999 32c-.48 0-.904-.347-.985-.836-.091-.544.277-1.06.822-1.15l12-2c.544-.098 1.06.277 1.15.822.091.544-.277 1.06-.822 1.15l-12 2c-.055.01-.111.014-.165.014zm0-4c-.48 0-.904-.347-.985-.836-.091-.544.277-1.06.822-1.15l12-2c.544-.097 1.06.277 1.15.822.091.544-.277 1.06-.822 1.15l-12 2c-.055.01-.111.014-.165.014z"/></svg> RECOMENDACIONES:")
if productos_sin_stock > 0:
print(" 1. Reabastecer inmediatamente productos sin stock")
if productos_stock_bajo > 0:
print(" 2. Programar reabastecimiento para productos con stock crítico")
if productos_premium > productos_economicos:
print(" 3. Considerar promoción de productos premium")
else:
print(" 3. Considerar expandir línea de productos premium")
print("=" * 62)
Explicación de la solución:
- Estructuras anidadas: Uso if/elif/else para múltiples categorizaciones
- Bucles con lógica compleja: Cada iteración realiza múltiples cálculos y clasificaciones
- Contadores y acumuladores: Mantengo estadísticas durante el procesamiento
- Listas de categorización: Guardo productos en listas según sus características
- Sistema de alertas: Genero recomendaciones basadas en los datos
Notas Importantes
Cómo usar este apéndice efectivamente
- Antes de ver la solución: Intenta resolver el ejercicio completamente
- Compara tu solución: Ve las diferencias entre tu enfoque y el propuesto
- Entiende el razonamiento: Lee las explicaciones, no solo el código
- Experimenta: Modifica las soluciones para entender mejor cómo funcionan
- Aplica conceptos: Usa las técnicas aprendidas en tus propios proyectos
Patrones comunes en las soluciones
- Validación de datos: Siempre verifico que los datos sean válidos
- Formateo profesional: Uso formateo avanzado para salidas legibles
- Cálculos adicionales: Añado análisis que serían útiles en la vida real
- Manejo de errores: Considero casos especiales y situaciones límite
- Documentación: Comento el código para explicar decisiones no obvias
Siguientes pasos
Despues de revisar estas soluciones:
- Intenta variaciones: Modifica los ejercicios con diferentes datos
- Combina conceptos: Usa técnicas de varios ejercicios juntas
- Crea tus propios ejercicios: Diseña problemas similares
- Busca optimizaciones: ¿Puedes hacer el código más eficiente?
- Añade funcionalidades: Extiende las soluciones con nuevas características
Recuerda: No hay una única forma “correcta” de resolver un problema en programación. Estas soluciones representan un enfoque, pero tu solución puede ser igualmente válida si resuelve el problema eficientemente.
Agradecimientos
Este libro no habría sido posible sin el increíble trabajo de las comunidades de código abierto y los desarrolladores que han creado las herramientas, bibliotecas y recursos que utilizamos día a día. Queremos expresar nuestro más profundo agradecimiento a todos los que han contribuido a hacer este proyecto una realidad.
🛠️ Herramientas de Desarrollo
mdBook
Generador de libros estáticos basado en Rust
mdBook es la base fundamental de este libro digital. Esta fantástica herramienta desarrollada por la comunidad de Rust nos permite crear documentación web interactiva de alta calidad con una sintaxis Markdown simple y elegante.
- Uso en este libro: Generación de HTML interactivo, navegación, búsqueda integrada
- Licencia: Mozilla Public License 2.0
- Agradecimientos especiales: A todo el equipo de desarrollo y mantenedores de mdBook
D2
Lenguaje de diagramas declarativo
D2 nos permite crear diagramas técnicos claros y profesionales que ayudan a visualizar conceptos complejos de programación de manera accesible.
- Uso en este libro: Diagramas de flujo, estructuras de datos, arquitecturas de proyectos
- Licencia: Mozilla Public License 2.0
- Agradecimientos: Al equipo de Terrastruct por esta innovadora herramienta
Git
Sistema de control de versiones distribuido
Git hace posible el desarrollo colaborativo y el mantenimiento histórico de este proyecto.
- Uso en este libro: Control de versiones, colaboración, historial de cambios
- Licencia: GNU General Public License v2
- Agradecimientos: A Linus Torvalds y toda la comunidad de contribuidores de Git
Tipografía y Fuentes
Google Fonts
Biblioteca de fuentes web gratuitas
Google Fonts proporciona las fuentes de alta calidad que utilizamos tanto en la versión web como en el PDF, asegurando una excelente legibilidad y soporte Unicode completo.
Fuentes Específicas Utilizadas:
- Uso: Texto principal en todos los formatos
- Características: Soporte Unicode comprehensivo, excelente legibilidad
- Licencia: SIL Open Font License 1.1
- Uso: Emojis y símbolos coloridos en PDFs
- Características: Compatibilidad completa con estándares Unicode de emojis
- Licencia: SIL Open Font License 1.1
- Uso: Bloques de código y texto monoespaciado
- Características: Diseño optimizado para programación, ligaduras opcionales
- Licencia: SIL Open Font License 1.1
- Uso: Símbolos matemáticos y técnicos
- Características: Cobertura completa de símbolos matemáticos Unicode
- Licencia: SIL Open Font License 1.1
Generación de Documentos
Pandoc
Conversor universal de documentos
Pandoc es la herramienta que nos permite generar múltiples formatos de salida (PDF, EPUB) a partir de nuestro contenido Markdown, manteniendo la calidad y formato en cada uno.
- Uso en este libro: Generación de PDF y EPUB, conversión de formatos
- Licencia: GNU General Public License v2+
- Agradecimientos: A John MacFarlane y todos los contribuidores de Pandoc
LuaLaTeX
Motor de tipografía TeX con soporte Unicode
LuaLaTeX nos permite generar PDFs de alta calidad con soporte completo para Unicode, incluyendo emojis y caracteres especiales.
- Uso en este libro: Generación de PDF con tipografía profesional
- Licencia: TeX Live License
- Agradecimientos: Al equipo de desarrollo de LuaTeX y la comunidad TeX
fontspec
Paquete LaTeX para selección avanzada de fuentes
fontspec nos permite utilizar fuentes modernas TrueType y OpenType en nuestros documentos LaTeX, habilitando el soporte Unicode completo.
- Uso en este libro: Configuración avanzada de fuentes en PDF
- Licencia: LaTeX Project Public License 1.3
- Agradecimientos: A Will Robertson y contribuidores del paquete fontspec
HarfBuzz
Motor de renderizado de texto Unicode
HarfBuzz proporciona el renderizado de texto avanzado que permite la correcta visualización de caracteres complejos y sistemas de escritura diversos.
- Uso en este libro: Renderizado correcto de texto Unicode en PDFs
- Licencia: MIT License
- Agradecimientos: Al equipo de HarfBuzz y la comunidad de desarrollo
Despliegue y Hosting
Cloudflare Pages
Plataforma de despliegue y CDN global
Cloudflare Pages hace posible que este libro esté disponible globalmente con tiempos de carga rápidos y alta disponibilidad.
- Uso en este libro: Hosting web, CDN global, despliegue automático
- Agradecimientos: A Cloudflare por proporcionar esta plataforma excepcional
GitLab CI/CD
Plataforma de integración y despliegue continuo
GitLab CI/CD automatiza la construcción, testing y despliegue de este libro, asegurando calidad y consistencia en cada versión.
- Uso en este libro: Automatización de build, testing, despliegue automático
- Licencia: MIT License
- Agradecimientos: A GitLab Inc. y la comunidad de contribuidores
Desarrollo Web y UX
Tecnologías Web Estándar
HTML5, CSS3, JavaScript ES6+
Los estándares web modernos nos permiten crear una experiencia interactiva y accesible para todos los usuarios.
- Uso en este libro: Interfaz web, interactividad, accesibilidad
- Organizaciones: W3C, WHATWG, Ecma International
- Agradecimientos: A todas las organizaciones de estándares web y sus contribuidores
WCAG (Web Content Accessibility Guidelines)
Directrices de accesibilidad web
Las directrices WCAG nos ayudan a hacer este libro accesible para personas con diferentes capacidades y necesidades.
- Uso en este libro: Guías de accesibilidad, navegación por teclado, contraste de colores
- Organización: W3C Web Accessibility Initiative
- Agradecimientos: A la WAI y todos los expertos en accesibilidad
Comunidad Python
Python Software Foundation
Lenguaje de programación Python
Python es el corazón de este libro. Su filosofía de código limpio y legible, junto con su comunidad acogedora, hacen que sea el lenguaje perfecto para principiantes.
- Uso en este libro: Lenguaje de programación principal, ejemplos, ejercicios
- Licencia: Python Software Foundation License
- Agradecimientos especiales: A Guido van Rossum, la PSF y toda la comunidad Python mundial
Documentación Oficial de Python
Documentación y tutoriales oficiales
La excelente documentación de Python ha sido una referencia invaluable para asegurar la precisión técnica de nuestro contenido.
- Uso en este libro: Referencia técnica, verificación de conceptos
- Licencia: Python Software Foundation License
- Agradecimientos: A todos los documentadores y traductores de la comunidad Python
Recursos Educativos y Comunidad
Comunidad de Educadores en Programación
Un agradecimiento especial a todos los educadores, bloggers, y creadores de contenido que han compartido sus conocimientos y métodos de enseñanza que han inspirado el enfoque pedagógico de este libro.
Lectores Beta y Colaboradores
Gracias a todas las personas que han proporcionado feedback, reportado errores, y sugerido mejoras durante el desarrollo de este libro. Sus contribuciones han sido invaluables para mejorar la calidad del contenido.
Reconocimientos Especiales
Código Abierto
Este proyecto es un testimonio del poder del software de código abierto. Cada herramienta, biblioteca y recurso utilizado está disponible gracias a la generosidad y dedicación de desarrolladores de todo el mundo que contribuyen su tiempo y conocimiento sin esperar nada a cambio.
Accesibilidad e Inclusión
Agradecemos especialmente a las comunidades que trabajan en accesibilidad web y educación inclusiva, cuyas directrices y mejores prácticas han guiado el desarrollo de este libro para que sea accesible para todos.
Comunidades de Aprendizaje
A todas las comunidades en línea, foros, y espacios de aprendizaje donde programadores novatos y experimentados comparten conocimiento y se ayudan mutuamente. Su espíritu colaborativo inspira el enfoque de este libro.
Una Nota Personal
Crear este libro ha sido posible únicamente gracias al ecosistema increíble de herramientas de código abierto y las comunidades que las mantienen. Cada línea de código que escribimos, cada diseño que creamos, y cada problema que resolvemos se basa en el trabajo previo de miles de desarrolladores que han contribuido a estos proyectos.
Si este libro te ha sido útil, considera contribuir de vuelta a estas comunidades: reporta bugs, contribuye con código, ayuda con documentación, o simplemente agradece a los mantenedores. El código abierto funciona porque todos participamos.
¡Gracias a todos por hacer posible este proyecto!
Este libro se mantiene actualizado gracias a las versiones más recientes de todas estas herramientas